acwing算法基础课-第四章 数学知识
数学知识
- 质数
-
- 试除法判定质数
-
- 模板
- AcWing 866 试除法判定质数(模板题)
- 试除法分解质因数
-
- 思想
- 模板
- AcWing 867 分解质因子(模板题)
- 筛质数
-
- 朴素筛法求素数(埃氏筛法)
-
- 思想
- 模板
- AcWing 868 筛质数 (朴素筛法求素数)(埃氏筛法)(模板题)
- 线性筛法求素数
-
- 思想
- 模板
- AcWing 868 筛质数 (线性筛法求素数)(模板题)
- 约数
-
- 试除法求约数
-
- 模板
- AcWing 869 试除法求约数(模板题)
- 求约数个数
-
- 思想
- AcWing 870 约数个数(模板题)
- 求约数之和
-
- 思想
- AcWing 871 约数之和(模板题)
- 最大公约数
-
- 思想
- 模板
- AcWing 872 最大公约数(模板题)
- 欧拉函数
-
- 思想
- 模板
- AcWing 873 欧拉函数(模板题)
- AcWing 874 筛法求欧拉函数.cpp(模板题)
- 快速幂
-
- 思想
- 模板
- AcWing 875 快速幂(模板题)
- AcWing 876 快速幂求逆元
- 扩展欧几里德算法
-
- 思想
- 模板
- AcWing 877 扩展欧几里德算法(模板题)
- AcWing 878 线性同余方程
- 中国剩余定理
-
- 思想
- AcWing 204 表达整数的奇怪方式
- 高斯消元
-
- 思想
- 模板
- AxWing 883 高斯消元解线性方程组(模板题)
- AcWing 884 高斯消元解异或线性方程组
- 求组合数
-
- 思想
- 组合数 I
-
- 模板
- AcWing 885 求组合数 I(模板题)
- 组合数 II
-
- 模板
- AcWing 886 求组合数 II(模板题)
- 组合数 III
-
- 思想
- 模板
- AcWing 887 球组合数 III(模板题)
- 组合数 IV
-
- 思想
- 模板
- AcWing 888 球组合数 IV(模板题)
- 卡特兰问题
-
- 思想
- AcWing 889 满足条件的01序列(模板题)
- 容斥原理
-
- 思想
- AcWing 890 能被整除的数
- 博弈论
-
- 思想
- AcWing 891 Nim 游戏(Nim游戏 - 模板题)
- AcWing 892 台阶-Nim游戏
- AcWing 893 集合-Nim游戏(有向图游戏的和 - 模板题)
- AcWing 894 拆分-Nim游戏
质数
试除法判定质数
模板
试除法判定质数 —— 模板题 AcWing 866. 试除法判定质数
bool is_prime(int x)
{
if (x < 2) return false;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
return false;
return true;
}
AcWing 866 试除法判定质数(模板题)
对于 i <= x / i; 因为 x 的因子是成对出现的,当遍历到 i时,说明 2 ~ (i - 1) 无 x的因子。
遍历到 i时,如果 i 为大于sqrt(n)的因子,那么 x / i一定被遍历了,所以只需遍历到 sqrt(n)
#include试除法分解质因数
思想
思路操作:对于待分解的正整数n:
1.从2开始,依次尝试将n除以小于等于sqrt(n)的每个素数。
2.如果某个素数p能够整除n,那么p就是n的一个质因子,记录下p后,继续对n/p执行分解操作。
3.如果没有小于等于sqrt(n)的素数能够整除n,那么n本身就是质数,分解结束。
注意,为了提高效率,我们在试除时只需要考虑小于等于sqrt(n)的素数是否能够整除n,因为如果n有大于sqrt(n)的质因数,它们的积一定大于n,不可能整除n。
模板
试除法分解质因数 —— 模板题 AcWing 867. 分解质因数
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}
AcWing 867 分解质因子(模板题)
//对于 i <= x / i; 因为 x 的质因子是成对出现的,
//当遍历到 i时,说明 2 ~ (i - 1) 无 x的质因子
//遍历到 i时,如果 i 为大于sqrt(n)的质因数,那么 x / i一定被遍历了,所以只需遍历到 sqrt(n)
#include筛质数
朴素筛法求素数(埃氏筛法)
思想
操作步骤:
1.从2开始,将2标记为素数。
2.将所有2的倍数标记为合数。
3.找到下一个未被标记的数,将其标记为素数。
4.将该素数的所有倍数标记为合数。
5.重复步骤3和4,直到找不到新的素数。
实际上,为了提高效率,我们只需遍历到 sqrt(n) 就可以找到2~n之间所有的素数。
时间复杂度为O(nloglogn)。
模板
朴素筛法求素数 —— 模板题 AcWing 868. 筛质数
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (st[i]) continue;
primes[cnt ++ ] = i;
for (int j = i; j <= n; j += i)
st[j] = true;
}
}
AcWing 868 筛质数 (朴素筛法求素数)(埃氏筛法)(模板题)
#include线性筛法求素数
思想
线性筛法是一种高效的求素数的方法,可以在可以在O(n)的时间内找到从1到n之间的所有素数。
操作步骤:
1.定义一个布尔数组isprime,将数组中的所有元素初始化为true.
2.定义一个数组primers,用于存储找到的素数。初始化primers为空.
