【STL】stack和queue
文章目录
- 1. stack和queue
-
- 1.1 stack的使用
- 1.2 queue的使用
- 1.3 priority_queue的使用
- 2 适配器模式
-
- 2.1 模拟实现stack
- 2.2 模拟实现queue
- 2.3 模拟实现priority_queue
- 3. 仿函数的更多用法
-
- 3.1 仿函数的优势
- 3.2 自己去写仿函数
- 4. deque
-
- 4.1 deque
- 4.2 vector、list的优缺点
- 4.3 deque的设计
- 4.4 性能测试
- 5. 反向迭代器
-
- 5.1 设计思路
- 5.2 模拟实现反向迭代器
- 5.3 测试
1. stack和queue
这篇博客我们要学3个数据结构:stack、queue以及priority_queue,但是它们都不是容器,它们是容器适配器。
为什么它们是容器适配器呢?我们先来看一下list、stack、queue的声明:
list的第二个参数是空间配置器,stack和queue的第二个参数是Container。
stack、queue不是自己实现的,它是依靠其他东西适配出来的。最终分别达到LIFO和FIFO的效果。

1.1 stack的使用
stack的Construct中除了构造函数,其他什么都没有,它连拷贝构造、析构都没有。这个也跟它是容器适配器有关系,因为它的成员都是自定义类型,编译器默认生成的就够用。
stack是容器适配器以后,就开始不支持迭代器了。容器支持迭代器,容器适配器不支持迭代器。
栈随便去遍历反而是不好的,因为要保证后进先出的性质。
所以取数据得用top,想取下一个数据就得先pop。
1.2 queue的使用
队列也是一样的道理,它没有迭代器。Construct也只提供了构造函数,没有拷贝构造和析构。原因是默认生成的就够用,一样的道理。
队列支持取队头(front)、取队尾(back)、插入(push)以及删除(pop)。
1.3 priority_queue的使用
优先级队列的适配会更复杂一些些。它的适配容器用的是vector。
优先级队列就不是什么先进先出了,它虽然叫队列,但它不是真队列。其实它的底层是堆,可以在任意时刻插入数据,默认是大堆,当然也可以通过仿函数去调整。
优先级队列有一个反人类的设计:传less仿函数,底层是大堆。传greater仿函数,底层是小堆。

我们再来看一看priority的函数接口:

它也有push、top和pop接口,但是它的top、pop分别是取或者删除优先级最高的数据,大的优先级高还是小的优先级高是可以控制的,具体看实际应用场景。
2 适配器模式
日常生活中,我们会有电源适配器。它可以把交流转直流,也可以控制瓦数。容器适配器也是同样的道理。
2.1 模拟实现stack
stack用数组结构去实现是比较好的。但是插入数据、删除数据等逻辑我们还要自己去写一遍吗?
自己写一遍太麻烦了,stack没有自己去实现,而是去转换。
stack默认用deque来转换,deque是一个双端队列,具体是什么,我们后面再说。
// Stack.h
#pragma once
namespace Yuucho
{
template>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
const T& top()
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
测试:

为什么叫适配器?还有一点在于它可以用不同的容器来转换,只是它默认传的是deque。
stack可以用任意线性容器适配。
stack> s;
stack> s;
stack s;
用string转换,数据可能会溢出或截断,有风险。
2.2 模拟实现queue
同样的道理,我们分分钟造一个队列出来。
队列就不支持vector适配了,因为vector不支持头部的删除。
// Queue.h
#pragma once
namespace Yuucho
{
template>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
const T& front()
{
return _con.front();
}
const T& back()
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
测试:

多样性适配:
stack> s;
2.3 模拟实现priority_queue
所有的适配器都想stack和queue一样轻轻松松就实现了吗?也不是。
优先级队列还得把堆的算法应用上去。但是我们也没必要原生去实现一个堆,所有它继续采用适配器容器。默认用的是vector,没有继续用deque,因为deque随机访问效率不高。priority_queue还有一个参数叫仿函数,我们待会再说。
STL库中是有堆的算法的,但是为了更好地让大家理解仿函数,我们这里自己实现堆的算法。在优先级队列里插入数据和删除数据时间复杂度是O(logn)。
// 我们跟着库走 -- 大堆 < 小堆 >
template>
class priority_queue
{
public:
void AdjustUp(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (_con[parent] < _con[child])
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
AdjustUp(_con.size() - 1);
}
void AdjustDown(int parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child+1 < _con.size() && _con[child] < _con[child+1])
{
++child;
}
if (_con[parent] < _con[child])
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
assert(!_con.empty());
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}
// 堆不允许随便修改数据
const T& top()
{
return _con[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
我们这种写法有一个缺陷,就是把优先级写死了,如果我们要排升序就没法玩了。
C++在这里为了控制这一个东西,它就搞出了一个仿函数。当然这里只是仿函数的一种价值,具体我们后面再说。
在这里,我们先写一个最简单的仿函数来控制优先级。这里仿函数会重载函数调用时的圆括号:函数名(形参表)。我们就可以让对象可以像调用函数一样去使用。
template
struct less
{
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
template
struct greater
{
bool operator()(const T& x, const T& y) const
{
return x > y;
}
};
ok,那我们怎么玩呢?可以用模板参数来玩(源码默认less是大堆)。我们比较的时候就可以不用确定的符号去比了,我们用仿函数去比较。到时候优先级就可以通过传参来控制。
// 优先级队列 -- 大堆 < 小堆 >
template, class Compare = less>
class priority_queue
{
public:
void AdjustUp(int child)
{
Compare comFunc;
int parent = (child - 1) / 2;
while (child > 0)
{
//if (_con[parent] < _con[child])
if (comFunc(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int parent)
{
Compare comFunc;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
//if (child+1 < _con.size() && _con[child] < _con[child+1])
if (child + 1 < _con.size() && comFunc(_con[child], _con[child + 1]))
{
++child;
}
//if (_con[parent] < _con[child])
if (comFunc(_con[parent],_con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
private:
Container _con;
};
测试:
void test_priority_queue()
{
//priority_queue pq; 啥也不传默认是大堆
priority_queue, greater> pq;// 小堆
pq.push(2);
pq.push(5);
pq.push(1);
pq.push(6);
pq.push(8);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
}

