ClickHouse 特性及存储原理
更多内容关注微信公众号:fullstack888
背景
目前业务中有大量实时分析需求,随着数据量的增加,基于行存储的 OLTP 数据库已经不能满足性能的需求,我们对 ClickHouse 进行了基础调研与性能摸底,并最终决定引入 ClickHouse 作为新系统的 OLAP 方案。
简介
ClickHouse 是一个列式存储数据库管理系统(DBMS)。相比于其他传统行式数据库系统,列式存储数据库更适合 OLAP 的场景,使用一个官方的动态图来做对比二者的性能(客观性大家自己判断):
行式存储:

列式存储:

行式存储与列式存储
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和 OLAP。相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于 OLTP。
以下述数据为例进行行式与列式存储的简单分析:
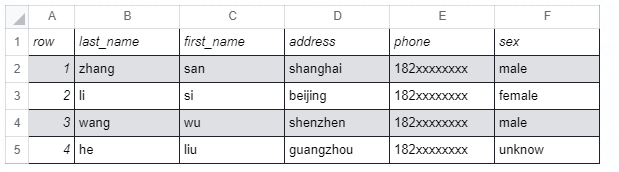
常见的数据库如:MySQL、Postgres 为行式存储数据库,需要把二维表存储在一系列一维的“字节”中,由操作系统写到内存或硬盘中。行式存储数据库把一“行”数据存储在一起,然后再存储下一“行”;读取时也按照行为单位读取,即使只需要其中的几个字段内容也是需要读取整行数据再进行过滤。简化的存储格式:
1,zhang,san,shanghai,182xxxxxxxx,male2,li,si,beijing,182xxxxxxxx,female3,wang,wu,shenzhen,182xxxxxxxx,male4,he,liu,guangzhou,182xxxxxxxx,unknow
列式存储则与之相反,以 ClickHouse 为例,逻辑上一行数据依旧是由多个不同的 column 组成,但列存储会将二维表中同一列的数据组织在一起,以 ClickHouse 为例:一列数据在物理硬盘上对应于一组文件,落盘存储前,ClickHouse 会对列数据进行压缩,相同类型的数据在一起压缩能提供更高压缩比;读取时也会优先对 SQL 进行解析和裁剪,只加载指定列数据,从而有效的降低数据从文件系统中加载的耗时。这是 ClickHouse 核心优势之一。
简化的存储格式(最后一行为对应列在文件系统中存储的文件名):
1 |zhang |san |shanghai |182xxxxxxxx|male
2 |li |si |beijing |182xxxxxxxx|female
3 |wang |wu |shenzhen |182xxxxxxxx|male
4 |he |liu |guangzhou |182xxxxxxxx|unknow
... | ... | ... | ... | ... | ...
row.bin |last_name.bin|first_name.bin|address.bin|phone.bin |sex.bin
数据存储
ClickHouse 中有众多的不同特性的表引擎可以应对不同的需要,其中 MergeTree 引擎作为 ClickHouse 的核心,凭借其强大的性能与丰富的特性得到了广泛的使用,并成为其他特性引擎的基础。后续将基于 MergeTree 引擎进行讨论。
由于 ClickHouse 的更新迭代较快,相邻版本之间的数据存储结构以及特性会有变化,但基本原理相通,本文基于 21.6.5 版本做演示和说明。
文件结构
在 ClickHouse 中,每个表都对应文件系统中的一个目录,目录中不同的文件保存了表数据与相关的属性信息,例如我们创建如下的表,并写入一些数据:
CREATE TABLE id_test( `ID` Int64, `StringID` FixedString(24))ENGINE = MergeTreeORDER BY (ID, StringID)SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0;
insert into id_test values(1,'1')(2,'2')
执行成功后会在文件系统中创建如下的目录结构:
id_test ├── all_1_1_0 │ ├── ID.bin │ ├── ID.mrk2 │ ├── StringID.bin │ ├── StringID.mrk2 │ ├── checksums.txt │ ├── columns.txt │ ├── count.txt │ └── primary.idx ├── detached └── format_version.txt
说明:
id_test:每个表在文件系统都对应于一个目录,以表名命名。
all_1_1_0:如果对表进行了分区,那么每个分区的都会有相应的目录,本例没有进行分区,所以只有一个目录。
checksums.txt:校验文件,二进制存储了各文件的大小、哈希等,用于快速校验存储的正确性。
columns.txt:列名以及数据类型,本例该文件的内容为:
columns format version: 12 columns:`ID` Int64`StringID` FixedString(24)
count.txt:记录数据的总行数,本例中文件内容为 2 (只写入了两行数据)。
primary.idx:主键索引文件,用于存放稀疏索引的数据。通过查询条件与稀疏索引能够快速的过滤无用的数据,减少需要加载的数据量。
{column}.bin:列数据的存储文件,以
列名+bin为文件名,默认设置采用 lz4 压缩格式。每一列都会有单独的文件(新版本需要指定 SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0 参数来强制跳过 Compact format)。{column}.mrk2:列数据的标记信息,记录了数据块在 bin 文件中的偏移量。标记文件首先与列数据的存储文件对齐,记录了某个压缩块在 bin 文件中的相对位置;其次与索引文件对齐,记录了稀疏索引对应数据在列存储文件中的位置。clickhouse 将首先通过索引文件定位到标记信息,再根据标记信息直接从.bin 数据文件中读取数据。
索引与数据存储
ClickHouse 通过将数据排序并建立稀疏索引的方式来加速数据的定位与查询;ClickHouse 的稀疏索引就像是目录只记录开始位置,一条索引记录就能标记大量的数据,而且数据量越大这种优势就会越明显。例如,MergeTree 默认的索引粒度(index_granularity)为 8192,标记 1 亿条数据只需要 12208 条索引。索引少占用的空间就小,所以对 ClickHouse 而言,primary.idx 中的数据是可以常驻内存。
引用官方文档的示例:

这里使用(CounterID,Date)两个字段作为索引,当需要查询 CounterID in ('a', 'h')时,服务器会定位到 mark [0,3) 和 mark [6,8);当需要查询 CounterID in ('a', 'h') and Date = 3 时,服务器会定位到 mark [1,3) 和 mark [7,8);当需要查询 Date=3 的时候,服务器会定位到 mark [1,10]。
稀疏索引无法精确的找到数据,只能定位到大概范围,但作为一个旨在处理海量数据的系统而言,这些性能浪费是可以忽略的。
上述分析可知,索引的性能会受到索引字段数据分布的影响,设计表的时候需要充分考虑业务数据的实际情况,避免使用区分度很低的字段做索引。同时索引粒度(index_granularity)也是一个重要的属性,ClickHouse 默认 8192,这个值在大多数的情况下都能提供良好的性能。
为了后续演示的方便,我们修改建表语句,将 index_granularity 设置为 3,如下:
CREATE TABLE id_test( `Score` Int64, `StringID` FixedString(24))ENGINE = MergeTreePRIMARY KEY (ID, StringID)SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, index_granularity=3
向刚才创建的表中写入几条数据:
insert into id_test values
(1,'607589cdcbc95900017ddf01')
(2,'607589cdcbc95900017ddf02')
(3,'607589cdcbc95900017ddf03')
(4,'607589cdcbc95900017ddf04')
(5,'607589cdcbc95900017ddf05')
(6,'607589cdcbc95900017ddf06')
(7,'607589cdcbc95900017ddf07')
(8,'607589cdcbc95900017ddf08')
(9,'607589cdcbc95900017ddf09')
