爬虫实战:基于urllib和mysql爬取苏州公交线路信息
文章目录
- 写在前面
-
- 实验环境
- 实验描述
- 实验目标
- 实验内容
-
- 1. 确定并分析目标网页结构
- 2. 编写urllib代码爬取公交信息
- 3. 保存公交数据到csv文件中
- 4. 保存公交数据到mysql数据库中
- 写在后面
写在前面
本文将基于python的urllib模块,爬取北京公交线路的信息,最后将数据保存在csv文件和mysql数据库中。
实验环境
- anaconda丨pycharm
- python3.11.4
- mysql
- urllib
实验描述
- 学习网络爬虫相关技术,熟悉爬虫基本库urllib的使用。
- 熟悉网络爬虫相关基础知识。
- 使用urllib基本库获取苏州公交线路信息的HTML源代码。
- 使用BeautifulSoup解析库完成苏州公交线路相关信息的获取。
实验目标
- 知道urllib基本库和BeautifulSoup解析库的使用方法
- 学会使用urllib基本库和BeautifulSoup解析库进行苏州公交线路相关信息的爬取。
实验内容
1. 确定并分析目标网页结构
(1)进入 https://suzhou.8684.cn/ 网页,即进入苏州公交查询界面
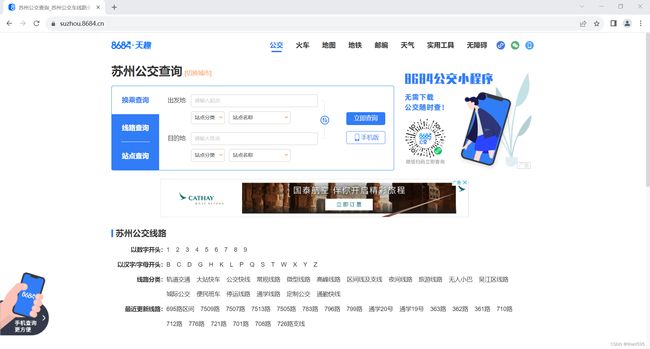
(2)单击“以数字开头”中的各数字,观察URL的变化,不难看出网页URL的变化规律为:https://suzhou.8684.cn/list + 数字。


(3)单击数字 “1” 进入 https://suzhou.8684.cn/list1 界面,按下键盘上的“F12”进入检查页面。
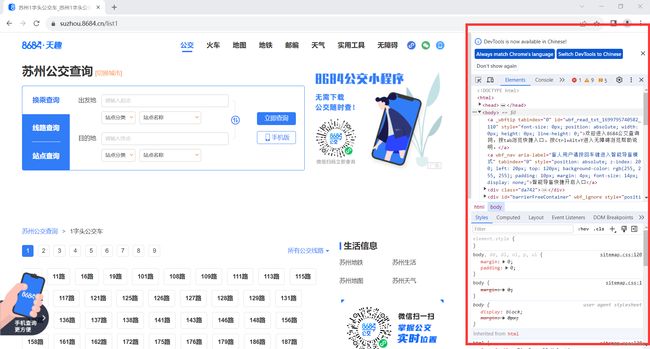
(4)使用快捷键“Ctrl+Shift+C”, 单击公交车链接,可以查看该标签的HTML代码。
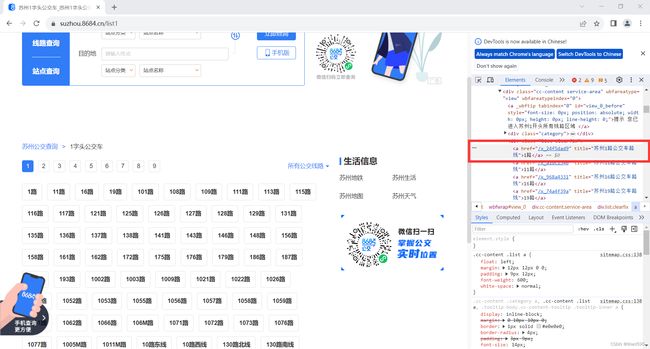
(5)单击a标签中的href属性,进入详细信息页面。

此时观察URL的变化,我们发现详细信息页面的URL变化规律为 https://suzhou.8684.cn/ + a标签中的href属性。
(6)综上,在构建URL时,我们需要获取对应a标签的href属性的内容。
2. 编写urllib代码爬取公交信息
(1)构造一个URL,获取所有一级页面的URL。
import urllib.request
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
import csv
import pymysql
url = 'http://suzhou.8684.cn'
url_list = url + '/list%d'
for i in range(1, 10):
urls = url_list % i
print(urls)
http://suzhou.8684.cn/list1
http://suzhou.8684.cn/list2
http://suzhou.8684.cn/list3
http://suzhou.8684.cn/list4
http://suzhou.8684.cn/list5
http://suzhou.8684.cn/list6
http://suzhou.8684.cn/list7
http://suzhou.8684.cn/list8
http://suzhou.8684.cn/list9
该脚本的功能是爬取苏州公交网站(http://suzhou.8684.cn/)中的公交线路信息。首先,通过导入urllib.request、BeautifulSoup和urllib.parse等库,实现对网页的解析和数据的提取。 然后,通过循环获取公交线路信息的分页,拼接成完整的url列表。最后,打印出所有的url列表。
(2)创建一个get_page_url的方法,获取拥有公交信息网页的URL。
def get_page_url(url):
html = urllib.request.urlopen(url)
soup = bs(html.read(), 'html.parser')
lu = soup.find('div', class_ = 'list clearfix')
hrefs = lu.find_all('a')
url_list = []
for i in hrefs:
url_list.append(urljoin(urls, i['href']))
return url_list
该函数的功能是获取公交线路信息页中所有公交线路的url。首先,通过urllib库中的urlopen()方法和BeautifulSoup库中的find()方法,解析出公交线路信息页中指定的HTML标签。然后,通过循环遍历所有公交线路的a标签,使用urljoin()方法将相对路径转换为完整的URL,并将转换后的URL添加到列表url_list中,最后返回url_list。
(3)创建一个get_page_info的方法,获取公交的详细信息。
def get_page_info(url):
html = urllib.request.urlopen(url)