3.从2开始遍历到n, 对于每个数 i, 执行以下操作:
(1).如果isprime为true,将 i 加入primes数组
(2).遍历primes数组每个素数p,如果p * i > n,,跳出循环。否则,将 p * i标记为合数,即isprimer[p * i] = false如果 p 能整除 i,跳出循环
4.遍历完 2 ~ n的元素后,isprimer数组中下标为true的下标就是素数。
线性筛法不仅能够快速地找到素数,还可以记录每个合数的最小质因子。具体地说,在执行第3步时,如果如果 p 能整除 i,则停止处理,因为 p 已经是 i 的的最小质因子了。
对于3.(2)(同模板内容) 的解析
核心:n 只会被最小质因子筛掉。
- st[primes[j] * i] = true.
对于一个合数 x, 设pj为 x 的最小质因子,当 i 枚举到 x/pj 时,便会被筛除,例, x = 8, i = 8/2 = 4 时,st[pj * i] = true.
,每次用最小质因子去筛,而合数的最小质因子都是唯一的,所以每个数只会被筛一次,所以它是线性的。 - if (i % primes[j] == 0) break;i % primes[j] 有两种可能性
a. i % pj == 0, pj是 i 的最小质因子, pj 一定是pi * i 的最小质因子
b. i % pj != 0, pj 小于 i的所有质因子, pj 一定是pi * i 的最小质因子 - for (int j = 0; primes[j] <= n / i; j ++ )
在判断语句中 加入 && j < cnt 没必要
a. i 为合数时, 因为 i 的最小质因子小于 i, 且 i的最小质因子在primers[cnt]中,当 枚举到 i的最小质因子便会停下来。
b. i 为质数,在这步中if (!st[i]) primes[cnt ++ ] = i;i会被收进primers[cnt]中,
当primer[j] = i 时, 便会停下来。也符合条件。
模拟一下 2 ~ 15,便会清楚很多
| i | 被筛 | p[cnt++] | cnt |
|---|---|---|---|
| 2 | 2 * 2 | p[0] = 2 | 1 |
| 3 | 2 * 3 ,3 * 3 | p[1] = 3 | 2 |
| 4 | 2 * 4 | ||
| 5 | 2 * 5,3 * 5 | p[2] = 5 | 3 |
| 6 | 2 * 6 | ||
| 7 | 2 * 7 | p[3] = 7 | 4 |
| …… | …… | …… | …… |
模板
线性筛法求素数 —— 模板题 AcWing 868. 筛质数
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
AcWing 868 筛质数 (线性筛法求素数)(模板题)
线性筛法求素数 常用该法
当 n 为 10 ^ 6时,与 朴素法差不多;n 为 10 ^ 7时, 比朴素法快一倍
#include约数
试除法求约数
模板
试除法求所有约数 —— 模板题 AcWing 869. 试除法求约数
vector<int> get_divisors(int x)
{
vector<int> res;
for (int i = 1; i <= x / i; i ++ )
if (x % i == 0)
{
res.push_back(i);
if (i != x / i) res.push_back(x / i);
}
sort(res.begin(), res.end());
return res;
}
AcWing 869 试除法求约数(模板题)
#include求约数个数
思想
一般地,对自然数n进行分解质因数,设n可以分解为
n=p⑴α⑴·p⑵α⑵·…·p(k)^α(k)
其中p⑴、p⑵、…p(k)是不同的质数,α⑴、α⑵、…α(k)是正整数,则形如
n=p⑴β⑴·p⑵β⑵·…·p(k)^β(k)的数都是n的约数,其中β⑴可取a⑴+1个值:0,1,2,…,α⑴;β⑵可取α⑵+1个值:0,1,2,…,α⑵…;β(k)可取a(k)+1个值:0,1,2,…,α(k).且n的约数也都是上述形式,根据乘法原理,n的约数共有
(α⑴+1)(α⑵+1)…(α(k)+1) ⑺个。
公式:
如果 N = p1^c1 * p2^c2 * ... *pk^ck; 约数个数: (c1 + 1) * (c2 + 1) * ... * (ck + 1)
例:n = 8, 8 = 2a1 * 3a2,a1=3,a2=1
则约数 x = 2b13b2;
b1可取(0,1,2,3)
b2可取(0,1)
共有(a1 + 1)*(a2 + 1)种匹配结果,即 x的结果共有 8种
AcWing 870 约数个数(模板题)
#include求约数之和
思想
公式
如果 N = p1^c1 * p2^c2 * ... *pk^ck; 约数之和: (p1^0 + p1^1 + ... + p1^c1) * ... * (pk^0 + pk^1 + ... + pk^ck)
例:24 = 23 * 31, 约数m = 2b1 * 3b2,b1={0,1,2,3},b2={0,1};
s = 20*31 + 21*31 + 22*31 + 23*31 + 20*30 + 21*30 + 22*30 + 23*30
s = (20 + 21 + 22 + 23) * (30 + 31),也就是上面的合并
AcWing 871 约数之和(模板题)
#include最大公约数
思想
这里用欧几里得算法求
欧几里得算法又称辗转相除法,是指用于计算两个非负整数a,b的最大公约数。应用领域有数学和计算机两个方面。计算公式gcd(a,b) = gcd(b,a mod b)。
证明
让D 表示 a 与 b 的公约数集合,Q 表示 b 与 a % b 的公约数集合
因为a / b = k(余r)所以 a可以表示成a = kb + r(a,b,k,r皆为正整数,且r假设d是a,b的任意一个公约数,则 a%d == 0, b%d == 0
而r = a - kb,两边同时除以d,r/d=a/d-kb/d=m,由等式右边可知m为整数,因此r%d==0
而r=a mod b,因此d也是b,a mod b的公约数(暂时认为D⊆R)
假设q是b,a mod b的公约数, 则b%q == 0,(a-kb)%q == 0
(a − k ∗ b a-kba−k∗b)%q = a%d-k∗ *∗b%q == 0 , k是一个整数。
进而a%q == 0.因此q也是a,b的公约数(暂时认为R⊆D)
由上可知,D=R,因此(a,b)和(b,a mod b)的公约数是一样的,其最大公约数也必然相等,得证。
转载修改于辜月博客
模板
欧几里得算法 —— 模板题 AcWing 872. 最大公约数
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
AcWing 872 最大公约数(模板题)
#include欧拉函数
思想
在数论,对正整数n,欧拉函数是小于n的正整数中与n互质的数的数目.

