第16章 I/O编程
I/O(input/Output,输入/输出)可以实现数据的读取与写入操作,java针对I/O操作的实现提供了java.io工具包,此包的核心组成由File类、InputStream类、OutputStream类、Reader类、Writer类、Serializable接口。在学习java I/O前,一定要清楚掌握对象多态性的概念与特点,而对象多态性中最为核心的概念是如果抽象类或接口类的抽象发发被子类复写了,那么所调用方法必然是被子类复写过的方法,及方法名称以父类为标准,具体实现靠子类。
16.1 File文件操作
java.io.File类是一个与文件操作本身相关的类,此类可以实现文件创建、删除、重命名、取得文件大小、修改日期等常见系统文件操作。
16.1.1 File类基本使用
如果要使用File类则必须提供完整的文件操作路径,对于文件路径的设置可以通过File类的构造方法完成,当获取了争取的文件路径后就可以进行文件创建与删除的操作:
| No | 方法 | 类型 | 描述 |
| 1 | public File(String pathname) | 构造 | 给定一个要操作文件的完整路径 |
| 2 | public File(File parent,String child) | 构造 | 给定要操作文件的父路径和子文件名称 |
| 3 | public boolean createNewFile()throws IOException | 普通 | 创建文件 |
| 4 | public boolean delete() | 普通 | 删除文件 |
| 5 | public boolean exists() | 普通 | 判定给定路径是否存在。 |
package cn.mldn.demo;
import java.io.File;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("d:\\mldn.txt");
if(file.exists()){file.delete();}
else{System.out.println(file.createNewFile());}
}
}
16.1.2 File类操作深入
在使用File类进行文件创建时需要设置完整路径,但是对于不同操作系统文件的分隔符也不同。在Windows中的路径分隔符为“\”,而在UNIX或类UNIX操作系统中路径分割符号为“/”,所以为了解决不同操作系统的路径分隔符问题,在java.io.File类中提供了一个路径分隔符常量:
路径分隔符:public static finale String seprator,在不同的操作系统可以获取不同的分隔符。
在实际项目开发中对于文件路径操作,建议使用以下方式进行定义。
File file=new File("d:"+File.separotor+"mldn.txt");
此时就会根据不同的操作系统西风匹配不同的路劲分隔符,这样就可以保证路径与操作系统相匹配。
提问:全局常量的命名规范不应该是全部字母大写吗
按照Java的命名规范来讲,全局常量的组成应该为大写字母,但是在File类中定义的常量名称为public static final String separator,这并不符合命名标准,为什么不是public static final String SEPERATOR
回答:历史发展原因
Java在最初的版本中并没有对常量名进行专门的命名规范(与成员属性名称相同),而在JDK不断完善的同时,命名规范也越来越完善,所以才有了命名全部采用大写字母的要求,这些都属于历史遗留问题。
另外,通过本程序的执行也可以发现,JVM的支持实际上对程序的开发非常有帮助,但同时也需要清楚一个问题:Java的程序是通过JVM执行,而后再由JVM取调用操作系统的文件处理函数而形成的文件操作 使用File类创建文件时必须保证父路径存在,当前程序是直接在根路径下进行文件创建,所以用户可以直接使用createNewFile()方法创建文件,如果此时文件需要保存在特定目录下,则必须先创建父目录后才可以进行文件创建。
使用File类创建文件时必须保证父路径存在,当前程序是直接在根路径下进行文件创建,所以用户可以直接使用createNewFile()方法创建文件,如果此时文件需要保存在特定目录下,则必须先创建父目录后才可以进行文件创建。
| No | 方法 | 类型 | 描述 |
| 1 | public File getParentFile() | 普通 | 找到一个指定路径的父路径 |
| 2 | public boolean mkdirs() | 普通 | 创建指定目录 |
范例:创建带目录的文件
package cn.mldn.demo;
import java.io.File;
public class JavaIODemo
{
public static void main(String []args)throws Exception
{
File file=new File("d:"+File.separator+"hello"+File.separator+"demo"+File.separator+"message"+File.separator+"mldn.txt");
if(!file.getParentFile().exists()){file.getParentFile().mkdirs();}
}
if(file.exists()){file.delete;}else{System.out.prinln(filr.createNewFile());}
}
本程序创建了带目录的文件,所以文件创建前首先要判断父目录是否存在,如果不存在则通过getParentFile()获取父路径的File类对象,并利用mkdirs()方法创建多级目录。
16.1.3 获取文件信息
为了方便进行文件的管理,系统会针对不同的文件进行一些元数据信息的记录,在File类中可以通过: 范例:获取文件基础信息
范例:获取文件基础信息
package cn.mldn.demo;
import java.io.File;
import java.txtx.SimpleDateFormat;
import java.util.Date;
class MathUtil
{
private MathUtil(){}
public static double round(double num,int scale)
{
return Math.round(Math.pow(10,scale)*num)/Math.pow(10,scale);
}
}
public class JavaIODemo
{
public static void main(String []args)throws Exception
{
File file=new File("d:"+File.separator+"mldn.jpg");
System.out.println("文件是否可读:"+file.canRead());
System.out.println("文件是否可写:"+file.canWrite());
System.out.println("文件大小:"+MathUtil.round(file.length()/(double)1024/1024,2)+"M");
System.out.println("最后修改时间"+new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date(file.lastModified())));
