牛客刷题笔记--(java基础101-150)
101 ArrayList和LinkList的描述,下面说法错误的是?(D)
LinkedeList和ArrayList都实现了List接口
ArrayList是可改变大小的数组,而LinkedList是双向链接串列
LinkedList不支持高效的随机元素访问
在LinkedList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在ArrayList的中间插入或删除一个元素的开销是固定的
解释:
ArrayList是基于数组的,所以,具备随机访问特点,但LinkedList就不一样了,虽然,也可以通过也支持随机访问,但却付出了一定的代价。在LInkedLIst中,如果想返回某个位置的元素,就是从前往后遍历。
LinkedList是基于双链表的,增加是在尾部增加,增加和删除都只需要修改指针,不需要移动元素。
ArrayList插入或删除一个元素的开销不是固定的。在插入时,如果索引正确,容量够,则直接插入,插入位置之后的都需要移动,如果容量不够,还得扩充容量,开销当然不一样。删除操作同理。
ArryList和LinkedList都实现了List接口,ArrayList的内存结构是数组,本质是顺序存储的线性表,插入和删除操作都会引起后续元素移动,效率低,但是随机访问效率高
LinkedList的内存结构是双向链表存储的,链式存储结构插入和删除效率高,不需要移动,但是随机访问效率低,需要从头开始向后依次访问
所谓构造方法, 1,使用关键字new实例化一个新对象的时候默认调用的方法; 2,构造方法所完成的主要工作是对新创建对象的数据成员赋初值。 使用构造方法时需注意以下几点 1.构造方法名称和其所属的类名必须保持一致; 2.构造方法没有返回值,也不可以使用void; 3.构造方法也可以像普通方法一样被重载; 4.构造方法不能被static和final修饰; 5.构造方法不能被继承,子类使用父类的构造方法需要使用super关键字
javac是将源程序.java编译成.class文件
java是将字节码转换为机器码文件执行
102 我们在程序中经常使用“System.out.println()”来输出信息,语句中的System是包名,out是类名,println是方法名。(错误)
System是java.lang中的类(因此system不是包的名字,java.lang才是),out为System中的一个静态成员,out是java.io.PrintStream类的对象,而println()是java.io.PrintStream类的方法,所有可以调用类.静态方法.println()方法。
System是一个类名,out是System类里面的一个静态数据成员,而这个成员是java.io.PrintStream的对象,println是PrintStream类里面的一个方法,它的作用是向控制台输出内容。
103语句:char foo=‘中’,是否正确?(假设源文件以GB2312编码存储,并且以javac – encoding GB2312命令编译)(正确 )
Java语言中,中文字符所占的字节数取决于字符的编码方式,一般情况下,采用ISO8859-1编码方式时,一个中文字符与一个英文字符一样只占1个字节;采用GB2312或GBK编码方式时,一个中文字符占2个字节;而采用UTF-8编码方式时,一个中文字符会占3个字节。
在C++中
在C++中,char是基础数据类型,8位,1个字节。byte不是基础数据类型,一般是typedef unsigned char byte;这样子的,也就是说,byte其实是unsigned char类型,那么也是8位,1个字节。不同的是,char可以表示的范围是-128-127,而byte可以表示的范围是0-255。
在Java中
在java中,char和byte都是基础数据类型,其中的byte和C++中的char类型是一样的,8位,1个字节,-128-127。但是,char类型,是16位,2个字节, ‘\u0000’-’\uFFFF’。
为什么java里的char是2个字节?
因为java内部都是用unicode的,所以java其实是支持中文变量名的,比如string 世界 = “我的世界”;这样的语句是可以通过的。
综上,java中采用GB2312或GBK编码方式时,一个中文字符占2个字节,而char是2个字节,所以是对的
这在java中是正确的,在C语言中是错误的,java的char类型占两个字节,默认使用GBK编码存储。这种写法是正确的,此外java还可以用中文做变量名。
c是面向过程,java和c++都是面向对象,面向对象的三大特征是:封装、继承、多态。
104 下列那些方法是线程安全的(所调用的方法都存在)ACD
public class MyServlet implements Servlet {
public void service (ServletRequest req, ServletResponse resp) {
BigInteger I = extractFromRequest(req);
encodeIntoResponse(resp,factors);
}
}
public class MyServlet implements Servlet {
private long count =0;
public long getCount() {
return count;
}
public void service (ServletRequest req, ServletResponse resp) {
BigInteger I = extractFromRequest(req);
BigInteger[] factors = factor(i);
count ++;
encodeIntoResponse(resp,factors);
}
}
public class MyClass {
private int value;
public synchronized int get() {
return value;
}
public synchronized void set (int value) {
this.value = value;
}
}
public class Factorizer implements Servlet {
private volatile MyCache cache = new MyCache(null,null);
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = cache.getFactors(i);
if (factors == null) {
factors = factor(i);
cache = new MyCache(i,factors);
}
encodeIntoResponse(resp,factors);
}
这几个类都没有类属性,不存在共享资源,为了满足题目的意思,应该是多线程情况下使用同一个对象,以达到使成员成为共享资源的目的; A:没有成员(没有共享资源),线程安全; B:假设存在线程1和线程2,count初始值为0,当线程1执行count++中count+1(此时未写回最终计算值),这时线程2执行count++中读取count,发生数据错误,导致线程1线程2的结果都为1,而不是线程1的结果为1,线程2的结果为2,线程不安全; C:成员私有,对成员的set get方法都加重量级锁,线程安全; D:volatile有两个作用:可见性(volatile变量的改变能使其他线程立即可见,但它不是线程安全的,参考B)和禁止重排序;这里是可见性的应用,类中方法对volatile修饰的变量只有赋值,线程安全; 欢迎指正。
105 以下哪些代码段能正确执行(CD)
public static void main(String args[]) {<br />byte a = 3;<br />byte b = 2;<br />b = a + b;<br />System.out.println(b);<br />}
