Linux组调度
为什么引入组调度可以参考这篇文章的讨论。核心原因是基础的调度算法都是基于任务的,如果用户A有10个任务,用户B只有1个任务,假设这些任务的优先级都相同,那么用户A得到的CPU时间将是用户B的10倍,这样从任务的角度看虽然是公平的,但是从用户角度看这不一定合理。引入组调度后,可以将用户A的任务安排为GroupA,用户B的任务安排为GroupB,调度算法在GroupA和GroupB之间平均分配CPU时间即可,由此可以解决上面提到的问题。
组调度是一个可选的特性,基础开关为CONFIG_SCHED_GROUP,开启该开关后,将基于CGROUP机制实现一个名为cpu的资源控制器,该控制器实现对CPU时间的管理。目前只有RT调度器和CFS调度器支持组调度,它们的开关分别为CONFIG_RT_GROUP_SCHED和CONFIG_FAIR_GROUP_SCHED,要实现完整的组调度功能,这两个宏至少要打开一个。
为了减小理解组调度的难度,这篇笔记以RT组调度为例分析组调度相关的实现,CFS组调度的实现在单独的笔记中总结。
关键数据结构
任务组: task_group
组调度引入了task_group表示任务组,task_group和cgroup分组对应,每个cgroup分组都会存在一个对应的task_group实例。
struct task_group {
struct cgroup_subsys_state css; // ---(1)
#ifdef CONFIG_FAIR_GROUP_SCHED // ---(2)
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
struct cfs_rq **cfs_rq;
unsigned long shares;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu; // ---(3)
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
struct cfs_bandwidth cfs_bandwidth;
};- CGROUP相关字段。
- 分别对应RT任务组调度和CFS任务组调度的字段。核心字段是rq数组和se数组,每个CPU对应一个调度实体和一个运行队列。见下面“任务的组织”部分介绍
- 用来组织系统中所有的task_group实例,见下面“任务组的管理”部分介绍。
任务组的管理
系统用一个链表+一棵树来管理所有的task_group实例:
- 用list字段将所有task_group实例组织为一个链表,表头为task_groups。
LIST_HEAD(task_groups);- 属于同一层的task_group实例用siblings字段组织成链表,链表头为上一层task_group实例中的children字段。下一层task_group实例的parent字段指向上一层的task_group实例。系统定义了一个根任务组root_task_group实例,根分组也是默认的任务分组。
/*
* Default task group.
* Every task in system belongs to this group at bootup.
*/
struct task_group root_task_group;下图表示在根分组下有两个一级分组的数据结构示意图:
- 红色线条表示所有的分组形成单链表;绿色的线条表示相邻两个层级之间的task_group实例是如何组织的。
- 根分组没有parent,其它分组的parent指向其上一层级的task_group实例。

任务的组织
每个task_group实例对应一个分组,一个分组进一步由若干个任务和子分组组织,如此嵌套,则系统中所有的任务都分散组织在了task_group树中。我们知道调度单位是任务,所以每个task_group实例需要能够合理的管理属于自己的任务和子分组。
首先,task_group针对每个CPU都有一个运行队列,该运行队列管理了所有属于该分组并且调度到该CPU上的任务。
其次,支持组调度后,调度实体的概念进行了扩展,它不仅仅可以代表一个任务,也可以代表一个任务组。task_group针对每个CPU都分配一个调度实体,这样,每当该分组有任务分配到某个CPU上时,就可以将对应CPU的调度实体挂到该任务组的父亲的对应CPU运行队列中。
假设一个系统有任务TaskA、TaskB以及任务组GroupA、GroupB,其中GroupA为根分组,GroupA包含GroupB分组以及TaskA,TaskB属于GroupB。下图为相关数据结构(以RT任务为例)示意图。
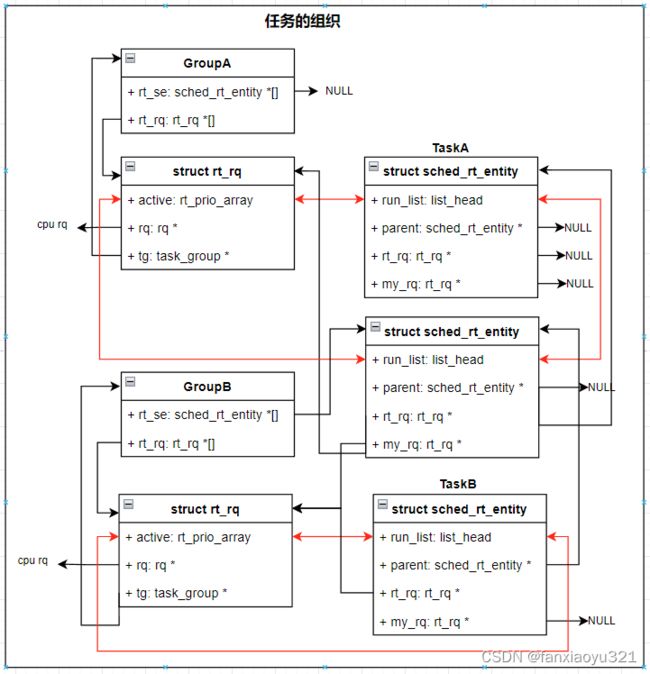
- GroupA为根任务组,它包含了GroupB和TaskA,所以TaskA的调度实体和GroupB的调度实体会被组织到GroupA的运行队列中。特别的,GroupA为根分组,其运行队列就是CPU的运行队列。
- 由于GroupA为根分组,所以其不需要调度实体,因为调度器总是会从它的运行队列开始寻找要运行的任务。
- GoupB作为一个普通分组,它有自己的调度实体,通过该调度实体才能将GroupB组织到GroupA的运行队列中。
- GroupB只包含了TaskB,所以它的运行队列中只有TaskB的调度实体。
运行队列&调度实体