System.out.println("是目录吗"+file.isDirectory());
System.out.println("是文件吗"+file.isFile());
}
}
本程序利用File类中提供的方法获取了与文件有关的一些基础数据信息,再获取文件长度以及最后修改日期时返回的数据类型都是long,所以需要进行相应的转换才可以方便阅读。
范例:列出目录组成
package cn.mldn,demo;
import java.io.File;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("d:"+File.separator);
if(file.isDirectory())
{
File result[]=filr.listFiles();
for(int x=0;x
System.out.println(result[x]);
}
}
}
}
本程序通过listFiles方法讲一个给定目录中的全部内容列出。需要注意的是,listFiles()方法返回的是File型的对象数组,即在获取数组每一个File类失利后可以继续进行各个子路径的处理。
16.1.4 综合案例:文件列表显示
一个瓷盘中的文件目录非常庞大,经常会出现目录嵌套的操作,如果想要列出一个牟丽霞全部组成,就可以利用File类结合递归形式实现
范例:列出目录组成
pcakge cn.mldn.demo;
import java.io.File;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File filr=new File("D:"+File.separator);
listDir(file);
}
public static void listDir(File file)
{
if(file.isDirectory())
{
File results[]=file.listFiles();
if(result!=null)
{
for(int x=0;x
ListDir(result[x]);
}
}
}
System.out.println(file);
}
}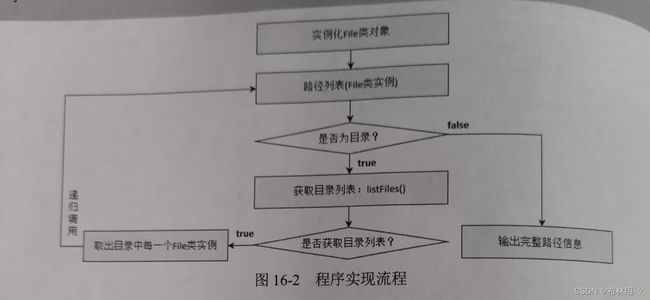 本程序通过递归调用的形式姜传儒的目录路径进行结构列出,如果发现当前传入的路径不是目录而只是一个普通文件,则直接进行路径打印。
本程序通过递归调用的形式姜传儒的目录路径进行结构列出,如果发现当前传入的路径不是目录而只是一个普通文件,则直接进行路径打印。
16.1.5 综合案例:文件批量更名
在项目开发过程中经常会存在数据采集问题,现在假设有这样一个案例:某系统在进行数据采集是,会将所有采集道德日志信息保存在一个指定的目录中(假设保存路径为d:'mldn-log),但是由于设计人员的疏忽,文件的猴嘴均采用.java进行定义,为了修正这一结果,要求将目录中给所有文件的后缀统一替换为.txt,同时也需要考虑到多级目录下文件更名操作。

范例:目录批量改名
package cn.mldn.demo;
import java.io.File;
public class JavaIODemo
{
public static void main(String[]args)
{
File file=new File("D:"+File.separator+"mldn-log");
renameDir(file);
}
public static void renameDir(File file)
{
if(file.isDirectory())
{
File result[]=filr.listFiles();
if(results!=null)
{
for(int x=0x
renameDir(results[x]);
}
}
}
else
{
if(filr.isFile())
{
String filename=null;
if(file.getName().endWith(".java"))
{
fileName=file.getName().substring(0,file.getName().lastIndexOf("."))+".txt";
File newFile=new File(file.getParentFile(),fileName);
file.renameTo(newFile);
}
}
}
}
}
16.2 字节流与字符流
在程序中所有的数据都是以流的方式进行传输或保存的,在流中存在输入流和输出流两种: 当程序需要通过数据文件读取数据时就可以利用输入流来完成,而当程序需要将数据保存在文件时,就可以使用输出流完成,在Java中对于流操作提供有两类支持
当程序需要通过数据文件读取数据时就可以利用输入流来完成,而当程序需要将数据保存在文件时,就可以使用输出流完成,在Java中对于流操作提供有两类支持
字节操作流(在JDK1.0的时候定义):OutputStream、InputStream
字符操作流(正在JDK1.1的时候定义):Writer、Reader
数据流是一种重要的资源操作,而执行资源操作时一般按照以下及格不走进行
(1)如果要操作的是文件,那么首先要通过File类对象找到一个要操作的文件路径(路径可能存在可能不存在)
(2)通过字节流或字符流的子类为字节流或字符流的对象实例化(向上转型)
(3)执行读写操作
(4)一定要关闭操作的资源(close())
16.2.1 OutputStream
字节(Byte)是进行I/O操作的基本数据单位,在程序进行字节数据输出是可以使用java.io.OutputStream类完成,此类定义如下:
public abstract class OutputStream
extends Object
implements Closeable,Flushable{}
在OutputStream类中实现了两个父接口Closeable、Flushable,这两个接口的组成分别如下
| Closeable | Flushable |
| public interface Closeable{extends AutoCloseable { public void close() throws IOException; }} |
public interface Flushable { public void flush() throws IOExceotion; } |
这两个负借口是从JDK1.5后提供的,而在JDK1.5前close()与flush()两个方法都是直接定义在OutputStream类中的。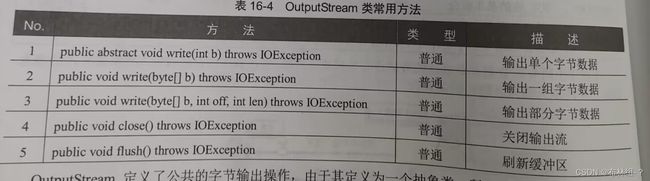 OutputStream定义了公共的字节输出操作,可以使用FileOutputStream,其继承关系如图:
OutputStream定义了公共的字节输出操作,可以使用FileOutputStream,其继承关系如图: 范例:使用OutputStream类实现内容输出
范例:使用OutputStream类实现内容输出
package cn.mldn.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("D:"+File.separator+"hello"+File.separator+"mldn.txt");
if(!file.getParentFile().exists())
{
filr.getParentFile().mkdirs();
}
OutputStream output =new FileOutputStream(file);
