【ATT&CK】MITRE Caldera -前瞻规划器
CALDERA是一个由python语言编写的红蓝对抗工具(攻击模拟工具)。它是MITRE公司发起的一个研究项目,该工具的攻击流程是建立在ATT&CK攻击行为模型和知识库之上的,能够较真实地APT攻击行为模式。
通过CALDERA工具,安全红队可以提前手动模拟并设定好攻击流程,并以此进行自动化攻击和事件响应演练。同样,安全蓝队也可以利用该工具,根据相应的威胁开展模拟应对。
github地址: mitre/caldera: Automated Adversary Emulation Platform (github.com)
Caldera规划器如何工作
在一次行动中,对抗的配置决定了可用的能力,规划者决定使用哪些能力及其顺序。Caldera 的默认规划器“原子规划器”根据对手配置文件的原子顺序一次向每个代理发送一个可用能力。如果代理有该能力的执行者并且其事实得到满足,则该能力是可用的。
Caldera 还预装了两个额外的规划器:Batch 和 Buckets。批量规划器将所有可用的能力发送给每个代理。存储桶规划器是批量规划器的变体,它在状态机中的不同状态(或“存储桶”)之间进行转换,并将所有可用能力从当前存储桶发送到每个代理。
这些规划器适用于大多数用例,但在使用具有数百种能力的大型对手配置文件时效果较差。例如,新的“Everything Bagel”对手将使用 Caldera 中加载的所有能力,默认情况下有超过 1,200 个能力。
使用 Atomic planner 运行 Everything Bagel 对手后,我们在下面的屏幕截图中看到了一些限制。规划者使用了很多不相关的能力并且需要很长时间才能完成。使用批量或桶规划器我们会得到类似的结果。能力太多,无法有效地全部使用。
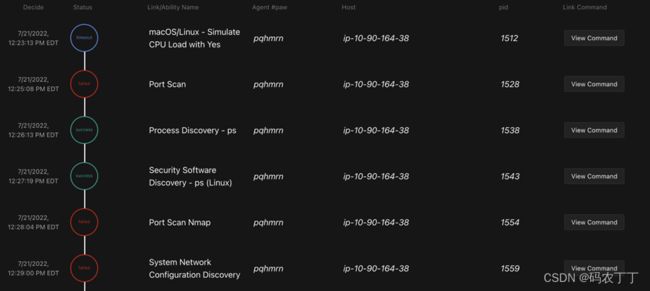
图 1 — 使用 Atomic planner 运行 Everything Bagel 对手
前瞻规划器
受这些限制的激励,前瞻性规划者根据预期的未来奖励决定使用哪些能力。它以能力奖励表、深度参数和折扣因子作为输入。深度参数有效地控制了规划器在对每个动作进行评分时的“前瞻”范围,而折扣因子则控制了规划器如何权衡未来的奖励。
在描述算法之前,先约定一些符号:
令g为折扣因子。这是全局定义的。默认为 0.9。
令d为前瞻深度。这是全局定义的。默认为 3。
令能力集为A。
定义函数E : A x P(A)为将A中的每个能力a映射到a后面的能力集的函数。
如果a的解析器生成了b的输入事实,我们就说能力b跟随能力a。从上面的语言来看,我们可能有一个例子:E(a) = {b}。
令R : A x N为我们的奖励表,将每种能力映射到其直接奖励。下面的伪代码描述了该算法:

使用前瞻规划器运行 Everything Bagel 对手后,我们在下面的屏幕截图中看到了一些有趣的结果。规划者使用多个相关能力序列中的第一个能力(例如,查找 Git 存储库、创建暂存目录、收集 ARP 详细信息)。

图 2 — 使用 Look Ahead 规划器运行 Everything Bagel 对手
规划者对每个能力的默认奖励为 1,因此能力的价值主要由后续能力序列的长度决定。
自定义前瞻性规划器
我们可以通过在 YAML 配置文件中编辑规划器的能力奖励来自定义前瞻规划器,该文件位于plugins/stockpile/data/planners/254c7035-de7d-4d76-a888–2c09ba594eca.yml。
如果我们希望规划者优先考虑特定能力或能力序列,我们需要定制能力奖励。ability_rewards字段包含从能力 ID 映射到奖励值的子字段。下面显示的示例配置为“Exfil staged directory”添加了 10 的能力奖励。
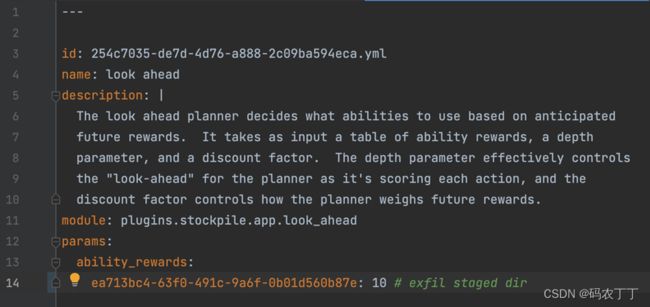
图 3 —在 planner 中自定义ability_rewards字段的示例配置
可以通过从“能力”选项卡中搜索并选择能力来找到能力 ID,如下所示。
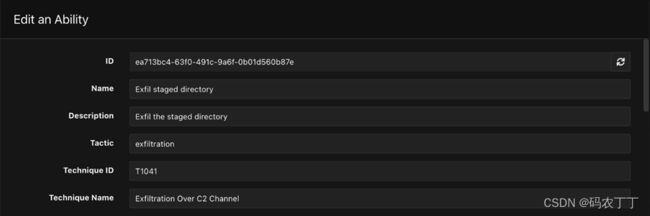
图 4 — 显示如何选择能力的屏幕截图
在使用定制的能力奖励运行 Everything Bagel 对手之后,我们看到了不同的结果。策划者立刻使用了可以获得高奖励的能力“Exfil暂存目录”。

图 5 — 运行 Everything Bagel 对手并提供定制能力奖励
有趣的是,所得到的能力序列比现有对手配置文件(例如窃贼对手)以更少的步骤达到“Exfil staged Directory”能力,并且由规划者自动生成,而无需明确指定此顺序。
总结
未来规划器根据预期的未来奖励决定使用哪些能力。我们可以定制能力奖励,以便规划者优先考虑导致不同能力的序列,例如窃取文件。通过优先考虑能力,前瞻规划器使我们能够更有效地利用大型对手的资料甚至Caldera的所有能力来运行行动。