证明:可参考这位博主的证明,通俗易懂
糖豆爸爸
模板
求欧拉函数 —— 模板题 AcWing 873. 欧拉函数
int phi(int x)
{
int res = x;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
res = res / i * (i - 1);
while (x % i == 0) x /= i;
}
if (x > 1) res = res / x * (x - 1);
return res;
}
筛法求欧拉函数 —— 模板题 AcWing 874. 筛法求欧拉函数
int primes[N], cnt; // primes[]存储所有素数
int euler[N]; // 存储每个数的欧拉函数
bool st[N]; // st[x]存储x是否被筛掉
void get_eulers(int n)
{
euler[1] = 1;
for (int i = 2; i <= n; i ++ )
{
if (!st[i])
{
primes[cnt ++ ] = i;
euler[i] = i - 1;
}
for (int j = 0; primes[j] <= n / i; j ++ )
{
int t = primes[j] * i;
st[t] = true;
if (i % primes[j] == 0)
{
euler[t] = euler[i] * primes[j];
break;
}
euler[t] = euler[i] * (primes[j] - 1);
}
}
}
AcWing 873 欧拉函数(模板题)
#includeAcWing 874 筛法求欧拉函数.cpp(模板题)
#include快速幂
思想
快速幂算法的核心思想就是每一步都把指数分成两半,而相应的底数做平方运算。这样不仅能把非常大的指数给不断变小,所需要执行的循环次数也变小,而最后表示的结果却一直不会变。
以下以求a的b次方来介绍
把b转换成二进制数。
该二进制数第i位的权为 2i-1
例如 a11 = a2的0次方+2的1次方+2的3次方
11的二进制是1011 ,
11 = 23 * 1 + 22 * 0 + 21 * 1+20 * 1
因此,我们将a¹¹转化为计算 a2的0次方 * a2的1次方 * a2的3次方
这种思想是将指数 十进制与二进制转换
快速幂可以用位运算来实现,因为只需计算指数二进制的位数,所以其时间复杂度为其时间复杂度为 O(log₂N)
模板
快速幂 —— 模板题 AcWing 875. 快速幂
求 m^k mod p,时间复杂度 O(logk)。
int qmi(int m, int k, int p)
{
int res = 1 % p, t = m;
while (k)
{
if (k&1) res = res * t % p;
t = t * t % p;
k >>= 1;
}
return res;
}
AcWing 875 快速幂(模板题)
#includeAcWing 876 快速幂求逆元

注意b 与 m互质,图片来自acwing
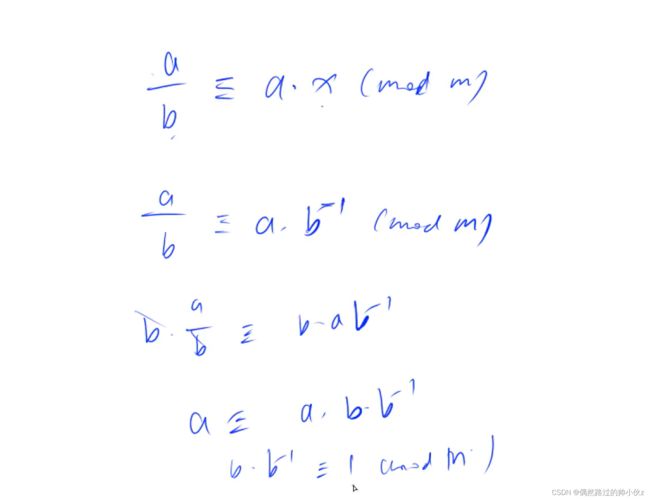
费马小定理(Fermat’s little theorem)是数论中的一个重要定理,在1636年提出。如果p是一个质数,而整数a不是p的倍数,则有a(p-1)≡1(mod p)。
a(p-1)≡1(mod p),a与p互质,且q为质数
a * a(p-2) ≡1(mod p);
则 a(p-2) 为 a 的逆元
#include扩展欧几里德算法
思想
相关证明可以参考该博主,非常详细(包含扩展欧几里得算法的推导过程,裴蜀定理, 扩展欧几里得算法,线性同余方程)
蒟蒻豆进阶之路
模板
扩展欧几里得算法 —— 模板题 AcWing 877. 扩展欧几里得算法,
求x, y,使得ax + by = gcd(a, b)
int exgcd(int a, int b, int &x, int &y)
{
if (!b)
{
x = 1; y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= (a/b) * x;
return d;
}
AcWing 877 扩展欧几里德算法(模板题)
#includeAcWing 878 线性同余方程
#include中国剩余定理
思想
百度百科的证明不错,
中国剩余定理(孙子定理)
关于百度百科的证明过程中该语句的解释:另外,假设x1 和 x2都是方程组(S) 的解,那么对于i(1,2,……n), x1 - x2 ≡ 0 (mod mi)。
x ≡ a1 (mod m1)
x ≡ a2 (mod m2)
…
x ≡ an (mod mn)
那么可以得到:
x1 ≡ a1 (mod m1)
x1 ≡ a2 (mod m2)
…
x1 ≡ an (mod mn)