String str-"AAAA";
output.Write(str.getBytes());
output.close();
}
}
本程序通过FileOutputStream类实现了程序内容的输出操作,在输出时务必保证父目录的存在,同时不需要用户手动插UN关键文件,会在输出是自动帮用于创建。
提示:使用AutoCloseable自动关闭接口
通过OutputStream的集成结构可以发现,OutputStream是AutoCloseable接口子类,所以此时就可以利用try...catch实现自动关闭
范例:自动关闭输出流
try(OutputStream output=new FileOutputStream(file,true))
{
String str="AAAA";
output.write(str.getBytes());
}catch(IOException e)
{
e.printStackTrace()
}
使用AutoCloseable可以由JDK帮助用户自动调用close()方法实现资源关闭。
重复执行以上代码会导致新的内容替换掉已有的文件数据,如果想追加内容可以更换FileOutputStream类的构造方法。
范例:文件内容追加"
OutputStream output=new FileOutputStream(file,true);
String str="AAA";
output.write(str.getBytes());
output.close();
16.22 InputStream流
当程序需要通过数据流进行字节数据读取时就可以利用java.io.InputStream类来实现,InputStream类实现了Closeable父接口,所以在输入完毕后需要进行流的关闭: 在InputStream类中提供的主要方法为read(),可以实现单个字节或一组字节数据的读取操作
在InputStream类中提供的主要方法为read(),可以实现单个字节或一组字节数据的读取操作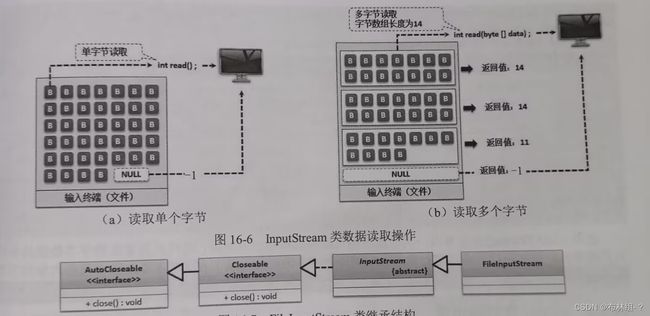 InputStream属于抽象类,对于稳健的读取可以通过FileInputStream子类来进行实例化。
InputStream属于抽象类,对于稳健的读取可以通过FileInputStream子类来进行实例化。
范例:使用INputStream类刦文件呃逆荣
package cn.mldn.demo;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("D:"+File.separator+"hello"+File.separator+"mldn.txt");
if(file.exists())
{
InputStream input=new FileInputStream(file);
byte data[]=new byte[1024];
int len=input.read(data);
System.out.println(""+new String(data,0,len));
input.close();
}
}
}
本程序在进行数据读取时开辟了一个字节缓冲区,这样在使用read()方法时就可以将读取的内容保存在缓冲区中,在输出时利用String类的构造方法将读取到的字节内容转为字符串。
从JDK1.9开始为了方便开发者使用InputStream读取数据,提供了返回全部输入流内容的方法readAllBytes();
范例:读取全部内容
package cn.mldn.demo;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("D:"+File.separator+"hello"+File.separator+"mldn.txt");
if(file.exists())
{
InputStream input=new FileInputStream(file);
byte data[]=input.readAllBytes();
System.out.println(new String(data)+"");
input.close();
}
}
}
使用readAllBytes()方法可以一次性的返回输入流中的所有字节数据,这样开发者再将字节数据内容转换为字符串的时候就不必进行数据长度的控制了。
16.2.3 Writer字符输出流
在底层通信处理中都是依靠字节实现的数据交互,在程序中为了方便进行中文的数据出炉,往往都采用字符数据类型,所以在JDK1.1开始提供有字符输出流Writer,
范例:使用FileWriter实现数据输出
package cn.mldn.demo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class JavaIODemo
{
File file=new File(String[]args)throws Exception
{
File file=new File("D:"+File.separator+"hello"+File.separator+"mldn.txt");
if(!file.getParentFile().exists())
{
file.getParentFile().mkdirs();
}
Writer outnew FileWritr(file);
out.write("AAA");
out.append("NN");
out.close();
}
}
16.2.4 Reader字符输入流
Reader是实现字符输入流的操作类,可以实现char数据类型的读取。
范例:文件内容读取
package cn.mldn.demo;
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("D:"+File.separarator+"hello"+File.separator+"mldn.txt");
if(file.exists())
{
Reader in =new FileReader(file);
char data[]=new char[1024];
in.skip(9);
int len=in.read(data);
System.out.println(new String(data,0,len));
in.close();
}
}
}
本程序通过FileReader实现了数据读取,在读取时可以利用skip()实现跨字符个数的数据读取操作,需要注意的是,Reader类并没有提供可以直接返回自复查UN的读取方法,只能利用字符数组进行读取;
16.2.5 字节流与字符流的区别
虽然java.io包中提供字节流和字符流两类处理支持类,但是在数据传输(或者将数据保存在磁盘)是所操作的数据依然为字节数据,字符数据都是通过缓冲区进行处理后得到的内容: 两类操作流程最大的区别在于自负六十用到了缓冲区(这样更适合进行中文数据的操作),而字节流是直接进行数据处理操作。所以当使用字符输出流进行输出时就必须使用Flushable接口中提供的flush()方法强制性刷新缓冲区中的内容,否则数据将不会输出。
两类操作流程最大的区别在于自负六十用到了缓冲区(这样更适合进行中文数据的操作),而字节流是直接进行数据处理操作。所以当使用字符输出流进行输出时就必须使用Flushable接口中提供的flush()方法强制性刷新缓冲区中的内容,否则数据将不会输出。
范例:字符流输出并强制刷新缓冲区
public class JavaIODemo
{