public static void main(String args[]) {<br />byte a = 127;<br />byte b = 126;<br />b = a + b;<br />System.out.println(b);<br />}
public static void main(String args[]) {<br />byte a = 3;<br />byte b = 2;<br />a+=b;<br />System.out.println(b);<br />}
public static void main(String args[]) {<br />byte a = 127;<br />byte b = 127;<br />a+=b;<br />System.out.println(b);<br />}
byte类型的变量在做运算时被会转换为int类型的值,故A、B左为byte,右为int,会报错;而C、D语句中用的是a+=b的语句,此语句会将被赋值的变量自动强制转化为相对应的类型。
+=会自动强转(自动装箱功能),但是+必须要手动强转b=(byte)(a+b)
106 往OuterClass类的代码段中插入内部类声明, 哪一个是错误的:(ABCD)
public class OuterClass{
private float f=1.0f;
//插入代码到这里
}
class InnerClass{
public static float func(){return f;}
}
abstract class InnerClass{
public abstract float func(){}
}
static class InnerClass{
protected static float func(){return f;}
}
public class InnerClass{
static float func(){return f;}
}
主要考核了这几个知识点:
1.静态内部类才可以声明静态方法
2.静态方法不可以使用非静态变量
3.抽象方法不可以有函数体
静态方法不能访问非静态变量,A和C错;
抽象类中的抽象方法不能有方法提,B错;
一个类中有多个类声明时,只能有一个public类,D错
107 A 是抽象父类或接口, B , C 派生自 A ,或实现 A ,现在 Java 源代码中有如下声明:
-
A a0=new A();
-
A a1 =new B();
-
A a2=new C();
问以下哪个说法是正确的?( A)
第1行不能通过编译
第1、2行能通过编译,但第3行编译出错
第1、2、3行能通过编译,但第2、3行运行时出错
第1行、第2行和第3行的声明都是正确的
解释:抽象类不能实例化, 理解多态就好了
108 下列说法正确的是(C)
java中包的主要作用是实现跨平台功能
package语句只能放在import语句后面
包(package)由一组类(class)和接口(interface)组成
可以用#include关键词来标明来自其它包中的类
A: java中"包"的引入的主要原因是java本身跨平台特性的需求。实现跨平台的是JVM。
B: package语句是Java源文件的第一条语句。(若缺省该语句,则指定为无名包。),如果想在另一个类里面引用包里面的类,要把名字写全。(相当用文件的绝对路径访问)或者用import导入。
D:java中并无#include关键字, 如果想在另一个类里面引用包里面的类,要把名字写全。(相当用文件的绝对路径访问)或者用import导入。
包的作用
1 把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。
2 如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。
3 包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。
package必须放在import的前面
不是include,而是import
需要注意的是包中不一定要有接口或者类,有其中一个就行了,有歧义
109 下面程序的输出结果为( B )
public class Demo {
public static String sRet = "";
public static void func(int i)
{
try
{
if (i%2==0)
{
throw new Exception();
}
}
catch (Exception e)
{
sRet += "0";
return;
}
finally
{
sRet += "1";
}
sRet += "2";
}
public static void main(String[] args)
{
func(1);
func(2);
System.out.println(sRet);
}
}
120
1201
12012
101
第一步,func(1),if条件不成立,不抛出异常,catch不运行,final运行,拼串得到“1”,程序继续往下走,拼串得到“12”。 第二步,fun(2),if条件成立,抛出异常,catch捕获异常,运行catch里面代码,拼串得到“120”,虽然有return,但是不管出不出异常,final里代码必须执行,执行final,拼串得到“1201”,然后return结束。所以最终结果“1201”
110 下面代码的运行结果为:(C)
代码得到编译,并输出“s=”
代码得到编译,并输出“s=null”
由于String s没有初始化,代码不能编译通过
代码得到编译,但捕获到 NullPointException异常
解释:局部变量可以先申明不用必须初始化,但使用到了一定要先初始化
局部变量,没有像成员变量那样类加载时会有初始化赋值,所以要使用局部变量时,一定要显式的给它赋值,也就是定义时就给它数值。
111 Hashtable 和 HashMap 的区别是: (BCDE)
Hashtable 是一个哈希表,该类继承了 AbstractMap,实现了 Map 接口
HashMap 是内部基于哈希表实现,该类继承AbstractMap,实现Map接口
Hashtable 线程安全的,而 HashMap 是线程不安全的
Properties 类 继承了 Hashtable 类,而 Hashtable 类则继承Dictionary 类
HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
Hashtable:
(1)Hashtable 是一个散列表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
(3)HashTable直接使用对象的hashCode。
HashMap:
(1)由数组+链表组成的,基于哈希表的Map实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
(2)不是线程安全的,HashMap可以接受为null的键(key)和值(value)。
(3)HashMap重新计算hash值
112 执行如下程序代码
char chr = 127;
int sum = 200;
chr += 1;
sum += chr;
后,sum的值是 ; ( AC )
备注:同时考虑c/c++和Java的情况的话
72
99
328
327
Java中只有byte, boolean是一个字节, char是两个字节, 所以对于java来说127不会发生溢出, 输出328
但是对于c/c++语言来说, char是一个字节, 会发生溢出, 对127加一发生溢出, 0111 1111 --> 1000 0000, 1000 0000为补码-128, 所以结果为200-128=72
113 下面哪些描述是正确的:( BC)
public class Test {
public static class A {
private B ref;
public void setB(B b) {
ref = b;
}
}
public static Class B {
private A ref;
public void setA(A a) {
ref = a;
}
}
public static void main(String args[]) {
…
start();
….