x2 ≡ a1 (mod m1)
x2 ≡ a2 (mod m2)
…
x2 ≡ an (mod mn),
由x1 - x2 ≡ 0 (mod mi)可知,(x1 - x2)% mi = 0 -->(x1%mi - x2%mi)% mi =0,因为 x1%mi = x2%mi,即得证。
对于本题,ai与mi不两两互质,也就不符合孙子定理,也就是说,我们需要重新推。
还是来看看这位大神的推导吧,
蒟蒻豆进阶之路
AcWing 204 表达整数的奇怪方式
#include高斯消元
思想
定义简介:数学上,高斯消元法(或译:高斯消去法),是线性代数规划中的一个算法,可用来为线性方程组求解。但其算法十分复杂,不常用于加减消元法,求出矩阵的秩,以及求出可逆方阵的逆矩阵。不过,如果有过百万条等式时,这个算法会十分省时。一些极大的方程组通常会用迭代法以及花式消元来解决。当用于一个矩阵时,高斯消元法会产生出一个“行梯阵式”。高斯消元法可以用在电脑中来解决数千条等式及未知数。亦有一些方法特地用来解决一些有特别排列的系数的方程组。
内容:消元法是将方程组中的一方程的未知数用含有另一未知数的代数式表示,并将其代入到另一方程中,这就消去了一未知数,得到一解;或将方程组中的一方程倍乘某个常数加到另外一方程中去,也可达到消去一未知数的目的。消元法主要用于二元一次方程组的求解。
核心:
初等行列变换
- 两方程互换,解不变;
- 一方程乘以非零数k,解不变;
- 一方程乘以数k加上另一方程,解不变。
增广矩阵 -> 阶梯矩阵
转换过程即 高斯消元法
对于 高斯消元解线性方程组,可以参考该博主的文章
糖豆爸爸
高斯消元步骤:
依次枚举增广矩阵的列
(1)找到该列绝对值最大的行
(2)将该行换到(未确定阶梯型的行的)最上面
(3)将该行第一个数(当前枚举的列)变成1(该行其它数作相应变换)
(4)将该行下面所有行的当前列消成0,(该行其它数作相应变换)
(枚举完即是阶梯矩阵)
(5)如果该矩阵是唯一的解,则,从最后一行开始依次往上倒,每次将该行上面的数全变成 0,那么当前行只有一个 1,该 1对应的未知数即为第 i 行关于第 i 个未知数的解
方程组有三种情况,即有唯一解,无穷多的解,无解
唯一解:完美阶梯形

无解:0 = 非0,即 存在某一行系数都为 0,该方程等号右侧的常数不为0。(原方程中出现了矛盾)
无穷多的解:0 = 0,即 存在某一行系数都为 0,该方程等号右侧的常数也为0。(原方程中出现了一样的方程)
模板
高斯消元 —— 模板题 AcWing 883. 高斯消元解线性方程组
a[N][N]是增广矩阵
int gauss()
{
int c, r;
for (c = 0, r = 0; c < n; c ++ )
{
int t = r;
for (int i = r; i < n; i ++ ) // 找到绝对值最大的行
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;
for (int i = c; i <= n; i ++ ) swap(a[t][i], a[r][i]); // 将绝对值最大的行换到最顶端
for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c]; // 将当前上的首位变成1
for (int i = r + 1; i < n; i ++ ) // 用当前行将下面所有的列消成0
if (fabs(a[i][c]) > eps)
for (int j = n; j >= c; j -- )
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if (r < n)
{
for (int i = r; i < n; i ++ )
if (fabs(a[i][n]) > eps)
return 2; // 无解
return 1; // 有无穷多组解
}
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] * a[j][n];
return 0; // 有唯一解
}
AxWing 883 高斯消元解线性方程组(模板题)
对于该代码的相关解答
if(r < n)
{
for(int i = r; i < n; i++)
if(fabs(a[i][c]) > eps) return 2;//无解
return 1;// 无穷多的解
}
1.为什么从第 r 行开始?
首先 r < n, 这意味着已经是无解或无穷多的解的情况,
而 r < n, 是因为在依次枚举增广矩阵的列时,出现了该列绝对值最大值都为 0的情况,这时continue, 即行不变,列加 1,说明有一个方程组出错了 。最后经过一系列操作转化成阶梯矩阵后,从第 r 行开始,方程左边系数都为 0,从这开始判断方程是 无解 还是 无穷多的解
2.判断无解情况,为什么要循环判断?
