Hive的表操作2
Hive系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Hive的表操作2
#博学谷IT学习技术支持
文章目录
- Hive系列
- 前言
- 一、Hive表操作2-分区表
-
- 1.静态分区
- 2.动态分区
- 二、Hive表操作2-分桶表
- 总结
前言

1、Hive是数仓管理工具,用来管理数仓
2、Hive可以将数仓存在HDFS上的文件变成一张张的表
3、Hive提供一种HiveSQL可以表进行分析处理
4、HiveSQL底层默认是MapReduce,以后可以换成其他的引擎(Spark),我们写HiveSQL会去匹配底层的MR模板,匹配上则执行,否则不能执行

一、Hive表操作2-分区表
1、分区表就是对一个表的文件数据进行分类管理,表现形式就是有很多的文件夹(dt=2019-02-27)
2、分区表的作用是以后查询时,我们可以手动指定对应分区的数据,避免全表扫描,提高查询效率
3、专业的介绍
所谓的分区表,指的就是将数据按照表中的某一个字段进行统一归类,并存储在表中的不同的位置,也就是说,一个分区就是一类,这一类的数据对应到hdfs存储上就是对应一个目录。当我们需要进行处理的时候,可以通过分区进行过滤,从而只取部分数据,而没必要取全部数据进行过滤,从而提升数据的处理效率。且分区表是可以分层级创建。
select * from 表 where dt = ‘2019-03-13’
4、分区表的关键字是Partition,这里的分区是MR中的分区没有关系
5、分区表可以有内部分区表,也可以有外部分区表
6、什么时候表数据不用分区:
1)几乎在实际应用中所有的表数据都要分区
2)如果你的数据量很小,而且数据很单一,此时可以不用分区
1.静态分区
----------------------单级分区----------------------------------
-- 1、创建单分区表
create table score
(
sid string,
cid string,
sscore int
)
partitioned by (dt string) -- 这个dt是分区字段和表字段没有关系,理论上可以随便写
row format delimited fields terminated by '\t';
-- 2、给分区表加载数据
-- 第一件事:在HDFS的表目录下创建文件夹:dt=2022-10-13 第二件事:将score.txt复制到该文件夹下
load data local inpath '/export/data/hivedatas/score.txt' into table score partition (dt='2022-10-13');
select * from score;
-- 再添加一个分区
load data local inpath '/export/data/hivedatas/score2.txt' into table score partition (dt='2022-10-14');
select * from score;
-- 3、查询数据
-- 查找dt=2022-10-13分区数据
select * from score where dt='2022-10-13';
-- 查找dt=2022-10-14分区数据
select * from score where dt='2022-10-14';
desc score; -- 查看哪个是分区列
----------------------多级分区----------------------------------
-- 1、创建多级分区表
create table score2
(
sid string,
cid string,
sscore int
)
partitioned by (year string, month string ,dt string) -- 这个dt是分区字段和表字段没有关系,理论上可以随便写
row format delimited fields terminated by '\t';
-- 2、给分区表加载数据
-- 第一件事:在HDFS的表目录下创建三级文件夹:year=2022/month=10/dt=13 第二件事:将score.txt复制到该文件夹下
load data local inpath '/export/data/hivedatas/score.txt'
into table score2 partition (year='2022',month='10',dt='13');
select * from score2;
-- 再添加一个分区
load data local inpath '/export/data/hivedatas/score2.txt'
into table score2 partition (year='2022',month='11',dt='13');
-- 再添加一个分区
load data local inpath '/export/data/hivedatas/score2.txt'
into table score2 partition (year='2023',month='11',dt='13');
select * from score2;
-- 3、查询分区数据:查询 2022年 10月13号数据
select * from score2 where year='2022' and month = '10' and dt = '13';
----------------------分区相关的SQL----------------------------------
show partitions score; -- 查看表所有分区情况
alter table score add partition(dt='2022-01-01'); -- 手动添加一个分区
alter table score drop partition(dt='2022-01-01'); -- 手动删除一个分区
2.动态分区