}
public static void start() { A a = new A();
B b = new B();
a.setB(b);
b = null; //
a = null;
…
}
}
b = null执行后b可以被垃圾回收
a = null执行后b可以被垃圾回收
a = null执行后a可以被垃圾回收
a,b必须在整个程序结束后才能被垃圾回收
类A和类B在设计上有循环引用,会导致内存泄露
a, b 必须在start方法执行完毕才能被垃圾回收

答案BC。
内存如下:
a -> “a(b)”
b -> “b”
a引用指向一块空间,这块空间里面包含着b对象
b引用指向一块空间,这块空间是b对象
A选项,b = null执行后b可以被垃圾回收。这里"b可以被垃圾回收"中的b指的是引用b指向的内存。这块内存即使不被引用b指向,还是被引用a指向着,不会被回收。
B选项,a = null执行后b可以被垃圾回收。从代码中可以看到,a = null是在b = null后执行的,该行执行后,引用a和b都没有指向对象,对象会被回收。
C选项,同理。
深堆和浅堆的问题
深堆:自己的和引用别的对象
浅堆:只有自己的
这个题:互相引用
如果使用计数器法来看 肯定是不能够回收的
现在虚拟机内部使用的是可达性分析
a.set(b) a包含b的引用 深堆全部释放 a b全部被回收
114以下代码在编译和运行过程中会出现什么情况 (A)
public class TestDemo{
private int count;
public static void main(String[] args) {
TestDemo test=new TestDemo(88);
System.out.println(test.count);
}
TestDemo(int a) {
count=a;
}
}
编译运行通过,输出结果是88
编译时错误,count变量定义的是私有变量
编译时错误,System.out.println方法被调用时test没有被初始化
编译和执行时没有输出结果
解释:private是私有变量,只能用于当前类中,题目中的main方法也位于当前类,所以可以正确输出
115 有如下代码:请写出程序的输出结果。 (B)
public class Test
{
public static void main(String[] args)
{
int x = 0;
int y = 0;
int k = 0;
for (int z = 0; z < 5; z++) {
if ((++x > 2) && (++y > 2) && (k++ > 2))
{
x++;
++y;
k++;
}
}
System.out.println(x + ”” +y + ”” +k);
}
}
432
531
421
523
z=0时候,执行++x > 2,不成立,&&后面就不执行了,此时 x=1,y=0,k=0;
z=1时候,执行++x > 2,还不成立 ,&&后面就不执行了,此时 x=2,y=0,k=0;
z=2时候, 执行++x > 2,成立,继续执行 ++y > 2, 不成立 , &&后面就不执行了, 此时 x=3,y=1,k=0;
z=3时候,执行++x > 2,成立,继续执行++y > 2,不成立 , &&后面就不执行了, 此时 x=4,y=2,k=0;
z=4 时候,执行++x > 2,成立,继续执行 ++y > 2, 成立 , 继续执行k++>2 ,不成立,此时仍没有进入for循环的语句中, 但此时 x=5,y=3,k=1;
z=5时候,不满足条件了,整个循环结束,所以最后打印时候: x=5,y=3,k=1;
&和&&都是逻辑运算符,都是判断两边同时真则为真,否则为假;但是&&当第一个条件不成之后,后面的条件都不执行了,而&则还是继续执行,直到整个条件语句执行完为止
116 下面代码的执行结果是 : (A)
class Chinese{
private static Chinese objref =new Chinese();
private Chinese(){}
public static Chinese getInstance() { return objref; }
}
public class TestChinese {
public static void main(String [] args) {
Chinese obj1 = Chinese.getInstance();
Chinese obj2 = Chinese.getInstance();
System.out.println(obj1 == obj2);
}
}
true
false
TRUE
FALSE
单例模式,obj1和obj2其实是一个对象,应该返回true!
饿汉式单例模式,在类创建时,就已经实例化完成,在调用Chinese.getInstance()时,直接获取静态对象
单例模式: 第一步,不让外部调用创建对象,所以把构造器私有化,用private修饰。 第二步,怎么让外部获取本类的实例对象?通过本类提供一个方法,供外部调用获取实例。由于没有对象调用,所以此方法为类方法,用static修饰。 第三步,通过方法返回实例对象,由于类方法(静态方法)只能调用静态变量,所以存放该实例的变量改为类变量,用static修饰。 最后,类变量,类方法是在类加载时初始化的,只加载一次。所以由于外部不能创建对象,而且本来实例只在类加载时创建一次
117 下列语句正确的是:(D)
形式参数可被字段修饰符修饰
形式参数不可以是对象
形式参数为方法被调用时真正被传递的参数
形式参数可被视为local variable
A:形式参数只能被final修饰
B:形式参数可以是对象
C:形式参数被调用时被传递的是实际参数的拷贝
D:local variable:局部变量
java修饰符专项
形式参数:就是在定义函数或过程的时候命名的参数。通俗讲就是一个记号。
对于形式参数只能用final修饰符,其它任何修饰符都会引起编译器错误。但是用这个修饰符也有一定的限制,就是在方法中不能对参数做任何修改。
形式参数为方法在定义时没有给它参数,在调用是就没有参数传递。
local variable的中文意思是局部变量。
118 尝试编译以下程序会产生怎么样的结果?(C)
public class MyClass {
long var;
public void MyClass(long param) { var = param; }//(1)
public static void main(String[] args) {
MyClass a, b;
a =new MyClass();//(2)
b =new MyClass(5);//(3)
}
}
编译错误将发生在(1),因为构造函数不能指定返回值
编译错误将发生在(2),因为该类没有默认构造函数
编译错误将在(3)处发生,因为该类没有构造函数,该构造函数接受一个int类型的参数
该程序将正确编译和执行
这道题一定要看仔细了,MyClass方法并不是构造参数,而是返回类型为void的普通方法,普通方法自然需要实例化对象然后去调用它,所以124不对,第三个是正确的,因为没有带参数的构造器,所以自然不能传一个int进去。
构造方法就是:public 类名, 没有方法修饰符,所以 (1) 处就是一个普通方法,所以该类没有带参数构造方法 ,编译报错
119 以下哪些jvm的垃圾回收方式采用的是复制算法回收(AD)
新生代串行收集器
老年代串行收集器
并行收集器
新生代并行回收收集器
老年代并行回收收集器
cms收集器
两个最基本的java回收算法:复制算法和标记清理算法
复制算法:两个区域A和B,初始对象在A,继续存活的对象被转移到B。此为新生代最常用的算法
标记清理:一块区域,标记可达对象(可达性分析),然后回收不可达对象,会出现碎片,那么引出
标记-整理算法:多了碎片整理,整理出更大的内存放更大的对象
两个概念:新生代和年老代
新生代:初始对象,生命周期短的
永久代:长时间存在的对象
整个java的垃圾回收是新生代和年老代的协作,这种叫做分代回收。
P.S:Serial New收集器是针对新生代的收集器,采用的是复制算法
Parallel New(并行)收集器,新生代采用复制算法,老年代采用标记整理
Parallel Scavenge(并行)收集器,针对新生代,采用复制收集算法
Serial Old(串行)收集器,新生代采用复制,老年代采用标记整理
Parallel Old(并行)收集器,针对老年代,标记整理
CMS收集器,基于标记清理
G1收集器:整体上是基于标记 整理 ,局部采用复制
综上:新生代基本采用复制算法,老年代采用标记整理算法。cms采用标记清理。
120下面有关java threadlocal说法正确的有?(ABCD)
ThreadLocal存放的值是线程封闭,线程间互斥的,主要用于线程内共享一些数据,避免通过参数来传递
线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收
在Thread类中有一个Map,用于存储每一个线程的变量的副本。
对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式
ThreadLocal类用来提供线程内部的局部变量。这种变量在多线程环境下访问(通过get或set方法访问)时能保证各个线程里的变量相对独立于其他线程内的变量。ThreadLocal实例通常来说都是private static类型的,用于关联线程和线程的上下文。 ==可以总结为一句话:ThreadLocal的作用是提供线程内的局部变量,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或者组件之间一些公共变量的传递的复杂度。 ==举个例子,我出门需要先坐公交再做地铁,这里的坐公交和坐地铁就好比是同一个线程内的两个函数,我就是一个线程,我要完成这两个函数都需要同一个东西:公交卡(北京公交和地铁都使用公交卡),那么我为了不向这两个函数都传递公交卡这个变量(相当于不是一直带着公交卡上路),我可以这么做:将公交卡事先交给一个机构,当我需要刷卡的时候再向这个机构要公交卡(当然每次拿的都是同一张公交卡)。这样就能达到只要是我(同一个线程)需要公交卡,何时何地都能向这个机构要的目的。 有人要说了:你可以将公交卡设置为全局变量啊,这样不是也能何时何地都能取公交卡吗?但是如果有很多个人(很多个线程)呢?大家可不能都使用同一张公交卡吧(我们假设公交卡是实名认证的),这样不就乱套了嘛。现在明白了吧?这就是ThreadLocal设计的初衷:提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程。
121 下列说法正确的有(A)
数组是一种对象
数组属于一种原生类
int number=[]={31,23,33,43,35,63}
数组的大小可以任意改变
原生类是指Java中,数据类型分为基本数据类型(或叫做原生类、内置类型)和引用数据类型。
java眼中,万物皆为对象,数组自然是对象。
数组不是基本类型,在java中,数据类型就分为基本数据类型(即原生类)和引用数据类型,所以数组不是原生类。
122 try块后必须有catch块。(错误)
try 和 catch 不需要一定共存,try是尝试对其中代码捕获异常,catch是捕获异常并且可以处理异常。你可以 try 来搜寻异常,不去捕获。也就是不去catch 这是可以的。至于提示加finally,finally的意思是,其中的代码一定会执行,也就是说,如果try 其中的代码产生了异常,如果有catch 则会直接跳转到catch部分,如果没有catch 会跳转到‘}’后面的代码,这样,以上方法就没有一个确定的返回值,所以要加finally 作为方法出异常以后的返回的结果。
123 下面有关JSP内置对象的描述,说法错误的是?(C)
session对象:session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止
request对象:客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应
application对象:多个application对象实现了用户间数据的共享,可存放全局变量
response对象:response对象包含了响应客户请求的有关信息
解释;application对象是共享的,多个用户共享一个,以此实现数据共享和通信。application服务器就创建了一个
124 以下代码执行后输出结果为( A)
public class Test
{
public static Test t1 = new Test();
{
System.out.println("blockA");
}
static
{
System.out.println("blockB");
}
public static void main(String[] args)
{
Test t2 = new Test();
}
}
blockAblockBblockA
blockAblockAblockB
blockBblockBblockA
blockBblockAblockB
静态块:用static申明,JVM加载类时执行,仅执行一次
构造块:类中直接用{}定义,每一次创建对象时执行
执行顺序优先级:静态块>main()>构造块>构造方法
静态块按照申明顺序执行,先执行Test t1 = new Test();
所有先输出blockA,然后执行静态块,输出blockB,最后执行main
方法中的Test t2 = new Test();输出blockA。
1.首先,需要明白类的加载顺序。
(1) 父类静态对象和静态代码块
(2) 子类静态对象和静态代码块
(3) 父类非静态对象和非静态代码块
(4) 父类构造函数
(5) 子类 非静态对象和非静态代码块
(6) 子类构造函数
其中:类中静态块按照声明顺序执行,并且(1)和(2)不需要调用new类实例的时候就执行了(意思就是在类加载到方法区的时候执行的)
2.因而,整体的执行顺序为
public static Test t1 = new Test(); //(1)
static
{
System.out.println(“blockB”); //(2)
}
Test t2 =new Test(); //(3)
在执行(1)时创建了一个Test对象,在这个过程中会执行非静态代码块和缺省的无参构造函数,在执行非静态代码块时就输出了blockA;然后执行(2)输出blockB;执行(3)的过程同样会执行非静态代码块和缺省的无参构造函数,在执行非静态代码块时输出blockA。因此,最终的结果为
blockA
blockB
blockA
public class Test
{
public static Test t1 = new Test();//静态变量
//构造块
{
System.out.println("blockA");
}
//静态块
static
{
System.out.println("blockB");
}
public static void main(String[] args)
{
Test t2 = new Test();
}
}
静态域:用staitc声明,jvm加载类时执行,仅执行一次
构造代码块:类中直接用{}定义,每一次创建对象时执行。
执行顺序优先级:静态域,main(),构造代码块,构造方法。
1 静态域 :首先执行,第一个静态域是一个静态变量 public static Test t1 = new Test(); 创建了Test 对象,会执行构造块代码,所以输出blockA。然后执行第二个静态域(即静态代码块)输出blockB。
2 main():Test t2 = new Test()执行,创建Test类对象,只会执行构造代码块(创建对象时执行),输出blockA。
3 构造代码块只会在创建对象时执行,没创建任何对象了,所以没输出
4 构造函数:使用默认构造函数,没任何输出
125 下面哪些具体实现类可以用于存储键,值对,并且方法调用提供了基本的多线程安全支持:(AE )
java.util.ConcurrentHashMap
java.util.Map
java.util.TreeMap
java.util.SortMap
java.util.Hashtable
java.util.HashMap
线程安全的类有hashtable concurrentHashMap synchronizedMap
java.util.concurrent.ConcurrentHashMap 线程安全
java.util.Map 接口
java.util.TreeMap
java.util.SortedMap 接口
java.util.Hashtable 线程安全
java.util.HashMap
ConcurrentHashMap 键值对不可以为空,线程安全 java.util.Map是一个接口 java.util.TreeMap 键值对不可以为空,非线程安全 java.util.SortedMap 这是个接口并且扩展了Map接口,它确保条目按升序键维护。 java.util.Hashtable 键值对不可以为空,线程安全 java.util.HashMap键值对可以为空,非线程安全
126 下面描述属于java虚拟机功能的是?(ABCD)
通过 ClassLoader 寻找和装载 class 文件
解释字节码成为指令并执行,提供 class 文件的运行环境
进行运行期间垃圾回收
提供与硬件交互的平台
127 CMS垃圾回收器在那些阶段是没用用户线程参与的(AC)
初始标记
并发标记
重新标记
并发清理
户线程(user-level threads)指不需要内核支持而在用户程序中实现的线程,其不依赖于操作系统核心,应用进程利用线程库提供创建、同步、调度和管理线程的函数来控制用户线程。
CMS的GC过程有6个阶段(4个并发,2个暂停其它应用程序)
- 初次标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发可中断预清理(Concurrent precleaning)
- 最终重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
在初次标记,重新标志的时候,要求我们暂停其它应用程序,那么这两个阶段用户线程是不会参与的
128 JDK提供的用于并发编程的同步器有哪些?(ABC)
Semaphore
CyclicBarrier
CountDownLatch
Counter
同步器是一些使线程能够等待另一个线程的对象,允许它们协调动作。最常用的同步器是CountDownLatch和Semaphore,不常用的是Barrier 和Exchanger
A. semaphore:信号量。用于表示共享资源数量。用acquire()获取资源,用release()释放资源。
B. CyclicBarrier 线程到达屏障后等待,当一组线程都到达屏障后才一起恢复执行
C. CountDownLatch 初始时给定一个值,每次调用countDown值减1,当值为0时阻塞的线程恢复执行
D. 不知道是啥。。。。反正不是同步器
129 以下选项中,合法的赋值语句是(B)
a>1;
i++;
a= a+1=5;
y = int ( i );
B项,中间变量缓存机制。等同于temp = i;i=i+1;i=temp;D项,y=(int)i
130下列说法正确的是(AB)
JAVA程序的main方法必须写在类里面
JAVA程序中可以有多个名字为main方法
JAVA程序中类名必须与文件名一样
JAVA程序的main方法中,如果只有一条语句,可以不用{}(大括号)括起来
解释:
A,java是强类型语言,所有的方法必须放在类里面,包括main
强类型和弱类型的语言有什么区别
B ,java中可以有多个重载的main方法,只有public static void main(String[] args){}是函数入口
C,内部类的类名一般与文件名不同
D,函数都必须用{}括起来,不管是一条语句还是多条语句
131 Java.Thread的方法resume()负责重新开始被以下哪个方法中断的线程的执行(D)。
stop
sleep
wait
suspend
suspend() 和 resume() 方法:两个方法配套使用,suspend()使得线程进入阻塞状态,并且不会自动恢复,必须其对应的 resume() 被调用,才能使得线程重新进入可执行状态
132 下列容器中,哪些容器按 key 查找的复杂度为 O(log(n)) (BC)
std::unordered_set
std::multimap
std::map
std::deque
STL库中,map和multimap底层都是红黑树实现的,两者的不同在于multimap允许重复的可以,而map中不行。红黑树的查找复杂度为O(log(n)) ,nodered_map/_set底层是哈希表实现的,查找复杂度为O(1)
133 以下程序执行后,错误的结果是(ABC)
public class Test {
private String name = "abc";
public static void main(String[] args) {
Test test = new Test();
Test testB = new Test();
String result = test.equals(testB) + ",";
result += test.name.equals(testB.name) + ",";
result += test.name == testB.name;
System.out.println(result);
}
}
true,true,true
true,false,false
false,true,false
false,true,true
1、首先应该注意到作为成员变量的 name 是使用字面量直接赋值的 ( privateString name =“abc”; ) 这种赋值的执行过程是先看字符串常量池中有没有 value 数组为 [‘a’, ‘b’, ‘c’] 的 String 对象,如果没有的话就创建一个,有的话就拿到他的一个引用。
2、name 没有被static 修饰,所以每实例化一个对象都会执行 private String name =“abc”; 第一次执行的时候发现字符串常量池没有 value 数组为 [‘a’, ‘b’, ‘c’]的String 对象,所以创建一个,拿到他的一个引用,但是第二次的时候发现已经有了这样的对象了, 所以只是拿到这个拿到这个对象的一个引用而已。
3、执行 test.name == testB.name; 的时候比较的是两个name指向的内存是不是同一个(比较引用本身没有意义),所以 test.name == testB.name; 的结果是true。

1.test.equals(testB),两个对象用equals()函数比较,如果两个对象是一个则返回true,如果不是String的实例并且是两个不同的对象则返回false,==当两个对象是String的实例时,则比较字符串内容是否相同.相同则返回true, 不相同返回false. ==
2.test.name.equals(testB.name) 字符串内容相同,返回true.
3.test.name == testB.name, 栈中有一块内存存的是"abc", test.name和testB.name都指向这块内存,所以返回true,更具体还可以看一篇文章将java中String搞懂、搞透当中的介绍.
