Django
环境:
python 3.9
Django 3
pycharm
一、创建 Django项目
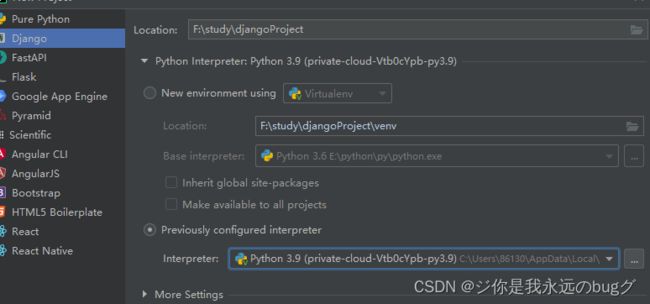
在此处选择项目的存放地址以及python的开发版本
1.1、项目结构
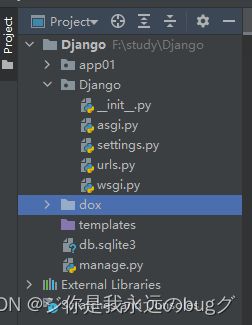
先忽视下 apps文件夹,后面会讲到
manage.py 【项目的管理,启动项目、创建app、数据管理】【不要动】【常常用】
└── Django
├── init.py
├── settings.py 【项目配置】 【常常修改】
├── urls.py 【URL和函数的对应关系】【常常修改】
├── asgi.py 【接收网络请求】【不要动】
└── wsgi.py 【接收网络请求】【不要动】
二、创建第一个 app(应用)
2.1、什么是app
一个app就是一个功能模块,比如:用户管理、用户管理都是一个app
2.2、创建一个app
python manage.py startapp app01 刷新项目
此时便可以看到 app01的文件夹,这就是一个app
2.3、app的目录结构
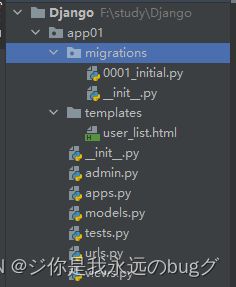
├── app01 app的名称
│ ├── init.py
│ ├── admin.py 【固定,不用动】django默认提供了admin后台管理。
│ ├── apps.py 【固定,不用动】app启动类
│ ├── migrations 【固定,不用动】数据库变更记录
│ │ └── init.py
│ ├── models.py 【重要】,对数据库操作。
│ ├── tests.py 【固定,不用动】单元测试
│ └── views.py 主要进行业务操作
2.4、注册app
上面只是创建了一个app但是并没有注册进我们的Django 项目
确保app已注册 【settings.py】在INSTALLED_APPS 中添加 ‘app01.apps.App01Config’
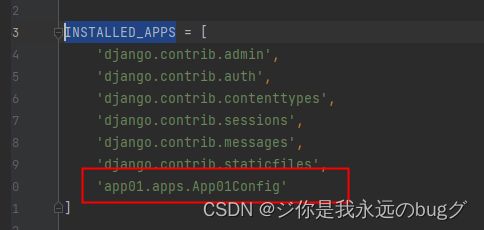

因为 新创建的app 的启动类的路径是 app01.apps.App01Config
2.5、第一个程序:hello
首先在 根目录的 urls.py中,配置请求路由和对应的业务代码地址
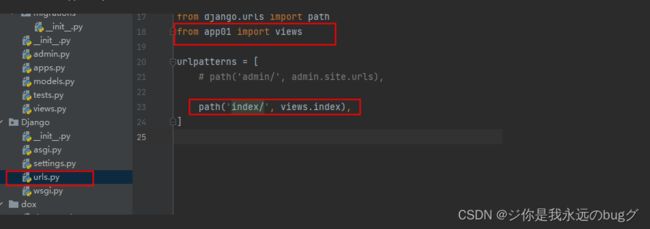
路由地址是 127.0.0.1:8000/index ,对应的业务在 app01下的views的index函数【from app01 import view】
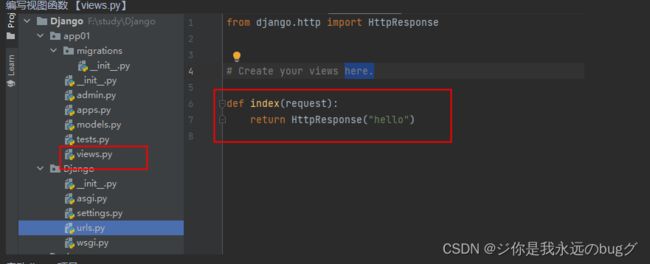
启动项目:python manage.py runserver
或者 pycharm的启动

2.6、返回前端页面
定义好路由和业务
path('getUserList', views.getUserList),
render(request,“user_list.html”) 返回html页面
# 返回对应的 html页面
def getUserList(request):
return render(request, "user_list.html")
app01下新建一个templates文件夹,新建user_list.html 文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>用户列表</title>
</head>
<body>
</body>
</html>
项目寻找 user_list.html 文件的顺序:优先到根目录中的templates 下查找,否则根据配置文件的中注册的 app的注册顺序,逐一去他们的 templates 目录查找
2.7、Django 路由配置
2.7.1 一般url配置
1、首先在 app01下新建文件 urls.py文件 在这个里面写 这个app的路由
name 只是给这个 url命名,作为全局变量使用
# 指定当前 app的命名
from django.urls import path
from app01 import views
app_name = "app01"
urlpatterns = [
# path('admin/', admin.site.urls),
path('index', views.index,name ='index'),
path('getUserList', views.getUserList),
path('startRequest', views.startRequest),
path('ORM', views.orm),
]
2、在根目录中的urls中配置app01的路由
from django.contrib import admin
from django.urls import path, include
from app01 import views
urlpatterns = [
path('demo/', include("app01.urls"))
]
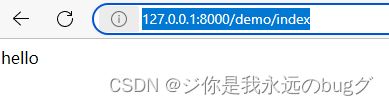
此时的hello的程序路由是
http://127.0.0.1:8000/demo/index 根目录的路由+对应app的路由
2.7.2、path和re_path方法
path是正常参数传递,re_path是采用正则表达式regex匹配
-
path方法:采用双尖括号<变量类型:变量名>或<变量名>传递,例如
。 -
re_path方法: 采用命名组(?P<变量名>表达式)的方式传递参数。
path('blog/articles//' , views.article_detail, name = 'article_detail'),
re_path(r'^blog/articles/(?P\d+)/$' , views.article_detail, name='article_detail'),
2.7.3、通过URL传递额外的参数
在你配置URL时,你还可以通过字典的形式传递额外的参数给视图, 而不用把这个参数写在链接里
urlpatterns = [
path('', views.ArticleList.as_view(), name='article_list', {'blog_id': 3}),
]
2.7.4、动态路由
path('/' ,AddView.as_view())
class AddView(APIView):
def get(self,request,module,*args,**kwargs):
if module =="info":
return HttpResponse("info")
else:
return HttpResponse("qqq")
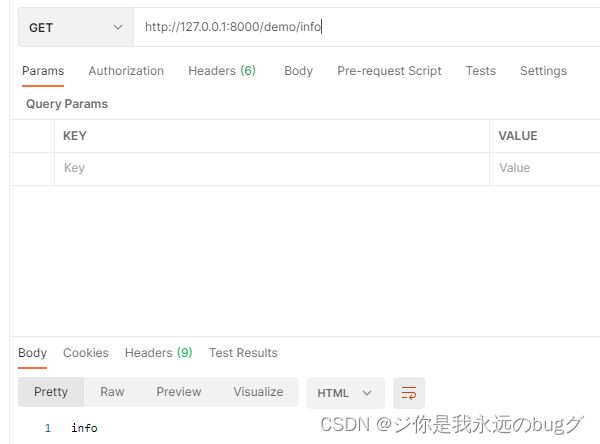
路由地址:http://127.0.0.1:8000/demo/info Get请求
路由的module 作为参数 传入 view 当 module = info 则返回 info
2.8、请求和响应
2.8.1、获取请求方式
request.method
2.8.2、获取请求数据
GET: request.GET
POST: request.POST
# 可以通过request对象拿到请求的所有数据
if request.method == 'GET': # 大写
return HttpResponse(" You're at the polls login.GET请求")
elif request.method == 'POST':
return HttpResponse(" You're at the polls login.POST请求")
else:
return HttpResponse(" You're at the polls login.其它请求")
二、Django的函数视图及通用类视图
Django的视图(view)是处理业务逻辑的核心,它负责处理用户的请求并返回响应数据。Django提供了两种编写视图的方式:基于函数的视图和基于类的视图。
2.1、函数视图
函数视图的优点是比较直接,容易读者理解, 缺点是不便于继承和重用。
# blog/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('blog/', views.index, name='index'),
path('blog/articles//' , views.article_detail, name='article_detail'),
]
# blog/views.py
from django.shortcuts import render, get_object_or_404
from .models import Article
# 展示所有文章
def index(request):
latest_articles = Article.objects.all().order_by('-pub_date')
return render(request, 'blog/article_list.html', {"latest_articles": latest_articles})
# 展示所有文章
def article_detail(request, id):
article = get_object_or_404(Article, pk=id)
return render(request, 'blog/article_detail.html', {"article": article})
request, 它是一个全局变量。Django把每个用户请求封装成了request对象,它包含里当前请求的所有信息,比如请求路径request.path, 当前用户request.user以及用户通过POST提交的数据request.POST
2.2、类视图
使用类视图后可以将视图对应的不同请求方式以类中的不同方法来区别定义(get方法处理GET请求,post方法处理POST请求),相对于函数视图逻辑更清晰,代码也有更高的复用性。
from django.views.generic import View
class MyClassView(View):
"""类视图"""
def get(self, request):
"""处理GET请求"""
return render(request, 'register.html')
def post(self, request):
"""处理POST请求"""
return ...
此时路由配置 需要使用 as_view()
path('', views.MyClassView.as_view()),
2.3、Django通用类视图
三、Mysql数据库的操作
3.1、python操作数据库
import pymysql
# 1.连接MySQL
conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd="root123", charset='utf8', db='unicom')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 2.发送指令
cursor.execute("insert into admin(username,password,mobile) values('wupeiqi','qwe123','15155555555')")
conn.commit()
# 3.关闭
cursor.close()
conn.close()
3.2、Django模型【models】详解
每个Django的模型(model)实际上是个类,继承了models.Model。每个Model应该包括属性(字段),关系(比如单对单,单对多和多对多)和方法。当你定义好Model模型后,Django的接口会自动帮你在数据库生成相应的数据表(table)。
3.2.1、示例
书本和出版社创建模型。出版社有名字和地址。书有名字,描述和添加日期。我们还需要利用ForeignKey定义了出版社与书本之间单对多的关系,因为一个出版社可以出版很多书,每本书都有对应的出版社。我们定义了Publisher和Book模型,它们都继承了models.Model
# models.py
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=60)
def __str__(self):
return self.name
class Book(models.Model):
name = models.CharField(max_length=30)
description = models.TextField(blank=True, default='')
publisher = ForeignKey(Publisher,on_delete=models.CASCADE)
add_date = models.DateField(auto_now_add=True)
def __str__(self):
return self.name
依次执行一下命令,可在数据库中生成表
python manage.py makemigrations
python manage.py migrate
注意:
1、CharField的 max_length必须设置
2、ForeignKey 的 on_delete 必须设置
3、这个字段 field 是否必填(blank = True or False),是否可以为空(null = True or False)
3.2.2、模型的组成
一个标准的Django模型分别由模型字段、META选项和方法三部分组成
- 定义的模型字段:包括基础字段和关系字段
- 自定义的Manager方法:改变模型
- class Meta选项: 包括排序、索引等等(可选)。
- def str():定义单个模型实例对象的名字(可选)。
- def save():重写save方法(可选)。
- def get_absolute_url():为单个模型实例对象生成独一无二的url(可选)
- 其它自定义的方法。
3.2.2.1、字段
1、基础字段:charFieId
一般需要通过max_length = xxx 设置最大字符长度。如不是必填项,可设置blank = True和default = ‘‘。如果用于username, 想使其唯一,可以设置unique = True。如果有choice选项,可以设置 choices = XXX_CHOICES
如:
STATUS_CHOICES = (
('p', _('Published')),
('d', _('Draft')),
)
status = models.CharField(_('Status (*)'), max_length=1, choices=STATUS_CHOICES, default='s', null=True, blank=True)
2、文本字段 :TextFieId
适合大量文本,max_length =xxx 可选
3、时间字段: DateFieId 和 DateTimeFieId
可通过default=xx选项设置默认日期和时间。
- 对于DateTimeField: default=timezone.now - 先要from django.utils import timezone
- 如果希望自动记录一次修改日期(modified),可以设置: auto_now=True
- 如果希望自动记录创建日期(created),可以设置auto_now_add=True
4、邮箱字段:EmailFieId
如不是必填项,可设置blank = True和default = ‘。一般Email用于用户名应该是唯一的,建议设置unique = True
5、IntegerField(), SlugField(), URLField(),BooleanField()
可以设置blank = True or null = True。对于BooleanField一般建议设置defaut = True or False
6、文件字段:FileField(upload_to=None, max_length=100)
upload_to = “/some folder/”:上传文件夹路径
max_length = xxxx:文件最大长度
7、图片字段:ImageField (upload_to=None, max_length=100,)
upload_to = “/some folder/”: 指定上传图片路径
8、一对一字段:OneToOneField(to, on_delete=xxx, options) :
- to必需指向其他模型,比如 Book or ‘self’ .
- 必需指定on_delete选项(删除选项): i.e, “on_delete = models.CASCADE” or “on_delete = models.SET_NULL” .
- 可以设置 “related_name = xxx” 便于反向查询
9、一对多字段:ForeignKey(to, on_delete=xxx, options)
- to必需指向其他模型,比如 Book or ‘self’ .
- 必需指定on_delete选项(删除选项): i.e, “on_delete = models.CASCADE” or “on_delete = models.SET_NULL” .
- 可以设置”default = xxx” or “null = True” ;
- 如果有必要,可以设置 “limit_choices_to = “,
- 可以设置 “related_name = xxx” 便于反向查询。
对于OneToOneField和ForeignKey, on_delete选项和related_name是两个非常重要的设置,前者决定了了关联外键删除方式,后者决定了模型反向查询的名字。
10、多对多字段:ManyToManyField(to, options
- to 必需指向其他模型,比如 User or ‘self’ .
- 设置 “symmetrical = False “ 表示多对多关系不是对称的,比如A关注B不代表B关注A
- 设置 “through = ‘intermediary model’ “ 如果需要建立中间模型来搜集更多信息。
- 可以设置 “related_name = xxx” 便于反向查询。
多对多实例
一个人加入多个组,一个组包含多个人,我们需要额外的中间模型记录加入日期和理由。
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self):
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through='Membership')
def __str__(self):
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person, on_delete=models.CASCADE)
group = models.ForeignKey(Group, on_delete=models.CASCADE)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
on_delete选项
- CASCADE:级联删除。当你删除publisher记录时,与之关联的所有 book 都会被删除。
- PROTECT: 保护模式。如果有外键关联,就不允许删除,删除的时候会抛出1) ProtectedError错误,除非先把关联了外键的记录删除掉。例如想要删除publisher,那你要把所有关联了该publisher的book全部删除才可能删publisher。
- SET_NULL: 置空模式。删除的时候,外键字段会被设置为空。删除publisher后,book 记录里面的publisher_id 就置为null了。
- SET_DEFAULT: 置默认值,删除的时候,外键字段设置为默认值。
SET(): 自定义一个值。 - DO_NOTHING:什么也不做。删除不报任何错,外键值依然保留,但是无法用这个外键去做查询。
related_选项
在文初的Publisher和Book模型里,我们可以通过book.publisher获取每本书的出版商信息,这是因为Book模型里有publisher这个字段。但是Publisher模型里并没有book这个字段,可以使用 related 字段 反向查询
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=60)
def __str__(self):
return self.name
# 将related_name设置为books
class Book(models.Model):
name = models.CharField(max_length=30)
description = models.TextField(blank=True, default='')
publisher = ForeignKey(Publisher,on_delete=models.CASCADE, related_name='books')
add_date = models.DateField(auto_now_add=True)
def __str__(self):
return self.name
3.2.2.2、模型的META选项
- abstract=True: 指定该模型为抽象模型
- proxy=True: 指定该模型为代理模型
- verbose_name=xxx和verbose_name_plural=xxx: 为模型设置便于人类阅读的别名
- db_table= xxx: 自定义数据表名
- odering=[‘-pub-date’]: 自定义按哪个字段排序,-代表逆序
- permissions=[]: 为模型自定义权限
- managed=False: 默认为True,如果为False,Django不会为这个模型生成数据表
- indexes=[]: 为数据表设置索引,对于频繁查询的字段,建议设置索引
- constraints=: 给数据库中的数据表增加约束。
class Meta:
ordering = ['-create_date']
verbose_name = "Article"
verbose_name_plural = "Articles"
3.2.2.3、模型的方法
1、标准方法
- def str():给单个模型对象实例设置人为可读的名字(可选)。
- def save():重写save方法(可选)。
- def get_absolute_url():为单个模型实例对象生成独一无二的url(可选)
2、自定义方法
1、自定义方法
# 计数器
def viewed(self):
self.views += 1
self.save(update_fields=['views'])
2、自定义Manager方法
# First, define the Manager subclass.
class DahlBookManager(models.Manager):
def get_queryset(self):
return super().get_queryset().filter(author='Roald Dahl')
# Then hook it into the Book model explicitly.
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.CharField(max_length=50)
objects = models.Manager() # The default manager.
dahl_objects = DahlBookManager() # The Dahl-specific manager.
3.2.3、完美的高级Django模型示例
from django.db import models
from django.urls import reverse
# 自定义Manager方法
class HighRatingManager(models.Manager):
def get_queryset(self):
return super().get_queryset().filter(rating=1)
# CHOICES选项
class Rating(models.IntegerChoices):
VERYGOOD = 1, 'Very Good'
GOOD = 2, 'Good'
BAD = 3, 'Bad'
class Product(models.Model):
# 数据表字段
name = models.CharField('name', max_length=30)
rating = models.IntegerField(max_length=1, choices=Rating.choices)
# MANAGERS方法
objects = models.Manager()
high_rating_products =HighRatingManager()
# META类选项
class Meta:
verbose_name = 'product'
verbose_name_plural = 'products'
# __str__方法
def __str__(self):
return self.name
# 重写save方法
def save(self, *args, **kwargs):
do_something()
super().save(*args, **kwargs)
do_something_else()
# 定义单个对象绝对路径
def get_absolute_url(self):
return reverse('product_details', kwargs={'pk': self.id})
# 其它自定义方法
def do_something(self):
3.2、Django操作数据库
其中Django内置了ORM ,他的作用是:
创建、修改、删除数据库,对表的操作:不需要写sql。
ORM操作参考
3.2.1、Django连接数据库
安装组件:pip install mysqlclient
1、在根目录下的setting配置文件中配置mysql路径地址
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 驱动`在这里插入代码片`
'NAME': 'school', # 数据库名字
'USER': 'root',
'PASSWORD': '123456',
'HOST': '127.0.0.1', # 那台机器安装了MySQL
'PORT': 3306,
}
}
3.2.2、写表对象生成mysql表结构
2、在 app下的models文件中写入
from django.db import models
class UserInfo(models.Model):
name = models.CharField(max_length=32)
class Aaa(models.Model):
name = models.CharField(max_length=32,verbose_name="姓名")
age = models.IntegerField(max_length=10)
create_time = models.DateTimeField
count = models.DecimalField(verbose_name="账户余额", max_digits=10, decimal_places=2, default=0)
del_flag = models.IntegerField(max_length=2,default=1)
3、在pycharm的 terminal中分别输入
python manage.py makemigrations
python manage.py migrate
看下数据库,多了两张表
![]()