public static void main(String args[])
{
File file=new File("D:"+File.separator+"hello"+File.separator+"mldn.txt");
if(!file.getParentFile().exists())
{
file.getParentFile().mkdirs();
}
Writer out=new FileWriter(file);
out.write("AAA");
out.append("AAA");
out.flush();
}
}
本程序在使用Writer类输出时使用了flush()方法,如果不使用此方法,男此时将不会有任何内容保存在文件中。
提问:必须使用flush()方法才可以输出吗
本程序在16.2.3小节详解过,当时并没有调用flush()方法,内容不也是能输出的吗
回答:字符流关闭时自动清空缓冲区
在讲解Writer类作用时的确没有明确调用flush()方法,但是调用的close()方法进行输出流关闭,在关闭的时候会洗东进行缓冲区的强制刷新,所以程序的内容才会正常保存在文件中。
16.2.6 转换流
转换流的设计目的是解决字节流与字符流之间操作类型的转换,java.io包中提供有两个转换流:OutputStreamWriter、InputStreamReader: 转换流实现类型转换的流程需要观察OutputStreamWriter与InputStreamReader类的定义结构和构造方法:
转换流实现类型转换的流程需要观察OutputStreamWriter与InputStreamReader类的定义结构和构造方法: 通过定义的继承结构可以发现OutputStreamWriter是Writer的子类,并且可以通过构造方法接收OutputStream类实例。InputStreamReader是Reader的子类,并且可以通过构造方法接收InputStream类实例,即只需要在转换流中传入相应的字节流实例就可以利用对象的向上转型逻辑将自己饿流转换为字符流操作:
通过定义的继承结构可以发现OutputStreamWriter是Writer的子类,并且可以通过构造方法接收OutputStream类实例。InputStreamReader是Reader的子类,并且可以通过构造方法接收InputStream类实例,即只需要在转换流中传入相应的字节流实例就可以利用对象的向上转型逻辑将自己饿流转换为字符流操作:
 范例:实现OutputStream与Writer转换
范例:实现OutputStream与Writer转换
package cn.mldn.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("D:"+File.separator+"hello"+File.separator+"mldn.txt");
if(!file.getParentFile().exists())
{
file.getParentFile().mkdirs();
}
OutputStream output=new FileOutputStream(file);
Writer out=new OutputStreamWriter(output);
out.write("AAA");
out.close();
output.close();
}
}
本程序利用转换流将字节输出流转为了字符输出流,这样就可以调用Writer类的write()方法直接输出字符串的内容。
提示:关于文件操作流
学习完了四个基本的流操作类,可以发现对于每一种流处理都有一个文件处理类,但是也可以发现,字节文件流都是字节流的直接子类,儿子读流中的两个操作流都是转换流的子类。
16.2.7 综合案例:文件复制
范例:实现复制操作
package cn.mldn.demo;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
class FileUtil
{
private File srcFile;
private File desFile;
public FileUtil(String src,String des)
{
this(new File(src),new File(des));
}
public FileUtil(File srcFile,File desFile)
{
this.srcFile=srcFile;
this.desFile=desFile;
}
private void copyImpl(File file)throws Exception
{
if(file.isDirectory())
{
File results[]=file.listFiles();
if(results!=null)
{
for(int x=0;x
copyImpl(results[x]);
}
}
else
{
if(file.isFile())
{
String newFilePath=file.getPath().replace(this.srcFile().getPath()+File.separator,"");
File newFile=new File(this.desFile,newFilePath);
this.copyFileImpl(file,newFile);
}
}
}
private boolean copyFileImpl(File srcFileTmp,File desFileTmp)throws IOException
{
if(!this.desFile,getParentFile().exists())
{
this.defFile.getParentFile().mkdirs();
}
InpitStream input=null;
OutputStream output=null;
input=new FileInputStream(srcFileTmp);
output=new FileOutputStream(desfileTmp);
input.transferTo(output);
return true;
input.close();
output.close();
}
}
public boolean copy()throws Exception
{
if(!this.srcFile.exists())
{
System.out.println("复制的文件不存在");
return false;
}
this.copyImpl(this.srcFile);
return true;
}
}
public class Copy{
public static void main(String []args)throws Exception
{
if(args.length!=2)
{
System.out.println(1);
}
long start=System.currentTimeMillis();
FileUtil fu=new FileUtil(args[0],args[1]);
fu.copy();
long end=System.currentTimeMills();
System.out.println("复制完成的试件"+(end-start));
}
}
本程序可以实现单个文件与文件目录的复制,所以在进行复制前回收箱判断传入的路径的形式,如果是文件,直接进行文件复制;如果是目录,则会将目录组成列出,随后逐个复制文件。
提示:关于InputStream类提供的transferTo()方法