我们使用 StringID 作为主键,为了记录首尾信息会固定创建两条索引,同时根据上述的索引粒度配置,每 3 行会生成一条索引记录:
607589cdcbc95900017ddf01(第一行)...607589cdcbc95900017ddf04(第四行)...607589cdcbc95900017ddf07(第七行)...607589cdcbc95900017ddf09(最后一行 - 第九行)
通过 primary.idx 文件内容分析,也能得到相同的结论,文件内容如下:
hexdump -C primary.idx00000000 18 36 30 37 35 38 39 63 64 63 62 63 39 35 39 30 |.607589cdcbc9590|00000010 30 30 31 37 64 64 66 30 31 18 36 30 37 35 38 39 |0017ddf01.607589|00000020 63 64 63 62 63 39 35 39 30 30 30 31 37 64 64 66 |cdcbc95900017ddf|00000030 30 34 18 36 30 37 35 38 39 63 64 63 62 63 39 35 |04.607589cdcbc95|00000040 39 30 30 30 31 37 64 64 66 30 37 18 36 30 37 35 |900017ddf07.6075|00000050 38 39 63 64 63 62 63 39 35 39 30 30 30 31 37 64 |89cdcbc95900017d|00000060 64 66 30 39 |df09|00000064
由于主键 StringID 是变长字符串,需要一字节来保存字符串的长度,测试数据中 StringID 的长度都是 24(0x18),所以第一位是 0x18,然后是相应的值:607589cdcbc95900017ddf01,随后紧接着第二个索引:长度+值。稀疏索引的存储非常紧密不浪费一点空间,ClickHouse 中很多的数据结构都是这种思路,这种极度优化的思路这也是 ClickHouse 高效的原因之一。
mark 的结构与数据存储文件
ClickHouse 中列数据的存储分为两个文件:{column}.bin、{column}.mrk2。在介绍这两个文件之前,先要介绍两个 MergeTree 存储的概念,granule 和 mark,官方说明如下:
Each data part is logically divided into granules. A granule is the smallest indivisible data set that ClickHouse reads when selecting data. ClickHouse does not split rows or values, so each granule always contains an integer number of rows. The first row of a granule is marked with the value of the primary key for the row. For each data part, ClickHouse creates an index file that stores the marks. For each column, whether it’s in the primary key or not, ClickHouse also stores the same marks. These marks let you find data directly in column files.
简单的解释就是:ClickHouse 会根据 index_granularity 的设置将数据分成多个 granule,每个 granule 中索引列的第一个记录将作为索引写入到 primary.idx;其他非索引列也会用相同的策略生成一条 mark 数据写入相应的*.mrk2 文件中,并与主键索引一一对应,用于快速定位数据。
*.bin 文件内容是压缩存放的,为了保证读写的效率,压缩的粒度有两个参数控制:max_compress_block_size(默认 1MB)和 min_compress_block_size(默认 64k),简单的算法描述如下:
假设每次写入的数据大小为 x:
如果 x<64KB,会等待下一批数据,直到累计的总量>64 的时候,生成一个压缩块。
如果 64KB
