【分布式id生成系统——leaf源码】
分布式id生成系统——leaf源码
- 号段模式
-
- 双buffer优化
- id获取
Leaf ,分布式 ID 生成系统,有两种生成 ID 的方式:
- 号段模式
- Snowflake模式
号段模式
由于号段模式依赖于数据库表,我们先看一下相关的数据库表:
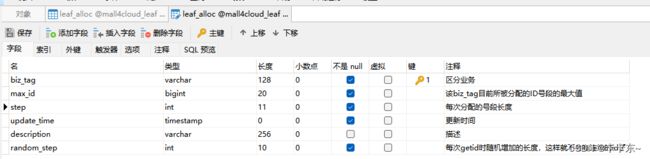
biz_tag:针对不同业务需求,用biz_tag字段来隔离,如果以后需要扩容时,只需对biz_tag分库分表即可
max_id:当前业务号段的最大值,用于计算下一个号段
step:步长,也就是每次获取ID的数量
random_step: 每次getid时随机增加的长度
对应的实体类如下
import java.util.concurrent.atomic.AtomicLong;
/**
* @author left
*/
public class Segment {
private AtomicLong value = new AtomicLong(0); //对 long 类型的变量进行原子操作,这里就是产生的id值
private volatile long max; //当前号段起始id
private volatile int step; //每次缓存数量
private volatile int randomStep; //随机增长
private final SegmentBuffer buffer; //双buffer
}
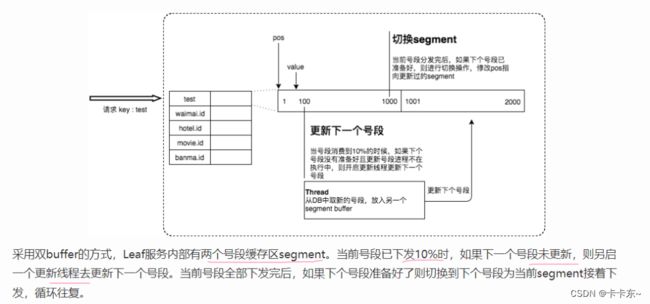
这样一看,就是在把数据库的自增方式放到了内存中,相当于加了一层缓存,减少了数据库的访问次数。但其实做的比这更好,程序通过一种双 Buffer 优化方式,提前缓存下一个 Segement,降低网络请求的耗时。
双buffer优化
思路如下
数据库表对应的实体类如下:
/**
* @author leaf
*/
public class LeafAlloc {
private String key;
private long maxId;
private int step;
private String updateTime;
private int randomStep;
}
这个类是用于缓存的类
public class SegmentBuffer {
private String key; //对应了数据库中的biz_tag
/**
* 双buffer
*/
private final Segment[] segments;
/**
* 当前的使用的segment的index
*/
private volatile int currentPos;
/**
* 下一个segment是否处于可切换状态
*/
private volatile boolean nextReady;
/**
* 是否初始化完成
*/
private volatile boolean initOk;
/**
* 线程是否在运行中
*/
private final AtomicBoolean threadRunning;
private final ReadWriteLock lock;
private volatile int step;
private volatile int minStep;
private volatile long updateTimestamp;
}
下面从具体代码来体现:
首先是程序启动后,对SegmentService进行实例化,在通过构造方法实例化SegmentService时,首先对IDAllocDao进行了创建,这里的dao层没有直接用@Mapper注解去创建实现,而是通过实现类实现IDAllocDaoImpl方式(主要原因应该是作为被引入的包,mapper注解可能扫描不到对应的sql吧)。
@Service("SegmentService")
public class SegmentService {
private final Logger logger = LoggerFactory.getLogger(SegmentService.class);
private final IDGen idGen;
public SegmentService(DataSource dataSource) throws InitException {
// Config Dao
IDAllocDao dao = new IDAllocDaoImpl(dataSource);
// Config ID Gen
idGen = new SegmentIDGenImpl();
((SegmentIDGenImpl) idGen).setDao(dao);
if (idGen.init()) {
logger.info("Segment Service Init Successfully");
}
else {
throw new InitException("Segment Service Init Fail");
}
}
public IDAllocDaoImpl(DataSource dataSource) {
// 创建事务工厂
TransactionFactory transactionFactory = new JdbcTransactionFactory();
// 创建MyBatis环境
Environment environment = new Environment("development", transactionFactory, dataSource);
// 创建MyBatis配置对象
Configuration configuration = new Configuration(environment);
// 添加IDAllocMapper映射
configuration.addMapper(IDAllocMapper.class);
// 构建SqlSessionFactory
sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
}
接下来这里的idGen.init(),初始化发号器,方法调用了updateCacheFromDb()和updateCacheFromDbAtEveryMinute()对数据进行缓存。updateCacheFromDb()中,SegmentBuffer buffer = new SegmentBuffer();创建了SegmentBuffer,初始化时建立一个Segment[]数组保存了当前的SegmentBuffer 。其他就是初始化需要的值