从JDK1.9后才提供transferTo()方法,并且此方法也可以方便的将输入流中的数据保存在输出流中,但在JDK1.9之后,对于复制的操作实现需要通过循环的方式完成。
int len=0;
while((len=input.read(data))!=-1)
{
output.write(data,0,len);
}
16.3 字符编码
在计算机的世界中,所有县市的文字都是按照其指定的数字编码进行保存的,在以后济宁程序开发的过程中,会经常见到一些常见的编码。
ISO8859-1:是一种国际通用的单字节编码,最多只能表示0-255的自付范围,主要在英文传输中舒勇。
GBK/GB2312:中文的国际编码,专门用来表示汉字,是双字节编码,如果在英文传输中使用。
UNICODE:十六进制编码,可以准确地表示出任何语言文字,此编码不兼容ISO8859-1编码。
UTF-8:由于UNICODE不支持ISO8859-1编码,而且占用空间更多,英文字母也需要使用两个字节编码,这样使用UNICODE不便于传输和存储,因此产生了UTF编码。UTF编码兼容ISO8859-1编码同时也可以用来表示所有的语言字符,不过UTF编码是不定长编码,每一个字符的长度1-6个字节不等,因此一般在中文网页中使用此编码。
范例:获取本地系统默认编码
pakcage cn.mldn.demo;
public class JavaIODemo
{
public static void main(STring[]args)
{
System.out.println("系统默认编码"+System.getProperty("file.encodding"));
}
}
System类提供了获取本机环境属性的支持,从JDK1.9开始,Java中的默认编码为UTF-8
提示:程序乱码产生分析
在程序中如果处理不好字符的编码,就有可能出现乱码问题。如果本机默认的是GBK,但在程序中使用了ISO8859-1编码,就会出现字符乱码的问题,开发中使用最广泛的编码为UTF-8
下面通过一个程序讲解乱码产生的原因。现在本地默认编码是UTF-8,下面通过ISO8859-1编码对文字进行编码转换,则可以使用String类中的getBytes(String charset)方法,此方法可以设定指定的编码
范例:程序乱码产生
package cn.mldn.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
OutputStream output=new FileOutputStream("D:"+File.separartor+"mldn.txt");
output.write("中华文明".getBytes("ISO8859-1"));//编码为ISO8859-1
output.close();
}
}
本程序通过String类的getBytes()方法将字符串转为ISO8859-1编码,由于系统文件编码不同意,所以文件输出后的内容就成为乱码。
16.4 内存操作流
内存操作流是以内存作为操作终端实现的I/O数据处理,与文件操作不同的地方在于,内存操作流程不会进行磁盘数据操作,Java中提供一下两类内存操作刘
字节内存操作流程:ByteArrayOutputStream、ByteArrayInputStream,继承结构如图:
 范例:利用内存流实现小写字母转大写字母的操作
范例:利用内存流实现小写字母转大写字母的操作
pakcage cn.mldn.demo;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
String str="www.mldn.cn";
InputStream input=new ByteArrayInputStream(str.getBytes());
OutputStream outpu=new ByteArrayOutputStream();
int data=0;
while((data=input.read)!=-1)
{
output.write(Character.toUpperCase(data));
}
System.out.println(output);
input.close();
output.close();
}
}
本程序利用内存作为操作终端,将定义的字符串作为输入流的内容,并且通过循环获取每一个字节的数据,利用Charactor类提供的toUpperCase将小写字母转为大写字母保存在输出流中。
提示:ByteArrayOutputStream类的一个重要方法
ByteArrayOutputStream是内存的字节输出流操作类,所有的内容暂时都会保存在此类对象中,在此类中提供有一个获取全部数据的方法public byte[]toByteArray(),可以将全部的数据转为字节数据去除。
ByteArrayOutputStream output=new ByteArrayOutputStream();
int data=0;
while((data=input.read())!=-1)
{
output.write(Charactor.toUppercase(data));
}
byte result[]=output.toByteArray();
最初的时候可以利用该方法实现一个大文件内容的读取操作,通过合理的读取机制将每行数据读取出来保存到内存流,随后再将数据取出操作。
16.5 管道流
管道流的主要作用是可以进行两个线程间的通信,分为管道输出流(PipedOutputStream、PipedWriter、)、管道输入流(PipedInputStream、PipedReader),其继承结构如下
【PipedOutputStream】管道连接:public void connect(PipedInputStream snk)throws IOException
【PipedWriter】管道连接:public void connect(PipedReader snk)throws IOException 范例:使用字节流管道流实现线程通信
范例:使用字节流管道流实现线程通信
package cn.mldn.demo;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.pipedInpitStream;
import java.io.PipedOutputStream;
class SendThread implements Runnable
{
private PipedOutputStream output;//输出管道流
public SendThread(){this.output=new PipedOutputStream();
@Override
public void run()
{
this.output.write("AAAA");
this.output.close();
}
public PipedOutputStream getOutput()
{
return output;
}
}
class ReceiveThread implements Runnable
{
private PipedInputStream input;
public ReceiveThread(){this.input=new PipedInputStream();}
@Override
public void run(){byte[]data=new byte[1024];
int len=0;
ByteArrayOutputStream bos=new ByteArrayOutputStream();//通过内存流内容