综上,程序输出是false,true,true. 本题的正确答案则是ABC
134 关于AOP错误的是?©
AOP将散落在系统中的“方面”代码集中实现
AOP有助于提高系统可维护性
AOP已经表现出将要替代面向对象的趋势
AOP是一种设计模式,Spring提供了一种实现
AOP和OOP都是一套方法论,也可以说成设计模式、思维方式、理论规则等等。
AOP不能替代OOP,OOP是obejct abstraction,而AOP是concern abstraction,前者主要是对对象的抽象,诸如抽象出某类业务对象的公用接口、报表业务对象的逻辑封装,更注重于某些共同对象共有行为的抽象,如报表模块中专门需要报表业务逻辑的封装,其他模块中需要其他的逻辑抽象 ,而AOP则是对分散在各个模块中的共同行为的抽象,即关注点抽象。一些系统级的问题或者思考起来总与业务无关又多处存在的功能,可使用AOP,如异常信息处理机制统一将自定义的异常信息写入响应流进而到前台展示、行为日志记录用户操作过的方法等,这些东西用OOP来做,就是一个良好的接口、各处调用,但有时候会发现太多模块调用的逻辑大都一致、并且与核心业务无大关系,可以独立开来,让处理核心业务的人专注于核心业务的处理,关注分离了,自然代码更独立、更易调试分析、更具好维护。
核心业务还是要OOP来发挥作用,与AOP的侧重点不一样,前者有种纵向抽象的感觉,后者则是横向抽象的感觉, AOP只是OOP的补充,无替代关系。
AOP 和 OOP的区别:
- 面向方面编程 AOP 偏重业务处理过程的某个步骤或阶段,强调降低模块之间的耦合度,使代码拥有更好的移植性。
- 面向对象编程 (oop) 则是对业务分析中抽取的实体进行方法和属性的封装。
也可以说 AOP 是面向业务中的动词领域, OOP 面向名词领域。
AOP 的一个很重要的特点是源代码无关性,也就是说如果我们的系统中引用了 AOP 组件,即使我们把该组件去掉,系统代码也应该能够编译通过。要实现这一点,可以使用动态 proxy 模式。
AOP的概念是Aspected Oriented Programming 面向方面编程。
好处:AOP将程序分解成各个方面或者说关注点。这使得可以模块化,相当横向上分切了。它可以解决OOP和过程化方法不能够很好解决的横切(crosscut)问题,如:事务、安全、日志等横切关注
实现AOP有几种方式:
-
Spring 1.2版本中通过ProxyFactoryBean来实现aop,即通过动态***来实现的,Aspect必须继承MethodBeforeAdvice,MethodAfterAdvice等
-
Spring 2.0 AOP需要改的是FBI 这个类,而且它也不需要再实现某些接口
-
三使用标注(@AspectJ)实现AOP
135 以下代码的循环次数是(D)
public class Test {
public static void main(String args[]) {
int i = 7;
do {
System.out.println(--i);
--i;
} while (i != 0);
System.out.println(i);
}
}
0
1
7
无限次
每次循环都是减二,i一直不为0,所以循环为无限执行
136 假设num已经被创建为一个ArrayList对象,并且最初包含以下整数值:[0,0,4,2,5,0,3,0]。 执行下面的方法numQuest(),最终的输出结果是什么?(D)
private List<Integer> nums;
//precondition: nums.size() > 0
//nums contains Integer objects
public void numQuest() {
int k = 0;
Integer zero = new Integer(0);
while (k < nums.size()) {
if (nums.get(k).equals(zero))
nums.remove(k);
k++;
}
}
[3, 5, 2, 4, 0, 0, 0, 0]
[0, 0, 0, 0, 4, 2, 5, 3]
[0, 0, 4, 2, 5, 0, 3, 0]
[0, 4, 2, 5, 3]

结果中数组的第一个元素 0 是 原数组中的第二个0。
这个程序就是在删除数组中的0 ,但是会有个小问题,就是连续的0会只删除一个。
原因:当执行remove的时候,ArrayList 数组的 size 会变小一个,原本的位置上的 0 会被后面的 0 给替代;而在执行完remove后执行了k++;所以跳过了第二个0
关键在于 每次remove 之后 数组的长度会-1 但是获取数据的下标会+1
137 下列关于修饰符混用的说法,错误的是( D)
abstract不能与final并列修饰同一个类
abstract类中不应该有private的成员
abstract方法必须在abstract类或接口中
static方法中能直接调用类里的非static的属性
解释:
A、使用抽象类基本就是为了被继承使用,使用final类就是为了不被继承,比如String类(故A正确)
B、abstract类不应该有private成员,这也是合理的,抽象类存在的目的基础都是为了被继承提供给外部使用,而被private修饰过的,
表示只能在本类的范围内使用,也就是仅仅提供给内部使用,这基本就违反了抽象类的“用法”(故B正确)
C、抽象方法,不是在抽象类里就是在接口里,没有第三方选择!(除非Java以后额外提供)(故C正确)
D、从排除法来看,D是绝对错误的,但还是要解释下,静态方法不能“直接”调用非静态属性,注意,D答案是直接,并没有说“可以”,
换句话说是这样的:
static方法中能“直接”调用类里的非静态属性
static方法中“可以”调用类里的非静态属性 上面这两句是完全不一样的意思:
“直接”:表示直接用属性也就是变量名。
“可以”:表示可以new一个实例出来,在调用也是没有问题的。(故D错误)
138 请问所有的异常类皆直接继承于哪一个类?(C)
java.applet.Applet
java.lang.Throwable
java.lang.Exception
java.lang.Error
题目中问的是直接继承,Throwable是总基类!