经测试:在 models中的已有表类中,新增或者修改列时,不生效!!!!!!!!!!!!
以后在开发中如果想要对表结构进行调整:
在models.py文件中操作类即可。
命令
python manage.py makemigrations
python manage.py migrate
3.2.3、原本数据库中的表导入models中
注意注意注意:提前将pycharm的编码改为 utf-8,否则会报错
遇到的问题解决
python manage.py inspectdb (‘表名,可不写’)> app名/models.py
等一会 ,才会有
3.2.4、增删改查
基于 querysetd的惰性原理,当user_list = UserInfo.objects.filter(id=12).value(“可选字段名” 代码时,并不会去数据库中查询,当对user_list 进行操作时如遍历、if 【if user_list.exit 不会执行】才回去执行,并将其结果放入缓存中,下次再对 user_list操作不会到数据库中查找,那么进行计数的话 如果先查找再计数可以用len获取,避免到数据库查找。
1、增:
create:
UserInfo.objects.create(name="武沛齐")
UserInfo.objects.create(name="朱虎飞")
UserInfo.objects.create(name="吴阳军")
get_or_create
它会返回查询到的或新建的模型对象实例,还会返回这个对象实例是否是刚刚创建的。
obj, created = Article.objects.get_or_create(title="My first article", body="My first article body")
save
article = Article(title="My first article", body="My first article body")
article.save()
批量新增
bulk_create和bulk_update方法可以一次SQL添加或更新多条数据
user_list = [UserInfo(name="ls001"),UserInfo(name="ls002")]
# 执行一次sql插入数据
UserInfo.objects.bulk_create(user_list)
update_or_create
无则新增,有则更新
Storage.objects.update_or_create(
name=user.username,
defaults={
'user': user,
'size': user.storage_size,
'create_user': user
},
)
name=user.username,:是判断存不存在得条件
defaults:是新增/修改的值
2、删除
删除单条
UserInfo.objects.filter(id=3).delete() # 删除 id = 3
删除部分数据
# 删除标题含有python的文章
Article.objects.filter(title__icontains="python").delete()
删除所有数据
# 慎用
Article.objects.all().delete()
3、修改
既可以用save方法,也可以用update方法。其区别在于save方法不仅可以更新数据中现有对象数据,还可以创建新的对象。而update方法只能用于更新已有对象数据。一般来说,如果要同时更新多个对象数据,用update方法或bulk_update方法更合适。
UserInfo.objects.all().update(name=999) #修改所以
UserInfo.objects.filter(id=2).update(name=999)# 修改id=2
UserInfo.objects.filter(name="朱虎飞").update(name=999)# 修改 name = 朱虎飞
4、查询
查询条件放进字典
data_dict = {"name":"lsl","id":1}
UserInfo.objects.filter(**data_dict).value("可选字段名")
范围查询
UserInfo.objects.filter(id=12).value("可选字段名") # 等于12
UserInfo.objects.filter(id__gt=12).value("可选字段名") # 大于12
UserInfo.objects.filter(id__gte=12).value("可选字段名") # 大于等于12
UserInfo.objects.filter(id__lt=12).value("可选字段名") # 小于12
UserInfo.objects.filter(id__lte=12).value("可选字段名") # 小于等于12
# 按范围查询,in或者range
articles = Article.objects.filter(id__range=[2, 11])
articles = Article.objects.filter(id__in=[3, 6,9])
当查询 id 不存在时,会报错,可以使用 get_object_or_404 方法,即使Id不存在 也不会报错
from django.shortcuts import get_object_or_404
article = get_object_or_404(Article, pk=1)
模糊查询
UserInfo.objects.filter(name_contains="ls").value("可选字段名") # 名字中包含 ls的
UserInfo.objects.filter(mobile__startswith="1999").value("可选字段名") # 筛选出以1999开头
UserInfo.objects.filter(mobile__endswith="999").value("可选字段名") # 筛选出以999结尾
UserInfo.objects.filter(mobile__contains="999").value("可选字段名") # 筛选出包含999
日期查询
# 查询2021年发表的文章
Article.objects.filter(created__year=2021)
# 查询2021年3月19日发表的文章
import datetime
Article.objects.filter(created__date=datetime.date(2021,3,19))
# 查询2021年1月1日以后发表的文章
Article.objects.filter(created__gt=datetime.date(2021, 1, 1))
# 与当前时间相比,查询即将发表的文章
from django.utils import timezone
Article.objects.filter(created__gt=timezone.now())
# 按绝对时间范围查询,查询2021年1月1日到6月30日发表文章
article = Aritlce.objects.filter(created__gte=datetime.date(2021, 1, 1),
pub_date__lte=datetime.date(2021, 6, 30))
# 按相对时间范围查询,用range查询3月1日以后30天内发表文章
startdate = datetime.date(2021, 3, 1)
enddate = startdate + datetime.timedelta(days=30)
Article.objects.filter(pub_date__range=[startdate, enddate])
切片、排序、去重
# 切片
articles = Article.objects.filter(created__year=2021)[:5]
# 排序:created正序,-表示逆序
articles = Article.objects.all().order_by('-created')
# 去重
Article.objects.filter(title__icontains='python').distinct()
5、分页查询
queryset = models.PrettyNum.objects.all().order_by("id").value("可选字段名")
queryset = models.PrettyNum.objects.filter(id=1).order_by("id")[0:10]
# 第1页
queryset = models.PrettyNum.objects.all().order_by("id")[0:10]
# 第2页
queryset = models.PrettyNum.objects.all().order_by("id")[10:20]
# 第3页
queryset = models.PrettyNum.objects.all().order_by("id")[20:30]
Paginator插件
queryset = Article.objects.filter(status='p').order_by('-pub_date')
paginator = Paginator(queryset, 10) # 实例化一个分页对象, 每页显示10个
page = request.GET.get('page') # 从URL通过get页码,如?page=3
try:
page_obj = paginator.page(page)
except PageNotAnInteger:
page_obj = paginator.page(1) # 如果传入page参数不是整数,默认第一页
except EmptyPage:
page_obj = paginator.page(paginator.num_pages)
6、查询数量
data = models.PrettyNum.objects.all().count()
data = models.PrettyNum.objects.filter(id=1).count()
6、条件查询
Q方法
有时候我们需要执行or逻辑的条件查询,这时使用Q方法就可以了,它可以连接多个查询条件。Q对象前面加~可以表示否定。
from django.models import Q
# 查询标题含有python或Django的文章
article = Article.objects.filter(Q(title__icontains='python')|Q(title__icontains='django'))
# 查询标题含有python,不含有Django的文章
article = Article.objects.filter(Q(title__icontains='python')|~Q(title__icontains='django'))
F方法
使用F()方法可以实现基于自身字段值来过滤一组对象,它还支持加、减、乘、除、取模和幂运算等算术操作
from django.db.models import F
Article.objects.filter(n_commnets__gt=F('n_pingbacks'))
Article.objects.filter(n_comments__gt=F('n_pingbacks') * 2)
四、请求拦截器[中间件]
4.1、请求通过
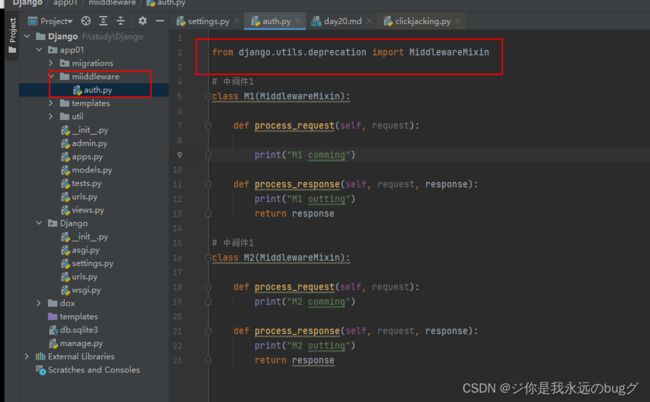
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import HttpResponse
# 中间件1
class M1(MiddlewareMixin):
def process_request(self, request):
print("M1 comming")
def process_response(self, request, response):
print("M1 outting")
return response
# 中间件1
class M2(MiddlewareMixin):
def process_request(self, request):
print("M2 comming")
def process_response(self, request, response):
print("M2 outting")
return response
新建一个拦截器文件,创建两个拦截器类对象 每个请求都会走进这里