while(len=this.input.read(data)!=-1)
{
bos.write(data,0,len);
}
System.out.println(nre String(bos.toByteArray()));
bos.close();
}
public PipedInputStream getInput(){return input;}
}
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
SendThread send=new SendThread();
ReceiveThread receive=new ReceiveThread();
send.getOutput().connect(receive.getInput());
new Thread(send,"消息发送线程").start();
new Thread(receive,"消息接收线程").start();
}
}
16.6 RandomAcessFile
RandomAcessFile可以实现文件数据的随机读取,即通过对文件内部读取位置的自由定义,已实现部分数据的读取操作,所有在使用此类操作时就必须保证写入数据时数据格式长度统一。方法如下: 现在假设要通过文件实现以下3个数据的保存操作(格式:姓名/年龄):"zhangsan/30""lisi/16","wangwu/20",此时姓名数据的最大保存长度为8位,数字的长度为4位。那么想要使用RandomAccessFile实现随机读取,就必须保证姓名数据的长度,那么可以通过追加空格来填充空位
现在假设要通过文件实现以下3个数据的保存操作(格式:姓名/年龄):"zhangsan/30""lisi/16","wangwu/20",此时姓名数据的最大保存长度为8位,数字的长度为4位。那么想要使用RandomAccessFile实现随机读取,就必须保证姓名数据的长度,那么可以通过追加空格来填充空位 范例:使用RandomAccessFile写入数据
范例:使用RandomAccessFile写入数据
package cn.mldn.demo;
import java.io.File;
import java.io.RandomAcessFile;
public class JavaIODemo
{
public static void main(STring[]args)throws Exception
{
File file=new File("D:"+File.separator+"mldn.txt");
//要保存的姓名数据,为了保证长度一致,使用空格填充
String names[]=new String[]{"zhangsan","lisi ","wangwu "};
int ages[]=new int[]{30,20,16};
for(int x=0;x
raf.write(names[x].getBytes());
raf.writeInt(ages[x]);
}
raf.close();
}
}
RandomAccessFile;类具备数据的写入和读取能力,本程序为了方便操作使用了rw读/写模式,随后利用循环将内容写入文件中。
范例:使用RandomAccessFile读取数据
package cn.mldn.demo;
import java.io.File;
import java.io.RandomAcessFile
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("D:"+file.separator+"mldn.txt");
RandomAcessFile raf=new RandomAcessFile(file,"rw");
{
//读取王五的数据,跳过24位
raf.skipBytes(24);
byte[]data=new byts[8];
int len=raf.read(data);
System.out.println(""+new String(data,0,len).trim()+raf.readInt());
}
}
}
16.7 打印流
在java.io包中对于数据的输出操作可以通过OutputStream类或Writer类完成,但这两个输出类本身存在一定的局限性。例如,OutputStream只允许输出字节数据,Writer只允许输出字符数据和字符串数据。而在实际的项目开发中,会有许多类型的数据需要输出(例如,整数、浮点数、字符、应用对象),因而为了简化输出的操作提供了两个打印流操作类:字节打印流(printStream)、字符打印流(PrintWriter) PrintStream类与PrintWriter类中定义的方法形式非常类似,下面是PrintWriter类的常用方法
PrintStream类与PrintWriter类中定义的方法形式非常类似,下面是PrintWriter类的常用方法
 范例:使用PrinterWriter实现文件内容输出
范例:使用PrinterWriter实现文件内容输出
package cn.mldn.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.PrintWriter;
pubic class JavaIODemo
{
public static void main(String[]args)throws Exception
{
File file=new File("d:"+File.separator+"mldn.txt");
PrintWriter pu=new PrintWriter(new FileOutputStream(file));
pu.println("姓名:mldn");
pu.print("年龄");
pu.println(15);
pu.clsoe();
}
}
本程序通过PrintWriter实现了文件数据的输出操作,并且通过实际的执行结果可以发现,打印流支持多种数据类型。
提示:装饰设计模式与打印流
通过程序的执行代码可以发现,打印流设计的思路非常简单,弥补已有输出流的不足,而本质上并没有脱离输出流的本质,这样的设计在Java中被称为装饰设计模式(Decorator Pattern),为了方便理解装饰设计,下面模拟打印流实现机制。
范例:模拟打印流完善输出类支持
class PrintUtil implements AutoCloseable
{
private OutputStream output;
public PrintUtil(OutputStream output){this.output=output;}
@Override
public void close()throws Exception{this.output.close();}
public void println(long sum){this.println(String.valueOf(num));}
public void print(String str){this.output.write(str.getBytes());}
public void println(String str){this.print(str+"\r\n");}
}
本程序中通过构造方法接收OutputStream类对象,这样就可以确定打印的输出位置,同时不同类型的数据输出依靠的依然是输出流所提供的方法。
从JDK1.5开始打印流支持了格式化输出的操作,可以利用printf()方法设置数据的占位符(字符串%s,整数%d,浮点数%m.nf,字符%c).
