Clickhouse学习笔记01——入门及安装
文章目录
-
- 一、Clickhouse入门
-
- 1.使用场景
- 2.Clickhouse的特点
-
- 2.1 列式存储
- 2.2 DBMS功能
- 2.3 多样化引擎
- 2.4 高吞吐写入能力
- 2.5 数据分区和线程并行
- 2.6 一些限制
- 2.7 哪些公司在使用clickhouse
- 3.优缺点
-
- 3.1 优点
- 3.2 缺点
- 4.核心概念
-
- 4.1 数据分片
- 4.2 列式存储
- 4.3 向量化
- 4.4 表
- 4.5 分区
- 4.6 副本
- 4.7 引擎
- 二、安装单机版clickhouse
-
- 1.准备工作
-
- 1.1 CentOS取消打开文件数限制
- 1.2 CentOS取消SELINUX
- 1.3 关闭防火墙
- 1.4 重启服务器
- 2.单机安装
-
- 2.1 安装依赖的工具
- 2.2 使用yum安装(需要网络)
- 2.3 使用rmp离线安装(不需要网络)
- 2.4 修改配置文件
- 2.5 启动ClickhouseServer
- 2.6 启动ClickhouseClient
- 2.7 关闭开机自启动
- 3.卸载重装
一、Clickhouse入门
1.使用场景
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查(OLAP),能够使用SQL查询实时生成分析数据报告。
OLAP场景的关键特征
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
2.Clickhouse的特点
2.1 列式存储
| Id | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
- 采用行式存储时,数据在磁盘上的组织结构为:
![]()
-
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
-
而采用列式存储时,数据在磁盘上的组织结构为:
![]()
-
这时想查所有人的年龄只需把年龄那一列拿出来就可以了
-
列式储存的好处:
1.对于列的聚合,计数,求和等统计操作原因优于行式存储。
2.由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
3.由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。
2.2 DBMS功能
- ClickHouse支持基于SQL的声明式查询语言,该语言大部分情况下是与SQL标准兼容的。
- 支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。
- 不支持窗口函数和相关子查询。
2.3 多样化引擎
clickhouse和mysql类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。
目前包括合并树、日志、接口和其他四大类20多种引擎
2.4 高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。
通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。
顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
2.5 数据分区和线程并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。所以,clickhouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就***不利于同时并发多条查询***。所以对于高qps的查询业务,clickhouse并不是强项。
2.6 一些限制
- 没有完整的事务支持。
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
2.7 哪些公司在使用clickhouse
https://clickhouse.tech/docs/zh/introduction/adopters/
3.优缺点
3.1 优点
- 灵活的MPP架构,支持线性扩展,简单方便,高可靠性
- 多服务器分布式处理数据 ,完备的DBMS系统
- 底层数据列式存储,支持压缩,优化数据存储,优化索引数据 优化底层存储
- 容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别
- 功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
- 海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持
3.2 缺点
- 不支持事务,不支持真正的删除/更新
- 不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下
- 不支持二级索引
- 不擅长多表join,建议使用大宽表
- 元数据管理需要人为干预
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作
4.核心概念
4.1 数据分片
数据分片是将数据进行横向切分,这是一种在面对海量数据的场 景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。 ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限 取决于节点数量(1个分片只能对应1个服务节点)。ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表(Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。这就好比一辆手动挡赛车,它将所有的选择权都交到了使用者的手中!
4.2 列式存储
① 如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个bloCK中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
② 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
③ 更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
④ 自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
⑤ 高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
4.3 向量化
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
① 对每一行数据都要调用相应的函数,函数调用开销占比高;
② 存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
③ 按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
(SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。以同步方式,在同一时间内执行同一条指令。)
4.4 表
上层数据的视图展示概念 ,包括表的基本结构和数据
4.5 分区
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。数据以分区的形式统一管理和维护一批数据!