流程图梳理:

3. 仿函数的更多用法
3.1 仿函数的优势
C语言的函数指针多嵌套几层往往比较复杂,仿函数很多场景替代的是函数指针。

但是C++毕竟沿袭自C语言,要兼容大部分C语言的用法,所以这里不仅仅能传仿函数,也支持传函数指针类型。
因为模板参数可以自动推导
bool comIntLess(int x1, int x2)
{
return x1 > x2;
}
priority_queue, bool(*)(int, int)> pq;
函数指针和仿函数不一样的地方在于它实际调用的时候会出错。
仿函数本身是一个类型,这个类型传给Compare去定义一个对象。这个对象去调用operator()就调用到自己了。
但是如果传一个函数指针类型过去,那用这个函数指针去定义一个指针(随机值),还不知道指向谁,咋整?
虽然说在类模板里面,你传什么我就推演什么,但是函数指针在这是直接跑不起来的。
所以我们就要想想在构造的时候能不能传一个实质性的对象给我,让我想办法去走一下。
调用的时候把函数名(即函数指针)传给构造函数:
priority_queue, bool(*)(int, int)> pq(comIntLess);
template, class Compare = less>
class priority_queue
{
public:
// 默认用Compare构造的匿名对象来构造,是一个空指针。
// 显式传了函数名就能调用到comIntLess。
priority_queue(const Compare& comFunc = Compare())
:_comFunc(comFunc)
{}
// 用迭代器区间初始化,传一段区间就可以建堆,支持topK问题。
// void test_priority_queue2()
//{
// int a[] = { 1, 4, 2, 7, 8, 9 };
// priority_queue pq(a, a + 6);
//}
template
priority_queue(InputIterator first, InputIterator last,
const Compare& comFunc = Compare())
: _comFunc(comFunc)
{
while (first != last)
{
_con.push_back(*first);
++first;
}
// 建堆
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(i);
}
}
// ......
private:
Compare _comFunc;
Container _con;
};
3.2 自己去写仿函数
默认情况下我们用库里面的less或者greater就OK了。但是有些情况下必须我们自己显示地去写。
优先级队列是类模板,传的是类型;sort是函数模板,传的是对象。编译器都会自动推导。
比如说我们用sort去排序商品(自定义类型),就得自己写仿函数。
// 商品
struct Goods
{
string _name;
double _price;
size_t _saleNum; // 销量
};
void test_functional()
{
Goods gds[4] = { { "苹果", 2.1, 1000}, { "香蕉", 3.0, 200}, { "橙子", 2.2,300}, { "菠萝", 1.5,50} };
sort(gds, gds + 4, LessPrice());
sort(gds, gds + 4, GreaterPrice());
sort(gds, gds + 4, LessSaleNum());
sort(gds, gds + 4, GreaterSaleNum());
}
这里最大的问题就是自定义类型不支持比较大小而已,我们可以自己重载。
但是我们不会用重载,因为无法在一个类里面重载多个同样的关系运算符。
这个时候就要用仿函数了:
struct LessPrice
{
bool operator()(const Goods& g1, const Goods& g2) const
{
return g1._price < g2._price;
}
};
struct GreaterPrice
{
bool operator()(const Goods& g1, const Goods& g2) const
{
return g1._price > g2._price;
}
};
struct LessSaleNum
{
bool operator()(const Goods& g1, const Goods& g2) const
{
return g1._saleNum < g2._saleNum;
}
};
struct GreaterSaleNum
{
bool operator()(const Goods& g1, const Goods& g2) const
{
return g1._saleNum > g2._saleNum;
}
};
4. deque
4.1 deque
Deque(通常读作“deck”)是双端队列(double-ended queue)的不规则首字母缩写。 双端队列是具有动态大小的序列容器,可以在两端(前端或后端)展开或收缩。

deque结合了vector和list的优缺点设计出来的,听起来很牛逼,其实也就那回事,外强中干。
4.2 vector、list的优缺点
vector物理空间全部连续,你老让我扩容也不太好,不连续吧也不行。
list物理空间太碎,对访问也不太好。