范例:格式化输出
package cn.mldn.demo
import java.io.File;
import java.io.FileOutputStream;
import java.io.PrintWriter;
public class JavaIODemo
{
public static void main(String []args)throws Exception
{
File file=new File("d:"+File.separator+"mldn.txt");
PrinterWriter pu=new PrinterWriter(new FileOutputStream(file));
String name="mldn";
int age=15;
double salary=1111;
pu.printf("姓名%s,年龄%d,收入%9.2f",name,age,salary);
pu.close();
}
}
16.8 System类对于I/O的支持
System类是系统类,在这个类中定义有3个与I/O操作有关的常量,这些常量的定义和作用:
 从上表可以发现System类的3个常量有两个都是PrintStream类的实力,所以之前一直使用的System.out.println()操作实际上就是利用了I/O操作来完成的。
从上表可以发现System类的3个常量有两个都是PrintStream类的实力,所以之前一直使用的System.out.println()操作实际上就是利用了I/O操作来完成的。
提示:由于System类出现的比较早,存在命名不标准的问题,这里可以发现out、err、in三个全局常量的名称全部都是小写字母。
范例:实现信息输出
package cn.mldn.demo;
public class JavaIODemo;
public static void main(String[]args)throws Exception
{
try
{
Interger.parseInt("mldn");
}catch(NumberFormatException e)
{
System.out.println(e);
System.out.println(e);
}
}
本程序由于将字符串“mldn”强制变为int型数据,所以发生了异常,而此时异常处理中分别使用System.out和System.err输出了异常类对象,单输出结果相同,所以这两者没有任何区别。但Java本身的规定是这样解释的:System.err输出的不希望用户看见的错误,而System.out输出的是希望用户看见的错误。
提示:IDE中适合观察System.out和System.in的区别
如果只是通过命令行的方式之星,System.er和System.out输出的内容是完全相同的,但是如果在开发工具上执行,两者的输出会使用不同颜色表示,Eclipse中,如果执行了System.err则输出的文本为红色,所以一部分开发人员在进行代码调试时,为了方便找到所需要的信息使用System.err输出内容。
System.in提供了一个键盘输入数据的INputStream实例,通过此常量就可以实现用户和程序的数据交互处理。
范例:使用System.in实现键盘数据输入
package cn.mldn.demo;
import java.io.InputStream;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
InputStream input=System.in;
System.out.println("请输入数据");
byte[]data=new byte[1024];
int len=input.read(data);
System.out.println("输入内容为"+new String(data,0,len));
}
}
16.9 BufferedReader缓冲输入流
BufferedReader提供了一种字符流的缓冲区数据读取,利用此类进行数据读取时会将读取到的数据暂时保存在缓冲区中,而后利用其内部提供的方法将读取到的内容一次性取出。BufferedReader类常用方法如下:
| No | 方法 | 类型 | 描述 |
| 1 | public BufferedReader(Reader in) | 构造 | 接受一个Reader类的实例 |
| 2 | public String readLine()throws IOException | 普通 | 一次次从缓冲区中将内容全部取出来 |
BufferedReader定义的构造方法只能接受字符输入流的实例,所以必须使用字符输入转换流InputStreamReader类将字节输入流System.i转变为字符流 范例:实现键盘数据输入
范例:实现键盘数据输入
pakcage cn.mldn.demo;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class JavaIODemo
{
public static void main(String []args)throws Exception
{
BufferedReader input=new BufferedReader(new InputStreamReader(System.in));
System.out.println("请输入您的年龄");
String msg=input.readLine();
if(msg.matches("\\d{1,3}"))
{
int age=Interger.parseInt(msg);
System.out.println(""+age);
}else
{
System.out.println("输入的内容不是数字");
}
}
}
16.10 Scanner输入流工具
在JDK1.5后Java提供了专门的输入数据类型,此类不仅可以完成之前的输入数据操作,也可以方便的对输入数据进行验证,此类放在java.util包中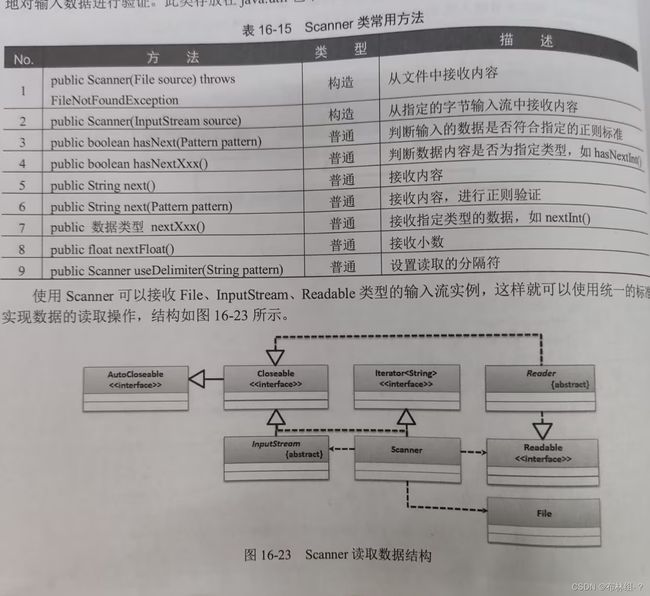 范例:使用canner实现键盘数据输入
范例:使用canner实现键盘数据输入
package cn.mldn.demo;
import java.util.Scanner;
public class JavaIODemo
{
Scanner scan=new Scanner(System.in);
System.out.print("请输入年龄:");
if(scan.hasNextInt())
{
int age=scan.nextInt();
System.out.println("年龄"+age);
}else
{
System.out.println("输入的内容不是数字,程序无法正常执行");
}
}
范例:输入日期数据,并使用正则判断格式