4.6 副本
数据存储副本,在集群模式下实现高可用 , 简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式:(1)基于ZooKeeper的表复制方式;(2)基于Cluster的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
4.7 引擎
不同的引擎决定了表数据的存储特点,位置和表数据的操作行为:
① 决定表存储在哪里以及以何种方式存储
② 支持哪些查询以及如何支持
③ 并发数据访问
④ 索引的使用
⑤ 是否可以执行多线程请求
⑥ 数据复制参数
⑦ 并发操作 insert into tb_x select * from tb_x ;
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
二、安装单机版clickhouse
1.准备工作
1.1 CentOS取消打开文件数限制
修改/etc/security/limits.conf
sudo vim /etc/security/limits.conf
添加以下内容,如果已经添加过,则修改
注意前面需要添加 *
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
修改/etc/security/limits.d/20-nproc.conf
sudo vim /etc/security/limits.d/20-nproc.conf
添加以下内容,如果已经添加过,则修改
注意前面需要添加 *
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
1.2 CentOS取消SELINUX
别改错了,注意是对SELINUX进行修改
sudo vim /etc/selinux/config
SELINUX=disabled
1.3 关闭防火墙
如果已经关闭, 跳过改步骤
-
查看防火墙状态
sudo firewall-cmd --state -
关闭防火墙
sudo systemctl stop firewalld -
关闭开机自启动(因为防火墙是服务, 所以开启会自启, 需要关闭)
sudo systemctl disable firewalld
1.4 重启服务器
上述修改完成后重启服务器
2.单机安装
2.1 安装依赖的工具
sudo yum -y install yum-utils
2.2 使用yum安装(需要网络)
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
sudo yum -y install clickhouse-server clickhouse-client
2.3 使用rmp离线安装(不需要网络)
注意: 使用yum和使用rmp二选一
-
准备离线安装包
下载地址: https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/ -
需要下面4个安装包
clickhouse-client-20.4.5.36-2.noarch.rpm clickhouse-common-static-20.4.5.36-2.x86_64.rpm clickhouse-common-static-dbg-20.4.5.36-2.x86_64.rpm clickhouse-server-20.4.5.36-2.noarch.rpm -
使用rpm安装
sudo rpm -ivh clickhouse-client-20.4.5.36-2.noarch.rpm sudo rpm -ivh clickhouse-common-static-20.4.5.36-2.x86_64.rpm sudo rpm -ivh clickhouse-common-static-dbg-20.4.5.36-2.x86_64.rpm sudo rpm -ivh clickhouse-server-20.4.5.36-2.noarch.rpm -
或者直接一次性安装所有rpm包
sudo rpm -ivh *.rpm
2.4 修改配置文件
修改/etc/clickhouse-server/config.xml
sudo vim /etc/clickhouse-server/config.xml
# ipv4均能连接和ipv6均能连接,docker下可能出现问题!!!
<listen_host>::</listen_host>
# docker下使用下面的配置
<listen_host>0.0.0.0</listen_host>
允许: 来自任何地方的客户度连接当前服务器(ipv4和ipv6都可以)
在这个文件中,有ClickHouse的一些默认路径配置,比较重要的
- 数据文件路径:
/var/lib/clickhouse/ - 日志文件路径:
/var/log/clickhouse-server/clickhouse-server.log
注意,使用CDH时9000端口已经被占用,可以修改配置中和9000端口有关的参数,将其修改为9003
<tcp_port>9003tcp_port>
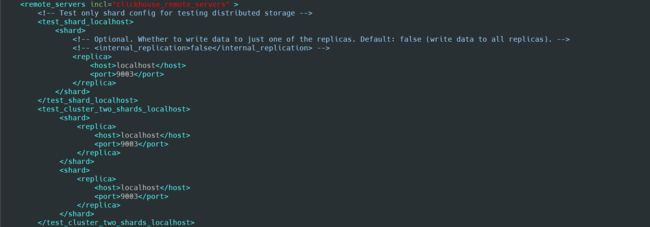
<remote_servers incl="clickhouse_remote_servers" >
<remote_servers incl="clickhouse_remote_servers" >
<test_shard_localhost>