因为只要出现了 0 = 非0,即无解的情况
而无穷多的解需都满足 0 = 0
对于对于该代码的解答
//从最后一行开始往上消元计算 (不懂该语句的模拟一遍基本就ok了)
for(int i = n - 1; i >= 0; i--)
for(int j = i + 1; j < n; j++)
a[i][n] -= a[i][j] * a[j][n];
对于求最终未知数的值,只需a[i][n] -= a[i][j] * a[j][n]。
我们的目的是求a[i][n],而除了 a[i][i]和 a[i][n]的元素外,我们不用第 i 行每个元素都减去 k(a[i][j]) * 对应 j 行元素。因为我们使用一次它(即 作为 k的元素)后,把它当作 0,便不再使用它了,不用管它(实际上应该为0,因为 第 i 行实际上是个方程,用了该 k 后,即消去了该未知数)
#includeAcWing 884 高斯消元解异或线性方程组
等式与等式间的异或要左右两端全都异或才能保证等式左右两边依然相等
a ^ b ^ c = x;d ^ f= y
则 a ^ b ^ c ^ d ^ f = x ^ y
#include求组合数
思想
Cba
组合数 I : 适合 a, b 在 1 ~ 2000内的大小,有取模
组合数 II : 适合 a, b 在 1 ~ 1e5 内的大小,有取模
组合数 III : a, b 在 1 ~ 1e18内,适合 a, b 很大,取模(p) 很小的情况
组合数 IV : 无取模
组合数 I
核心:Cba=Cba−1+Cb−1a−1
模板
递归法求组合数 —— 模板题 AcWing 885. 求组合数 I
// c[a][b] 表示从a个苹果中选b个的方案数
for (int i = 0; i < N; i ++ )
for (int j = 0; j <= i; j ++ )
if (!j) c[i][j] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
AcWing 885 求组合数 I(模板题)
#include组合数 II
Cba = (fact[a]∗infact[a−b]∗infact[b])
模板
通过预处理逆元的方式求组合数 —— 模板题 AcWing 886. 求组合数 II
首先预处理出所有阶乘取模的余数fact[N],以及所有阶乘取模的逆元infact[N]
如果取模的数是质数,可以用费马小定理求逆元
int qmi(int a, int k, int p) // 快速幂模板
{
int res = 1;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
// 预处理阶乘的余数和阶乘逆元的余数
fact[0] = infact[0] = 1;
for (int i = 1; i < N; i ++ )
{
fact[i] = (LL)fact[i - 1] * i % mod;
infact[i] = (LL)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
}
AcWing 886 求组合数 II(模板题)
#include组合数 III
思想
lucas定理
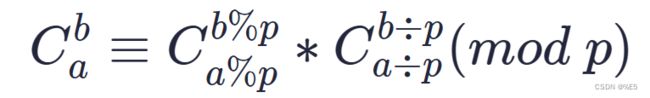
证明所需要的知识点
1.
 2.
2.

3.

证明:推荐百度百科和维基百科
百度百科
维基百科
以下是维基百科的证明


模板
Lucas定理 —— 模板题 AcWing 887. 求组合数 III
若p是质数,则对于任意整数 1 <= m <= n,有:
C(n, m) = C(n % p, m % p) * C(n / p, m / p) (mod p)
int qmi(int a, int k) // 快速幂模板
{
int res = 1;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
int C(int a, int b) // 通过定理求组合数C(a, b)
{
int res = 1;
for (int i = 1, j = a; i <= b; i ++, j -- )
{
res = (LL)res * j % p;
res = (LL)res * qmi(i, p - 2) % p;
}
return res;
}
int lucas(LL a, LL b)
{
if (a < p && b < p) return C(a, b);
return (LL)C(a % p, b % p) * lucas(a / p, b / p) % p;
}
AcWing 887 球组合数 III(模板题)
#include组合数 IV
思想
算术基本定理: Cba=pα11 × pα22 × pα33 …… × pαkk
求n!中质因子p的个数:res = [n/p] + [n/(p2)] + [n/(p3)] + ……
简单证明:
步骤:
(1). 筛素数,把 所需区间的的素数筛出来
(2). 计算Cba中每个已求得素数的个数
(3). 利用高精度乘法,计算Cba=pα11 × pα22 × pα33 …… × pαkk
模板
分解质因数法求组合数 —— 模板题 AcWing 888. 求组合数 IV
当我们需要求出组合数的真实值,而非对某个数的余数时,分解质因数的方式比较好用:
1. 筛法求出范围内的所有质数
2. 通过 C(a, b) = a! / b! / (a - b)! 这个公式求出每个质因子的次数。 n! 中p的次数是 n / p + n / p^2 + n / p^3 + …
3. 用高精度乘法将所有质因子相乘
int primes[N], cnt; // 存储所有质数
int sum[N]; // 存储每个质数的次数
bool st[N]; // 存储每个数是否已被筛掉
void get_primes(int n) // 线性筛法求素数
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
int get(int n, int p) // 求n!中 p的次数
{
int res = 0;
while (n)
{
res += n / p;
n /= p;
}
return res;
}
vector<int> mul(vector<int> a, int b) // 高精度乘低精度模板
{
vector<int> c;
int t = 0;
for (int i = 0; i < a.size(); i ++ )
{
t += a[i] * b;
c.push_back(t % 10);
t /= 10;
}
while (t)
{
c.push_back(t % 10);
t /= 10;
}
return c;
}
get_primes(a); // 预处理范围内的所有质数
for (int i = 0; i < cnt; i ++ ) // 求每个质因数的次数
{
int p = primes[i];
sum[i] = get(a, p) - get(b, p) - get(a - b, p);
}
vector<int> res;
res.push_back(1);
for (int i = 0; i < cnt; i ++ ) // 用高精度乘法将所有质因子相乘
for (int j = 0; j < sum[i]; j ++ )
res = mul(res, primes[i]);
AcWing 888 球组合数 IV(模板题)
#include卡特兰问题
思想
这位博主写的非常好
蒟蒻豆进阶之路
取模

卡特兰数 —— 模板题 AcWing 889. 满足条件的01序列
给定n个0和n个1,它们按照某种顺序排成长度为2n的序列,满足任意前缀中0的个数都不少于1的个数的序列的数量为: Cat(n) = C(2n, n) / (n + 1)
AcWing 889 满足条件的01序列(模板题)
#include容斥原理
思想
简介:在计数时,必须注意没有重复,没有遗漏。为了使重叠部分不被重复计算,人们研究出一种新的计数方法,这种方法的基本思想是:先不考虑重叠的情况,把包含于某内容中的所有对象的数目先计算出来,然后再把计数时重复计算的数目排斥出去,使得计算的结果既无遗漏又无重复,这种计数的方法称为容斥原理。
定义:如果被计数的事物有A、B、C三类,那么,A类和B类和C类元素个数总和= A类元素个数+ B类元素个数+C类元素个数—既是A类又是B类的元素个数—既是A类又是C类的元素个数—既是B类又是C类的元素个数+既是A类又是B类而且是C类的元素个数。(A∪B∪C = A+B+C - A∩B - B∩C - C∩A + A∩B∩C) [2] 。
例如:一次期末考试,某班有15人数学得满分,有12人语文得满分,并且有4人语、数都是满分,那么这个班至少有一门得满分的同学有多少人?