soup = bs(html.read(), 'html.parser')
bus_name = soup.select('div[class="bus-lzinfo service-area mb20"]>div[class="info"]>h1[class="title"]>span')[0].string
bus_type = soup.select('div[class="bus-lzinfo service-area mb20"]>div[class="info"]>h1[class="title"]>a')[0].string[1:-1]
bus_time = soup.find_all('li', tabindex='0')[4].string
bus_ticket = soup.find_all('li', tabindex='0')[5].string
bus_gongsi = soup.select('ul[class="bus-desc"]>li>span')[0].string + soup.select('ul[class="bus-desc"]>li>a')[0].string
bus_gengxin = soup.select('ul[class="bus-desc"]>li>span')[1].string
try:
wang_info = soup.select('div[class="bus-excerpt mb15"]>div>div[class="trip"]')[0].string
wang_list = soup.select('div[class="bus-lzlist mb15"]:nth-of-type(2)>ol>li>a')
except:
wang_info = None
wang_list = None
try:
fan_info = soup.select('div[class="bus-excerpt mb15"]>div>div[class="trip"]')[1].string
fan_list = soup.select('div[class="bus-lzlist mb15"]:nth-of-type(4)>ol>li>a')
except:
fan_info = None
fan_list = None
if wang_list != None:
bus_wang = ''
for i in range(len(wang_list)):
if i != len(wang_list) - 1:
bus_wang += wang_list[i].string + ','
else:
bus_wang += wang_list[i].string
else:
bus_wang = None
if fan_list != None:
bus_fan = ''
for i in range(len(fan_list)):
if i != len(fan_list) - 1:
bus_fan += fan_list[i].string + ','
else:
bus_fan += fan_list[i].string
else:
bus_fan = None
result = [bus_name, bus_type, bus_time, bus_ticket, bus_gongsi, bus_gengxin, wang_info, bus_wang, fan_info, bus_fan]
return result
该函数的功能是获取公交线路信息页中指定的公交线路详细信息,并将其封装成一个列表返回。首先,通过urllib库中的urlopen()方法和BeautifulSoup库中的select()方法,解析出公交线路名称、类型、运行时间、票价、公交公司、更新时间等信息。其中,使用CSS选择器来定位HTML标签,可以更加方便地解析HTML文档。接着,通过find_all()方法和tabindex属性来获取HTML中指定的标签,进一步解析出公交线路的运行时间和票价信息。
然后,使用select()方法来查找公交线路是否有往返信息,如果有,则获取往返信息和对应的公交线路列表。而如果没有往返信息,则往返信息和对应的公交线路列表赋值为None。需要注意的是,在获取公交线路列表时,需要遍历所有的a标签,并将每个a标签的string属性连接成一个以逗号为分隔符的字符串,最后赋值给bus_wang或bus_fan。
最后,将所有获取到的公交线路信息按照指定的顺序封装成一个列表result,并返回该列表。
(4)编写主函数,爬取公交信息。
if __name__ == "__main__":
url = 'http://suzhou.8684.cn/list%d'
url_list = []
for i in range(1,10):
urls = url % i
url_list += get_page_url(urls)
for i in url_list:
result = get_page_info(i)
for j in result:
print(j)
print('\n')
