flink-connector-mysql-cdc编译——flink-1.15.2版本
xflink-cdc编译——flink-1.15.2版本
Flink目前最新版本已经更新到1.15.2版本,flink-cdc的release版本目前最新版本是2.2.1。flink-cdc官网的版本信息显示,2.2.*版本是支持flink1.13.及1.14.,并没有支持flink1.15.*的release版本,因此想尝试自己编译flink-cdc源码,踩了不少坑。发文记录一下,也希望给给有相同需求的同学一点小小的帮助(我自己就没有搜到相关的帖子)。

首先要做的是,获取flink-cdc的源码,一般获取源码有两种方式,一种是根据官网提供的下载链接下载特定的release版本,另一种是使用git命令从github上直接clone源码到本地,这里推荐使用第二种方式,因为使用git,不仅可以看到master分支的代码,还可以通过分支切换,来查看各种release版本的代码,在编译master分支时万一遇到版本问题,可以尝试根据release版本代码来修改master分支代码,且我本次编译过程中的确这么做了。
那下面准备动手
1、使用IDEA从github上下载flink-cdc源码
打开IDEA——>新建项目——>get from cvs

flink-cdc github仓库复制URL
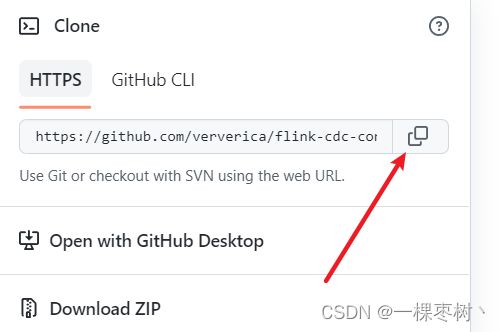

等待代码Clone完成——>等待maven加载项目依赖

项目加载完成

2、在master分支上修改Flink版本
首先,我的需求其实是只有一个flink-connector-mysql-cdc,因此本次只编译这一个模块以及它依赖的模块。那么首先要做的就是在父工程的pom文件中,将不需要的子模块都删掉或者注释掉,如下图,我这边只保留了 base、debezium、test-util(这个模块是个测试工具模块,也可以注释掉,但是因为每个项目都引用了这个模块,删起来嫌麻烦,就让它一起编译好了)、flink-connector-mysql-cdc以及flink-sql-connector-mysql-cdc,一共5个模块。

接下来进入整体,修改flink版本,flink1.15版本和之前有一些变动,暂且按下不表,我们一步一步往下做。
找到父工程pom文件中定义flink版本的地方,将版本修改为1.15.2,同时将scala版本修改为 2.12

需要注意的是,flink1.15版本,很多flink的jar包的 artifactId 和之前版本不一样了,区别如下
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>1.14.5version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-javaartifactId>
<version>1.15.2version>
<scope>providedscope>
dependency>
因此,我们需要继续修改pom文件中的flink相关依赖的 artifactId ,删除 _${scala.binary.version} 后缀,如下所示
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
修改成
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridgeartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
除了父工程的依赖,还要去修改我们保留的5个子模块中的pom文件中的flink相关依赖的 artifactId。这里就是代开子工程的pom文件一个一个去修改就行了,这里不一一列出具体过程。
需要特别说明的是,在flink-connector-mysql-cdc模块的pom文件中,有一个flink-table-planner的依赖,这个依赖的 artifactId 不用更改,这个依赖在1.15版本中,artifactId 也是带 scala版本后缀的
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>testscope>
dependency>
那么至此,对flink版本的修改就完成了,接下来就尝试编译,看flink-cdc的代码是否兼容flink-1.15.2。
不出意外的情况下,换版本一定会出点什么意外的,哈哈哈!!!*
3、开始编译
由于flink1.15版本的更新还不少,大概率代码是会出点什么问题的,比如版本升级会对之前代码中某个类或者某个方法做了一些修改,而cdc中又使用到了那段代码。废话不多说,先来编译一下试试看会有什么问题吧!
直接 install
果然,报错了
这个错误的原因就是找不到 org.apache.flink.connector.base 这个包。
那么有两种可能:
- 版本更新后,删除了这个包,或者是改了包名
- 相关依赖未成功引入
光靠这个包名,我是没有办法得知这个包属于哪个依赖的。
那么要怎么解决呢?我的思路是,release版本是稳定的版本,里面的版本都是兼容的,那么我可以将项目切到一个最近的release版本,找到这个类,然后通过强大的IDEA的定位功能,按住CTRL,点击包名,这样它会自动跳转到对应的jar包下,这样我就可以知道它是属于哪个依赖的了**(这也是在文章开头我建议通过git来获取cdc源码的原因)**
这里切分支之前,记得先 git commit 刚才在master分支做的修改,不然切换分支好像会删除没有 commit的 操作,那刚才修改版本的操作就得重新来一次了。