4.3 deque的设计
有人就想那能不能折中一下,我设计一个deque,物理空间是一段一段的,比如说一段是10个。满了我在后面再加一段空间,我不去扩容。这样空间浪费也不会太多。比如vector一次扩容,从100扩到200,我只用120,80的空间就浪费了,而deque最多就浪费9个。
这样设计也可以间接支持随机访问,比如我要访问第23个数据,我只需要23/10,就知道它在第几个buf,再用23%10就知道它在buf的第几个位置。而且我头插也不用挪动数据了,我们在前面再加一段空间(buf)。
deque为了把所有的buf管理起来,又设计了一个中控数组(实际上是一个指针数组),还得有两个指针分别指向第一个数据和最后一个数据去控制头插、尾插。
比如你插入的第一个数据是10,它就在中控数组的最中间的指针去指向10的buf。
第一个buf满了,继续尾插就用数组中间指针的下一个指针指向新buf,头插就用数组中间指针的前一个指针去指向新buf。
中控数组满了,还是得扩容,但是它扩容的代价很小,因为它新开辟的空间只需要拷贝中控数组的指针。

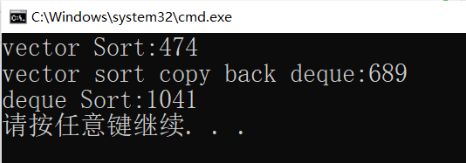
4.4 性能测试
void TestOP()
{
srand(time(0));
const int N = 10000000;
vector v;
v.reserve(N);
deque dq1;
deque dq2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
v.push_back(e);
dq1.push_back(e);
dq2.push_back(e);
}
// 用vector排序
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
// 把dq1拷贝给vector排序后再把数据拷贝回来
int begin2 = clock();
vector copy(dq1.begin(), dq1.end());
sort(copy.begin(), copy.end());
dq1.assign(copy.begin(), copy.end());
int end2 = clock();
// 用deque排序
int begin3 = clock();
sort(dq2.begin(), dq2.end());
int end3 = clock();
printf("vector Sort:%d\n", end1 - begin1);
printf("vector sort copy back deque:%d\n", end2 - begin2);
printf("deque Sort:%d\n", end3 - begin3);
}
5. 反向迭代器
5.1 设计思路
C++通过对不同容器的正向迭代器封装适配生成相应的反向迭代器。
怎么适配呢?通过再写一个reverse_iterator的类来适配。
rbegin用正向迭代器的end来构造,rend用正向迭代器的begin来构造。
++调用正向迭代器的–,–调用正向迭代器的++等。经典的对称设计。
OK,我们通过list的反向迭代器来加深理解,配合SGI中的源码来看:

5.2 模拟实现反向迭代器
简陋版的反向迭代器。
// ReverseIterator.h
#pragma once
namespace Yuucho
{
// 加后两个参数是为了支持vector的适配,库里面没有加,是使用了迭代器萃取的技术
template
struct Reverse_iterator
{
Iterator _it;
typedef Reverse_iterator Self;
Reverse_iterator(Iterator it)
:_it(it)
{}
Ref operator*()
{
Iterator tmp = _it;
return *(--tmp);
}
Ptr operator->()
{
return &(operator*());
}
Self& operator++()
{
--_it;
return *this;
}
Self& operator--()
{
++_it;
return *this;
}
bool operator!=(const Self& s)
{
return _it != s._it;
}
};
}
在list类中支持反向迭代器:
template
class list
{
typedef list_node Node;
public:
typedef __list_iterator iterator;
typedef __list_iterator const_iterator;
// 反向迭代器适配支持
typedef Reverse_iterator reverse_iterator;
typedef Reverse_iterator const_reverse_iterator;
const_reverse_iterator rbegin() const
{
return const_reverse_iterator(end());
}
const_reverse_iterator rend() const
{
return const_reverse_iterator(begin());
}
reverse_iterator rbegin()
{
return reverse_iterator(end());
}
reverse_iterator rend()
{
return reverse_iterator(begin());
}
// ......
}
在vector类中支持反向迭代器:
template
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
// 反向迭代器适配支持
typedef Reverse_iterator reverse_iterator;
typedef Reverse_iterator const_reverse_iterator;
const_reverse_iterator rbegin() const
{
return const_reverse_iterator(end());
}
const_reverse_iterator rend() const
{
return const_reverse_iterator(begin());
}
reverse_iterator rbegin()
{
return reverse_iterator(end());
}
reverse_iterator rend()
{
return reverse_iterator(begin());
}
// ......
}
5.3 测试