如果 x>1MB,则按照 1MB 进行分割,成为多个压缩块。
这就导致一个 granule 的数据也可能存放在多个压缩块中,同时一块压缩可能存有多个 granule 的数据。这就需要 mark 记录既要保存某个 granlue 与压缩块的对应关系,还保存其在压缩块中的相对位置。
索引使用与数据加载概述
下图简单的展示了 primary.idx,*.mrk2,*.bin 之间的对应关系,其中 *.bin 文件中压缩快 Block0,Block1 的划分仅仅只是为描述概念,实际情况可能不是这样。

在 ClickHouse 的查询过程中,理想的情况下可以通过查询条件,利用预设的分区信息,一级索引,二级索引,将需要加载的数据 mark 缩至最少,尽可能减少数据扫描的范围;通过 SQL 分析得到必须的数据列,根据 mark 范围,将必须的数据加载进内存,进行后续的处理。例如我们有如下的 SQL:
select StringID,avg(Score) from id_test where StringID between '607589cdcbc95900017ddf03' and '607589cdcbc95900017ddf06' group by StringID;
简化的 ClickHouse 数据加载过程如下:
根据条件 StringID 与一级索引,确定 mark 范围:
mark0 [607589cdcbc95900017ddf01, 607589cdcbc95900017ddf04) mark1 [607589cdcbc95900017ddf04, 607589cdcbc95900017ddf07)通过 sql 定位到需要加载 StringID 列和 Score 列的数据,根据步骤 1 得到的 mark 范围,需要从 StringID.bin 与 Score.bin 中加载 mark0 和 mark1 的数据。通过分析 Score.mrk2 和 StringID.mrk2 的内容,得到 mark0 和 mark1 对应的压缩 block 在 *.bin 文件中的偏移信息。将 Score.bin 以及 StringID.bin 中相应压缩 block 的数据读取出来并解压;根据 sql 的条件进行精确的过滤。
对数据进行后续处理,本例需要根据 StringID 进行聚合并计算 Score 的平均值,这一步基本上全部在内存中完成。
字段类型对索引性能分析
目前业务中使用 ClickHouse 作为 OLAP 的主要解决方案,处理各种业务报表,最广泛的分析需求是基于某个 ID 进行去重计数(uniq count),对应于 ClickHouse 中的 uniqExact() 和 uniq() 方法,需要将筛选范围内的所有数据全都加载进来进行去重统计。根据之前列存储的原理,可以猜测数据的类型对这种统计的影响会比较大。后续通过两种不同方案的对比,探讨数据类型对 uniqExact()的性能影响。
现在业务系统广泛使用 MongoDB 的 ObjectId 内部 ID,常见的思路是将 ObjectId 作为 hex 字符串保存并使用,后续使用两种方法进行性能优化,总体思路都是尽可能减少该列需要存储的数据大小:
因为 ObjectId 是一个 12 byte 的数据结构,可以直接保存成二进制数据。
将所有的 ObjectId 重新分配一个数字 I D,这种方式局限性较大,仅限于 ObjectId 个数有限的情况。
测试环境信息如下:
ClickHouse :21.6.5
CPU:intel i7 9th
内存:20GB
硬盘:SSD
构造数据
建立如下的表,同时包含三种数据类型的 ID,然后通过程序(详见附录)写入 100,000,000 条记录,其中包含 1,000,000 个 ObjectId ,最终的结果如下图:
# ClickHouse支持Int128等大数类型的功能是默认set allow_experimental_bigint_types=true# ClickHouse中可以使用String类型保存二进制的数据:# Strings of an arbitrary length. The length is not limited. The value can contain an arbitrary set of bytes, including null bytes. The String type replaces the types VARCHAR, BLOB, CLOB, and others from other DBMSs.CREATE TABLE MixDataType( SeqID Int64, StrID String, #字符串格式的ObjectId BytesID String, #直接拿将ObjectId的二进制数据保存到数据库。 MapID Int64 #将所有的ObjectId排序,使用数据下标作为新的ID)ENGINE = MergeTreeORDER BY SeqID
数据库中记录如下:
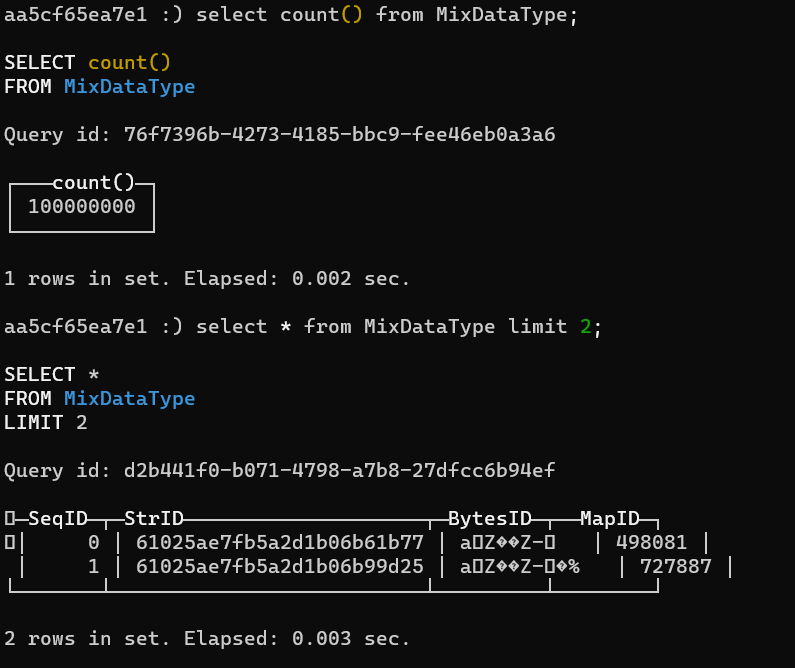
通过以下 SQL 中获取该表中各个列的实际存储情况:
SELECT table, name, type, formatReadableSize(data_compressed_bytes) AS compressed, formatReadableSize(data_uncompressed_bytes) AS ori, formatReadableSize(marks_bytes) AS mark_size, round((data_compressed_bytes/ data_uncompressed_bytes) * 100, 2) AS precentageFROM system.columnsWHERE (database = 'default') AND (table = 'MixDataType')
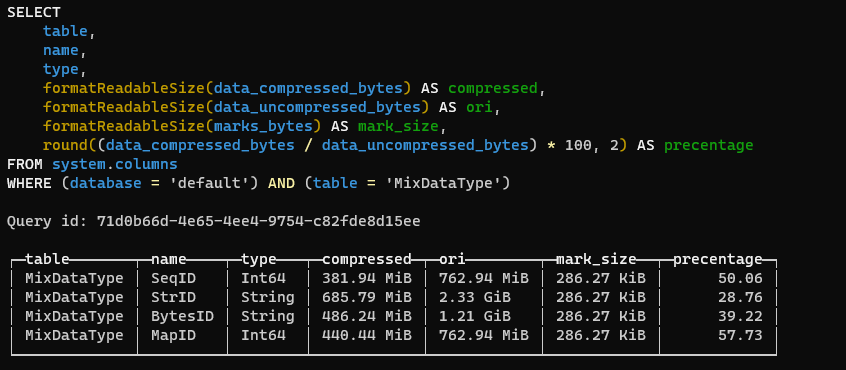
说明:
SeqID:行 ID,类似自增主键。
StrID:ObjectId 的 hex 字符串。原始大小:2.33GB,压缩后大小:685.79MB。
BytesID:ObjectId 的二进制内容。原始大小:1.21GB,压缩后大小:486.2MB。
MapID:将对所有 ObjectId 重新分配的 Int64 类型的 ID。原始大小:762MB,压缩后大小:440.44MB。
分析:
StrID 类型占用 24 字节(字符串长度是 24),BytesID 占用 12 字节,所以两个字段原始数据的大小比例大概为 2:1(2.33GB:1.21GB)
MapID 类型占用 8 字节(Int64),与 StrID 类型相比,原始数据大小的比例大概为 1:3(762MB:2.33GB);与 BytesID 相比,原始数据比例大概为 1:1.5(762MB:1.21GB)。
字符串的压缩率最高,Int64 的最低。
性能分析
对 StrID 进行统计,有如下结果:

说明:
一共有 1,000,000 个 ObjectId,统计总耗时 2.9s,一共处理了 100 million 行数据。
过程中一共处理了 3.3GB 的数据,处理速度大概 34.48 million rows/s。
对 BytesID 进行统计,有如下结果:
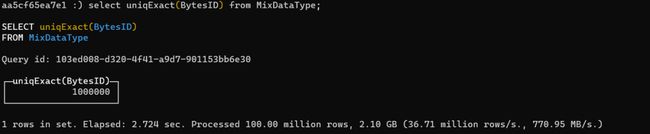
说明:
一共有 1,000,000 个 ObjectId,统计总耗时 2.7s,一共处理了 100 million 行数据。
过程一共处理了 2.1GB 的数据,处理速度大概 37.71 million rows/s。
对 MapID 进行统计,有如下结果:

说明:
一共有 1,000,000 个 ObjectId,统计总耗时 0.78s,一共处理了 100 million 行数据。
过程一共处理了 800MB 的数据,处理速度大概 127.75 million rows/s。
总结:
原始字符串做 ID 取出即可使用,较为便利;但在内存占用以及耗时方面没有优势。
使用 Blob 做 ID 在取出后需要进行处理才能得到可读可用的 ID,耗时方面没有明显的优势,但可以降低内存的使用。
将原始字符串 ID 再次映射成唯一的数字 ID,在内存使用,统计速度都可以得到大幅度的提升。同时缺点也比较明显:取出的 ID 需要二次查询后在才能对应到原始 ID,同时对原始 ID 个数有限制。
综合上述,如果业务 ID 是有限的,同时存在大量去重统计或者全量加载统计的需求,那么可以考虑建立二次 ID 映射,在 ClickHouse 中使用整形代替字符串作为 ID。
PS:ClickHouse 中 原生支持 UUID 类型。
- END -
推荐阅读:
Java日志框架的那些事儿
技术债不是负担,而是成功的战略杠杆
如何构建一个较为通用的业务技术架构
Kafka 为何弃用 zookeeper
关于软件分层设计的一些思考
技术债管理的七大挑战

关注:fullstack888
学习架构知识
互联网后端架构