程序执行前判断了当前模块是否是主模块,如果是主模块,则执行程序中的main()函数。在main()函数中,通过调用get_page_url()函数,获取了所有公交线路信息页的URL,并将其保存到url_list中。接着,使用循环遍历url_list中的每个URL,调用get_page_info()函数获取每个URL中的公交线路详细信息,并将每条公交线路的详细信息按照指定的顺序打印出来,以供可视化查看。
3. 保存公交数据到csv文件中
程序设计
修改主函数为:
if __name__ == "__main__":
url = 'http://suzhou.8684.cn/list%d'
url_list = []
cs = open("bus_info.csv",'w',newline='')
writer = csv.writer(cs)
for i in range(1,10):
urls = url % i
url_list += get_page_url(urls)
for i in url_list:
result = get_page_info(i)
writer.writerow(result)
with open('bus_info.csv', newline='') as csvfile:
reader = csv.reader(csvfile)
for i in reader:
for j in i:
print(j)
print('\n')
该程序在前一个的基础上增加了将获取到的公交线路信息写入到CSV文件中的功能。程序开始时同样会判断当前模块是否为主模块,若是则执行程序中的main()函数。在main()函数中,首先打开一个名为“bus_info.csv”的文件,用于存储公交线路信息。通过csv.writer创建一个csv文件写入器writer,然后循环遍历url_list列表中的每个URL,调用get_page_info()函数获取每个URL中的公交线路详细信息,并将获取到的信息写入到创建的CSV文件中。最后,再次打开“bus_info.csv”文件,通过csv.reader读取其中的数据,然后将每一行数据输出到终端,实现可视化输出。
运行结果

4. 保存公交数据到mysql数据库中
程序设计
修改主函数为:
if __name__ == "__main__":
url = 'http://suzhou.8684.cn/list%d'
url_list = []
cs = open("bus_info.csv",'w',newline='')
writer = csv.writer(cs)
for i in range(1,10):
urls = url % i
url_list += get_page_url(urls)
mysql_url = pymysql.connect(host="***", user="***", passwd="***", db="***")
curson = mysql_url.cursor()
curson.execute("create table bus_info(name varchar(1000), type varchar(1000), time varchar(1000),ticket varchar(1000),gongsi varchar(1000),gengxin varchar(1000),wang varchar(1000),wang_info varchar(1000),fan varchar(1000), fan_info varchar(1000))")
mysql_url.commit()
for i in url_list:
result = get_page_info(i)
writer.writerow(result)
data = tuple(result)
curson.execute('insert into bus_info(name,type,time,ticket,gongsi,gengxin,wang,wang_info,fan,fan_info) values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)', data)
mysql_url.commit()
该程序在前一个程序的基础上增加了将获取到的公交线路信息写入到MySQL数据库中的功能。程序开始时同样会判断当前模块是否为主模块,若是则执行程序中的main()函数。在main()函数中,首先打开一个名为“bus_info.csv”的文件,用于存储公交线路信息。通过csv.writer创建一个csv文件写入器writer,然后循环遍历url_list列表中的每个URL,调用get_page_info()函数获取每个URL中的公交线路详细信息,并将获取到的信息写入到创建的CSV文件中。接下来连接MySQL数据库,创建一个包含各列标题的表,用于存储公交线路信息。然后再次循环遍历url_list列表,调用get_page_info()函数获取该URL中的公交线路详细信息,并将获取到的信息通过SQL语句写入到已创建的MySQL表中。最后,提交数据库的更改并关闭数据库连接。这样就可以实现从网页上爬取公交线路信息并将其存储到MySQL数据库中。
运行结果

写在后面
我是一只有趣的兔子,感谢你的喜欢!