小心你的大模型被基准评估坑了,模型直接傻掉!人大高瓴揭秘大模型作弊
作者 | 谢年年、Python
从 ChatGPT 横空出世到国内外「百模大战」打响以来,我们隔三差五就会看到某某大模型又超越多个模型,刷新SOTA,成功屠榜的消息。
这些榜单都是基于一系列高质量的评估基准创立的,从不同的方面比较LLMs的性能。典型的评估基准包括MMLU(用于衡量多任务语言理解能力)、Big-Bench(用于量化和外推LLMs的能力)以及AGIEval(用于评估应对人类级任务的能力)。
不同的评估基准就是一张张公开的试卷,LLMs参加考试以评估其能力。
既然是考试,公平公正就非常重要。但如果在考试之前LLMs已经偷看过原题或者做过模拟卷了呢,这种作弊行为势必会让模型效果大大提升。作弊的后果就是高估了大模型的能力,一到真实场景用户测试就露馅。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
http://hujiaoai.cn
这类问题称作基准泄露,如下图所示,LLMs使用了与基准评估数据集相关或完全相同的数据进行训练,导致模型性能异常提升。

但这个问题有时候并不是模型研发人员有意为之,而可能是无意识地引发的。在准备预训练语料库时,我们可能并不知道未来的评估数据集是什么。而预训练语料与评估数据集都是从网上爬取的,因此预训练语料中很有可能包含了评估数据集部分内容。例如,GPT-3发现了CBT数据集被包含在预训练语料库中,LLaMA-2提到直接从网页上提取的BoolQ数据集可能包含在公开可用的语料库中。
再加上,训练语料库的详细构成(例如数据来源)通常被视为现有LLMs的核心“秘密”,因此,在进行基准评估时,难以对数据污染问题直接进行检查。
人大高瓴团队通过设置几个常见的基准泄露情景训练了四个流行的语言模型,并在多个现有基准上测试模型性能,详细揭示了基准泄露的潜在风险,并基于风险提出几项解决措施。研究结果将有助于更好地了解现有基准所带来的潜在偏见和局限性,帮助研究人员在评估LLMs时做出更明智的决策。
论文标题:
Don’t Make Your LLM an Evaluation Benchmark Cheater
论文链接:
https://arxiv.org/pdf/2311.01964.pdf
基准泄露的实验设置
基准泄露情景预设
一个评估基准通常包含一组测试样例,并依赖于固定的模板来提示LLMs进行评估。这样的评估过程可能存在三种类型的基准泄露风险:
-
测试提示泄露
-
测试集泄露
-
其他相关数据(例如训练集)包含到预训练语料库中。
本文将以上泄露情况交叉用于训练LLMs,具体来说设置如下:
-
使用MMLU训练集:使用官方MMLU基准提供的辅助训练集训练大模型。
-
使用所有训练集:除了MMLU训练集外,还使用了所有其他收集的评估基准的训练集进行训练。
-
使用所有训练集+测试提示:使用所有训练集及其相应的测试提示例如任务描述和少样本演示进行训练。
-
使用所有训练集、测试提示和测试集:这是最极端的情况,其中所有信息都被泄露。
评估基准
为了进行研究,本文选择了广泛使用的基准MMLU,并使用了一些问答、推理和阅读理解数据集进行评估。
-
MMLU:涵盖了57个任务,涉及数学、历史、科学和法律等各种知识领域,已成为评估LLMs是否拥有世界知识和解决问题的能力方面最常用的评估基准之一。本文报告了5-shot评估性能。
-
开放域QA任务:LLMs应该完全基于内在知识回答问题。选择七个开放域QA数据集,包括BoolQ、PIQA、Hellaswag、WinoGrande、ARC Easy and Challenge、OpenBookQA,本文报告了zero-shot下的精度。
-
推理任务:采用常识推理数据集CommonsenseQA ,以及两个常用的数学推理数据集GSM8k 和AQuA进行评估。使用思维链提示和重用提示评估模型的准确性。
-
阅读理解任务:选择三个英文数据集RACE-Middle、RACEHigh、 CoQA 和两个中文数据集CMRC2018、C3-Dialog。
评估模型选择
为了深入分析基准泄露对评估性能的影响,作者选择了四个模型进行评估,这些模型都提供了预训练细节或进行了详尽的数据污染分析:
-
GPT-Neo-1.3B :是一种基于transformer的GPT-3架构模型;在Pile数据集上进行预训练
-
phi-1.5:在约27B tokens的“教科书质量”数据上训练的1.3B模型,虽然是小模型却可以达到与更大的模型相当的性能。
-
OpenLLaMA-3B:这是一个开源项目,基于LLaMA模型在超过1.2T tokens的RedPajama数据集上进行预训练。
-
LLaMA-2-7b :是LLaMA 2代,在大小约为2T tokens的公开在线数据上预训练。
结果与分析
下面两张表分别显示了三种基准泄露设置与原始LLMs在MMLU和QA任务以及推理和阅读理解任务上的比较:

▲表1 三种基准泄露设置与原始LLMs在MMLU和QA任务上的比较。

▲表2 不同基准泄露设置与原始LLMs在推理和阅读理解任务上的比较
实验结果显示:
-
仅使用MMLU训练集可以大大提高MMLU基准上的评估结果。然而,这种改进会造成与MMLU无关的任务(如常识和数学知识的HellaSwag和GSM8k)性能下降,这表明过度强调特定任务可能会降低模型泛化能力。
-
随着数据泄露的严重程度,评估分数不断上升。当合并评估基准的所有训练集进行预训练时,几乎所有评估任务的性能都显著提高。
-
另外测试提示是评估基准中不可忽视的重要信息,当测试提示被泄露时,1.3B大小的LLM甚至可以超过LLaMA 65B。因此在LLMs训练过程中,建议避免这种带有测试提示的特殊学习方式。
-
极端设置下(灰色部分)1.3B LLM在大多数任务中优于65B LLM。显然,这种增长不可能说明1.3B模型强于65B,而是基准作弊在作怪。
除了带来虚假的性能提升以外,基准泄露还存在着一些潜在的风险~
基准泄露的潜在风险
1. 对其他任务产生副作用
在对泄露的基准数据进行训练后,可能会误导LLMs过度强调基准数据的特定知识和输出样式,而对其他任务产生副作用。
从下表结果中可以看到,在泄露数据上进行训练后,LLMs在两个文本生成数据集LAMBADA和XSum上的性能都有所下降。这表明基准泄露可能会对其他正常测试任务的性能产生负面影响。
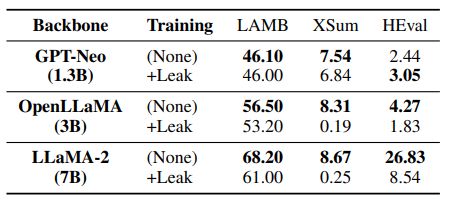
▲表3 “+Leak”代表模型使用评估基准的所有训练集进行过预训练,其训练数据已经被泄露。
2. 限制模型微调的能力
我们时常需要对LLMs进一步微调以达到某些特定目标,然而,在对泄露数据进行训练后,LLMs将被训练成拟合基准数据的模型,这可能影响模型微调后完成任务的能力。
为了研究数据泄露对LLMs微调能力的影响,作者采用了两个具有代表性的指令数据集Alpaca(主要包含自然语言指令)和CodeAlpaca(侧重于代码生成指令)分别对泄露以及未泄露的LLMs进行微调。结果显示,基准泄露的模型的性能不如未泄露的模型。
这表明基准泄露极有可能限制了LLMs通过后续微调过程进行适应或改进的能力。
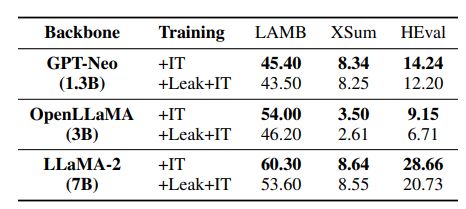
▲表4 指令调优后LLMs之间的比较,“IT”表示使用Alpaca和CodeAlpaca进行文本生成和代码合成任务的指令调优
LLMs评估基准改进建议
基于以上讨论,为尽可能避免基准泄露风险,作者提出了以下建议,以改进LLMs现有的能力评估基准。
-
应该使用来自不同来源的更多基准,涵盖基本能力(例如,文本生成)和高级能力测试(例如,复杂推理),以全面评估LLMs的能力。
对LLMs开发人员来说:
-
严格检查预训练数据,避免在训练过程中包含任何后续的评估数据。比如可以使用n-gram(一般为n = 13)哈希算法来检查某些特定任务的预训练数据和评估数据之间的重叠度。
-
建议将主流评测基准的训练数据从预训练数据中剔除。
-
当在某些评估基准上展示结果时,建议指出任何潜在的数据污染风险,并报告重叠度等污染分析参数,具体报告可以参照LLaMA-2。
-
展示更详细的预训练数据组成结构,特别是与主流评估基准相关的数据集,以方便公众检查潜在泄露风险。
对基准维护者的建议:
-
提供构建基准的数据源细节,使用主流预训练语料库对当前数据集进行污染分析。基准应该明确指出常用的预训练数据集可能存在的污染风险。
-
建议提交者附上特定污染分析报告,以便检查预训练数据和评估数据(包括训练和测试数据)之间的语义相关性。
-
为测试提供多样化的提示。最终的评估结果应该是多个提示多次运行的平均值。它有助于降低特定提示的敏感性,提高模型结果的可靠性。
结论
本文探讨了基准泄露对LLMs评估的潜在风险和影响。数据泄露会极大地提升LLMs(即使是小模型)的基准测试结果,使评估变得不公平和不可信。这个问题很难从预训练阶段完全消除,因此作者提出了一些有用的指导方针来改进现有评估基准的使用方案。
更重要的是,LLM开发人员和基准测试维护人员在解释和使用排行榜的结果时应该充分意识到数据污染问题,共同努力,一起打造一个公平公正的模型性能评估环境。