通过上述操作,我找到了这个jar包,名字叫 flink-cdc-base-1.1x.x.jar

然后回到master分支,检查项目 External Libraries 依赖中是否有这个jar
检查发现的确没有引入这个jar包,这里我猜测原因应该是1.15之前的版本,有些flink 的jar包会自己依赖这个 flink-connector-base,所以不需要手动引入。所以我们这里需要手动引入依赖即可。
在父工程pom文件中,添加如下依赖:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-baseartifactId>
<version>${flink.version}version>
dependency>
手动添加依赖后,再次 install 试试!!!!
依赖问题已解决,但是……
不出所料,果然代码兼容性有问题

这里暴露的问题就是,新版本的 LogicalTypeCheck 类中没有 hasFamily() 这个方法,也就是说,在flink旧版本中,是有这么个方法,但是在新版本中删掉了。这里我想要吐槽一下,不需要的方法可以标注为过期方法,不建议使用就是了,直接删了,不是会有兼容性问题嘛!!!!差评!!!!
幸运的情况下,也许就这一处代码有兼容性问题,不幸的话,可能有好多………………
走一步算一步,先来尝试解决这个问题吧!!!
我首先想到的是,去看看旧版本flink中这个方法的代码怎么写的,然后定义一个类继承自 LogicalTypeCheck 类,加一个 hasFamily() 方法,然后修改上图中这段代码,使用我自定义的 LogicalTypeCheck 的子类。
第一步,翻flink的源码,找到这个 LogicalTypeCheck 类中的 hasFamily() 方法。我这里懒得再去clone一份flink的源码了,就在github上直接翻flink-1.14.4(选这个版本,是因为cdc源码master分支本身的flink版本就是1.14.4)的代码,这里贴出这个类的github地址,感兴趣可以自己看看
https://github.com/apache/flink/blob/release-1.14.4/flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/logical/utils/LogicalTypeChecks.javagithub源码查看
public static boolean hasFamily(LogicalType logicalType, LogicalTypeFamily family) {
return logicalType.getTypeRoot().getFamilies().contains(family);
}
上图就是flink-1.14.4中 hasFamily() 方法的源码,然后我尝试自定义类 extends LogicalTypeCheck,发现报错,原因是 LogicalTypeCheck 类的定义是 final 类,不可以被继承。。。。。那也没啥大问题,我们来大致研究一下这个源码
private static Optional<DeserializationRuntimeConverter> createArrayConverter(
ArrayType arrayType) {
// 这个方法大致的逻辑就是,对ArrayType类型进行判断,判断其是否hasFamily,然后返回一个 Converter对象。逻辑很简单,那我能不能直接把hasFamily方法的逻辑写到这段代码中,而不是定义成一个方法,也就是直接把 logicalType.getTypeRoot().getFamilies().contains(family) 这句代码复制到下面这个 if()条件判断中去
if (LogicalTypeChecks.hasFamily(
arrayType.getElementType(), LogicalTypeFamily.CHARACTER_STRING)) {
// only map MySQL SET type to Flink ARRAY type
return Optional.of(
new DeserializationRuntimeConverter() {
private static final long serialVersionUID = 1L;
@Override
public Object convert(Object dbzObj, Schema schema) throws Exception {
if (EnumSet.LOGICAL_NAME.equals(schema.name())
&& dbzObj instanceof String) {
// for SET datatype in mysql, debezium will always
// return a string split by comma like "a,b,c"
String[] enums = ((String) dbzObj).split(",");
StringData[] elements = new StringData[enums.length];
for (int i = 0; i < enums.length; i++) {
elements[i] = StringData.fromString(enums[i]);
}
return new GenericArrayData(elements);
} else {
throw new IllegalArgumentException(
String.format(
"Unable convert to Flink ARRAY type from unexpected value '%s', "
+ "only SET type could be converted to ARRAY type for MySQL",
dbzObj));
}
}
});
} else {
// otherwise, fallback to default converter
return Optional.empty();
}
}
下面是直接 把 hasFamily() 方法的代码逻辑写到 if() 条件判断中
private static Optional<DeserializationRuntimeConverter> createArrayConverter(
ArrayType arrayType) {
if (arrayType.getElementType().getTypeRoot().getFamilies().contains(LogicalTypeFamily.CHARACTER_STRING)) {
// only map MySQL SET type to Flink ARRAY type
return Optional.of(
new DeserializationRuntimeConverter() {
private static final long serialVersionUID = 1L;
@Override
public Object convert(Object dbzObj, Schema schema) throws Exception {
if (EnumSet.LOGICAL_NAME.equals(schema.name())
&& dbzObj instanceof String) {
// for SET datatype in mysql, debezium will always
// return a string split by comma like "a,b,c"
String[] enums = ((String) dbzObj).split(",");
StringData[] elements = new StringData[enums.length];
for (int i = 0; i < enums.length; i++) {
elements[i] = StringData.fromString(enums[i]);
}
return new GenericArrayData(elements);
} else {
throw new IllegalArgumentException(
String.format(
"Unable convert to Flink ARRAY type from unexpected value '%s', "
+ "only SET type could be converted to ARRAY type for MySQL",
dbzObj));
}
}
});
} else {
// otherwise, fallback to default converter
return Optional.empty();
}
}
这样修改过代码后,我又尝试 install,但是又报错了