'app01.miiddleware.auth.M1',
'app01.miiddleware.auth.M2',
在项目的 配置文件中配置这个拦截器 M1在前就会先执行 M1
随意访问一个请求:
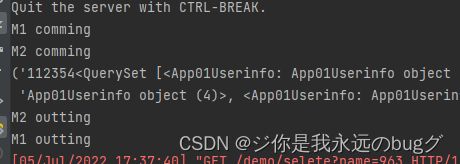
4.2、请求拦截
在process_request 中 如果没有返回值则继续执行,有返回值 则返回 HttpResponse
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import HttpResponse
# 中间件1
class M1(MiddlewareMixin):
def process_request(self, request):
# 如果没有返回值则继续执行,有返回值 则返回 HttpResponse
print("M1 comming")
return HttpResponse("err")
def process_response(self, request, response):
print("M1 outting")
return response
# 中间件1
class M2(MiddlewareMixin):
def process_request(self, request):
print("M2 comming")
def process_response(self, request, response):
print("M2 outting")
return response
结果:

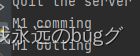
不会再进入 M2
五、验证码显示
参考这个
其中的字体我们在 c:// windows/font下有很多自提可以复制道到项目根目录下
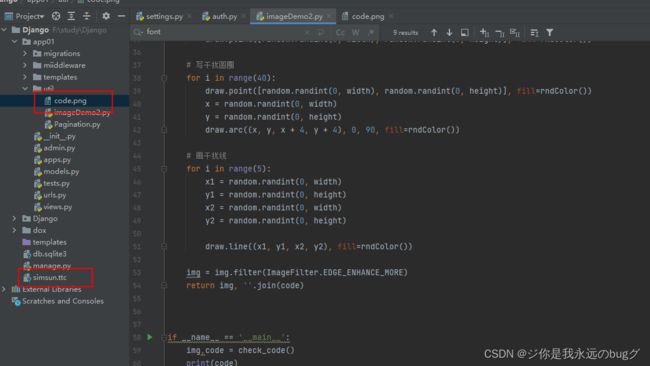
import random
from PIL import Image, ImageDraw, ImageFont, ImageFilter
def check_code(width=120, height=30, char_length=5, font_file='simsun.ttc', font_size=28):
code = []
img = Image.new(mode='RGB', size=(width, height), color=(255, 255, 255))
draw = ImageDraw.Draw(img, mode='RGB')
def rndChar():
"""
生成随机字母
:return:
"""
return chr(random.randint(65, 90))
def rndColor():
"""
生成随机颜色
:return:
"""
return (random.randint(0, 255), random.randint(10, 255), random.randint(64, 255))
# 写文字
font = ImageFont.truetype(font_file, font_size)
for i in range(char_length):
char = rndChar()
code.append(char)
h = random.randint(0, 4)
draw.text([i * width / char_length, h], char, font=font, fill=rndColor())
# 写干扰点
for i in range(40):
draw.point([random.randint(0, width), random.randint(0, height)], fill=rndColor())
# 写干扰圆圈
for i in range(40):
draw.point([random.randint(0, width), random.randint(0, height)], fill=rndColor())
x = random.randint(0, width)
y = random.randint(0, height)
draw.arc((x, y, x + 4, y + 4), 0, 90, fill=rndColor())
# 画干扰线
for i in range(5):
x1 = random.randint(0, width)
y1 = random.randint(0, height)
x2 = random.randint(0, width)
y2 = random.randint(0, height)
draw.line((x1, y1, x2, y2), fill=rndColor())
img = img.filter(ImageFilter.EDGE_ENHANCE_MORE)
return img, ''.join(code)
if __name__ == '__main__':
img,code = check_code()
print(code)
with open('code.png', 'wb') as f:
img.save(f,format='png')
# 1. 直接打开
# img,code = check_code()
# img.show()
# # 2. 写入文件
# img,code = check_code()
# with open('code.png','wb') as f:
# img.save(f,format='png')
# 3. 写入内存(Python3)
# from io import BytesIO
# stream = BytesIO()
# img.save(stream, 'png')
# stream.getvalue()
# 4. 写入内存(Python2)
# import StringIO
# stream = StringIO.StringIO()
# img.save(stream, 'png')
# stream.getvalue()
结果: 随机码 打印为TFBAG