-- -----------------------单级分区:按照日进行分区---------------------------------
-- 1、开启动态分区
set hive.exec.dynamic.partition=true; -- 开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict;-- 设置为非严格格式
-- 2、模拟数据
/*
1 2022-01-01 zhangsan 80
2 2022-01-01 lisi 70
3 2022-01-01 wangwu 90
1 2022-01-02 zhangsan 90
2 2022-01-02 lisi 65
3 2022-01-02 wangwu 96
1 2022-01-03 zhangsan 91
2 2022-01-03 lisi 66
3 2022-01-03 wangwu 96
*/
-- 3、创建一个中间普通表(该表用来存入原始数据)
create table test1
(
id int,
date_val string,
name string,
score int
)
row format delimited fields terminated by '\t';
-- 4、给普通表加载数据
load data local inpath '/export/data/hivedatas/partition.txt' into table test1;
-- 5、来创建最终的分区表
create table test2
(
id int,
name string,
score int
)
partitioned by (dt string) -- 这个分区字段的名字随便写,它来决定HDFS上文件夹的名字:day=2022-01-01
row format delimited fields terminated by ',';
-- 6、查询普通表,将数据插入到分区表
insert overwrite table test2 partition (dt)
select id, name, score, date_val from test1;
select * from test2;
-- -----------------------单级分区:按照月进行分区---------------------------------
1 2022-01-01 zhangsan 80
2 2022-01-01 lisi 70
3 2022-01-01 wangwu 90
1 2022-01-02 zhangsan 90
2 2022-01-02 lisi 65
3 2022-01-02 wangwu 96
1 2022-01-03 zhangsan 91
2 2022-01-03 lisi 66
3 2022-01-03 wangwu 96
1 2022-02-01 zhangsan 80
2 2022-02-01 lisi 70
3 2022-02-01 wangwu 90
1 2022-02-02 zhangsan 90
2 2022-02-02 lisi 65
3 2022-02-02 wangwu 96
1 2022-02-03 zhangsan 91
2 2022-02-03 lisi 66
3 2022-02-03 wangwu 96
load data local inpath '/export/data/hivedatas/partition2.txt' overwrite into table test1;
drop table test2_1;
create table test2_1
(
id int,
date_val string,
name string,
score int
)
partitioned by (month string) -- 这个分区字段的名字随便写,它来决定HDFS上文件夹的名字:day=2022-01-01
row format delimited fields terminated by ',';
-- 6、查询普通表,将数据插入到分区表
insert overwrite table test2_1 partition (month)
select id, date_val,name, score, substring(date_val,1,7) from test1;
动态多级分区
-- 1、创建普通表
drop table if exists test3;
create table test3
(
id int,
date_val string,
name string,
sex string,
score int
)
row format delimited fields terminated by '\t';
;
-- 2、给普通表加载数据
load data local inpath '/export/data/hivedatas/partition3.txt' overwrite into table test3;
select * from test3;
-- 3、创建最终的分区表
drop table test4;
create table test4
(
id int,
name string,
score int
)
partitioned by (xxx string, yyy string)
row format delimited fields terminated by '\t'
;
-- 4、去普通表查询,将查询后的结果插入到最终的分区表
insert overwrite table test4
select id, name, score,date_val,sex from test3; -- 这里的动态分区是看最后的两个字段
二、Hive表操作2-分桶表
1、分桶就是MR的分区
2、分桶表的表现形式就是分文件,可以通俗的理解为将一个大的表文件拆分成多个小文件
3、分桶的作用有两个:
作用1:主要是来提高多张表join的效率
作用2:主要是用于数据的抽样
4、分桶的方式就是拿到分桶字段的值,然后取hash值对分桶的个数取模
专业说法:
在表或者分区中使用分桶通常有两个原因,一个是为了高效的join查询,另一个则是为了高效的抽样。
桶其实是在表中加入了特殊的结构,hive在查询的时候可以利用这些结构来提高查询效率。比如,
如果两个表根据相同的字段进行分桶,则在对这两个表进行join关联的时候可以使用map-side关联高效实现。

-- 1、创建分桶表
create table course
(
cid string,
c_name string,
tid string
)
clustered by (cid) into 3 buckets
row format delimited fields terminated by '\t';
-- 解释:
clustered by (cid) into 3 buckets 表示按照cid 这一列进行分桶,并且将表数据分到3个桶中(3个文件中)
-- 2、创建普通表
create table course_common
(
cid string,
c_name string,
tid string
) row format delimited fields terminated by '\t';
-- 3、给普通表加载数据
load data local inpath '/export/data/hivedatas/course.txt' into table course_common;
select * from course_common;
-- 4、将普通表的数据进行查询插入到普通表
insert overwrite table course
select * from course_common cluster by (cid);
select * from course;
作用1-提高join的效率
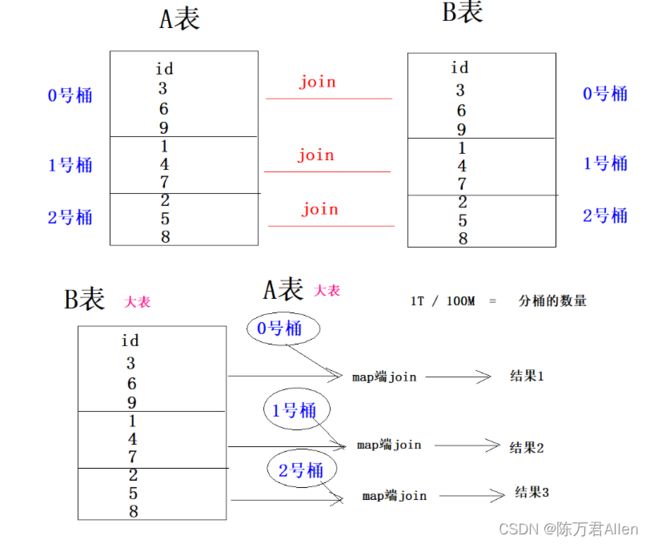
作用2 -可以用于数据的抽样
1、有时候在大数据分析时,我们并不需要全部的数据参与分析,而只需要抽取一部分具有代表性的数据参与分析,这样可以提高分析的效率,此时就可以使用分桶表来完成
1 zs
2 ls
3 ww
4 zl
5 zq
6 mb
7 lf
8 we
9 zz
10 qw
-- 1、创建分桶表
drop table sample_test;
create table sample_test
(
sid int,
s_name string
)
clustered by (sid) into 6 buckets
row format delimited fields terminated by '\t';
-- 2、创建普通表
create table sample_common
(
sid int,
s_name string
) row format delimited fields terminated by '\t';
-- 3、给普通表加载数据
load data local inpath '/export/data/hivedatas/sample.txt' overwrite into table sample_common;
select * from sample_common;
set hive.stats.column.autogather=false;
set hive.exec.mode.local.auto=true; --开启本地mr
-- 4、将普通表的数据进行查询插入到普通表
insert overwrite table sample_test
select * from sample_common cluster by (sid);
select * from course;
-- 5、对数据进行抽样(先保留)
-- TABLESAMPLE (BUCKET x OUT OF y [ON colname]) 6 / 2 = 3
select * from sample_test tablesample ( bucket 1 out of 2 on sid);
总结
今天继续和大家分享一下Hive的表操作2 分区和分桶表。