Android逆向fiddler抓包工具——理解HTTP协议
HTTP协议格式
HTTP协议是一种应用非常广泛的应用层协议,当我们在浏览器中输入一个URL(“网址”)时,浏览器就会给客户端发送一个HTTP请求,服务器收到请求之后,就会返回一个HTTP响应。
为了能够看到HTTP请求和响应的详细内容,我们需要使用抓包工具,本文以Fiddler为例。
http工作过程
当我们在浏览器发送一个请求的时候,这个时候就会用到http协议,其实我们发送的就是一个http请求,服务器也会给我们返回http响应.
在这里我们发送一次请求,可能有许多次http请求与响应的交互过程.

在http协议通过网络交互的过程中,我们了解到一些关键字.
客户端:就是发送请求的一方(我们在浏览器查询事件的时候我们就是客户端)
服务器:返回响应的一方(我们向百度发送请求后,百度会给我们返回一个响应,百度可以理解为服务器)
请求:客户端向服务器发送的数据.
响应:服务器向客户端.
抓包工具的原理
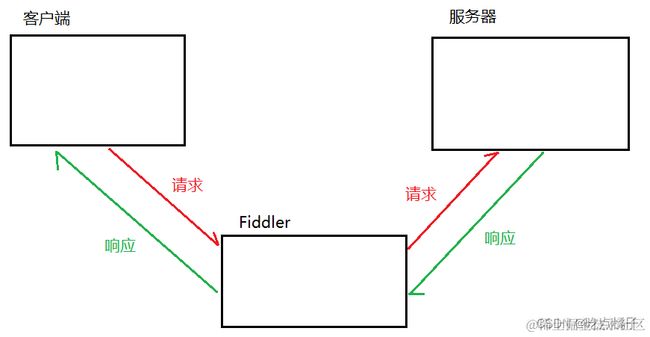
Fiddler抓包工具相当于一个“代理程序”:客户端向服务器发送的HTTP请求时,客户端会先把请求交给Fiddler,Fiddler再把请求转交给服务器;当服务器返回HTTP响应时,会先把响应交给Fiddler,Fiddler再把响应交给客户端。
因此,Fiddler就会很清楚客户端和服务器之间交互的数据细节。
简单理解就是,Fiddler相当于一个给客户端跑腿儿的小弟~
代理分为两种:
正向代理:给客户端提供服务的代理程序,此时正向代理就相当于把真实的客户端隐藏起来了,服务器不知道真实的客户端是谁。
反向代理:给服务器提供服务的代理程序,此时反向代理就相当于把真实的服务器隐藏起来了,客户端不知道真实的服务器是谁。
使用fiddler抓包
fiddler工具页面介绍
抓到包的列表
fiddler左边是抓到包的列表,列表的内容是不断的变化,这是很正常的,因为只要你的电脑与网络进行一次交互,就会进行http抓包.

包的详情
双击左侧的某个包就会进入该包的详情页.
右边上方是http的请求报文.
右边下方是http响应的报文.


包的详细数据
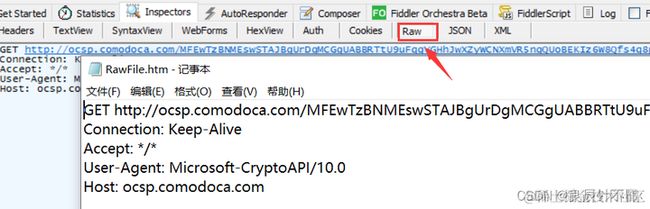
raw翻译为原生的,也就是http最原始的请求数据.
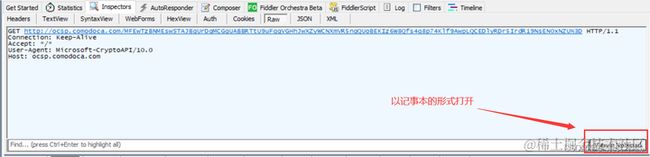
点击右下角的view in notepad就会以记事本的形式打开数据,可以更清楚的看到数据.
定位自己需要的包
我们抓包后,如何快速定位自己发的包呢?
黑色的包表示普通数据;蓝色的包响应是html.
看域名,根据域名定位,像百度,百度一下,你就知道
看响应的数据长度,一般是找长的.
抓包数据分析
http请求
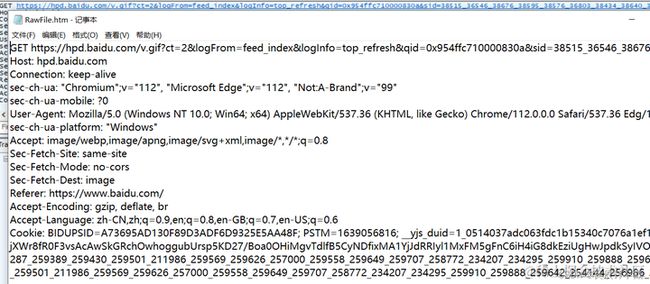
首行
GET https://mbd.baidu.com/newspage/api/getpcvoicelist?callback=JSONP_0& HTTP/1.1
请求报头header
从首行结束开始到空行结束,空行是header的结束标记.
正文
header结束后,下面的内容就是正文,有时候没有正文.
http响应
首行
HTTP/1.1 200 OK
响应报头header
从首行结束开始到空行结束,空行是header的结束标记.
正文
空行后面的内容.
一般来说,在上网的时候,页面显示的内容,哪怕是一个简单的页面,都是服务器作为响应返回来的结果.
这就是Android逆向开发中的使用fiddler抓包工具,进行抓包。更多有关逆向开发的学习大家可以参考《Android逆向文档》点击就可以查看详细类目了。

最后:下载抓包工具fiddler
抓包工具有很多,我们在这里主要研究http,因此我们简单的下载一个http的抓包工具即可.
- 进fiddler官网
直接在浏览器搜索fiddler即可,记住一定要进官网.
怎么辨别官网呢?右下角会有官网网站显示,比如fiddler,页面上会显示与fiddler相关的东西.
- 点进去下载经典版
经典版是免费的版本,有这一款
- 填写相关信息进行下载