六、文件的上传
6.1、上传图片
def upload(request):
file_object = request.FILES.get("avatar")
# 获取文件名
name = file_object.name
# 上传路径
f = open(name,"wb")
# 文件是一块块的读取,需要一块一块的上传
for chunk in file_object.chunks():
f.write(chunk)
f.close()
6.2、表格的读取上传
def uploadExcel(request):
# 1、获取文件上传对象 exc 为表格文件参数的 key的名字
files_get = request.FILES.get("exc")
# 2、对象传递给 openpyxl,由他读取文件的内容
workbook = load_workbook(files_get)
# 3、读取表格的sheet页
worksheet = workbook.worksheets[0]
# 4、读取第一行第二列
cell = worksheet.cell(1, 2)
# 5、获取内容
value = cell.value
f = open("文件名称", "wb")
# 6、循环获取每一行的数据 从第二行开始,第一行是标题
for row in worksheet.iter_rows(min_row=2):
text = row[0].value # 每行的内容
f.write(text)
f.close()
七、多进程
import random
import time
import os
"""
多进程编程
"""
"""
单进程
"""
def long_time_tack():
print("当前进程id:{}".format(os.getpid()))
time.sleep(2)
print("结果:{}".format(8 ** 20))
# 单进程测试
# if __name__ == '__main__':
# print("当前母进程:{}".format(os.getpid()))
# start = time.time()
#
# for i in range(2):
# long_time_tack()
#
# end = time.time()
# print("用时{}秒", format(end - start))
"""
多进程 【并行】
1、
利用multiprocess模块的Process()方法创建了两个新的进程p1和p2来进行并行计算。
Process()方法接收两个参数, 第一个是target,一般指向函数名,第二个是args,需要向函数传递的参数。
对于创建的新进程,调用start()方法即可让其开始。我们可以使用os.getpid()打印出当前进程的名字。
"""
from multiprocessing import Process, cpu_count, Pool, Queue
def long_time_process_task(i):
print("子进程:{} - 任务{}".format(os.getpid(), i))
time.sleep(2)
print("结果:{}".format(8 ** 20))
# if __name__ == '__main__':
# print("当前母进程:{}".format(os.getpid()))
#
# start = time.time()
# p1 = Process(target=long_time_process_task,args=(1,))
# p2 = Process(target=long_time_process_task,args=(2,))
# print("等待所有子进程完成")
# p1.start()
# p2.start()
#
# # 使用join()方法就是为了让母进程阻塞,等待子进程都完成后才打印出总共耗时
# p1.join()
# p2.join()
#
# end = time.time()
# print("总用时{}秒".format(end - start))
"""
多进程2:
利用multiprocess模块的pool类【进程池】创建多进程
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果进程池还没有满,就会创建一个新的进程来执行请求。
如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
"""
def long_time_pool_task(i):
print("子进程:{} - 任务{}".format(os.getpid(), i))
time.sleep(2)
print("结果:{}".format(8 ** 20))
# if __name__ == '__main__':
# print("cpu的内核数:{}".format(cpu_count()))
# print("当前母进程:{}".format(os.getpid()))
#
# start = time.time()
# # 容量为4的进程池
# p = Pool(4)
#
# for i in range(5):
# p.apply_async(long_time_pool_task, args=(i,))
# print("等待所有子进程完成")
# p.close()
# p.join()
# end = time.time()
# print("总用时{}秒".format(end - start))
"""
多进程直接的数据共享和 通信
创建了2个独立子进程,一个负责写(pw), 一个负责读(pr), 实现了共享一个队列queue。
q = Queue() 仅使用于两个进程
实现多进程的数据交换:
from multiprocessing import Manager
q = Manager().Queue()
"""
# 写数据进程执行的代码:
def write(q):
print("Process to write:{}".format(os.getpid()))
for value in ["A", "B", "C"]:
print("Put %s to queue..." % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码
def read(q):
print("Process to read:{}".format(os.getpid()))
while True:
value = q.get(True)
print("Get %s from queue" % value)
if __name__ == '__main__':
# 父进程创建queue,并传给各个子进程
q = Queue()
pw = Process(target=write, args=((q,)))
pr = Process(target=read,args=(q,))
# 启动子进程pw,写入
pw.start()
# 启动子进程pr 读取
pr.start()
# 等待pw结束
pw.join()
# pr进程是死循环,强行终止
pr.terminate()
八、多线程
"""
多线程
"""
import threading
import time
def long_time_task(i):
print('当前子线程: {} - 任务{}'.format(threading.current_thread().name, i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
# if __name__=='__main__':
# start = time.time()
# print('这是主线程:{}'.format(threading.current_thread().name))
# t1 = threading.Thread(target=long_time_task, args=(1,))
# t2 = threading.Thread(target=long_time_task, args=(2,))
#
# # 设置 主线程结束的同时 不管子线程如何 都不在执行
# # t1.setDaemon(True)
# # t2.setDaemon(True)
#
#
# t1.start()
# t2.start()
#
# # 主线程等待子线程结束后继续执行,需要用 join,
# t1.join()
# t2.join()
#
# end = time.time()
# print("总共用时{}秒".format((end - start)))
#-*- encoding:utf-8 -*-
"""
继承Thread类重新 run方法,创建线程
"""
def long_time_task(i):
time.sleep(2)
return 8**20
class MyThread(threading.Thread):
def __init__(self, func, args , name='', ):
threading.Thread.__init__(self)
self.func = func
self.args = args
self.name = name
self.result = None
def run(self):
print('开始子进程{}'.format(self.name))
self.result = self.func(self.args[0],)
print("结果: {}".format(self.result))
print('结束子进程{}'.format(self.name))
# if __name__=='__main__':
# start = time.time()
# threads = []
# for i in range(1, 3):
# t = MyThread(long_time_task, (i,), str(i))
# threads.append(t)
#
# for t in threads:
# t.start()
# for t in threads:
# t.join()
#
# end = time.time()
# print("总共用时{}秒".format((end - start)))
"""
不同线程间的数据共享
修改前给其上一把锁lock,确保一次只有一个线程能修改它。threading.lock()方法可以轻易实现对一个共享变量的锁定,修改完后release供其它线程使用
"""
class Account:
def __init__(self):
self.balance = 0
def add(self, lock):
# 获得锁
lock.acquire()
for i in range(0, 100000):
self.balance += 1
# 释放锁
lock.release()
def delete(self, lock):
# 获得锁
lock.acquire()
for i in range(0, 100000):
self.balance -= 1
# 释放锁
lock.release()
# if __name__ == "__main__":
# account = Account()
# lock = threading.Lock()
#
# # 创建线程
# thread_add = threading.Thread(target=account.add, args=(lock,), name='Add')
# thread_delete = threading.Thread(target=account.delete, args=(lock,), name='Delete')
#
# # 启动线程
# thread_add.start()
# thread_delete.start()
#
# # 等待线程结束
# thread_add.join()
# thread_delete.join()
#
# print('The final balance is: {}'.format(account.balance))
"""
使用queue队列通信-经典的生产者和消费者模型
"""
from queue import Queue
import random, threading, time
# 生产者类
class Producer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.queue = queue
def run(self):
for i in range(1, 5):
print("{} is producing {} to the queue!".format(self.getName(), i))
self.queue.put(i)
time.sleep(random.randrange(10) / 5)
print("%s finished!" % self.getName())
# 消费者类
class Consumer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.queue = queue
def run(self):
for i in range(1, 5):
val = self.queue.get()
print("{} is consuming {} in the queue.".format(self.getName(), val))
time.sleep(random.randrange(10))
print("%s finished!" % self.getName())
def main():
queue = Queue()
producer = Producer('Producer', queue)
consumer = Consumer('Consumer', queue)
producer.start()
consumer.start()
producer.join()
consumer.join()
print('All threads finished!')
if __name__ == '__main__':
main()
九、配置缓存
9.1、redis 缓存
9.1.1、django 配置redis环境
pip install django-redis
在配置文件中配置redis
# 配置 redis缓存
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379', # redis所在服务器或容器ip地址
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"PASSWORD": "your_pwd", # 你设置的密码
},
},
}
#可以在settings.py设置缓存默认过期时间
REDIS_TIMEOUT=24*60*60
CUBES_REDIS_TIMEOUT=60*30
NEVER_REDIS_TIMEOUT=365*24*60*60
测试是否缓存成功
命令行执行
python manage.py shell
from django.core.cache import cache #引入缓存模块
cache.set('v', '555', 60*60) #写入key为v,值为555的缓存,有效期30分钟
cache.has_key('v') #判断key为v是否存在
cache.get('v') #获取key为v的缓存
9.1.2、使用缓存
全站缓存(per-site)是依赖中间件实现的,也是Django项目中使用缓存最简单的方式。这种缓存方式仅适用于静态网站或动态内容很少的网站。
- 配置
# 缓存中间件,添加顺序很重要
MIDDLEWARE = [
'django.middleware.cache.UpdateCacheMiddleware', # 新增
'django.middleware.common.CommonMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware', # 新增
]
# 其它设置
CACHE_MIDDLEWARE_ALIAS = 'default' # 缓存别名
CACHE_MIDDLEWARE_SECONDS = '600' # 缓存时间
CACHE_MIDDLEWARE_KEY_PREFIX = '' # 缓存别名前缀
2、自定义使用
class Indec(ListView):
def get(self, request):
userInfoList = cache.get("user")
if userInfoList:
print("已经存在")
return HttpResponse(userInfoList)
else:
print("不存在")
objects_all = App01Userinfo.objects.all().values()
cache.set("user",objects_all)
return HttpResponse(objects_all)
已经存进 redis
![]()
十、信号机制【监听器】
信号主要用于Django项目内不同事件的联动,实现程序的解耦。比如当模型A有变动时,模型B与模型C收到发出的信号后同步更新
1、在 app下新建监听器类
from django.db.models.signals import post_save
from django.dispatch import receiver
from app01.models import App01Userinfo
@receiver(post_save, sender=App01Userinfo)
def create_user_profile(sender, instance, created, **kwargs):
if created:
print("创建成功")
@receiver(post_save, sender=App01Userinfo)
def save_user_profile(sender, instance, **kwargs):
print("更新成功")
当创建 App01Userinfo 对象的时候 会触发 创建成功
当更新 App01Userinfo 对象的时候 会触发 更新成功
2、配置
在 apps 类中配置
from django.apps import AppConfig
class App01Config(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'app01'
def ready(self):
import app01.util.signals
在 __init.py__配置
default_app_config = 'app01.apps.App01Config'
调用接口方法
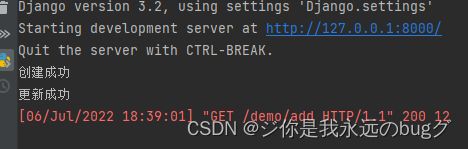
def add(request):
if request.GET != '':
name = request.GET.get("name")
App01Userinfo.objects.create(name=name)
return HttpResponse("新增成功")
else:
return HttpResponse("errrr")
结果:
此外 除了 post_save 信号 还有:
pre_save & post_save: 在模型调用 save()方法之前或之后发送。
pre_init& post_init: 在模型调用_init_方法之前或之后发送。
pre_delete & post_delete: 在模型调用delete()方法或查询集调用delete() 方法之前或之后发送。
m2m_changed: 在模型多对多关系改变后发送。
request_started & request_finished: Django建立或关闭HTTP 请求时发送。
注意:监听pre_save和post_save信号的回调函数不能再调用save()方法,否则回出现死循环。另外Django的update方法不会发出pre_save和post_save的信号。
2、自定义信号
每个自定义的信号,都是Signal类的实例。这里我们首先在app目录下新建一个signals.py文件,创建一个名为my_signal的信号,它包含有msg这个参数,这个参数在信号触发的时候需要传递。当监听函数收到这个信号时,会得到msg参数的值。
在上面配置的基础上
1、新建signals.py
from django.dispatch import receiver
from django.dispatch import Signal
my_signal = Signal(providing_args=['msg'])
@receiver(my_signal)
def my_signal_callback(sender, **kwargs):
print(kwargs['msg']) # 打印Hello world!
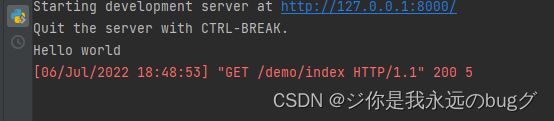
2、在需要触发的函数中加入
from app01.util import signals
signals.my_signal.send(sender=None, msg='Hello world')
3、当调用该函数时,会触发并打印 hello word
十一、Django异步和周期性任务【定时任务】
Django Web项目中我们经常需要执行耗时的任务比如发送邮件、调用第三方接口、批量处理文件等等,将这些任务异步化放在后台运行可以有效缩短请求响应时间。另外服务器上经常会有定时任务的需求,比如清除缓存、备份数据库等工作。Celery是一个高效的异步任务队列/基于分布式消息传递的作业队列,可以轻松帮我们在Django项目中设置执行异步和周期性任务。
Celery的工作原理
Celery是一个高效的基于分布式消息传递的作业队列。它主要通过消息(messages)传递任务,通常使用一个叫Broker(中间人)来协调client(任务的发出者)和worker(任务的处理者)。 clients发出消息到队列中,broker将队列中的信息派发给 Celery worker来处理。Celery本身不提供消息服务,它支持的消息服务(Broker)有RabbitMQ和Redis。小编一般推荐Redis,因为其在Django项目中还是首选的缓存后台。
1、前提
# pip安装必选
Django==3.2
celery==5.0.5
redis==3.5.3
# 可选,windows下运行celery 4以后版本,还需额外安装eventlet库
eventlet
# 推荐安装, 需要设置定时或周期任务时安装,推荐安装
django-celery-beat==2.2.0
# 视情况需要,需要存储任务结果时安装,视情况需要
django-celery-results==2.0.1
# 视情况需要,需要监控celery运行任务状态时安装
folower==0.9.7
2、Celeryp配置
1、新建celery.py文件
内容如下
import os
from celery import Celery
# 设置环境变量
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Django.settings')
# 实例化 backend 设置异步结果的保存
app = Celery('Django',backend="redis://localhost")
# namespace='CELERY'作用是允许你在Django配置文件中对Celery进行配置
# 但所有Celery配置项必须以CELERY开头,防止冲突
app.config_from_object('django.conf:settings', namespace='CELERY')
# 自动从Django的已注册app中发现任务
app.autodiscover_tasks()
# 一个测试任务
@app.task(bind=True)
def debug_task(self):
print(f'Request: {self.request!r}')
2、修改同级目录下的 init.py文件
from .celery import app as celery_app
__all__ = ('celery_app',)
3、修改配置文件 setting
# Celery配置
# 最重要的配置,设置消息broker,格式为:db://user:password@host:port/dbname
# 如果redis安装在本机,使用localhost
# 如果docker部署的redis,使用redis://redis:6379
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0"
# celery时区设置,建议与Django settings中TIME_ZONE同样时区,防止时差
# Django设置时区需同时设置USE_TZ=True和TIME_ZONE = 'Asia/Shanghai'
CELERY_TIMEZONE = TIME_ZONE
# 为任务设置超时时间,单位秒。超时即中止,执行下个任务。
CELERY_TASK_TIME_LIMIT = 5
此外还可选的配置
# 为django_celery_results存储Celery任务执行结果设置后台
# 格式为:db+scheme://user:password@host:port/dbname
# 支持数据库django-db和缓存django-cache存储任务状态及结果
CELERY_RESULT_BACKEND = "django-db"
# celery内容等消息的格式设置,默认json
CELERY_ACCEPT_CONTENT = ['application/json', ]
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
# 为任务设置超时时间,单位秒。超时即中止,执行下个任务。
CELERY_TASK_TIME_LIMIT = 5
# 为存储结果设置过期日期,默认1天过期。如果beat开启,Celery每天会自动清除。
# 设为0,存储结果永不过期
CELERY_RESULT_EXPIRES = xx
# 任务限流
CELERY_TASK_ANNOTATIONS = {'tasks.add': {'rate_limit': '10/s'}}
# Worker并发数量,一般默认CPU核数,可以不设置
CELERY_WORKER_CONCURRENCY = 2
# 每个worker执行了多少任务就会死掉,默认是无限的
CELERY_WORKER_MAX_TASKS_PER_CHILD = 200
3、测试Celery是否正常
先启动 redis ,然后运行 项目 ,最后 打开终端 输入
# Django 为项目的名字
# Linux下测试,启动Celery
Celery -A Django worker -l info
# Windows下测试,启动Celery
Celery -A Django worker -l info -P eventlet
# 如果Windows下Celery不工作,输入如下命令
Celery -A Django worker -l info --pool=solo
下面就是成功界面
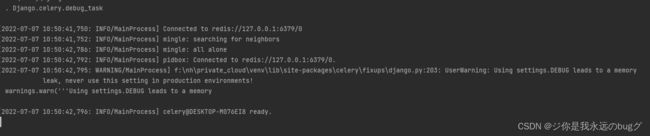
4、编写任务并获取任务相关信息
Django项目中所有需要Celery执行的异步或周期性任务都放在tasks.py文件里,该文件可以位于project目录下,也可以位于各个app的目录下。专属于某个Celery实例化项目的task可以使用@app.task装饰器定义,各个app目录下可以复用的task建议使用@shared_task定义。
注意:在修改代码后,重启项目后如果有报错先重启celery再试试
1、在 app下编写异步任务
# app/tasks.py, 可以复用的task
from celery import shared_task
import time
@shared_task
def add_test(x, y):
print("开始睡眠")
time.sleep(2)
print("睡眠结束")
return x + y
如果启动报错:
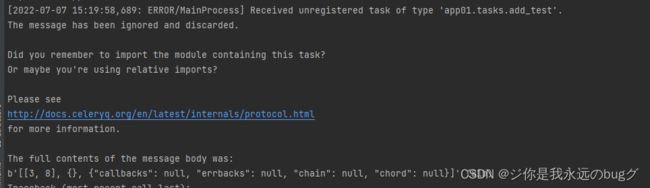
可以再异步任务上 定义名称
@shared_task(name='app01.tasks.add_test')
def add_test(x, y):
print("开始睡眠")
time.sleep(2)
print("睡眠结束")
return x + y
2、异步调用任务
Celery提供了2种以异步方式调用任务的方法,delay和apply_async方法,如下所示
# 方法一:delay方法
task_name.delay(args1, args2, kwargs=value_1, kwargs2=value_2)
# 方法二: apply_async方法,与delay类似,但支持更多参数
task.apply_async(args=[arg1, arg2], kwargs={key:value, key:value})
先使用 delay方法
# 返回对应的 html页面
def getUserList(request):
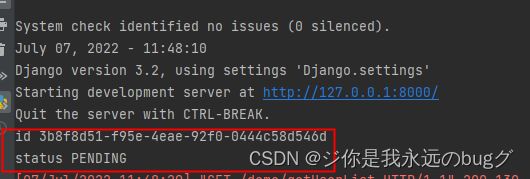
result = add_test.delay(3, 5)
print("id", result.task_id)
print("status", result.status)
return render(request, "user_list.html")
通过请求 调用该方法,感觉不到2秒的睡眠时间,打印出此异步任务的id和状态
注意此时获取任务状态结果,需要将异步任务信息保存下来 所以在celery.py中要有
# 实例化 backend 设置异步结果的保存
app = Celery('Django',backend="redis://localhost")
结果:
并且在终端有结果

除了状态和id之外,还可以打印
使用 apply_async调用
# 返回对应的 html页面
def getUserList(request):
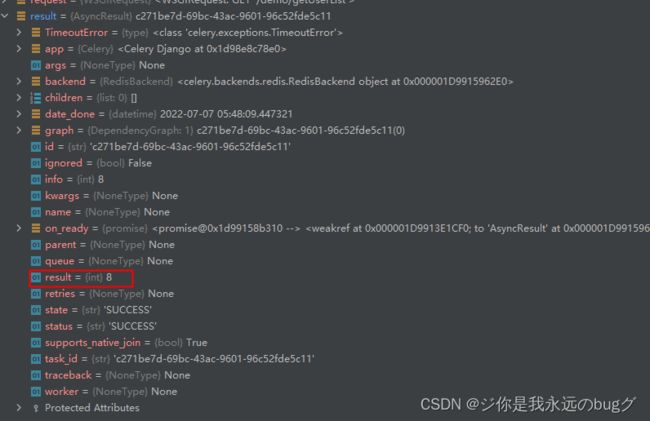
result1 = add_test.apply_async(args=[3, 5])
print("id", result1.task_id)
print("status", result1.status)
print("result", result1.result)
print("result", AsyncResult(result1.task_id).status) # 下面的 django-celery-results 代码获取任务信息的方式
return render(request, "user_list.html")
结果:

5、将任务信息存进数据库
1、安装django-celery-results
pip install django-celery-results
2、在配置文件中加入配置
# 支持数据库django-db和缓存django-cache存储任务状态及结果
# 建议选django-db
CELERY_RESULT_BACKEND = "django-db"
# celery内容等消息的格式设置,默认json
CELERY_ACCEPT_CONTENT = ['application/json', ]
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
此时 启动 celery 会报错:
RuntimeError: Model class django_celery_results.models.TaskResult doesn't declare an explicit app_label and isn't in an application in INSTALLED_APPS.
错误原因:'django_celery_results'未在INSTALL_APPS中注册。
这个时候 需要再配置文件中注册一下
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'django_celery_results'
]
再次启动,成功