139 volatile关键字的说法错误的是(A)
能保证线程安全
volatile关键字用在多线程同步中,可保证读取的可见性
JVM保证从主内存加载到线程工作内存的值是最新的
volatile能禁止进行指令重排序
出于运行速率的考虑,java编译器会把经常经常访问的变量放到缓存(严格讲应该是工作内存)中,读取变量则从缓存中读。但是在多线程编程中,内存中的值和缓存中的值可能会出现不一致。volatile用于限定变量只能从内存中读取,保证对所有线程而言,值都是一致的。但是volatile不能保证原子性,也就不能保证线程安全。
Java中的volatile关键字的功能
volatile是java中的一个类型修饰符。它是被设计用来修饰被不同线程访问和修改的变量。如果不加入volatile,基本上会导致这样的结果:要么无法编写多线程程序,要么编译器 失去大量优化的机会。
1,可见性
可见性指的是在一个线程中对该变量的修改会马上由工作内存(Work Memory)写回主内存(Main Memory),所以会马上反应在其它线程的读取操作中。顺便一提,工作内存和主内存可以近似理解为实际电脑中的高速缓存和主存,工作内存是线程独享的,主存是线程共享的。
2,禁止指令重排序优化
禁止指令重排序优化。大家知道我们写的代码(尤其是多线程代码),由于编译器优化,在实际执行的时候可能与我们编写的顺序不同。编译器只保证程序执行结果与源代码相同,却不保证实际指令的顺序与源代码相同。这在单线程看起来没什么问题,然而一旦引入多线程,这种乱序就可能导致严重问题。volatile关键字就可以从语义上解决这个问题。
java的内存模型
java 内存模型规定了所有的变量都存储在主内存中,但是每个线程会有自己的工作内存,线程的工作内存保存了该线程中使用了的变量(从主内存中拷贝的),线程对变量的操作都必须在工作内存中进行,不同线程之间无法直接访问对方工作内存中的变量,线程间变量值从传递都要经过主内存完成
 什么是原子性
什么是原子性
一个操作是不可中断的,要么全部执行成功要么全部执行失败,比如银行转账
什么是可见性
当多个线程访问同一变量时,一个线程修改了这个变量的值,其他线程就能够立即看到修改的值
什么是有序性
程序执行的顺序按照代码的先后顺序执行
volatile到底做了什么
禁止了指令重排
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量值,这个新值对其他线程是立即可见的
不保证原子性(线程不安全
140 非抽象类实现接口后,必须实现接口中的所有抽象方法,除了abstract外,方法头必须完全一致.(错误)
实际上这道题考查的是两同两小一大原则:
方法名相同,参数类型相同
子类返回类型小于等于父类方法返回类型,
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限。
方法头指:修饰符+返回类型 +方法名(形参列表)
接口的访问权限:public,abstract
两同两小一大原则
返回值和参数列表相同
返回值类型小于等于父类的返回值类型
异常小于等于父类抛出异常
访问权限大于等于父类
141 下面有关java的引用类型,说法正确的有?(ABCD)
对于一个对象来说,只要有强引用的存在,它就会一直存在于内存中
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存
一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的空间
四种引用类型
JDK1.2 之前,一个对象只有“已被引用”和"未被引用"两种状态,这将无法描述某些特殊情况下的对象,比如,当内存充足时需要保留,而内存紧张时才需要被抛弃的一类对象。
所以在 JDK.1.2 之后,Java 对引用的概念进行了扩充,将引用分为了:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)4 种,这 4 种引用的强度依次减弱。
一,强引用
Object obj = new Object(); //只要obj还指向Object对象,Object对象就不会被回收 obj = null; //手动置null
只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了
二,软引用
软引用是用来描述一些非必需但仍有用的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。这种特性常常被用来实现缓存技术,比如网页缓存,图片缓存等。
在 JDK1.2 之后,用java.lang.ref.SoftReference类来表示软引用。
三,弱引用
弱引用的引用强度比软引用要更弱一些,无论内存是否足够,只要 JVM 开始进行垃圾回收,那些被弱引用关联的对象都会被回收。在 JDK1.2 之后,用 java.lang.ref.WeakReference 来表示弱引用。
四,虚引用
虚引用是最弱的一种引用关系,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,它随时可能会被回收,在 JDK1.2 之后,用 PhantomReference 类来表示,通过查看这个类的源码,发现它只有一个构造函数和一个 get() 方法,而且它的 get() 方法仅仅是返回一个null,也就是说将永远无法通过虚引用来获取对象,虚引用必须要和 ReferenceQueue 引用队列一起使用。
1、强引用:一个对象赋给一个引用就是强引用,比如new一个对象,一个对象被赋值一个对象。
2、软引用:用SoftReference类实现,一般不会轻易回收,只有内存不够才会回收。
3、弱引用:用WeekReference类实现,一旦垃圾回收已启动,就会回收。
4、虚引用:不能单独存在,必须和引用队列联合使用。主要作用是跟踪对象被回收的状态。
142 下列程序test 类中的变量c 的最后结果为(D)
public class Test {
public static void main(String args[]) {
int a = 10;
int b;
int c;
if (a > 50) {
b = 9;
}
c = b + a;
}
}
10
0
19
编译出错
解释:
==方法内定义的变量没有初始值,必须要进行初始化。 类中定义的变量可以不需要赋予初始值,默认初始值为0。 ==方法中定义的变量一定要初始化,类中定义的变量可不用初始化,会有默认值
143 下面关于垃圾收集的说法正确的是(D)
一旦一个对象成为垃圾,就立刻被收集掉。
对象空间被收集掉之后,会执行该对象的finalize方法
finalize方法和C++的析构函数是完全一回事情
一个对象成为垃圾是因为不再有引用指着它,但是线程并非如此
1、在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行。
2、一旦垃圾回收器准备好释放对象占用的存储空间,将首先调用其finalize()方法, 并且在下一次垃圾回收动作发生时,才会真正的回收对象占用的内存(《java 编程思想》)
3、在C++中,对象的内存在哪个时刻被回收,是可以确定的,在C++中,析构函数和资源的释放息息相关,能不能正确处理析构函数,关乎能否正确回收对象内存资源。
在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行,在java中,所有的对象,包括对象中包含的其他对象,它们所占的内存的回收都依靠垃圾回收器,因此不需要一个函数如C++析构函数那样来做必要的垃圾回收工作。当然存在本地方法时需要finalize()方法来清理本地对象。在《java编程思想》中提及,finalize()方法的一个作用是用来回收“本地方法”中的本地对象
对象空间被收集前执行finalize()方法,而不是对象空间被收集之后再执行,如果这样的话执行finalize()就没有意义了。
144 what is the result of the following code? (C)
Compiles fine and output is prints”It is a account type”once followed by”FIXED”
Compiles fine and output is prints”It is a account type”twice followed by”FIXED”
Compiles fine and output is prints”It is a account type”thrice followed by”FIXED”
Compiles fine and output is prints”It is a account type”four times followed by”FIXED”
Compilation fails
枚举类有三个实例,故调用三次构造方法,打印三次It is a account type
枚举类 所有的枚举值都是类静态常量,在初始化时会对所有的枚举值对象进行第一次初始化。
枚举类在后台实现时,实际上是转化为一个继承了java.lang.Enum类的实体类,原先的枚举类型变成对应的实体类型,上例中AccountType变成了个class AccountType,并且会生成一个新的构造函数,若原来有构造函数,则在此基础上添加两个参数,生成新的构造函数,如上例子中:
private AccountType(){ System.out.println(“It is a account type”); } `
private AccountType(){ System.out.println(“It is a account type”); }
会变成:
private AccountType(String s, int i){
super(s,i); System.out.println(“It is a account type”); }
private AccountType(String s, int i){
super(s,i); System.out.println(“It is a account type”); }
而在这个类中,会添加若干字段来代表具体的枚举类型:
public static final AccountType SAVING;
public static final AccountType FIXED;
public static final AccountType CURRENT;
而且还会添加一段static代码段:
static{
SAVING = new AccountType("SAVING", 0);
... CURRENT = new AccountType("CURRENT", 0);
$VALUES = new AccountType[]{
SAVING, FIXED, CURRENT
} }
以此来初始化枚举中的每个具体类型。(并将所有具体类型放到一个$VALUE数组中,以便用序号访问具体类型)
在初始化过程中new AccountType构造函数被调用了三次,所以Enum中定义的构造函数中的打印代码被执行了3遍。
145 consider the following code:String s=null;Which code fragments cause an object of type NullPointerException to be thrown? (AC)
if((s!=null)&(s.length()>0))
if((s!=null)&&(s.length()>0))
if((s==null)|(s.length()==0))
if((s==null)||(s.length()==0))
== String为引用类型,如果对象为null,也就是说这个对象都不存在了,再去调用对象的相关方法,肯定会报空指针异常。这里调用了String类的length()方法==
&&和||具有短路的效果,在进行&&时,如果&&前的是false,那么&&后的不再执行,直接返回false,同理||也一样。所以BD的s.length()不会被执行,AC会抛出空指针异常.