运行队列(以RT运行队列为例)中增加了如下和组调度相关的字段:
- 保存了运行队列中最高优先级的调度实体,其作用后面介绍。
- rq指向CPU的运行队列。tg指向运行队列所属任务组,特别的,CPU运行队列中的该字段指向根任务组。
struct rt_rq {
struct rt_prio_array active;
...
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
} highest_prio; // ---(1)
#endif
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
struct rq *rq; // ---(2)
struct task_group *tg;
#endif
};调度实体(以RT调度实体为例)中增加了如下和组调度相关的字段:
- 如果调度实体代表一个任务,rt_rq指向所属任务组的运行队列;parent指向所属任务组的调度实体;my_q为NULL。如果它代表一个任务组,rt_rq指向上一层任务组的运行队列;parent指向上一层任务组的调度实体;my_q指向该任务组自己的运行队列,即用来管理属于自己这个任务组的调度实体的运行队列。
struct sched_rt_entity {
struct list_head run_list;
struct sched_rt_entity *back; // 作用见下面RT任务组优先级部分介绍
...
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent; // ---(1)
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};开机初始化
开机时,在sched_init()中会对根任务组实例进行初始化,下面列出相关代码:
- 根据CPU个数,为根任务组root_task_group分配调度实体指针数组和运行队列指针数组。
- 带宽控制相关逻辑。
- 将根任务组root_task_group添加到全局任务组链表中,并初始化其树形结构字段。
- 根据每个CPU运行队列,初始化根任务组的调度实体和运行队列。
void __init sched_init(void)
{
int i, j;
unsigned long alloc_size = 0, ptr;
#ifdef CONFIG_FAIR_GROUP_SCHED // ---(1)
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
#ifdef CONFIG_RT_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
if (alloc_size) {
ptr = (unsigned long)kzalloc(alloc_size, GFP_NOWAIT);
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.se = (struct sched_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.cfs_rq = (struct cfs_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_RT_GROUP_SCHED
root_task_group.rt_se = (struct sched_rt_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.rt_rq = (struct rt_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_RT_GROUP_SCHED */
}
init_rt_bandwidth(&def_rt_bandwidth, // ---(2)
global_rt_period(), global_rt_runtime());
init_dl_bandwidth(&def_dl_bandwidth,
global_rt_period(), global_rt_runtime());
#ifdef CONFIG_RT_GROUP_SCHED
init_rt_bandwidth(&root_task_group.rt_bandwidth,
global_rt_period(), global_rt_runtime());
#endif /* CONFIG_RT_GROUP_SCHED */
#ifdef CONFIG_CGROUP_SCHED
list_add(&root_task_group.list, &task_groups); // ---(3)
INIT_LIST_HEAD(&root_task_group.children);
INIT_LIST_HEAD(&root_task_group.siblings);
autogroup_init(&init_task);
#endif /* CONFIG_CGROUP_SCHED */
for_each_possible_cpu(i) {
struct rq *rq = cpu_rq(i);
#ifdef CONFIG_FAIR_GROUP_SCHED // ---(4)