当运行项目 开启异步的时候 会报错 ,因为上述任务存进数据库,表没建立的

3、建立 django-celery-results相关表
$ python manage.py migrate
此时启动项目,调用异步任务,会将信息插入到表

6、定时任务和周期性任务
1、安装 并配置 django-celery-beat
pip install django-celery-beat
加入到注册中
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'django_celery_results',
'django_celery_beat'
]
2、配置定时任务
在 setting 中添加
from datetime import timedelta
CELERY_BEAT_SCHEDULE = {
"add-every-30s": {
"task": "app01.task.add_task", # 不要写错,不然会报错
'schedule': 30.0, # 每30秒执行1次
'args': (3, 8) # 传递参数-
},
"add-every-day": {
"task": "app01.task.add_task",
'schedule': timedelta(hours=1), # 每小时执行1次
'args': (3, 8) # 传递参数-
},
}
启动调度任务【俩终端】
# 开启任务调度器
Celery -A Django beat
# windows下
Celery -A Django worker -l info --pool=solo
结果: 10秒钟执行一次
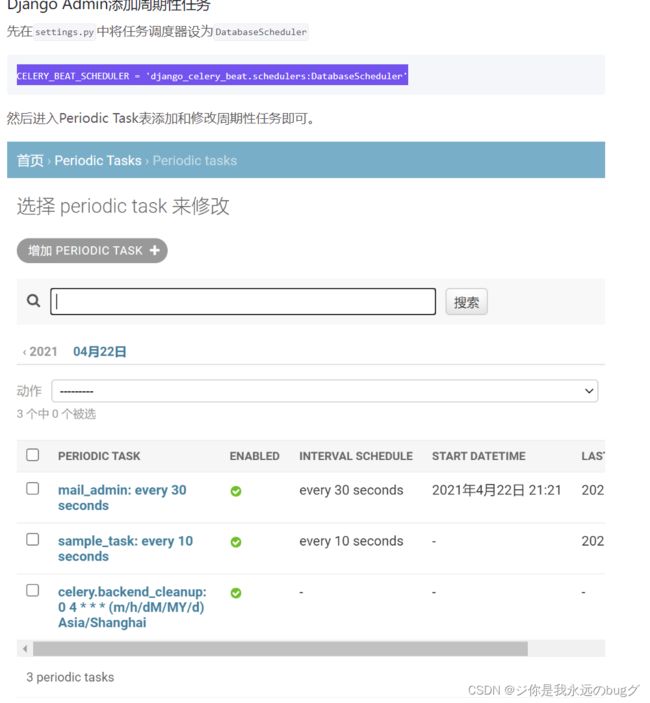
3、admin后台设置定时任务【未测】
1、先在settings.py中将任务调度器设为DatabaseScheduler
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
7、Flower监控任务执行状态【未测】
1、安装
pip install flower
2、启动
# 从terminal终端启动, proj为项目名
$ flower -A proj --port=5555
# 从celery启动
$ celery flower -A proj --address=127.0.0.1 --port=5555
3、打开网页
http://localhost:5555
8、给任务设置最大重试次数【未测】
定义任务时可以通过max_retries设置最大重试次数,并调用self.retry方法调用。因为要调用self这个参数,定义任务时必须设置bind=True。
@shared_task(bind=True, max_retries=3)
def send_batch_notifications(self):
try:
something_raising()
raise Exception('Can\'t send email.')
except Exception as exc:
self.retry(exc=exc, countdown=5)
send_mail(
subject='Batch email notifications',
message='Test email',
from_email='[email protected]',
recipient_list=['[email protected]']
)
9、不同任务由不同队列处理【未测】
不同的任务所需要的资源和时间不一样的。为了防止一些非常占用资源或耗时的任务阻塞任务队列导致一些简单任务也无法执行,可以将不同任务交由不同的Queue处理。下例定义了两个Queue队列,default执行普通任务,heavy_tasks执行重型任务。
CELERY_TASK_DEFAULT_QUEUE = 'default'
CELERY_TASK_DEFAULT_ROUTING_KEY = 'default'
CELERY_QUEUES = (
Queue('default', Exchange('default'), routing_key='default'),
Queue('heavy_tasks', Exchange('heavy_tasks'), routing_key='heavy_tasks'),
)
CELERY_TASK_ROUTES = {
'myapp.tasks.heave_tasks': 'heavy_tasks'
}
10、忽略 不想要的结果【未测】
如果你不在意任务的返回结果,可以设置 ignore_result 选项,因为存储结果耗费时间和资源。你还可以可以通过 task_ignore_result 设置全局忽略任务结果。
@app.task(ignore_result=True)
def my_task():
something()
11、避免启动同步子任务【未测】
让一个任务等待另外一个任务的返回结果是很低效的,并且如果工作单元池被耗尽的话这将会导致死锁。
下面:我们将不同的任务签名链接起来创建一个任务链,三个子任务按顺序执行。
def update_page_info(url):
# fetch_page -> parse_page -> store_page
chain = fetch_page.s(url) | parse_page.s() | store_page_info.s(url)
chain()
@app.task()
def fetch_page(url):
return myhttplib.get(url)
@app.task()
def parse_page(page):
return myparser.parse_document(page)
@app.task(ignore_result=True)
def store_page_info(info, url):
PageInfo.objects.create(url=url, info=info)
12、定时任务数据库的操作【事务回滚】【未测】
1、在 定时任务中进行查询数据
2、事务
我们再看另外一个celery中处理事务的例子。这是在数据库中创建一个文章对象的 Django 视图,此时传递主键给任务。它使用 commit_on_success 装饰器,当视图返回时该事务会被提交,当视图抛出异常时会进行回滚。
from django.db import transaction
@transaction.commit_on_success
def create_article(request):
article = Article.objects.create()
expand_abbreviations.delay(article.pk)
如果在事务提交之前任务已经开始执行会产生一个竞态条件;数据库对象还不存在。解决方案是使用 on_commit 回调函数来在所有事务提交成功后启动任务。
from django.db.transaction import on_commit
def create_article(request):
article = Article.objects.create()
on_commit(lambda: expand_abbreviations.delay(article.pk))
十二、Django日志 【未测】
1、日志基础
日志与我们的软件程序密不可分。它记录了程序的运行情况,可以给我们调试程序和故障排查提供非常有用的信息。每一条日志信息记录了一个事件的发生。具体而言,它包括了:
- 事件发生时间
- 事件发生位置
- 事件的严重程度–日志级别
- 事件内容
日志的级别又分为:
- DEBUG:用于调试目的的低级系统信息
- INFO:一般系统信息
- WARNING:描述已发生的小问题的警告信息。
- ERROR:描述已发生的主要问题的错误信息。
- CRITICAL:描述已发生的严重问题的信息。
在Django项目中,我们可以针对日志的不同级别设置不同的处理方式。比如INFO级别及以上的日志我们写入到log文件里保存,ERROR级别及以上的日志我们直接通过邮件发送给系统管理员。
2、配置
以下基本配置信息在django cookiecutter推荐使用的logging配置信息上做了修改,可适合大部分项目使用。如果真的希望发送和接收到邮件还需在settings.py正确配置电子邮箱Email。
# 给ADMINS发送邮件需要配置
ADMINS = (
('admin_name','[email protected]'),
)
MANAGERS = ADMINS
# 创建log文件的文件夹
LOG_DIR = os.path.join(BASE_DIR, "logs")
if not os.path.exists(LOG_DIR):
os.mkdir(LOG_DIR)
# 基本配置,可以复用的
LOGGING = {
"version": 1,
"disable_existing_loggers": False, # 禁用已经存在的logger实例
"filters": {"require_debug_false": {"()": "django.utils.log.RequireDebugFalse"}},
"formatters": { # 定义了两种日志格式
"verbose": { # 详细
"format": "%(levelname)s %(asctime)s %(module)s "
"%(process)d %(thread)d %(message)s"
},
'simple': { # 简单
'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
},
},
"handlers": { # 定义了三种日志处理方式
"mail_admins": { # 只有debug=False且Error级别以上发邮件给admin
"level": "ERROR",
"filters": ["require_debug_false"],
"class": "django.utils.log.AdminEmailHandler",
},
'file': { # 对INFO级别以上信息以日志文件形式保存
'level': "INFO",
'class': 'logging.handlers.RotatingFileHandler', # 滚动生成日志,切割
'filename': os.path.join(LOG_DIR,'django.log'), # 日志文件名
'maxBytes': 1024 * 1024 * 10, # 单个日志文件最大为10M
'backupCount': 5, # 日志备份文件最大数量
'formatter': 'simple', # 简单格式
'encoding': 'utf-8', # 放置中文乱码
},
"console": { # 打印到终端console
"level": "DEBUG",
"class": "logging.StreamHandler",
"formatter": "verbose",
},
},
"root": {"level": "INFO", "handlers": ["console"]},
"loggers": {
"django.request": { # Django的request发生error会自动记录
"handlers": ["mail_admins"],
"level": "ERROR",
"propagate": True, # 向不向更高级别的logger传递
},
"django.security.DisallowedHost": { # 对于不在 ALLOWED_HOSTS 中的请求不发送报错邮件
"level": "ERROR",
"handlers": ["console", "mail_admins"],
"propagate": True,
},
},
}
以上配置中大家最需要了解的就是Python提供的RotatingFileHandler, 其作用是滚动生成日志文件,当单个日志的文件大小达到上限时,会生成新的日志文件。当总的日志文件数量超过日志备份最大数量时删除老的日志文件。
十三、Django优化
1、数据库查询的优化
1、利用QuerySet的惰性和自带缓存的特性,避免重复查询
# 例1: 利用了缓存特性 - Good
article_list = Article.objects.filter(title__contains="django")
for article in article_list:
print(article.title)
2、我们只希望了解查询的结果是否存在或查询结果的数量,这时可以使用exists()和count()方法,如下所示。这样就不会浪费资源查询一个用不到的数据集,还可以节省内存。
# 例3: Good
article_list = Article.objects.filter(title__contains="django")
if article_list.exists():
print("Records found.")
else:
print("No records")
# 例4: Good
count = Article.objects.filter(title__contains="django").count()
3、我们可以使用select_related方法和prefetch_related方法一次性从数据库获取单对多和多对多关联模型数据,
# 一次性提取关联模型数据 - Good
def article_list(request):
articles = Article.objects.all().select_related('category').prefecth_related('tags')
return render(request, 'blog/article_list.html', {'articles': articles, })
4、仅查询需要用到的数据
# 例子6: Good - 字典格式数据
article_list = Article.objects.values('id', 'title')
if article_list:
print(article.title)
# 例子7: Good - 元组格式数据
article_list = Article.objects.values_list('id', 'title')
if article_list:
print(article.title)
# 例子8: Good - 列表格式数据
article_list = Article.objects.values_list('id', 'title', flat=True)
2、数据库设置
- 建立模型时能用CharField确定长度的字段尽量不用不用TextField, 可节省存储空间;
- 可以给搜索频率高的字段属性,在定义模型时使用索引(db_index=True);
- 持久化数据库连接。
设置持久化连接时间,仅需要添加CONN_MAX_AGE参数到你的数据库设置中,如下所示:
DATABASES = {
‘default’: {
‘ENGINE’: ‘django.db.backends.postgresql_psycopg2’,
‘NAME’: ‘postgres’,
‘CONN_MAX_AGE’: 60, # 60秒
}
}
十四、Django +RestFul风格的API框架
Django REST framework 给Django提供了用于构建Web API 的强大而灵活的工具包, 包括序列化器、认证、权限、分页、过滤和限流
1、安装配置
pip install djangorestframework
将resf 注册进 django
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'app01.apps.App01Config',
'django_celery_results',
'django_celery_beat'
]
2、序列化
将属于自己语言的数据类型或对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML、JSON或特定格式的字节串)的过程称为序列化(seralization);反之则称为反序列化。
2.1、python数据序列化
import json
dumps = json.dumps({'a':"v"})
print(dumps)
2.2、Django查询集序列化
使用Django自带的serializers类也可以轻易将QuerySet格式的数据转化为json格式。
from django.core import serializers
def selete(request):
if request.GET != '':
name = request.GET.get("name")
data_list = {'name': name}
data1 = serializers.serialize("json", App01Userinfo.objects.filter(**data_list))
print(data1)
return HttpResponse("查询成功", data1)
else:
return HttpResponse("errrr")
![]()
2.3、Django Rest Framework【DRF】才是真正需要的序列化工具
3、 Rest Framework
3.1、什么是restful的API
简单来说,就是用 URL表示资源,GET,POST,PUT,DELETE表示增删改查
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
DELETE(DELETE):从服务器删除资源。
3.2、请求状态码
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功
202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误
4、DRF提供的序列化器开发API接口并测试。
4.1、接口表述
接口描述:文章列表资源。GET请求获取文章列表资源, POST请求提交新文章
接口地址: http://127.0.0.1:8000/api/v1/articles
请求方式:GET, POST
返回参数:JSON格式文章列表和状态码
接口描述:单篇文章资源。GET获取文章详情, PUT修改,DELETE删除
接口地址: http://127.0.0.1:8000/api/v1/articles/{id}
请求方式:GET, PUT, DELETE
返回参数: GET和PUT(JSON格式文章详情和状态码), DELETE(状态码)
4.2、创建模型
用于存储我们博客的文章数据。用户(User)与文章(Article)是单对多的关系(ForeinKey),因为一个用户可以发表多篇文章。为了方便,用户模型我们使用了Django自带的用户模型。
# This is an auto-generated Django model module.
# You'll have to do the following manually to clean this up:
# * Rearrange models' order
# * Make sure each model has one field with primary_key=True
# * Make sure each ForeignKey and OneToOneField has `on_delete` set to the desired behavior
# * Remove `managed = False` lines if you wish to allow Django to create, modify, and delete the table
# Feel free to rename the models, but don't rename db_table values or field names.
from django.db import models
class App01Userinfo(models.Model):
id = models.BigAutoField(primary_key=True)
name = models.CharField(max_length=32, blank=True, null=True)
class Meta:
managed = False
db_table = 'app01_userinfo'
from django.db import models
from django.utils.translation import ugettext_lazy as _
from django.contrib.auth import get_user_model
User = get_user_model()
class Article(models.Model):
"""Article Model"""
STATUS_CHOICES = (
('p', _('Published')),
('d', _('Draft')),
)
title = models.CharField(verbose_name=_('Title (*)'), max_length=90, db_index=True)
body = models.TextField(verbose_name=_('Body'), blank=True)
author = models.ForeignKey(User, verbose_name=_('Author'), on_delete=models.CASCADE, related_name='articles')
status = models.CharField(_('Status (*)'), max_length=1, choices=STATUS_CHOICES, default='s', null=True, blank=True)
create_date = models.DateTimeField(verbose_name=_('Create Date'), auto_now_add=True)
def __str__(self):
return self.title
class Meta:
ordering = ['-create_date']
verbose_name = "Article"
verbose_name_plural = "Articles"
执行命令,同步数据并创建超级用户
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser
4.3、配置Django后台(admin)
admin文件的配置可以参考
编写app01下的admin文件
# 登记Models
from django.contrib import admin
from .models import Article
# Register your models here.
class ArticleAdmin(admin.ModelAdmin):
# 展示页面展示的字段
list_display = ('title', 'author', 'status', 'body','create_date')
'''filter options'''
list_filter = ('status',)
'''10 items per page'''
list_per_page = 10
admin.site.register(Article, ArticleAdmin)
运行项目进入管理员后台页面
新建的 app01下的 articles点击进去

也可以进行修改删除等操作
4.4、自定义序列化器
利用DRF开发Web API的第一步总是自定义序列化器(serializers)。序列化器的作用是将模型实例(比如用户、文章)序列化和反序列化为诸如json之类的表示形式。
一个模型实例可能有许多字段属性,但一般情况下你不需要把所有字段信息以JSON格式数据返回给用户。序列化器定义了需要对一个模型实例的哪些字段进行序列化/反序列化, 并可对客户端发送过来的数据进行验证和存储。
使用 ModelSerializer 类自定义序列化器
app01下 创建 serializers.py文件
from rest_framework import serializers
from .models import Article
from django.contrib.auth import get_user_model
"""
自定义序列化器
REST framework提供了Serializer类和ModelSerializer类两种方式供你自定义序列化器。
前者需手动指定需要序列化和反序列化的字段,
后者根据模型(model)生成需要序列化和反序列化的字段,可以使代码更简洁
"""
User = get_user_model()
class ArticleSerializer(serializers.ModelSerializer):
# 希望author不可见并让DRF根据request.user自动补全这个字段
author = serializers.HiddenField(default=serializers.CurrentUserDefault())
class Meta:
model = Article
fields = '__all__'
read_only_fields = ('id', 'author', 'create_date')
** author = serializers.HiddenField(default=serializers.CurrentUserDefault()**
这个 可以在返回的字段中,隐藏该字段
标识只读字段:read_only_fields ,
ID和create_date都是由模型自动生成,每个article的author我们也希望在视图中与request.user绑定,而不是由用户通过POST或PUT自行修改,所以这些字段都是read-only。相反title,body和status是用户可以添加或修改的字段,所以未设成read-only。
编写 API视图
from rest_framework import status
from rest_framework.decorators import api_view
from rest_framework.response import Response
from .models import Article
from .serializers import ArticleSerializer
@api_view(['GET', 'POST'])
def article_list(request):
"""
List all articles, or create a new article.
"""
if request.method == 'GET':
articles = Article.objects.all()
serializer = ArticleSerializer(articles, many=True)
return Response(serializer.data)
elif request.method == 'POST':
serializer = ArticleSerializer(data=request.data)
if serializer.is_valid():
# 由于序列化器中author是read-only字段,用户是无法通过POST提交来修改的,我们在创建Article实例时需手动将author和request.user绑定
serializer.save(author=request.user)
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
主要 注解: @api_view([‘GET’,‘POST’])
1、限制了请求的方式,
2、请求参数 一律通过 request.data
3、响应通过 Response方法。
5、基于类的视图
参考:视图类的关系
从高到低的继承关系如下

前言: 一个中大型的Web项目代码量通常是非常大的,使用类视图可以有效的提高代码复用,减少重复造轮子的工作。
DRF推荐使用基于类的视图(CBV)来开发API, 并提供了4种开发CBV开发模式。
- 使用基础的APIView类
- 使用Mixins类和GenericAPI类混配
- 使用通用视图generics.*类, 比如generics.ListCreateAPIView
- 使用视图集ViewSet和ModelViewSet
5.1、基于APIView
DRF的APIView类继承了Django自带的View类, 一样可以按请求方法调用不同的处理函数,比如get方法处理GET请求,post方法处理POST请求。
不过DRF的APIView要强大得多。它不仅支持更多请求方法,而且对Django的request对象进行了封装,可以使用request.data获取用户通过POST, PUT和PATCH方法发过来的数据,而且支持插拔式地配置认证、权限和限流类。
from rest_framework.views import APIView
from django.http import Http404
from .models import Article
from .serializers import ArticleSerializer
class ArticleList(APIView):
"""
List all articles, or create a new article.
"""
def get(self, request, format=None):
articles = Article.objects.all()
serializer = ArticleSerializer(articles, many=True)
return Response(serializer.data)
def post(self, request, format=None):
serializer = ArticleSerializer(data=request.data)
if serializer.is_valid():
# 注意:手动将request.user与author绑定
serializer.save(author=request.user)
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
class ArticleDetail(APIView):
"""
Retrieve, update or delete an article instance.
"""
def get_object(self, pk):
try:
return Article.objects.get(pk=pk)
except Article.DoesNotExist:
raise Http404
def get(self, request, pk, format=None):
article = self.get_object(pk)
serializer = ArticleSerializer(article)
return Response(serializer.data)
def put(self, request, pk, format=None):
article = self.get_object(pk)
serializer = ArticleSerializer(instance=article, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
def delete(self, request, pk, format=None):
article = self.get_object(pk)
article.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
和之前的代码差别不大,最大的不同是不需要对请求的方式进行判断,该视图可以自动将不同的请求转发到相应的处理方法上。
此时,定义的url路由需要调用 as_view()方法
path('articles', views.ArticleList.as_view()),
5.2、用Mixin类和 GenericAPI类混用
使用 基础的PIView类并没有大量简化我们的代码,
对于通用的增删改查行为,DRF提供了相应的Mixin类。Mixin类可与generics.GenericAPI类联用,灵活组成你所需要的视图。
如下:
from rest_framework import mixins
from rest_framework import generics
class ArticleList1(mixins.ListModelMixin, # .list方法获取列表
mixins.CreateModelMixin, # .create 方法创建
mixins.UpdateModelMixin,# .update方法更新
mixins.RetrieveModelMixin, # .retrieve 方法查询单个
mixins.DestroyModelMixin,# .destroy方法 删除单个
generics.GenericAPIView):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
def get(self,request,*args,**kwargs):
return self.list(request,*args,**kwargs)
def post(self,request,*args,**kwargs):
return self.create(request,*args,**kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
# 希望在创建article实例时我们将author与request.user进行手动绑定。
# 在前面的例子中我们使用serializer.save(author=request.user)这一方法进行手动绑定。
# 现在使用mixin类后,我们该如何操作呢? 答案是重写perform_create方法
# 将request.user与author绑定。调用create方法时执行如下函数。
def perform_create(self, serializer):
serializer.save(author=self.request.user)
GenericAPIView 类继承了APIView类,提供了基础的API视图。它对用户请求进行了转发,并对Django自带的request对象进行了封装。不过它比APIView类更强大,因为它还可以通过queryset和serializer_class属性指定需要序列化与反序列化的模型或queryset及所用到的序列化器类。
这里的 ListModelMixin 和 CreateModelMixin类则分别引入了.list() 和 .create() 方法,当用户发送get请求时调用Mixin提供的list()方法,将指定queryset序列化后输出,发送post请求时调用Mixin提供的create()方法,创建新的实例对象。
DRF还提供RetrieveModelMixin, UpdateModelMixin和DestroyModelMixin类,实现了对单个对象实例的查、改和删操作
修改对应的 URL路由地址
** path(‘articles’, views.ArticleList1.as_view()),**
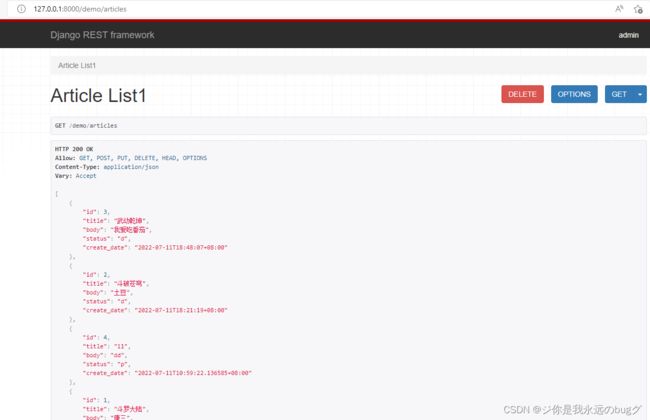
5.3、使用通用视图 Generics.*类
将Mixin类和GenericAPI类混配,已经帮助我们减少了一些代码,但我们还可以做得更好,比如将get请求与mixin提供的list方法进行绑定感觉有些多余。幸好DRF还提供了一套常用的将 Mixin 类与 GenericAPI类已经组合好了的视图,开箱即用,可以进一步简化我们的代码,如下
class ArticleList2(generics.ListCreateAPIView):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
# 将request.user与author绑定
def perform_create(self, serializer):
serializer.save(author=self.request.user)
class ArticleDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
顾名思义,generics.ListCreateAPIView类支持List、Create两种视图功能,分别对应GET和POST请求。generics.RetrieveUpdateDestroyAPIView支持Retrieve、Update、Destroy操作,其对应方法分别是GET、PUT和DELETE。
其它常用generics类视图还包括ListAPIView, RetrieveAPIView, RetrieveUpdateAPIView等等。你可以根据实际需求使用,为你的API写视图时只需要定义queryset和serializer_class即可。
5.4、视图集ViewSet
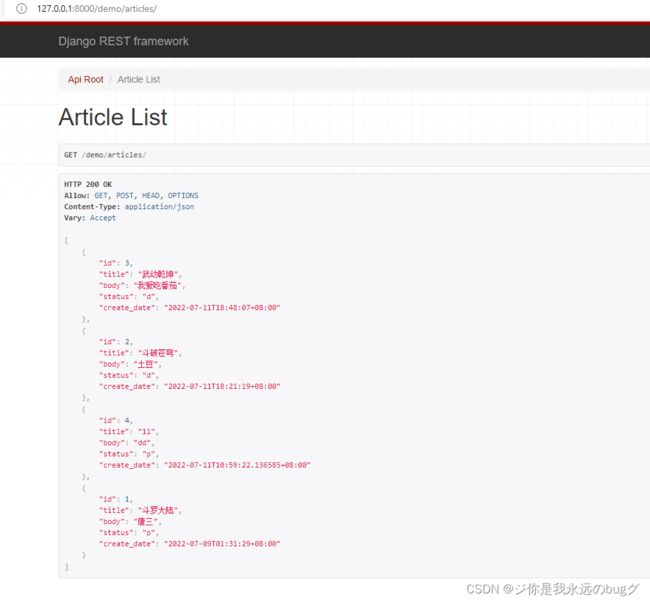
使用通用视图generics类后视图代码已经大大简化,但是ArticleList和ArticleDetail两个类中queryset和serializer_class属性依然存在代码重复。使用视图集可以将两个类视图进一步合并,一次性提供List、Create、Retrieve、Update、Destroy这5种常见操作,这样queryset和seralizer_class属性也只需定义一次就好, 这就变成了视图集(viewset)。
from rest_framework import viewsets
class ArticleViewSet(viewsets.ModelViewSet):
# 用一个视图集替代ArticleList和ArticleDetail两个视图
queryset = Article.objects.all()
serializer_class = ArticleSerializer
# 自行添加,将request.user与author绑定
def perform_create(self, serializer):
serializer.save(author=self.request.user)
使用视图集后,我们需要使用DRF提供的路由router来分发urls,因为一个视图集现在对应多个urls,而不像之前的一个url对应一个视图函数或一个视图类。
# 指定当前 app的命名
from django.urls import path
from app01 import views
from app01.views import Indec
from rest_framework.urlpatterns import format_suffix_patterns
from rest_framework.routers import DefaultRouter
app_name = "app01"
router = DefaultRouter()
router.register(r'articles',viewset=views.ArticleViewSet)
urlpatterns = [
# path('admin/', admin.site.urls),
path('index', Indec.as_view()),
path('getUserList', views.getUserList),
path('startRequest', views.startRequest),
path('add', views.add),
path('del', views.delete),
path('update', views.update),
path('selete', views.selete),
]
# urlpatterns = format_suffix_patterns(urlpatterns)
urlpatterns += router.urls
此时我们不需要再path中设置路由 ,而是在 router中定义路由对应的 set
你或许又要问了,一个视图集对应List、Create、Retrieve、Update、Destroy这5种操作。有时候我只需要其中的一种或几种操作,该如何实现呢?答案是在urls.py中指定方法映射即可,如下所示:
from django.urls import re_path
from rest_framework.urlpatterns import format_suffix_patterns
from . import views
# from rest_framework.routers import DefaultRouter
# router = DefaultRouter()
# router.register(r'articles', viewset=views.ArticleViewSet)
article_list = views.ArticleViewSet.as_view(
{
'get': 'list',
'post': 'create'
})
article_detail = views.ArticleViewSet.as_view({
'get': 'retrieve', # 只处理get请求,获取单个记录
})
urlpatterns = [
re_path(r'^articles/$', article_list),
re_path(r'^articles/(?P[0-9]+)$' , article_detail),
]
urlpatterns = format_suffix_patterns(urlpatterns)
另外DRF还提供了ReadOnlyModelViewSet这个类,它仅支持list和retrive这两个可读的操作,如下所示:
from rest_framework import viewsets
class UserViewSet(viewsets.ReadOnlyModelViewSet):
"""
ReadOnlyModelViewSet仅提供list和detail可读动作
"""
queryset = Article.objects.all()
serializer_class = ArticleSerializer
5.5 、GenericViewSet
支持类似 MyViewSet.as_view({‘get’: ‘list’, ‘post’: ‘create’}) 的动态绑定功能,或者由router.register进行注册
如果需要重构原有的FBV,建议使用GenericAPIView,改动小、变动少
.
‘get’: ‘lists’:其中 get 是请求方式,lists 是具体方法的名字
router = DefaultRouter()
# 当viewset中没有定义queryset字段时在路由的注册必须加上basename:
router.register('books',BookView,basename="title")
book_list = BookView.as_view({
'get': 'lists',
})
# django_crud 小应用
re_path('^books/$',book_list),
urlpatterns += router.urls
view:
class BookView(GenericViewSet):
serializer_class = ArticleSerializer
def get_queryset(self):
queryset = Article.objects.all()
title = self.request.query_params.get('title', None)
if title is not None:
queryset = Article.objects.filter(title=title).all()
return queryset
def lists(self, request, *args, **kwargs):
queryset = self.get_queryset()
bs = self.get_serializer(queryset, many=True)
return Response(bs.data)
5.7、总结:
- 基础的API类:可读性最高、代码最多、灵活性最高。当你需要对的API行为进行个性化定制时,建议使用这种方式。
- 通用generics类:可读性好、代码适中、灵活性较高。当你需要对一个模型进行标准的增删查改全部或部分操作时建议使用这种方式。
- 使用视图集viewset: 可读性较低、代码最少、灵活性最低。当你需要对一个模型进行标准的增删查改的全部操作且不需定制API行为时建议使用这种方式。
6、玩转序列化【改变输出内容】
在本文中,我们将玩转DRF的序列化器,教你如何修改序列化器,控制序列化后响应数据的输出格式, 如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何动态加载或重写序列化器类自带的方法。
6.1、准备工作
我们 Article模型和自定义序列化器 ArticleSerializer 类分别如下所示
class Article(models.Model):
"""Article Model"""
STATUS_CHOICES = (
('p', _('Published')),
('d', _('Draft')),
)
title = models.CharField(verbose_name=_('Title (*)'), max_length=90, db_index=True)
body = models.TextField(verbose_name=_('Body'), blank=True)
author = models.ForeignKey(User, verbose_name=_('Author'), on_delete=models.CASCADE, related_name='articles')
status = models.CharField(_('Status (*)'), max_length=1, choices=STATUS_CHOICES, default='s', null=True, blank=True)
create_date = models.DateTimeField(verbose_name=_('Create Date'), auto_now_add=True)
def __str__(self):
return self.title
class Meta:
ordering = ['-create_date']
verbose_name = "Article"
verbose_name_plural = "Articles"
from rest_framework import serializers
from .models import Article
from django.contrib.auth import get_user_model
"""
自定义序列化器
REST framework提供了Serializer类和ModelSerializer类两种方式供你自定义序列化器。
前者需手动指定需要序列化和反序列化的字段,
后者根据模型(model)生成需要序列化和反序列化的字段,可以使代码更简洁
"""
User = get_user_model()
class ArticleSerializer(serializers.ModelSerializer):
# 希望author不可见并让DRF根据request.user自动补全这个字段
# author = serializers.HiddenField(default=serializers.CurrentUserDefault())
class Meta:
model = Article
fields = '__all__'
read_only_fields = ('id', 'author', 'create_date')
此时输出结果:

在这里你可以看到序列化后输出的json格式数据里author字段输出的是用户id,而不是用户名,status输出的是p或者d,而不是输出Published或Draft这样的完整状态,这显然对用户不是很友好的。这时我们就要修改序列化器,改变序列化后的数据输出格式,接下来我们将介绍几种常用的方式。
6.2、指定 source 来源【增加返回数据】
我们在返回的结果中获取 作者的name 和 状态的全拼而不是首字母
首先在mdels中 我们定义了status 的对应关系
STATUS_CHOICES = (
('p', _('Published')),
('d', _('Draft')),
)
title = models.CharField(verbose_name=_('Title (*)'), max_length=90, db_index=True)
body = models.TextField(verbose_name=_('Body'), blank=True)
author = models.ForeignKey(User, verbose_name=_('Author'), on_delete=models.CASCADE, related_name='articles')
status = models.CharField(_('Status (*)'), max_length=1, choices=STATUS_CHOICES, default='s', null=True, blank=True)
create_date = models.DateTimeField(verbose_name=_('Create Date'), auto_now_add=True)
然后我们要在 序列化文件中 设置
**注意:**不要用和models中定义的字段相同,否则就是覆盖。
from rest_framework import serializers
from .models import Article
from django.contrib.auth import get_user_model
"""
自定义序列化器
REST framework提供了Serializer类和ModelSerializer类两种方式供你自定义序列化器。
前者需手动指定需要序列化和反序列化的字段,
后者根据模型(model)生成需要序列化和反序列化的字段,可以使代码更简洁
"""
User = get_user_model()
class ArticleSerializer(serializers.ModelSerializer):
# 希望author不可见并让DRF根据request.user自动补全这个字段
# author = serializers.HiddenField(default=serializers.CurrentUserDefault())
author_name = serializers.ReadOnlyField(source='author.username')
full_status = serializers.ReadOnlyField(source='get_status_display')
class Meta:
model = Article
fields = '__all__'
read_only_fields = ('id', 'author', 'create_date')
author_name = serializers.ReadOnlyField(source='author.username')
增加返回字段:author_name,对应的是 auth_user的username

full_status = serializers.ReadOnlyField(source='get_status_display')
增加返回字段:full_status :status字段为get_status_display方法返回的完整状态。
结果:

6.3、逻辑判断后输出字段
上述的字段为 Published或Draft标识,现想要增加字段cn_status用中文标识状态。
可以使用 SerializerMethodField
它可用于将任何类型的数据添加到对象的序列化表示中, 非常有用。
用法:
from rest_framework import serializers
from .models import Article
from django.contrib.auth import get_user_model
"""
自定义序列化器
REST framework提供了Serializer类和ModelSerializer类两种方式供你自定义序列化器。
前者需手动指定需要序列化和反序列化的字段,
后者根据模型(model)生成需要序列化和反序列化的字段,可以使代码更简洁
"""
User = get_user_model()
class ArticleSerializer(serializers.ModelSerializer):
# 希望author不可见并让DRF根据request.user自动补全这个字段
# author = serializers.HiddenField(default=serializers.CurrentUserDefault())
author_name = serializers.ReadOnlyField(source='author.username')
full_status = serializers.ReadOnlyField(source='get_status_display')
cn_status = serializers.SerializerMethodField()
class Meta:
model = Article
fields = '__all__'
read_only_fields = ('id', 'author', 'create_date')
def get_cn_status(self,obj):
if obj.status == 'p':
return "已发表"
elif obj.status == 'd':
return "草稿"
else:
return ''
结果:

不过需要注意的是SerializerMethodField通常用于显示模型中原本不存在的字段,类似可读字段,你不能通过反序列化对其直接进行修改。
6.4、使用嵌套序列化器【嵌套参数】
上述的 author 对应的是超管表的id ,是另一张表,如果要嵌套展示可以这样:
from rest_framework import serializers
from .models import Article
from django.contrib.auth import get_user_model
"""
自定义序列化器
REST framework提供了Serializer类和ModelSerializer类两种方式供你自定义序列化器。
前者需手动指定需要序列化和反序列化的字段,
后者根据模型(model)生成需要序列化和反序列化的字段,可以使代码更简洁
"""
User = get_user_model()
# 定义 User 的序列化器
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ('id', 'username', 'email')
class ArticleSerializer(serializers.ModelSerializer):
# 希望author不可见并让DRF根据request.user自动补全这个字段
# author = serializers.HiddenField(default=serializers.CurrentUserDefault())
author_name = serializers.ReadOnlyField(source='author.username')
author = UserSerializer(read_only=True) # required=False表示可接受匿名用户,many=True表示有多个用户。
full_status = serializers.ReadOnlyField(source='get_status_display')
cn_status = serializers.SerializerMethodField()
class Meta:
model = Article
fields = '__all__'
read_only_fields = ('id', 'author', 'create_date')
def get_cn_status(self,obj):
if obj.status == 'p':
return "已发表"
elif obj.status == 'd':
return "草稿"
else:
return ''
结果:

6.5、前面我们介绍的都是如何通过修改序列化器来控制输出数据的展现形式。下面我们将着重看下如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何重写序列化类自带的的save和update方法。
6.6、关系序列化【查用户下有哪些文章】
前面我们对文章模型进行了序列化,显示了每篇文章详情及其对应作者信息。这个很好理解,因为author本来就是Article模型中的一个字段。现在反过来要对用户信息进行序列化,要求返回信息里包含用户信息及所发表的文章列表,但用户User模型没有article这个字段,这时应该怎么做呢?
答案就是使用Django REST Framework提供的关系序列化方法。
前置条件:
view
#使用视图集ViewSet
class UserViewSet(viewsets.ModelViewSet):
#
queryset = User.objects.all()
serializer_class = UserSerializer
urls
router.register(r'user',viewset=views.UserViewSet)
1、获取用户下的 文章 id
定义 user序列化
# 定义 User 的序列化器
class UserSerializer(serializers.ModelSerializer):
articles = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ('id', 'username', 'articles',)
read_only_fields = ('id', 'username',)
结果:

2、获取用户下的文章的标题
# 定义 User 的序列化器
class UserSerializer(serializers.ModelSerializer):
articles = serializers.StringRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ('id', 'username', 'articles',)
read_only_fields = ('id', 'username',)
StringRelatedField 会直接返回 models中 文章对象 的_str_对应的字段
def __str__(self):
return self.title