<shard>
<replica>
<host>localhosthost>
<port>9003port>
replica>
shard>
test_shard_localhost>
<test_cluster_two_shards_localhost>
<shard>
<replica>
<host>localhosthost>
<port>9003port>
replica>
shard>
<shard>
<replica>
<host>localhosthost>
<port>9003port>
replica>
shard>
test_cluster_two_shards_localhost>
<test_cluster_two_shards>
<shard>
<replica>
<host>127.0.0.1host>
<port>9003port>
replica>
shard>
<shard>
<replica>
<host>127.0.0.2host>
<port>9003port>
replica>
shard>
test_cluster_two_shards>
<test_unavailable_shard>
<shard>
<replica>
<host>localhosthost>
<port>9003port>
replica>
shard>
<shard>
<replica>
<host>localhosthost>
<port>1port>
replica>
shard>
test_unavailable_shard>
remote_servers>


同时应当修改/etc/clickhouse-client/config.xml中的端口号
sudo vim /etc/clickhouse-client/config.xml
<port>9003</port>

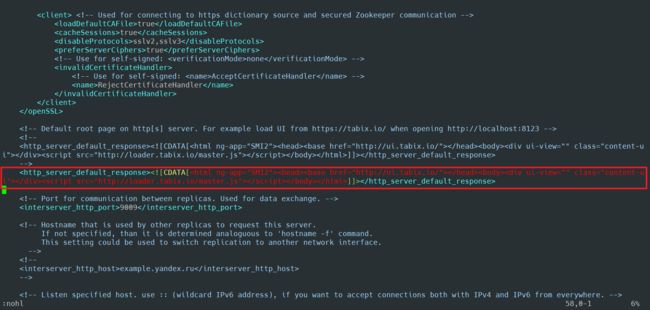
如果需要使用WebUI进行查看,可以放开下面一行配置的注释
<http_server_default_response><html ng-app="SMI2"><head><base href="http://ui.tabix.io/">head><body><div ui-view="" class="content-ui">div><script src="http://loader.tabix.io/master.js">script>body>html>]]>http_server_default_response>
通过以下WebUI操作ClickHouse:http://ui.tabix.io/
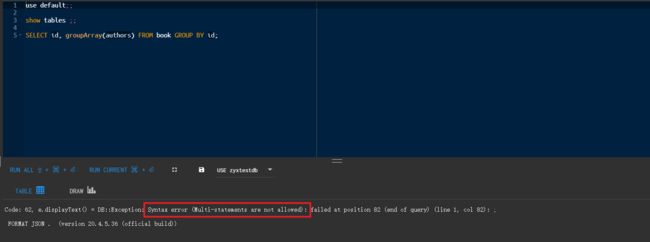
查询语句需要以;;结尾

否则可能报以下错误
Code: 62, e.displayText() = DB::Exception: Syntax error (Multi-statements are not allowed): failed at position 82 (end of query) (line 1, col 82): ;
2.5 启动ClickhouseServer
sudo systemctl start clickhouse-server
2.6 启动ClickhouseClient
source /etc/profile(可选)
连接本机服务器的client端口,-m表示可以换行使用
clickhouse-client -m
连接远程服务器
clickhouse-client --host=linux201 -m
也可以使用dbeaver进行连接,使用之前需要下载默认的驱动
2.7 关闭开机自启动
sudo systemctl disable clickhouse-server
3.卸载重装
需要更新ClickHouse时可以先停服务
systemctl stop clickhouse-server
刚才介绍了rpm方式的安装,如果有网络的情况下,可以使用yum安装或者卸载
首先卸载ClickHouse
yum remove -y clickhouse-common-static
yum remove -y clickhouse-server-common
然后查看是否卸载成功
yum list installed | grep clickhouse
如果还有没有卸载干净的继续使用yum进行删除
yum remove -y clickhouse-common-static-dbg.x86_64
全部卸载后删除ClickHouse的lib目录以及日志和数据目录(下面为默认的目录)
rm -rf /var/lib/clickhouse
rm -rf /etc/clickhouse-*
rm -rf /var/log/clickhouse-server
然后上传rmp安装包到CentOS上,由于有网路,使用yum进行安装,安装过程中如果有依赖包需要安装可以直接下载安装
yum install -y clickhouse-common-static-20.8.3.18-2.x86_64.rpm
yum install -y clickhouse-common-static-dbg-20.8.3.18-2.x86_64.rpm
yum install -y clickhouse-client-20.8.3.18-2.noarch.rpm
yum install -y clickhouse-server-20.8.3.18-2.noarch.rpm