分析:依题意,被计数的事物有语、数得满分两类,“数学得满分”称为“A类元素”,“语文得满分”称为“B类元素”,“语、数都是满分”称为“既是A类又是B类的元素”,“至少有一门得满分的同学”称为“A类和B类元素个数”的总和。为15+12-4=23。
公式:
来自百度百科
公式证明:j_d_m_y
AcWing 890 能被整除的数
这位博主写的非常好,大家可以看看
Cloudeeeee
这里提一下重点
① 求出每个集合中元素的个数( |Si| = n/pi)
② 求出集合和集合之间交集的个数( |S1∩S2∩……Si| = n/(pip2……pi))
③ 用二进制表示选择了哪个集合与否
对于③ ,我们知道p[i]的所有组合方式有 2m - 1 种

结合Cloudeeeee博主写的

我们可以从 1 ~ (m - 1)来遍历每种情况
代码实现思路:
1、每一个i代表一种可能的取法,最外层的循环遍历置2的m次方后,可以取完所有的取法
2、里面的循环就是提取出这个i值对应的取法
3、再将提取出的取法代入公式
转载自Cloudeeeee
#include博弈论
思想
NIM游戏 —— 模板题 AcWing 891. Nim游戏
给定N堆物品,第i堆物品有Ai个。两名玩家轮流行动,每次可以任选一堆,取走任意多个物品,可把一堆取光,但不能不取。取走最后一件物品者获胜。两人都采取最优策略,问先手是否必胜。
我们把这种游戏称为NIM博弈。把游戏过程中面临的状态称为局面。整局游戏第一个行动的称为先手,第二个行动的称为后手。若在某一局面下无论采取何种行动,都会输掉游戏,则称该局面必败。
所谓采取最优策略是指,若在某一局面下存在某种行动,使得行动后对面面临必败局面,则优先采取该行动。同时,这样的局面被称为必胜。我们讨论的博弈问题一般都只考虑理想情况,即两人均无失误,都采取最优策略行动时游戏的结果。
NIM博弈不存在平局,只有先手必胜和先手必败两种情况。
定理: NIM博弈先手必胜,当且仅当 A1 ^ A2 ^ … ^ An != 0
公平组合游戏ICG
若一个游戏满足:
由两名玩家交替行动;
在游戏进程的任意时刻,可以执行的合法行动与轮到哪名玩家无关;
不能行动的玩家判负;
则称该游戏为一个公平组合游戏。
NIM博弈属于公平组合游戏,但城建的棋类游戏,比如围棋,就不是公平组合游戏。因为围棋交战双方分别只能落黑子和白子,胜负判定也比较复杂,不满足条件2和条件3。
有向图游戏
给定一个有向无环图,图中有一个唯一的起点,在起点上放有一枚棋子。两名玩家交替地把这枚棋子沿有向边进行移动,每次可以移动一步,无法移动者判负。该游戏被称为有向图游戏。
任何一个公平组合游戏都可以转化为有向图游戏。具体方法是,把每个局面看成图中的一个节点,并且从每个局面向沿着合法行动能够到达的下一个局面连有向边。
Mex运算
设S表示一个非负整数集合。定义mex(S)为求出不属于集合S的最小非负整数的运算,即:
mex(S) = min{x}, x属于自然数,且x不属于S
SG函数
在有向图游戏中,对于每个节点x,设从x出发共有k条有向边,分别到达节点y1, y2, …, yk,定义SG(x)为x的后继节点y1, y2, …, yk 的SG函数值构成的集合再执行mex(S)运算的结果,即:
SG(x) = mex({SG(y1), SG(y2), …, SG(yk)})
特别地,整个有向图游戏G的SG函数值被定义为有向图游戏起点s的SG函数值,即SG(G) = SG(s)。
有向图游戏的和 —— 模板题 AcWing 893. 集合-Nim游戏
设G1, G2, …, Gm 是m个有向图游戏。定义有向图游戏G,它的行动规则是任选某个有向图游戏Gi,并在Gi上行动一步。G被称为有向图游戏G1, G2, …, Gm的和。
有向图游戏的和的SG函数值等于它包含的各个子游戏SG函数值的异或和,即:
SG(G) = SG(G1) ^ SG(G2) ^ … ^ SG(Gm)
定理
有向图游戏的某个局面必胜,当且仅当该局面对应节点的SG函数值大于0。
有向图游戏的某个局面必败,当且仅当该局面对应节点的SG函数值等于0。
作者:yxc
链接:https://www.acwing.com/blog/content/406/
来源:AcWing
必胜状态和必败状态
必胜状态:先手进行某一个操作,留给后手是一个必败状态时,对于先手来说是一个必胜状态。即先手可以走到某一个必败状态。
必败状态:先手无论如何操作,留给后手都是一个必胜状态时,对于先手来说是一个必败状态。即先手走不到任何一个必败状态。
结论
假设n堆石子,石子数目分别是a1,a2,…,an,如果a1⊕a2⊕…⊕an≠0,先手必胜;否则先手必
败。
————————————————
Cloudeeeee
问: 为什么公平组合游戏存在必胜与必败状态?