6.7、数据验证【未验证】
6.7.1、字段级别验证
在序列化器中
from rest_framework import serializers
class ArticleSerializer(serializers.Serializer):
title = serializers.CharField(max_length=100)
def validate_title(self, value):
"""
Check that the article is about Django.
"""
if 'django' not in value.lower():
raise serializers.ValidationError("Article is not about Django")
return value
6.7.2、对象级别验证
from rest_framework import serializers
class EventSerializer(serializers.Serializer):
description = serializers.CharField(max_length=100)
start = serializers.DateTimeField()
finish = serializers.DateTimeField()
def validate(self, data):
"""
Check that the start is before the stop.
"""
if data['start'] > data['finish']:
raise serializers.ValidationError("finish must occur after start")
return data
6.7.3、验证器
序列化器上的各个字段都可以包含验证器,通过在字段实例上声明,例如:
def title_gt_90(value):
if len(value) < 90:
raise serializers.ValidationError('标题字符长度不低于90。')
class Article(serializers.Serializer):
title = seralizers.CharField(validators=[title_gt_90])
...
DRF还提供了很多可重用的验证器,比如UniqueValidator,UniqueTogetherValidator等等。通过在内部 Meta 类上声明来包含这些验证器,如下所示。下例中会议房间号和日期的组合必须要是独一无二的。
class EventSerializer(serializers.Serializer):
name = serializers.CharField()
room_number = serializers.IntegerField(choices=[101, 102, 103, 201])
date = serializers.DateField()
class Meta:
# Each room only has one event per day.
validators = UniqueTogetherValidator(
queryset=Event.objects.all(),
fields=['room_number', 'date']
)
6.7.4、重写序列化器的create和update方法
假设我们有个Profile模型与User模型是一对一的关系,当用户注册时我们希望把用户提交的数据分别存入User和Profile模型,这时我们就不得不重写序列化器自带的create方法了。下例演示了如何通过一个序列化器创建两个模型对象。
class UserSerializer(serializers.ModelSerializer):
profile = ProfileSerializer()
class Meta:
model = User
fields = ('username', 'email', 'profile')
def create(self, validated_data):
profile_data = validated_data.pop('profile')
user = User.objects.create(**validated_data)
Profile.objects.create(user=user, **profile_data)
return user
同时更新两个关联模型实例时也同样需要重写update方法。
def update(self, instance, validated_data):
profile_data = validated_data.pop('profile')
profile = instance.profile
instance.username = validated_data.get('username', instance.username)
instance.email = validated_data.get('email', instance.email)
instance.save()
profile.is_premium_member = profile_data.get(
'is_premium_member',
profile.is_premium_member
)
profile.has_support_contract = profile_data.get(
'has_support_contract',
profile.has_support_contract
)
profile.save()
return instance
因为序列化器使用嵌套后,创建和更新的行为可能不明确,并且可能需要相关模型之间的复杂依赖关系,REST framework要求你始终显式的编写这些方法。默认的 ModelSerializer .create() 和 .update() 方法不包括对可写嵌套表示的支持,所以我们总是需要对create和update方法进行重写
6.7.4、动态加载序列化器类
有时你在类视里不希望通过通过serializer_class指定固定的序列化器类,而是希望动态的加载序列化器,你可以重写get_serializer_class方法,如下所示:
class UserViewSet(CreateModelMixin,
RetrieveModelMixin,UpdateModelMixin,viewsets.GenericViewSet):
# 这个就不需要了
#serializer_class = XXXSerializer
def get_serializer_class(self):
if self.action == 'create':
return CustomSerializer1
elif self.action == 'list':
return XXXSerializer
return CustomSerializer1
6.7、总结
- 改变序列化输出数据的格式可以通过指定字段的source来源,使用SerializerMethodField和to_representation方法以及使用嵌套序列化器。
- 反序列化时需要对客户端发送的数据进行验证。你可以通过自定义validate方法进行字段或对象级别的验证,你还可以使用自定义的validators或DRF自带的验证器。
- 当你使用嵌套序列化器后,多个关联模型的创建和更新的行为并不明确,你需要显示地重写create和update方法。
十五、Django 权限详解
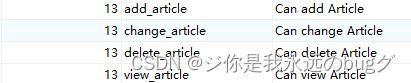
15.1、Django默认的权限
Django的权限permission本质是djang.contrib.auth中的一个模型, 其与User的user_permissions字段是多对多的关系。当我们在INSTALLED_APP里添加好auth应用之后,Django就会为每一个你安装的app中的模型(Model)自动创建4个可选的权限:view, add,change和delete
数据库表:
15.2、新增自定义权限
Django 默认的四个权限 有时不能满足需求,需要自定义权限,有两种方式
方法1、在 model 的 meta属性添加权限
class Article(models.Model):
...
class Meta:
permissions = (
("publish_article", "Can publish article"),
("comment_article", "Can comment article"),
)
方法2. 使用ContentType程序化创建权限
from app01.models import Article
from django.contrib.auth.models import Permission
from django.contrib.contenttypes.models import ContentType
content_type = ContentType.objects.get_for_model(article)
permission1 = Permission.objects.create(
codename='publish_article',
name='Can publish articles',
content_type=content_type,
)
permission2 = Permission.objects.create(
codename='comment_article',
name='Can comment articles',
content_type=content_type,
)
执行:
python manage.py makemigrations
python manage.py migrate
看库表:
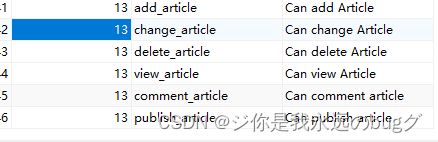
15.2.1、判断当前用户是否有该权限
has_perm = self.request.user.has_perm('app01.view_article')
15.2.2、查看用户所在的组的权限
permissions = self.request.user.get_group_permissions()
15.2.3、查看用户所有权限
all_permissions = self.request.user.get_all_permissions()
15.2.4、分配用户权限
myuser.user_permissions.add(permission1, permission2, ...)
15.2.5、通过用户组给用户增加权限
mygroup.permissions.add(permission1, permission2, ...)
15.2.6、移除用户权限
myuser.user_permissions.remove(permission1, permission2, ...)
myuser.user_permissions.clear()
15.3、用户权限认证
15.3.1、@permission_required
from django.contrib.auth.mixins import PermissionRequiredMixin
class MyView(PermissionRequiredMixin, View):
permission_required = 'polls.can_vote'
# Or multiple of permissions:
permission_required = ('polls.can_open', 'polls.can_edit')
from django.utils.decorators import method_decorator
from django.core.urlresolvers import reverse_lazy
from django.contrib.auth.decorators import user_passes_test
@method_decorator(user_passes_test(lambda u: Group.objects.get(name='admin') in u.groups.all()),name='dispatch')
class ItemDelete(DeleteView):
model = Item
success_url = reverse_lazy('items:index')
15.4、用户组
用户组(Group)和User模型是多对多的关系。其作用在权限控制时可以批量对用户的权限进行管理和分配,而不用一个一个用户分配,节省工作量。将一个用户加入到一个Group中后,该用户就拥有了该Group所分配的所有权限。例如,如果一个用户组editors有权限change_article, 那么所有属于editors组的用户都会有这个权限。
将用户添加到用户组或者给用户组(group)添加权限,一般建议直接通过django admin进行。如果你希望手动给group添加或删除权限,你可以使用如下方法:
mygroup.permissions = [permission_list]
mygroup.permissions.add(permission1, permission2, ...)
mygroup.permissions.remove(permission1, permission2, ...)
mygroup.permissions.clear()
如果你要将某个用户移除某个用户组,可以使用如下方法:
myuser.groups.remove(group1, group2, ...)
myuser.groups.clear()
15.5、Django自带权限的不足
Django自带的权限机制是针对模型的,这就意味着一个用户如果对Article模型有change的权限,那么该用户获得对所有文章对象进行修改的权限。如果我们对单个文章对象的权限管理,Django是做不到的
十六、Django-restful权限认证
16.1、DRF自带权限类
REST framework 包含许多默认权限类,我们可以用来限制谁可以访问给定的视图
如:只有身份认证通过的人才能访问 :permission_classes = [IsAuthenticated]
from rest_framework.permissions import *
class BookView(GenericViewSet):
serializer_class = ArticleSerializer
permission_classes = [IsAuthenticated]
def get_queryset(self):
queryset = Article.objects.all()
title = self.request.query_params.get('title', None)
if title is not None:
queryset = Article.objects.filter(title=title).all()
return queryset
def lists(self, request, *args, **kwargs):
queryset = self.get_queryset()
bs = self.get_serializer(queryset, many=True)
return Response(bs.data)
调用接口:

除了 IsAuthenticated 类,DRF自带的常用权限类还包括 :
IsAuthenticatedOrReadOnly 类:确保经过身份验证的请求获得读写访问权限,未经身份验证的请求将获得只读读的权限。
AllowAny类:允许任何用户访问;
IsAdminUser类:仅限管理员访问;
DjangoModelPermissions类:只有在用户经过身份验证并分配了相关模型权限时,才会获得授权访问相关模型。
DjangoModelPermissionsOrReadOnly类:与前者类似,但可以给匿名用户访问API的可读权限。
DjangoObjectPermissions类:只有在用户经过身份验证并分配了相关对象权限时,才会获得授权访问相关对象。通常与django-gaurdian联用实现对象级别的权限控制。
16.2、DRF-自定义权限
定义的权限类需要继承BasePermission类并根据需求重写has_permission(self,request,view)和has_object_permission(self,request, view, obj)方法。你还可以通过message自定义返回的错误信息。
from rest_framework import permissions
class CustomerPermission(permissions.BasePermission):
message = 'You have not permissions to do this.'
def has_permission(self, request, view):
...
def has_object_permission(self, request, view, obj):
示例:
首先我们在blog文件夹下创建permissions.py,添加如下代码:
# blog/permissions.py
from rest_framework import permissions
class IsOwnerOrReadOnly(permissions.BasePermission):
"""
自定义权限只允许对象的创建者才能编辑它。"""
def has_object_permission(self, request, view, obj):
# 读取权限被允许用于任何请求,
# 所以我们始终允许 GET,HEAD 或 OPTIONS 请求。
if request.method in permissions.SAFE_METHODS:
return True
# 写入权限只允许给 article 的作者。
return obj.author == request.user
修改我们的视图
permission_classes = (IsOwnerOrReadOnly)
十七、simplejwt Token 认证
认证: 通过用户名密码或token 验证用户身份
权限: 认证后,根据用户的权限对用户的操作进行授权
7.1、安装
pip install djangorestframework-simplejwt
7.2、配置路由
获取和刷新token的urls地址
from rest_framework_simplejwt.views import (
TokenObtainPairView,
TokenRefreshView,
)
urlpatterns = [
# path('admin/', admin.site.urls),
path('index', Indec.as_view()),
path('getUserList', views.getUserList),
path('startRequest', views.startRequest),
path('add', views.add),
path('del', views.delete),
path('update', views.update),
path('selete', views.selete),
path('articles2', views.ArticleList2.as_view()),
path('token', TokenObtainPairView.as_view(), name='token_obtain_pair'),
path('token/refresh', TokenRefreshView.as_view(), name='token_refresh'),
]
urlpatterns += router.urls
7.3、postman测试
1、获取token5分钟有效
如果登录成功,你将得到两个长字符串,一个是access token(访问令牌),还有一个是refresh token(刷新令牌)
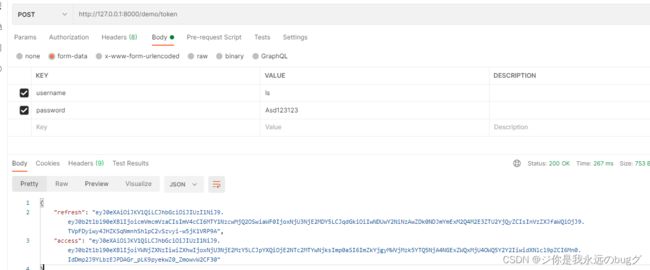
2、刷新token
将获取token时拿到的 refresh 放入参数

7.4、修改JWT配置
settings.py
# 修改 JWT 配置
SIMPLE_JWT = {
'REFRESH_TOKEN_LIFETIME': timedelta(days=15), # token 有效期改为15天
'ROTATE_REFRESH_TOKENS': True,
}
7.5、自定义令牌
token的payload数据部分包括token类型,token失效时间,jti(一个类似随机字符串)和user_id,如下
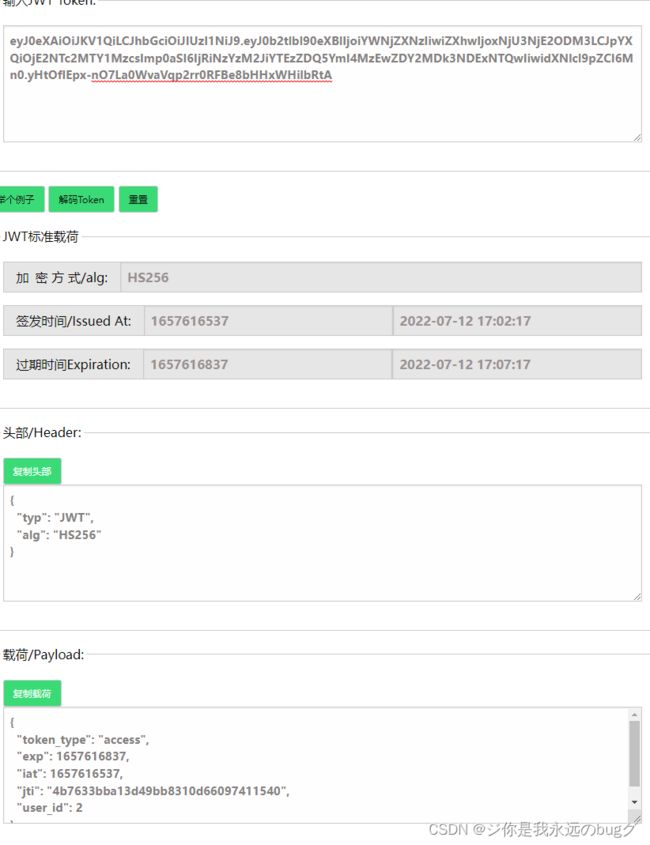
如果你希望在payload部分提供更多信息,比如用户的username,这时你就要自定义令牌(token)了。
1、编写序列化类
from rest_framework_simplejwt.serializers import TokenObtainPairSerializer
class MyTokenObtainPairSerializer(TokenObtainPairSerializer):
@classmethod
def get_token(cls, user):
token = super(MyTokenObtainPairSerializer, cls).get_token(user)
# 添加额外信息
token['username'] = user.username
return token
2、自定义视图
from rest_framework_simplejwt.views import TokenObtainPairView
from rest_framework.permissions import AllowAny
from .serializers import MyTokenObtainPairSerializer
class MyObtainTokenPairView(TokenObtainPairView):
permission_classes = (AllowAny,)
serializer_class = MyTokenObtainPairSerializer
3、将 获取token的路由对应的方法改为自定义视图
path('token', MyObtainTokenPairView.as_view(), name='token_obtain_pair'),
4、测试

6、登录流程
1、调用 token 接口
path('token', TokenObtainPairView.as_view(), name='token_obtain_pair'),
2、调用 类视图
from app01.serializers import MyTokenObtainPairSerializer
class MyObtainTokenPairView(TokenObtainPairView):
permission_classes = (AllowAny,)
serializer_class = MyTokenObtainPairSerializer
3、自定义的令牌 序列化
class MyTokenObtainPairSerializer(TokenObtainPairSerializer):
# 自定义 token的内容
@classmethod
def get_token(cls, user):
token = super(MyTokenObtainPairSerializer, cls).get_token(user)
# 添加额外信息
token['username'] = user.username
return token
# 响应数据
def validate(self, attrs):
self.get_user(attrs)
refresh = self.get_token(self.user)
data = {}
data['refresh'] = str(refresh)
data['access'] = str(refresh.access_token)
# 令牌到期时间
data['expire'] = refresh.access_token.payload['exp'] # 有效期
# 用户名
data['username'] = self.user.username
# 邮箱
data['email'] = self.user.email
return data
# 身份认证
def get_user(self, attrs):
user_obj = User.objects.filter(username=attrs['username']).first()
if not user_obj:
raise ValidationError('用户不存在')
if not user_obj.check_password(attrs['password']):
raise ValidationError('密码错误')
if not user_obj.is_active:
raise ValidationError('账户已停用')
self.user = user_obj

1、大江狗:推荐阅读!!!!!!!!!!!!!!网站如果失效 可搜索:【CSDN大江狗】、【知乎大江狗】和搜索微信公众号【Python Web与Django开发】关注我!!
2、黑羽 Django