146 在Java线程状态转换时,下列转换不可能发生的有(AC)?
初始态->运行态
就绪态->运行态
阻塞态->运行态
运行态->就绪态
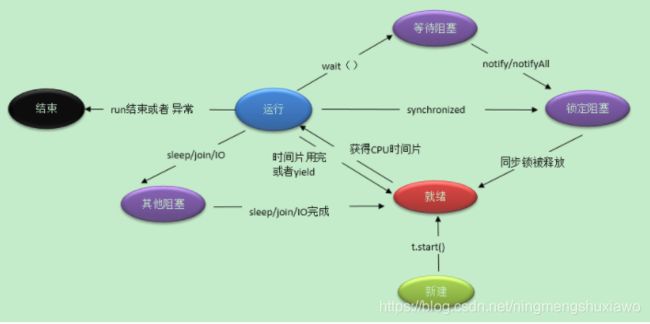
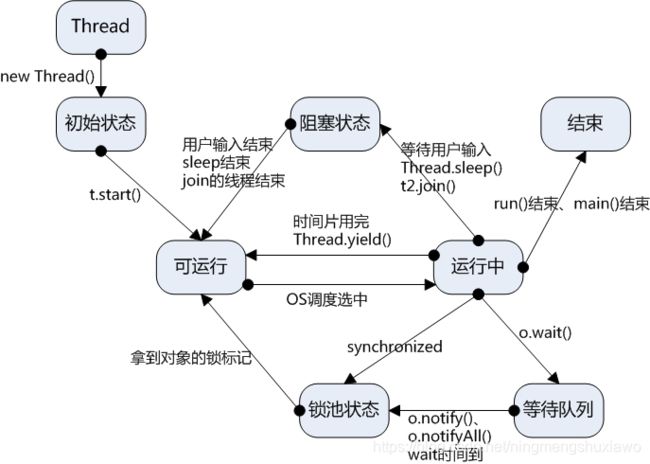
wait()、sleep()、yield()的理解
1)wait()是Object的实例方法,在synchronized同步环境使用,作用当前对象,会释放对象锁,需要被唤醒。
2)sleep()是Thread的静态方法,不用在同步环境使用,作用当前线程,不释放锁。
3)yield()是Thread的静态方法,作用当前线程,释放当前线程持有的CPU资源,将CPU让给优先级不低于自己的线程用,调用后进入就绪状态。
147 JSP分页代码中,哪个步骤次序是正确的?(A)
先取总记录数,得到总页数,最后显示本页的数据。
先取所有的记录,得到总页数,再取总记录数,最后显示本页的数据。
先取总页数,得到总记录数,再取所有的记录,最后显示本页的数据。
先取本页的数据,得到总页数,再取总记录数,最后显示所有的记录。
148 以下程序段执行后将有()个字节被写入到文件afile.txt中。 (C)
try {
FileOutputStream fos = new FileOutputStream("afile.txt");
DataOutputStream dos = new DataOutputStream(fos);
dos.writeInt(3);
dos.writeChar(1);
dos.close();
fos.close();
} catch (IOException e) {}
3
5
6
不确定,与软硬件环境相关
java采用的uincode编码,两个字节表示一个字符,因此 char型在java中占两个字节,而int型占四个字节,故总共占四个字节
byte 1个字节
short 2个字节
int 4个字节
long 8个字节
float 4个字节
double 8个字节
char 2个字节
boolean 1个字节或4个字节,在java规范2中,如果boolean用于声明一个基本类型变量时占4个字节,如果声明一个数组类型的时候,那么数组中的每个元素占1个字节
149 java中提供了哪两种用于多态的机制(AB)
通过子类对父类方法的覆盖实现多态
利用重载来实现多态.即在同一个类中定义多个同名的不同方法来实现多态。
利用覆盖来实现多态.即在同一个类中定义多个同名的不同方法来实现多态。
通过子类对父类方法的重载实现多态
Java通过方法重写和方法重载实现多态
方法重写是指子类重写了父类的同名方法
方法重载是指在同一个类中,方法的名字相同,但是参数列表不同
多态分为 编译时多态 和 运行时多态 。其中 编辑时多态是静态的 , 主要是指方法的重载 ,它是根据参数列表的不同来区分不同的函数,通过编辑之后会变成两个不同的函数,在运行时谈不上多态。而 运行时多态是动态的 ,它是 通过动态绑定来实现的 ,也就是我们所说的多态性(要有继承关系 2.子类要重写父类的方法 3.父类引用指向子类)
150 下列哪些情况下会导致线程中断或停止运行( AB )
InterruptedException异常被捕获
线程调用了wait方法
当前线程创建了一个新的线程
高优先级线程进入就绪状态
A选项正确,Java中一般通过interrupt方法中断线程
B选项正确,线程使用了wait方法,会强行打断当前操作,进入阻塞(暂停)状态,然后需要notify方法或notifyAll方法才能进入就绪状态
C选项错误,新创建的线程不会抢占时间片,只有等当前线程把时间片用完,其他线程才有资格拿到时间片去执行。
D选项错误,调度算法未必是剥夺式的,而准备就绪但是还没有获得CPU,它的权限更高只能说明它获得CPU被执行的几率更大而已