公平组合游戏指的是两个玩家交替进行操作的一种游戏,每个操作都从一组可行操作中选择一个,并改变游戏的状态。游戏在达到某个终止状态时结束,最终得分或胜负由终止状态决定。
对于公平组合游戏而言,存在必胜和必败状态的原因是基于一种数学原理,即游戏的状态可以通过其后继状态来进行分析。
假设我们将每个游戏状态视为节点,两个玩家的操作视为从一个状态到另一个状态的边。我们可以构建一个有向图,其中节点表示游戏状态,边表示操作。在这个有向图中,从初始状态开始,我们可以通过操作沿着边移动到其他状态。
现在考虑两种可能情况:
-
如果在当前状态下,存在一条边可以移动到一个必败状态,那么当前状态就是必胜状态。因为当前玩家可以选择这样的一条边,将游戏状态转移到必败状态,迫使对手处于必败状态。
-
如果在当前状态下,所有可能的边都导致必胜状态,或者不存在任何边可以移动到其他状态,那么当前状态就是必败状态。因为不管当前玩家选择哪条边,对手都可以在下一步移动后处于必胜状态,从而保证对手取胜。
基于上述原理,通过从终止状态向初始状态反向分析,我们可以确定哪些状态是必胜状态,哪些状态是必败状态。这种分析方法被称为"逆向归纳法"或"反向博弈论"。通过这种方法,我们可以确定公平组合游戏中的必胜和必败状态。
需要注意的是,这个结论仅适用于满足特定条件的公平组合游戏。在其他类型的游戏中,可能不存在必胜或必败状态,或者可能存在其他复杂的情况。
问:为什么公平组合游戏一般用异或就能判断必胜还是必败?
在某些特定的公平组合游戏中,可以使用异或(XOR)操作来判断一个状态是否是必胜状态。
这是因为在这些游戏中,每个状态都可以被表示为一组独立的子游戏的状态,并且这些子游戏是相互独立且可解决的。通过计算每个子游戏的状态,然后对这些状态进行异或操作,可以得到当前状态的异或和。根据这个异或和的结果,我们可以判断当前状态是必胜还是必败。
具体来说,假设我们将当前状态表示为一个整数,每个子游戏的状态也表示为相应的整数。我们可以计算当前状态的异或和,即将所有子游戏状态的整数进行异或操作。如果异或和为0,表示当前状态是必败状态;如果异或和不为0,表示当前状态是必胜状态。
这种判断方法的原理是基于以下观察:
- 如果当前状态是必败状态,那么对于每个子游戏状态,它们的异或和为0,因为无论玩家选择哪个子游戏,对手总是可以找到一个合法的操作来使得异或和保持为0。
- 如果当前状态是必胜状态,那么对于至少一个子游戏状态,它们的异或和不为0,因为当前玩家可以选择这个子游戏,并找到一个操作使得异或和不为0,从而保证取胜。
需要注意的是,这个判断方法仅适用于满足特定条件的公平组合游戏,并且需要将游戏状态和子游戏的状态映射到整数上。在其他类型的游戏中,可能不存在这种简单的判断方法,或者需要其他的分析技巧来确定必胜和必败状态。
yxc老师这么说:异或操作是判断必胜或必败的一种方式,至于为什么异或可以,大家可以参考 K-nim游戏 应该就明白了
AcWing 891 Nim 游戏(Nim游戏 - 模板题)
对于为什么
a1^ a2 ^ … ^an=0 先手必败
a1 ^ a2 ^ … ^an≠0 先手必胜
可以参考这位博主,将此问题讲的很好
糖豆爸爸
#includeAcWing 892 台阶-Nim游戏
奇数级台阶上的石子异或和不为0,则先手胜;
奇数级台阶上的石子异或和为0,则先手败。
像上一题,拿掉石子,相当于把某一个奇数级台阶上的任意石子放到下面的偶数级台阶去。
还有一种情况,如果对手把上面偶数级台阶上的石子放到下面的奇数级台阶去,ok,我们镜像它,把它放到下面的偶数级台阶去,如果为地板,岂不完美。
这样,我们只需关注奇数级台阶上的石子异或和就可以。
#includeAcWing 893 集合-Nim游戏(有向图游戏的和 - 模板题)
有向图游戏
给定一个有向无环图,图中有一个唯一的起点,在起点上放有一枚棋子。两名玩家交替地把这枚棋子沿有向边进行移动,每次可以移动一步,无法移动者判负。该游戏被称为有向图游戏。