root_task_group.shares = ROOT_TASK_GROUP_LOAD;
INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);
init_cfs_bandwidth(&root_task_group.cfs_bandwidth);
init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);
#endif /* CONFIG_FAIR_GROUP_SCHED */
rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;
#ifdef CONFIG_RT_GROUP_SCHED
init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL); // ---(4)
#endif
}
}初始化RT任务组
该函数用来初始化RT任务组的调度实体和运行队列,当创建一个新的分组时被调用。从上面也可以看到它还被用来初始化根任务的运行队列,特别的,根任务组不需要调度实体,传入的参数为NULL;运行队列就是CPU的运行队列。
void init_tg_rt_entry(struct task_group *tg, struct rt_rq *rt_rq,
struct sched_rt_entity *rt_se, int cpu,
struct sched_rt_entity *parent)
{
struct rq *rq = cpu_rq(cpu);
rt_rq->highest_prio.curr = MAX_RT_PRIO; // ---(1)
rt_rq->rt_nr_boosted = 0;
rt_rq->rq = rq;
rt_rq->tg = tg;
tg->rt_rq[cpu] = rt_rq; // ---(2)
tg->rt_se[cpu] = rt_se;
if (!rt_se)
return;
if (!parent) // ---(3)
rt_se->rt_rq = &rq->rt;
else
rt_se->rt_rq = parent->my_q;
rt_se->my_q = rt_rq;
rt_se->parent = parent;
INIT_LIST_HEAD(&rt_se->run_list);
}- 设置新任务组的运行队列。新的任务组还没有包含任何调度实体,其最高优先级默认取100。其rq指向CPU运行队列,tg指向任务组实例。
- 保存任务组的调度实体和运行队列到任务组中。
- 设置任务组的调度实体。只有根任务组和一级任务组的parent为NULL,它们挂到CPU的运行队列中。其它任务组的rt_rq指向其上一层任务组的运行队列。
创建分组
当新建一个分组时,CGROUP框架会调用控制器的css_alloc回调函数来分配任务组,cpu控制器的实现函数为cpu_cgroup_css_alloc()。
static struct cgroup_subsys_state *
cpu_cgroup_css_alloc(struct cgroup_subsys_state *parent_css)
{
struct task_group *parent = css_tg(parent_css);
struct task_group *tg;
if (!parent) {
/* This is early initialization for the top cgroup */
return &root_task_group.css;
}
tg = sched_create_group(parent); // 创建并初始化一个新的任务组对象
if (IS_ERR(tg))
return ERR_PTR(-ENOMEM);
return &tg->css;
}创建&初始化任务组
- 分配task_group对象。
- 为任务组分配调度实体和运行队列。
struct task_group *sched_create_group(struct task_group *parent)
{
struct task_group *tg;
tg = kzalloc(sizeof(*tg), GFP_KERNEL); // ---(1)
if (!tg)
return ERR_PTR(-ENOMEM);
if (!alloc_fair_sched_group(tg, parent)) // ---(2)
goto err;
if (!alloc_rt_sched_group(tg, parent))
goto err;
return tg;
err:
free_sched_group(tg);
return ERR_PTR(-ENOMEM);
}下面以RT组调度为例看其实现:
- 为RT任务组分配每个CPU上的运行队列指针数组和调度实体指针数组。
- 分配每个CPU上的调度实体和运行队列,并对其进行初始化。
int alloc_rt_sched_group(struct task_group *tg, struct task_group *parent)
{
struct rt_rq *rt_rq;
struct sched_rt_entity *rt_se;
int i;