package cn.mldn.demo;
import java.text.SimpleDateFormat;
import java.util.Scanner;
public class JavaIODemo
{
public static void main(String[]args)throws Exception
{
Scanner scan=new Scanner(System.in);
System.out.println("请输入您的生日");
if(scan.hasNext("\\d{4}-\\d{2}-\\d{2})")
{
String str=scan.next("\\d{4}-\\d{2}-\\d{2})");
Systen.out.println("输入信息为"+new SimpleDateFormat("yyyy-MM-dd").parse(str));
}
scan.close();
}
}
范例:读取文件内容
package cn.mldn.demo;
import java.io.File;
import java.util.Scanner;
public class JavaIODemo
{
public static void main(String []args)throws Exception
{
Scanner scan=new Scanner(new File("D:"+file.separator+"mldn-info.txt"));
scan.useDelimiter("\n");
while(scan.hasNext())
{
System.out.println(scan.next());
}
scan.close();
}
}
16.11 对象序列化
对象序列化,就是把一个对象变为二进制的数据流的一种方法,,通过对象序列化可以方便的实现对象的传输或存储
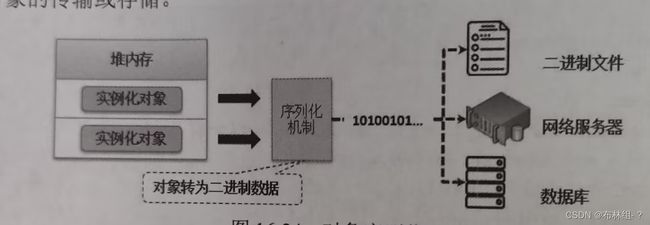 一个类的对象要想被序列化,择对象所在得类必须实现java.io.Serializable接口,然而此接口并没有提供任何的抽象方法,所以该接口是一个标识接口,只是表示一种对象可以被序列化的能力。
一个类的对象要想被序列化,择对象所在得类必须实现java.io.Serializable接口,然而此接口并没有提供任何的抽象方法,所以该接口是一个标识接口,只是表示一种对象可以被序列化的能力。
范例:定义序列化对象类
@suppressWarnings("serial");
class Mmeber implements Serializable
{
private String name;
private int age;
public Member(String nmae,int age)
{
this.name=name;this.age=age;
}
@Oerride
public String toString()
{
return ""+this.name+this.age;
}
}
本程序定义了Mmember类实现了Serializable接口,所以此类的实例化对象都允许进行二进制传输
提示:对象序列化的对象反序列化操作时的版本兼容性问题
在对象进行序列化或反序列化擦走哦的时候,要考虑JDK版本的问题,如果序列化的JDK版本盒反序列化的JDK版本不同意就可能造成异常。所以在序列化操作中引入了一个serialVersionUID的常量,可以通过此常量来验证版本的一致性。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地响应实体(类)的serialVersionUID进行比较,如果相同则认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量,当Java序列化机制在编译时会自动生成一个此版本的serialVersionUID。当然,如果不希望通过编译来自动生成,也可以直接显式定义一个名为serialVersionUID,类型为long的变量,那么只要不修改这个变量值的序列化实体都可以进行序列化和反序列化。
16.11.1 序列化与反序列化处理
Serializable接口只是定义了某一个类的对象是否可被允许序列化的支持,然而对于对象序列化和反序列化的具体事项,则需要依赖ObjectOutputStream与ObjectInputStream两类完成: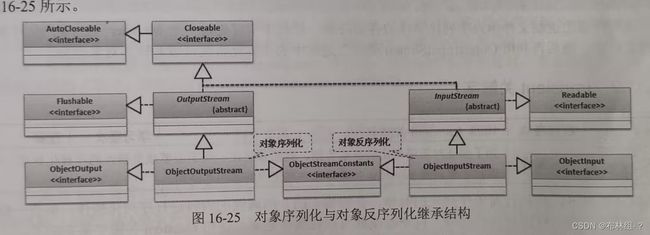 范例:实现对象序列化和反序列化操作
范例:实现对象序列化和反序列化操作
public class JavaIODemo
{
private static finale File SAVE_FILE=new File("D:"+File.separator+"mldn.member");
public static void main(String []args)throws Exception
{
saveObject(new Member("小李老师",18));
system.out.println(LoadObject());
}
public static void saveObject(Object obj)throws Exception
{
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream(SAVE_FILE));
oos.writeObject(obj);
oos.close();
}
public static Object loadObject()throws Exception
{
ObjectInputStream ios=new ObjectInputStream(new FileInputStream(SAVE_FILE));
Object obj=ois.readObject();
ois.close();
return obj;
}
}
本程序以二进制文件作为序列化操作的存储终端,在程序中首先讲一个Member类的实例化对象输出到文件中,随后再利用ObjectInputStream类二进制中的序列化数据读取并转化为对象返回。
16.11.2 transient关键字
默认情况下,当执行对象序列化的时候,会将类中的全部塑性的内容进行序列化操作,但有一些属性并不需要进行序列化的处理,这个时候就可以在属性定义上使用transient关键字来完成了。
@SuppressWarnings(""serial)
class Member implements Serializable
{
private transient String name;
private int age;
}
本程序如果要进行Mmeber类的对象序列化处理室,那么塑性的内容不会被保存下来,这样在进行反序列化操作时,那么使用的讲师其对应数据类型的默认值。