任何一个公平组合游戏都可以转化为有向图游戏。具体方法是,把每个局面看成图中的一个节点,并且从每个局面向沿着合法行动能够到达的下一个局面连有向边。
Mex运算
设S表示一个非负整数集合。定义mex(S)为求出不属于集合S的最小非负整数的运算,即:
mex(S) = min{x}, x属于自然数,且x不属于S
SG函数
在有向图游戏中,对于每个节点x,设从x出发共有k条有向边,分别到达节点y1, y2, …, yk,定义SG(x)为x的后继节点y1, y2, …, yk 的SG函数值构成的集合再执行mex(S)运算的结果,即:
SG(x) = mex({SG(y1), SG(y2), …, SG(yk)})
特别地,整个有向图游戏G的SG函数值被定义为有向图游戏起点s的SG函数值,即SG(G) = SG(s)。
有向图游戏的和 —— 模板题 AcWing 893. 集合-Nim游戏
设G1, G2, …, Gm 是m个有向图游戏。定义有向图游戏G,它的行动规则是任选某个有向图游戏Gi,并在Gi上行动一步。G被称为有向图游戏G1, G2, …, Gm的和。
有向图游戏的和的SG函数值等于它包含的各个子游戏SG函数值的异或和,即:
SG(G) = SG(G1) ^ SG(G2) ^ … ^ SG(Gm)
定理
有向图游戏的某个局面必胜,当且仅当该局面对应节点的SG函数值大于0。
有向图游戏的某个局面必败,当且仅当该局面对应节点的SG函数值等于0。
对于SG函数,是用于构成下面这张图的步骤,大家可以模拟一下。
注意 unordered_set s;表示当前的哈希表,返回时返回值进入另外一个哈希表,用来保证 mex()函数的完成 ,即下图中红色数字。
//用来求出每堆石子的SG值
int SG(int x)
{
if(f[x] != -1) return f[x]; //记忆化搜索,用来保证每种状态只会被算一次
// 哈希表存储SG函数值
//注意这里是局部变量,返回时返回值进入另外一个哈希表,用来保证 mex()函数的完成
unordered_set<int> s;
//遍历结点 x的下一条有向边
for(int i = 0; i < m; i++)
{
int sum = p[i];
if(x >= sum) s.insert(SG(x - sum));
}
// Mex运算,返回不属于集合S的最小非负整数
for(int j = 0; ; j++)
if(!s.count(j)) return f[x] = j;
}
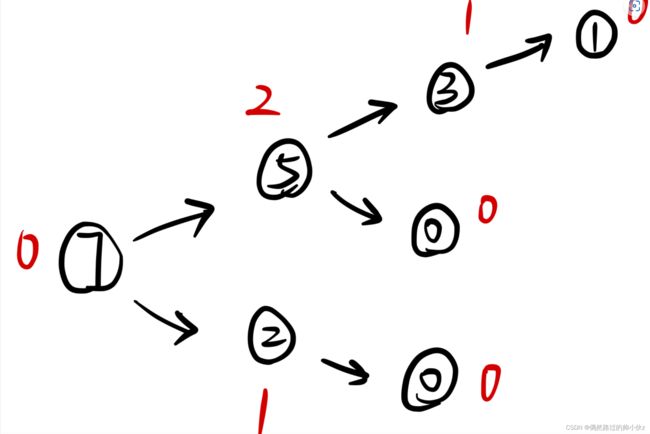
集合S中有k个数,表示每次只能取这k个数中的某一个数的石头。
如 k = 2,S = {2,5} ,表示S中有两个数,取石头时每次要么取2,要么取5。
n堆石子,如 n = 3,每堆分别有 2 4 7个石子。将每堆石子的取法看成一张有向图,此处取7,则取法的有向图如下:
所以 SG(G7) = 0 (初始状态的SG值),同理求出第一堆和第二堆的SG值,SG(G2) ,SG(G4)
然后把每堆石子的SG值异或起来,
则最终结果SG = SG(G2) ⊕ SG(G4) ⊕ SG(G7)
来源于Cloudeeeee
#includeAcWing 894 拆分-Nim游戏
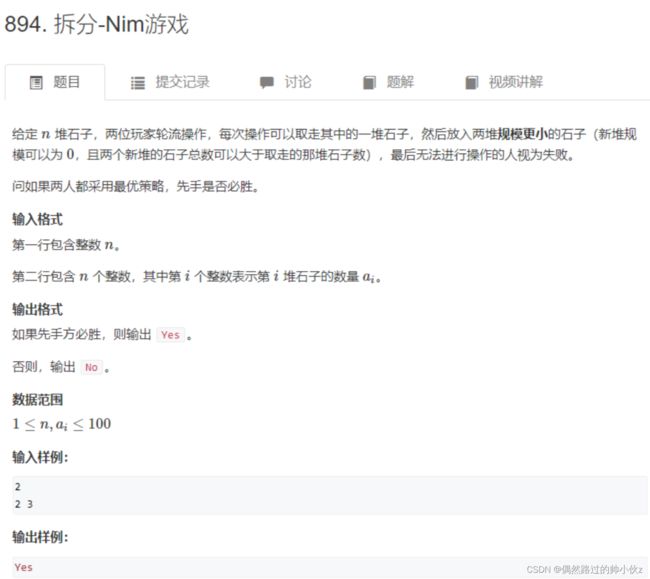
对于这题,对于这题,题目我一开始理解错了。
不是某堆的新的两堆可以加到另一原有的堆,而是有新的两堆代替这一堆,但新的两堆石子数都不大于这一堆的石子数
比如有三堆,(2 3 6 ),取为 6 的堆,可以拆为
0 0
0 1
0 2
0 3
0 4
0 5
…
1 0
1 2
1 3
1 4
1 5
…
5 0
5 1
5 2
5 3
5 4
5 5
但是其拆开的两堆不会加到原来的第一堆(2),第二堆(3)中
重要思路
有向图游戏的和的SG函数值等于它包含的各个子游戏SG函数值的异或和,即:
SG(G) = SG(G1) ^ SG(G2) ^ … ^ SG(Gm)
对于每个SG(Gi),考虑所有的局面,用mex运算计算出sg值

#include