看到报错不要慌,看看报错信息是啥意思。这里的大致意思是,有一个检查代码格式的插件,检查出代码格式不符合规范(我就改了一行代码,也不规范吗???),并且给出了修改代码的提示,详见下图

修改完成后,再次 install 试试!!!!
What the f*** !!!
又失败了……

报错信息显示是一个叫 maven-surefire-plugin的插件,看起来是跟测试相关的,我对maven也不熟,百度一下吧

看来只要编译的时候设置跳过测试就可以了,IDEA的maven插件上有个图标,点一下就跳过测试了,如下图

见证奇迹的时刻!!!!
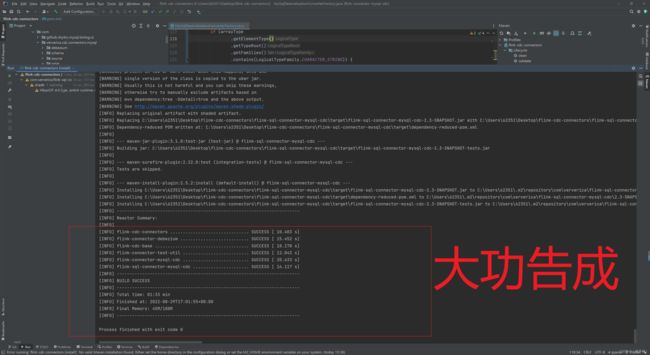
3、测试jar包是否可用
flink项目中 引入 刚编译好的 flink-sql-connector-mysql-cdc依赖。
com.ververica
flink-sql-connector-mysql-cdc
2.3-SNAPSHOT
flink-sql-connector-mysql-cdc本身是依赖于 flink-connector-mysql-cdc 的。

因此,只引入 flink-sql-connector-mysql-cdc 即可。
写flinksql代码进行测试
package FlinkSQL;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkCdcDorisConnectorDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(3000L);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String testCDCSource ="create table test_cdc ( \n" +
"id int, \n" +
"amount int," +
"primary key(id) not ENFORCED \n" +
") with ( \n" +
"'connector' = 'mysql-cdc', \n" +
"'hostname' = 'localhost', \n" +
"'port' = '3306', \n" +
"'username' = 'yourAcount', \n" +
"'password' = 'yourPassword', \n" +
"'database-name' = 'your_db', \n" +
"'table-name' = 'your_table' \n" +
")";
tableEnv.executeSql(testCDCSource);
Table table = tableEnv.sqlQuery("select * from test_cdc");
tableEnv.toChangelogStream(table).print();
env.execute();
}
}
运行代码,成功读取mysql中表的数据
对mysql源表执行写操作,验证是否实时同步


经验证,正常使用,至于有没有什么不知道的BUG,要深度使用以后才会知道,不过既然编译能通过了,就大概率是没有问题的了。
那这次编译flink-cdc的过程就完成了,希望对大家有所帮助!