tg->rt_rq = kzalloc(sizeof(rt_rq) * nr_cpu_ids, GFP_KERNEL); // ---(1)
if (!tg->rt_rq)
goto err;
tg->rt_se = kzalloc(sizeof(rt_se) * nr_cpu_ids, GFP_KERNEL);
if (!tg->rt_se)
goto err;
init_rt_bandwidth(&tg->rt_bandwidth,
ktime_to_ns(def_rt_bandwidth.rt_period), 0);
for_each_possible_cpu(i) { // ---(2)
rt_rq = kzalloc_node(sizeof(struct rt_rq),
GFP_KERNEL, cpu_to_node(i));
if (!rt_rq)
goto err;
rt_se = kzalloc_node(sizeof(struct sched_rt_entity),
GFP_KERNEL, cpu_to_node(i));
if (!rt_se)
goto err_free_rq;
init_rt_rq(rt_rq, cpu_rq(i));
rt_rq->rt_runtime = tg->rt_bandwidth.rt_runtime;
init_tg_rt_entry(tg, rt_rq, rt_se, i, parent->rt_se[i]);
}
return 1;
err_free_rq:
kfree(rt_rq);
err:
return 0;
}任务创建
在新任务创建完毕后,CGROUP框架会调用控制器的fork回调函数,让控制器在任务创建时执行一些逻辑,cpu控制器的实现函数为cpu_cgroup_fork()。
static void cpu_cgroup_fork(struct task_struct *task)
{
sched_move_task(task); // 任务切换分组也是调用该函数
}
/* change task's runqueue when it moves between groups.
* The caller of this function should have put the task in its new group
* by now. This function just updates tsk->se.cfs_rq and tsk->se.parent to
* reflect its new group.
*/
void sched_move_task(struct task_struct *tsk)
{
struct task_group *tg;
int queued, running;
unsigned long flags;
struct rq *rq;
rq = task_rq_lock(tsk, &flags);
running = task_current(rq, tsk); // ---(1)
queued = task_on_rq_queued(tsk);
if (queued)
dequeue_task(rq, tsk, 0);
if (unlikely(running))
put_prev_task(rq, tsk);
/*
* All callers are synchronized by task_rq_lock(); we do not use RCU
* which is pointless here. Thus, we pass "true" to task_css_check()
* to prevent lockdep warnings.
*/
tg = container_of(task_css_check(tsk, cpu_cgrp_id, true),
struct task_group, css); // ---(2)
tg = autogroup_task_group(tsk, tg);
tsk->sched_task_group = tg;
#ifdef CONFIG_FAIR_GROUP_SCHED
if (tsk->sched_class->task_move_group)
tsk->sched_class->task_move_group(tsk, queued);
else
#endif
set_task_rq(tsk, task_cpu(tsk)); // ---(3)
if (unlikely(running)) // ---(1)
tsk->sched_class->set_curr_task(rq);
if (queued)
enqueue_task(rq, tsk, 0);
task_rq_unlock(rq, tsk, &flags);
}如注释所描述,调用sched_move_task()函数之前,真正的CGROUP分组相关的任务设置已经完成,该函数负责更新任务的调度实体中和组调度相关的内容:
- 执行该动作前,任务可能已经在CPU运行队列中,或者正在运行,那么先将其从队列中移除,设置完组调度相关内容后再将其加回去。
- 根据CGROUP的层级关系,找到该任务所属任务组对象,将其保存到任务的sched_task_group字段中。
- 调用set_task_rq()函数设置任务的调度实体中的parent为所属任务组的调度实体,xxx_rq为所属任务组的运行队列。
设置任务调度实体
set_task_rq()函数将任务的调度实体中的xx_rq和parent分别设置为所属任务组的运行队列和调度实体。
static inline void set_task_rq(struct task_struct *p, unsigned int cpu)
{
#if defined(CONFIG_FAIR_GROUP_SCHED) || defined(CONFIG_RT_GROUP_SCHED)
struct task_group *tg = task_group(p);
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
p->se.cfs_rq = tg->cfs_rq[cpu];
p->se.parent = tg->se[cpu];
#endif
#ifdef CONFIG_RT_GROUP_SCHED
p->rt.rt_rq = tg->rt_rq[cpu];
p->rt.parent = tg->rt_se[cpu];
#endif
}RT调度器选择任务
在没有组调度的情况下,调度框架在调用RT的pick_next_task回调选择任务时,直接从CPU运行队列中选择优先级最高的任务即可。支持组调度后,由于每个任务组都是用独立的运行队列来管理组内调度实体的,所以任务的选择过程应该是个递归的过程,下面重新来看其中最终要的_pick_next_rt()函数实现。
static struct task_struct *_pick_next_task_rt(struct rq *rq)
{
struct sched_rt_entity *rt_se;
struct task_struct *p;
struct rt_rq *rt_rq = &rq->rt;
do {
rt_se = pick_next_rt_entity(rq, rt_rq); // ---(1)
BUG_ON(!rt_se);
rt_rq = group_rt_rq(rt_se);
} while (rt_rq); // ---(2)
p = rt_task_of(rt_se);
p->se.exec_start = rq_clock_task(rq);
return p;
}
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,
struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
idx = sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
next = list_entry(queue->next, struct sched_rt_entity, run_list);
return next;
}
- pick_next_rt_entity()函数从参数指定的运行队列中找到优先级最高的调度实体,该调度实体可能时任务,也可能是一个任务组。
- group_rt_rq()函数返回调度实体的my_q,如果找到的是任务组,则返回的是该任务组的运行队列,循环会继续下一层的遍历;如果找到的是任务,那么返回为NULL,结束循环。
通过上面的遍历过程,只要每一个任务组都能够正确维护运行队列中的优先级数组,那么每次调用就都可以找到优先级最高的任务。
RT任务组优先级
如前面对RT调度器选择任务过程的分析,每个任务组都需要维护自己的优先级数组。支持组调度后,优先级数组中除了任务的调度实体外,还会有任务组的调度实体,所以也需要为任务组定义优先级。RT任务组的优先级定义为自己运行队列中优先级最高的调度实体的优先级。RT任务组的优先级保存在任务组运行队列的rt_rq.highest.curr字段中。
为了维护RT任务组的优先级,在调度实体入队和出队时需要进行优先级的更新,具体的函数为__enqueue_rt_entity()-->inc_rt_tasks()-->inc_rt_prio()和__dequeue_rt_entity()-->dec_rt_tasks()-->dec_rt_prio()。
static void
inc_rt_prio(struct rt_rq *rt_rq, int prio)
{
// 入队时,如果新的优先级更高则更新运行队列的最高优先级
int prev_prio = rt_rq->highest_prio.curr;
if (prio < prev_prio)
rt_rq->highest_prio.curr = prio;
inc_rt_prio_smp(rt_rq, prio, prev_prio);
}
static void dec_rt_prio(struct rt_rq *rt_rq, int prio)
{
// 出队的是最高优先级时重新计算最高优先级。队列为空时,优先级设置为100
int prev_prio = rt_rq->highest_prio.curr;
if (rt_rq->rt_nr_running) {
WARN_ON(prio < prev_prio);
if (prio == prev_prio) {
struct rt_prio_array *array = &rt_rq->active;
rt_rq->highest_prio.curr = sched_find_first_bit(array->bitmap);
}
} else
rt_rq->highest_prio.curr = MAX_RT_PRIO;
dec_rt_prio_smp(rt_rq, prio, prev_prio);
}上面的inc_rt_prio()和dec_rt_prio()仅仅维护了参数指定的运行队列的优先级,但每个CPU的运行队列中的可能有多个任务组,任何一个低层级的任务组中任务的需要入队或出队,都会影响从根任务组到其直属任务组的优先级。因此在入队和出队时需要额外的流程来维护所有层级上任务组的优先级,下面以一个虚拟的任务组结构来分析入队和出队时的任务组优先级变化。
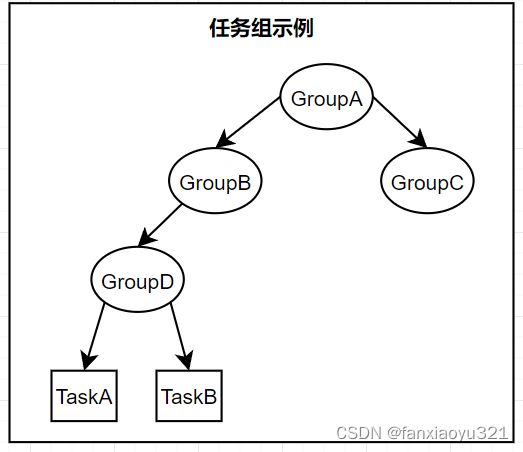
当TaskA入队和出队时,GroupA、GroupB、GroupD的优先级都需要更新。为了简化实现流程,内核在TaskA入队过程中,按照如下步骤执行:
- 按照GroupB->GroupD的顺序执行出队,这样随着出队过程不断更新各任务组的优先级,出队完毕后,GroupA、GroupB、GroupD的优先级都是正确的;
- 按照TaskA->GroupD->GroupB的顺序执行入队,这样随着入队过程不断更新各任务组的优先级,入队完毕后,GroupA、GroupB、GroupD的优先级都是正确的。
内核在TaskA出队过程中,按照如下步骤执行:
- 按照GroupB->GroupD->TaskA的顺序执行出队,这样随着出队过程不断更新各任务组的优先级,出队完毕后,GroupA、GroupB、GroupD的优先级都是正确的。
- 按照GroupD->GroupB的顺序执行入队,这样随着入队过程不断更新各任务组的优先级,入队完毕后,GroupA、GroupB、GroupD的优先级都是正确的。
这么做的好处是可以简化每个任务组在执行入队和出队时的处理逻辑,它们只需要处理好自己直接管理的调度实体即可,不需要操心祖先任务组的优先级更新。
调度实体入队
enqueue_rt_entity()函数负责将一个调度实体入队,该调度实体可以是任务也可以是任务组。任务入队函数enqueue_task_rt()最后也是调用该函数将任务加入队列中的。
static void enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
struct rq *rq = rq_of_rt_se(rt_se);
dequeue_rt_stack(rt_se); // 按照层级从高到低的顺序依次出队
for_each_sched_rt_entity(rt_se)
// 按照层级从低到高的顺序依次入队
__enqueue_rt_entity(rt_se, head);
enqueue_top_rt_rq(&rq->rt); // 重新设置CPU运行队列的可运行任务个数
}dequeue_rt_stack()
#define for_each_sched_rt_entity(rt_se) \
for (; rt_se; rt_se = rt_se->parent)
static void dequeue_rt_stack(struct sched_rt_entity *rt_se)
{
struct sched_rt_entity *back = NULL;
// 通过back指针得到一个从GroupB->GroupD->TaskA的调度实体链表
for_each_sched_rt_entity(rt_se) {
rt_se->back = back;
back = rt_se;
}
// rt_rq_of_se(back)得到的是CPU运行队列,所以直接会减去所有的任务
dequeue_top_rt_rq(rt_rq_of_se(back));
// 按照GroupB->GroupD->TaskA的顺序,将调度实体从所属运行队列中移除
for (rt_se = back; rt_se; rt_se = rt_se->back) {
if (on_rt_rq(rt_se))
__dequeue_rt_entity(rt_se);
}
}调度实体出队
dequeue_rt_entity()函数负责将一个调度实体出队,该调度实体可以是任务也可以是任务组。任务入队函数dequeue_task_rt()最后也是调用该函数将任务从队列中移除的。
static void dequeue_rt_entity(struct sched_rt_entity *rt_se)
{
struct rq *rq = rq_of_rt_se(rt_se);
dequeue_rt_stack(rt_se); // 按照层级从高到低的顺序依次出队
// 按照层级从低到高的顺序依次入队,这个过程只将非空的任务组调度实体入队,
// 所以步骤一中移除的最底层调度实体不会重新入队
for_each_sched_rt_entity(rt_se) {
struct rt_rq *rt_rq = group_rt_rq(rt_se);
if (rt_rq && rt_rq->rt_nr_running)
__enqueue_rt_entity(rt_se, false);
}
enqueue_top_rt_rq(&rq->rt); // 重新设置CPU运行队列的可运行任务个数
}