主要代码及注释如下:
@Override
public boolean init() {
logger.info("Init ...");
// 确保加载到kv后才初始化成功
updateCacheFromDb();
initOk = true;
//60s的定时更新号段
updateCacheFromDbAtEveryMinute();
return initOk;
}
private void updateCacheFromDb() {
logger.info("update cache from db");
try {
List<String> dbTags = dao.getAllTags();
if (dbTags == null || dbTags.isEmpty()) {
return;
}
List<String> cacheTags = new ArrayList<String>(cache.keySet());
Set<String> insertTagsSet = new HashSet<>(dbTags);
Set<String> removeTagsSet = new HashSet<>(cacheTags);
// db中新加的tags灌进cache
for (int i = 0; i < cacheTags.size(); i++) {
String tmp = cacheTags.get(i);
insertTagsSet.remove(tmp);
}
for (String tag : insertTagsSet) {
SegmentBuffer buffer = new SegmentBuffer();
buffer.setKey(tag);
//取当前位置的Segment,第一次取第一个位置的
Segment segment = buffer.getCurrent();
//初始化为0
segment.setValue(new AtomicLong(0));
segment.setMax(0);
segment.setStep(0);
//缓存
cache.put(tag, buffer);
logger.info("Add tag {} from db to IdCache, SegmentBuffer {}", tag, buffer);
}
//遍历数据库中的tags,如果数据库中的存在,removeTagsSet就不保存
for (int i = 0; i < dbTags.size(); i++) {
String tmp = dbTags.get(i);
removeTagsSet.remove(tmp);
}
// cache中已失效的tags从cache删除
for (String tag : removeTagsSet) {
cache.remove(tag);
logger.info("Remove tag {} from IdCache", tag);
}
}
catch (Exception e) {
logger.warn("update cache from db exception", e);
}
}
updateCacheFromDbAtEveryMinute()做了一个定时任务,定时刷新updateCacheFromDb();
private void updateCacheFromDbAtEveryMinute() {
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor(new ThreadFactory() {
@Override
//指定线程内容
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("check-idCache-thread");
//设置为守护线程,如果主线程结束,跟着结束
t.setDaemon(true);
return t;
}
});
//定时任务执行,60s后每60s执行一次
service.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
updateCacheFromDb();
}
}, 60, 60, TimeUnit.SECONDS);
}
id获取
这里通过请求一个用户注册接口,来获取一个用户id。通过fegin调用来调用getId服务

获取id的代码如下:
@Override
public Result get(final String key) {
if (!initOk) {
return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);
}
//通过key获取缓存
SegmentBuffer buffer = cache.get(key);
if (buffer != null) {
if (buffer.isInitOk()) {
//未初始化,锁住这个buffer,其他线程不可修改
synchronized (buffer) {
if (buffer.isInitOk()) {
try {
//从数据库中更新号段
updateSegmentFromDb(key, buffer.getCurrent());
logger.info("Init buffer. Update leafkey {} {} from db", key, buffer.getCurrent());
buffer.setInitOk(true);
}
catch (Exception e) {
logger.warn("Init buffer {} exception", buffer.getCurrent(), e);
}
}
}
}
return getIdFromSegmentBuffer(cache.get(key));
}
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
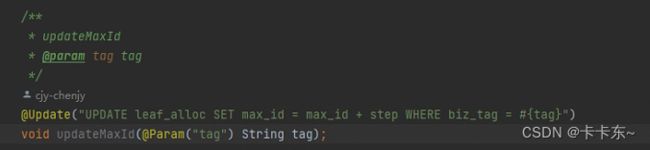
第一个核心代码:从数据库中更新号段

①:如果buffer是没有初始化,首先对数据库的号段最大值进行更新,更新完成后,获取结果,这里相当于是获取了一次缓存。更新方式是让max_id增加一次step。目前库中的step是100,也就是每次取100个号
②:第二种情况是,buffer已经初始化了,但是未发生过更新,这里就是走额外线程去获取第二层缓存了。
③④:一个segment的过期时间是15分钟,未过期,nextStep正常扩容为2倍,并且数据库进行更新
⑤:

⑥⑦:上诉对step操作完成后,根据key更新max_id,max_id值更新为max_id+step,相当于如果15分钟后,未使用的id将会被舍弃。
⑧:上面的三个if完成后,获取到value值,对当前的segment设置。
第二个核心代码:从缓存中获取id

①:
