【NLP】理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等

LLaMA 2.0是 Meta AI 的开创性作品,作为首批高性能开源预训练语言模型之一闯入了 AI 场景。值得注意的是,LLaMA-13B 的性能优于巨大的 GPT-3(175B),尽管其尺寸只是其一小部分。您无疑听说过 LLaMA 令人印象深刻的性能,但您是否想知道是什么让它如此强大? 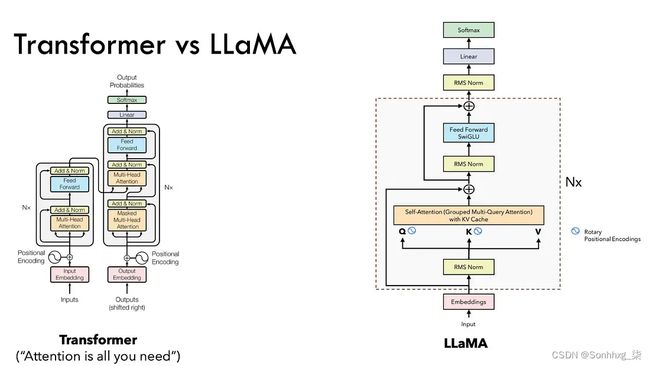
图 1:原始 Transformer 和 LLama 之间的架构差异
检查图 1 揭示了从原始 Transformer 到突破性的 LLaMA 架构的深刻转变。LLaMA 2.0 牢固地植根于 Transformer 框架的基础,但它引入了独特的创新——SwiGLU激活函数、旋转位置嵌入、均方根层归一化和键值缓存。在这篇博客中,我们将揭开 LLaMA 成功背后的秘密,并带您踏上实践之旅,从头开始编写新架构。
快速开始
要立即采取行动,我们的第一步是安装必要的库并导入所需的包。为了快速上手,我将首先从 Hugging Face下载一个紧凑的数据集,为我们提供一组文本句子。这些句子将使用“ daryl149/llama-2–7b-chat-hf ”中的预构建标记器转换为标记,该标记器与 LLaMA 预训练期间使用的标记器完全相同。
!pip install transformers datasets SentencePieceimport random
import math
import numpy as np
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from torch.utils.data.dataloader import DataLoader
from transformers import LlamaTokenizer
from datasets import load_dataset该代码库作为运行推理的简明示例,并强调了LLaMA 2.0 架构引入的范式转变。对于为微调量身定制的全面实现。在此演示中,我们将从数据集中获取一批随机数据,无需构建pytorch DataLoader,因为我们不会在这里训练模型。
model_id = "daryl149/llama-2-7b-chat-hf"
tokenizer = LlamaTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
config = {
'vocab_size': tokenizer.vocab_size,
'n_layers': 1,
'embed_dim': 2048,
'n_heads': 32,
'n_kv_heads': 8,
'multiple_of': 64,
'ffn_dim_multiplier': None,
'norm_eps': 1e-5,
'max_batch_size': 16,
'max_seq_len': 64,
'device': 'cuda',
}
dataset = load_dataset('glue', 'ax', split='test')
dataset = dataset.select_columns(['premise', 'hypothesis'])
test_set = tokenizer(
random.sample(dataset['premise'], config['max_batch_size']),
truncation=True,
max_length=config['max_seq_len'],
padding='max_length',
return_tensors='pt'
)旋转位置嵌入
LLaMA2 的基本进步之一是采用旋转位置嵌入 (RoPE)代替传统的绝对位置编码。RoPE 的与众不同之处在于它能够将显式相对位置依赖性无缝集成到模型的自注意力机制中。这种动态方法具有几个关键优势:
- 序列长度的灵活性:传统的位置嵌入通常需要定义最大序列长度,限制了它们的适应性。另一方面,RoPE 非常灵活。它可以为任意长度的序列即时生成位置嵌入。
- 减少代币间的依赖关系:RoPE 在对代币之间的关系进行建模方面非常聪明。随着令牌在序列中彼此距离越来越远,RoPE 自然会减少它们之间的令牌依赖性。这种逐渐衰退与人类理解语言的方式更加一致,早期单词的重要性往往会减弱。
- 增强的自注意力:RoPE 为线性自注意力机制配备了相对位置编码,这是传统绝对位置编码中不存在的功能。此增强功能允许更精确地利用令牌嵌入。
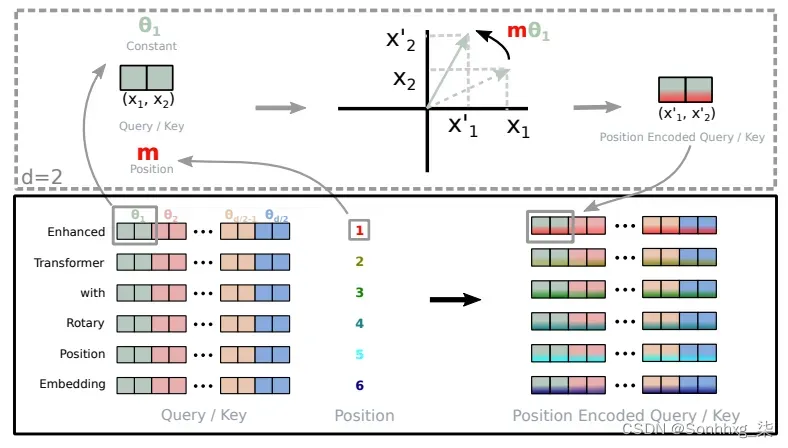
旋转嵌入的实现(取自Roformer)
传统的绝对位置编码类似于指定单词出现在位置 3、5 或 7,而与上下文无关。相比之下,RoPE 让模型了解单词之间是如何相互关联的。它认识到单词 A 经常出现在单词 B 之后和单词 C 之前。这种动态理解增强了模型的性能。
def precompute_theta_pos_frequencies(head_dim, seq_len, device, theta=10000.0):
# theta_i = 10000^(-2(i-1)/dim) for i = [1, 2, ... dim/2]
# (head_dim / 2)
theta_numerator = torch.arange(0, head_dim, 2).float()
theta = 1.0 / (theta ** (theta_numerator / head_dim)).to(device)
# (seq_len)
m = torch.arange(seq_len, device=device)
# (seq_len, head_dim / 2)
freqs = torch.outer(m, theta).float()
# complex numbers in polar, c = R * exp(m * theta), where R = 1:
# (seq_len, head_dim/2)
freqs_complex = torch.polar(torch.ones_like(freqs), freqs)
return freqs_complex
def apply_rotary_embeddings(x, freqs_complex, device):
# last dimension pairs of two values represent real and imaginary
# two consecutive values will become a single complex number
# (m, seq_len, num_heads, head_dim/2, 2)
x = x.float().reshape(*x.shape[:-1], -1, 2)
# (m, seq_len, num_heads, head_dim/2)
x_complex = torch.view_as_complex(x)
# (seq_len, head_dim/2) --> (1, seq_len, 1, head_dim/2)
freqs_complex = freqs_complex.unsqueeze(0).unsqueeze(2)
# multiply each complex number
# (m, seq_len, n_heads, head_dim/2)
x_rotated = x_complex * freqs_complex
# convert back to the real number
# (m, seq_len, n_heads, head_dim/2, 2)
x_out = torch.view_as_real(x_rotated)
# (m, seq_len, n_heads, head_dim)
x_out = x_out.reshape(*x.shape)
return x_out.type_as(x).to(device)让我们分解旋转位置嵌入 (RoPE) 的代码以了解它是如何实现的。
precompute_theta_pos_frequencies函数计算RoPE 的特殊值。首先定义一个名为 的超参数theta,控制旋转的幅度。较小的值会产生较小的旋转。然后,它使用计算一组旋转角度theta。该函数还创建序列中的位置列表,并通过获取位置列表和旋转角度的外积来计算每个位置应旋转的程度。最后,它将这些值转换为具有固定大小的极坐标形式的复数,这就像表示位置和旋转的密码。apply_rotary_embeddings函数采用数值并用旋转信息增强它们。它首先将输入值的最后一个维度分成代表实部和虚部的对。然后将这些对组合成单个复数。接下来,该函数将预先计算的复数与输入相乘,从而有效地应用旋转。最后,它将结果转换回实数并重塑数据,为进一步处理做好准备。
均方根标准值
Llama2采用均方根层归一化(RMSNorm),通过替换现有的层归一化(LayerNorm)来增强变压器架构。LayerNorm 有利于提高训练稳定性和模型收敛性,因为它重新居中并重新缩放输入和权重矩阵值。然而,这种改进是以计算开销为代价的,这会减慢网络速度。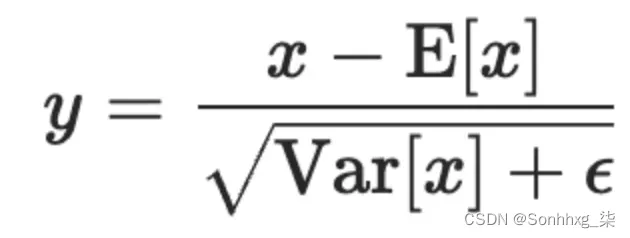
简化的 LayerNorm 公式:从输入中减去均值并除以标准差
另一方面,RMSNorm 保留了重新缩放不变性,同时简化了计算。它使用均方根 (RMS) 调节神经元的组合输入,提供隐式学习率自适应。这使得 RMSNorm 的计算效率比 LayerNorm 更高。
均方根归一化 (RMSNorm) 公式,其中 gi 是增益参数,用于重新缩放标准化求和输入
跨各种任务和网络架构的大量实验表明,RMSNorm 的性能与 LayerNorm 一样有效,同时将计算时间减少了 7% 至 64%。
class RMSNorm(nn.Module):
def __init__(self, dim, eps=1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x: torch.Tensor):
# (m, seq_len, dim) * (m, seq_len, 1) = (m, seq_len, dim)
# rsqrt: 1 / sqrt(x)
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x: torch.Tensor):
# weight is a gain parameter used to re-scale the standardized summed inputs
# (dim) * (m, seq_len, dim) = (m, seq_Len, dim)
return self.weight * self._norm(x.float()).type_as(x)该自定义脚本首先x通过将输入除以其均方根来标准化输入,从而使其对缩放变化保持不变。学习到的权重参数self.weight应用于标准化张量中的每个元素。此操作根据学习的缩放因子调整值的大小。
键值KV缓存
键值 (KV) 缓存是一种用于加速机器学习模型中的推理过程的技术,特别是在 GPT 和 Llama 等自回归模型中。在这些模型中,逐个生成令牌是一种常见做法,但计算成本可能很高,因为它在每一步都会重复某些计算。为了解决这个问题,KV 缓存就发挥了作用。它涉及缓存以前的 Keys 和 Values,因此我们不需要为每个新令牌重新计算它们。这显着减少了计算中使用的矩阵的大小,使矩阵乘法更快。唯一的代价是 KV 缓存需要更多的 GPU 内存(如果不使用 GPU,则需要 CPU 内存)来存储这些 Key 和 Value 状态。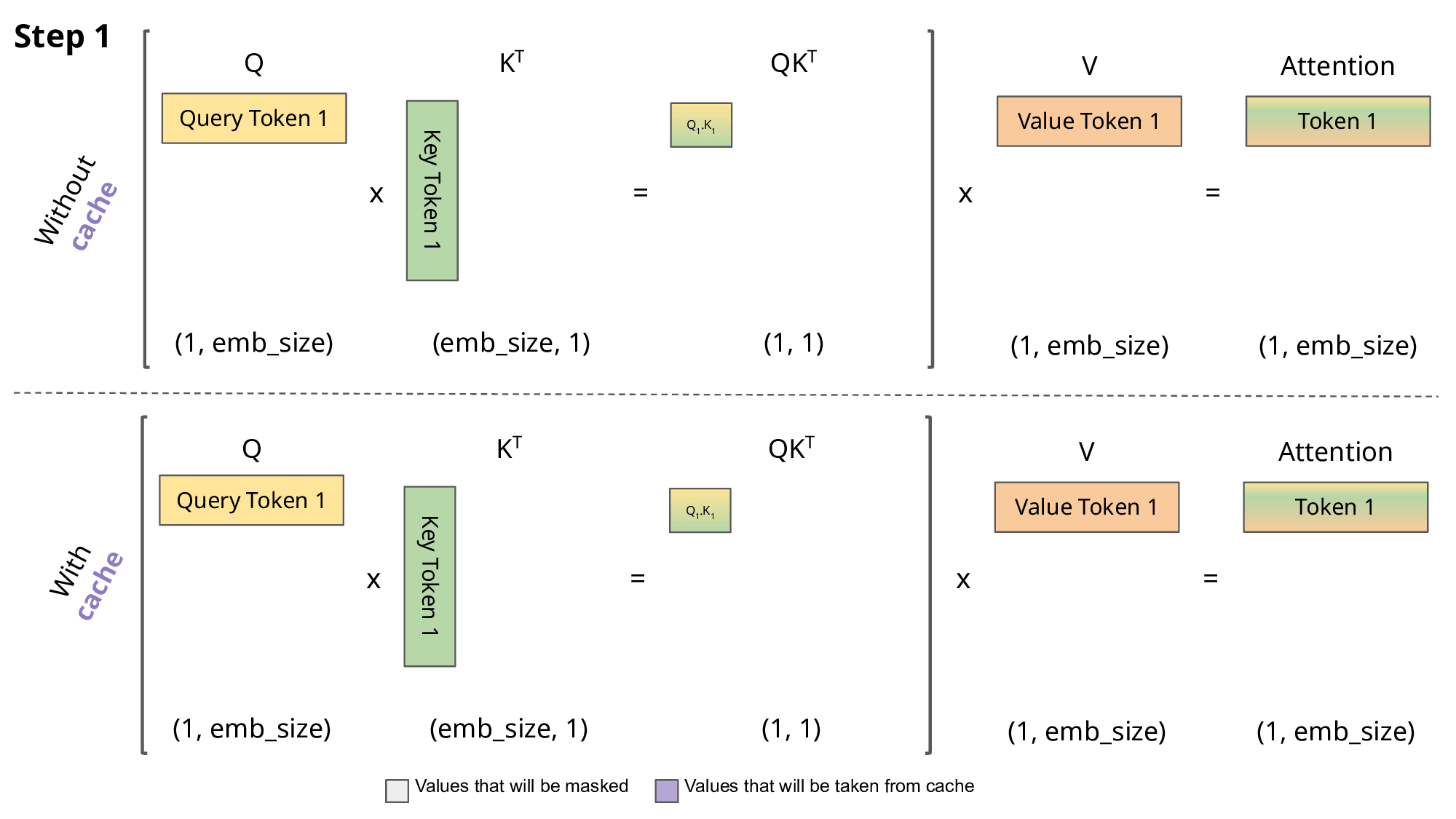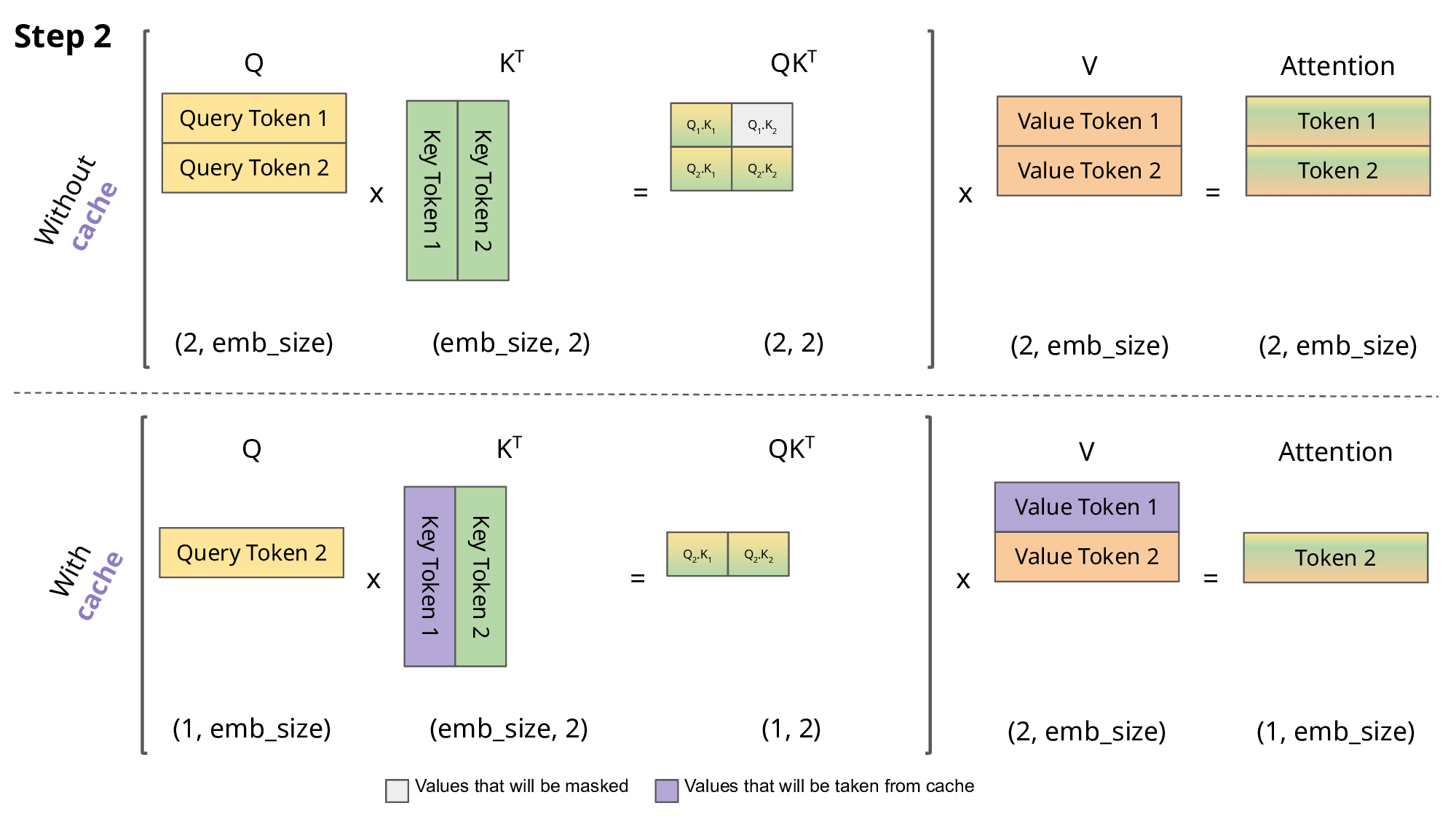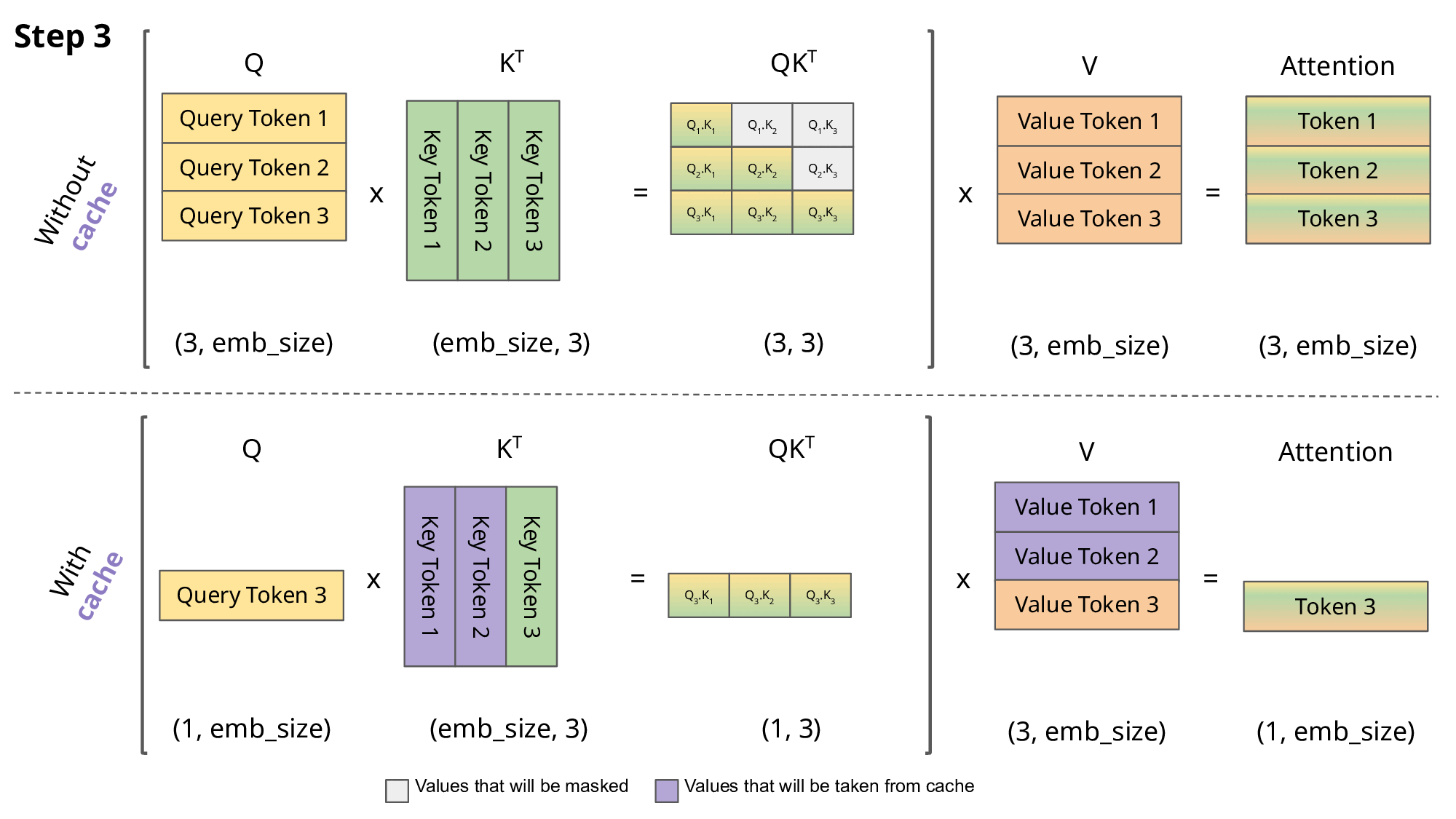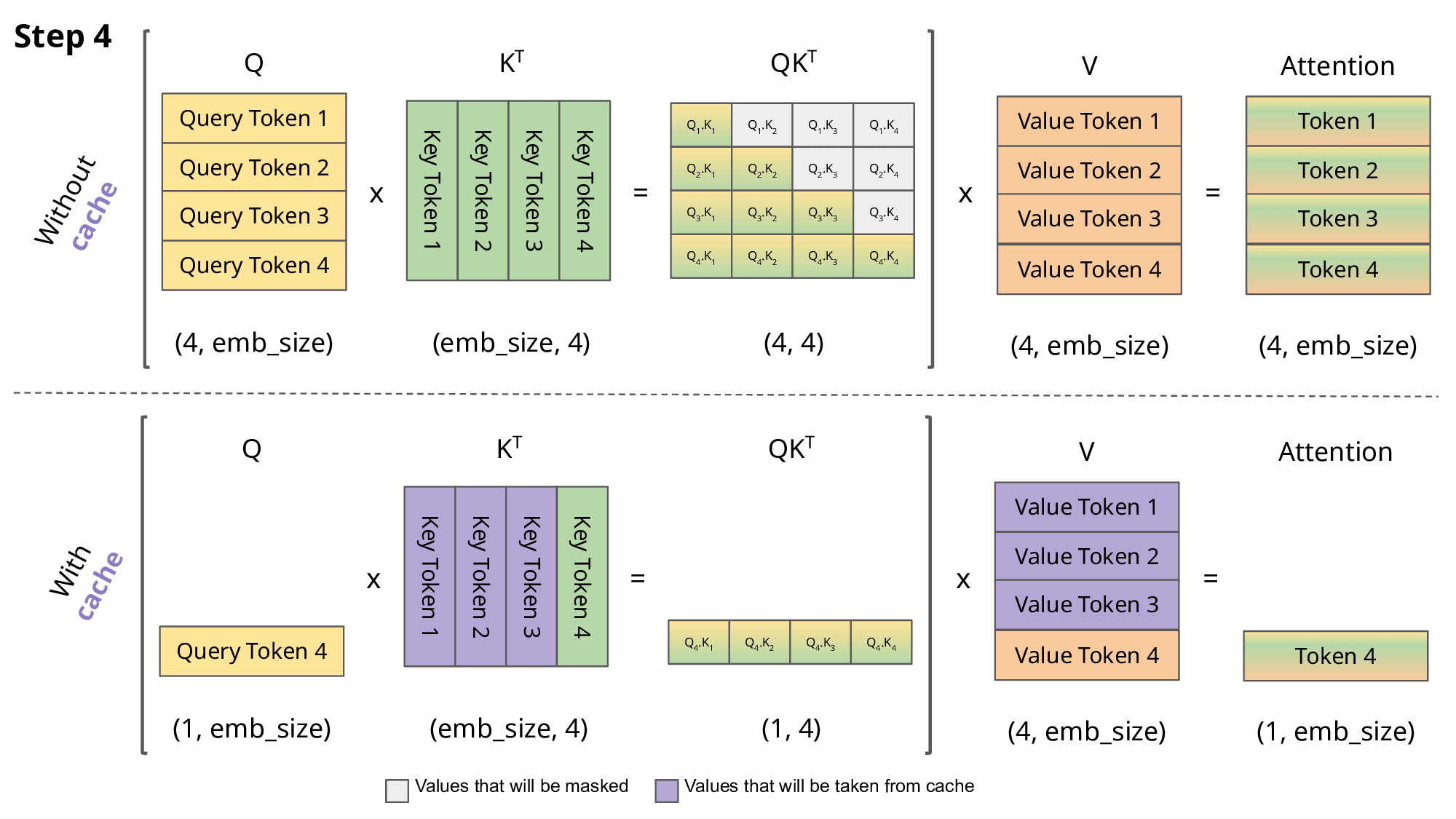
使用和不使用 KV 缓存的 Aattention
class KVCache:
def __init__(self, max_batch_size, max_seq_len, n_kv_heads, head_dim, device):
self.cache_k = torch.zeros((max_batch_size, max_seq_len, n_kv_heads, head_dim)).to(device)
self.cache_v = torch.zeros((max_batch_size, max_seq_len, n_kv_heads, head_dim)).to(device)
def update(self, batch_size, start_pos, xk, xv):
self.cache_k[:batch_size, start_pos :start_pos + xk.size(1)] = xk
self.cache_v[:batch_size, start_pos :start_pos + xv.size(1)] = xv
def get(self, batch_size, start_pos, seq_len):
keys = self.cache_k[:batch_size, :start_pos + seq_len]
values = self.cache_v[:batch_size, :start_pos + seq_len]
return keys, values在推理过程中,该过程一次对一个令牌进行操作,保持序列长度为 1。这意味着,对于 Key、Value 和 Query,线性层和旋转嵌入都专门针对特定位置的单个标记。Key 和 Value 的注意力权重被预先计算并存储为缓存,确保这些计算仅发生一次并且其结果被缓存。脚本get方法检索过去的 Key 和 Value 直到当前位置的注意力权重,将其长度扩展到 1 以上。在缩放点积运算期间,输出大小与查询大小匹配,这仅生成单个标记。
分组查询注意力
Llama 采用了一种称为分组查询注意力 (GQA) 的技术来解决Transformer 模型自回归解码期间的内存带宽挑战。主要问题源于需要在每个处理步骤加载解码器权重和注意键/值,这会消耗过多的内存。
作为回应,引入了两种策略:
- 多查询注意力(MQA)涉及利用具有单个键/值头的多个查询头,这可以加速解码器推理。但它也存在质量下降、训练不稳定等缺点。
- 分组查询注意力(GQA)是 MQA 的演变,通过使用中间数量的键值头(多于一个但少于查询头)来达到平衡。GQA 模型像
n_heads原始的多头注意力机制一样,有效地将查询分成片段,并且将键和值分为n_kv_heads组,使得多个键值头能够共享相同的查询。
通过重复键值对以提高计算效率,GQA 方法在保持质量的同时优化了性能,正如代码实现所证明的那样。
不同Attention Method概述
提供的代码用于使用 Transformer 模型在自回归解码器的上下文中实现分组查询注意 (GQA)。值得注意的是,在推理过程中,序列长度 (seq_len) 始终设置为 1。
def repeat_kv(x, n_rep):
batch_size, seq_len, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
else:
# (m, seq_len, n_kv_heads, 1, head_dim)
# --> (m, seq_len, n_kv_heads, n_rep, head_dim)
# --> (m, seq_len, n_kv_heads * n_rep, head_dim)
return (
x[:, :, :, None, :]
.expand(batch_size, seq_len, n_kv_heads, n_rep, head_dim)
.reshape(batch_size, seq_len, n_kv_heads * n_rep, head_dim)
)
class SelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.n_heads = config['n_heads']
self.n_kv_heads = config['n_kv_heads']
self.dim = config['embed_dim']
self.n_kv_heads = self.n_heads if self.n_kv_heads is None else self.n_kv_heads
self.n_heads_q = self.n_heads
self.n_rep = self.n_heads_q // self.n_kv_heads
self.head_dim = self.dim // self.n_heads
self.wq = nn.Linear(self.dim, self.n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(self.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wv = nn.Linear(self.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wo = nn.Linear(self.n_heads * self.head_dim, self.dim, bias=False)
self.cache = KVCache(
max_batch_size=config['max_batch_size'],
max_seq_len=config['max_seq_len'],
n_kv_heads=self.n_kv_heads,
head_dim=self.head_dim,
device=config['device']
)
def forward(self, x, start_pos, freqs_complex):
# seq_len is always 1 during inference
batch_size, seq_len, _ = x.shape
# (m, seq_len, dim)
xq = self.wq(x)
# (m, seq_len, h_kv * head_dim)
xk = self.wk(x)
xv = self.wv(x)
# (m, seq_len, n_heads, head_dim)
xq = xq.view(batch_size, seq_len, self.n_heads_q, self.head_dim)
# (m, seq_len, h_kv, head_dim)
xk = xk.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)
xv = xv.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)
# (m, seq_len, num_head, head_dim)
xq = apply_rotary_embeddings(xq, freqs_complex, device=x.device)
# (m, seq_len, h_kv, head_dim)
xk = apply_rotary_embeddings(xk, freqs_complex, device=x.device)
# replace the entry in the cache
self.cache.update(batch_size, start_pos, xk, xv)
# (m, seq_len, h_kv, head_dim)
keys, values = self.cache.get(batch_size, start_pos, seq_len)
# (m, seq_len, h_kv, head_dim) --> (m, seq_len, n_heads, head_dim)
keys = repeat_kv(keys, self.n_rep)
values = repeat_kv(values, self.n_rep)
# (m, n_heads, seq_len, head_dim)
# seq_len is 1 for xq during inference
xq = xq.transpose(1, 2)
# (m, n_heads, seq_len, head_dim)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
# (m, n_heads, seq_len_q, head_dim) @ (m, n_heads, head_dim, seq_len) -> (m, n_heads, seq_len_q, seq_len)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
# (m, n_heads, seq_len_q, seq_len)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
# (m, n_heads, seq_len_q, seq_len) @ (m, n_heads, seq_len, head_dim) -> (m, n_heads, seq_len_q, head_dim)
output = torch.matmul(scores, values)
# ((m, n_heads, seq_len_q, head_dim) -> (m, seq_len_q, dim)
output = (output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1))
# (m, seq_len_q, dim)
return self.wo(output)SelfAttention是一个结合了我们已经讨论过的机制的类。该类的关键组件如下:
- 线性变换应用于查询 (xq)、键 (xk) 和值 (xv) 的输入张量。这些转换将输入数据投影为适合处理的形式。
- 使用提供的频率复数将旋转嵌入应用于查询、键和值张量。此步骤增强了模型考虑位置信息和执行注意力计算的能力。
- 键值对(k 和 v)被缓存以有效使用内存。检索缓存的键值对,直到当前位置 (
start_pos + seq_len) - 通过重复键值对次数来准备查询、键和值张量以用于分组查询注意力
n_rep计算,其中n_rep对应于共享相同键值对的查询头的数量。 - 缩放点积注意力计算。注意力分数是通过查询和键的点积计算出来的,然后进行缩放。应用 Softmax 来获得最终的注意力分数。在计算过程中,输出大小与查询大小匹配,也是 1。
wo最后,该模块对输出应用线性变换( ),并返回处理后的输出。
SwiGlu
LLaMA2 模型中使用的 SwiGLU 是一种激活函数,旨在增强 Transformer 架构中位置前馈网络 (FFN) 层的性能。与其他激活函数相比,SwiGLU 的主要优点是:
- 平滑性:SwiGLU 比 ReLU 更平滑,可以带来更好的优化和更快的收敛。
- 非单调性:SwiGLU 是非单调的,这使得它能够捕获输入和输出之间复杂的非线性关系
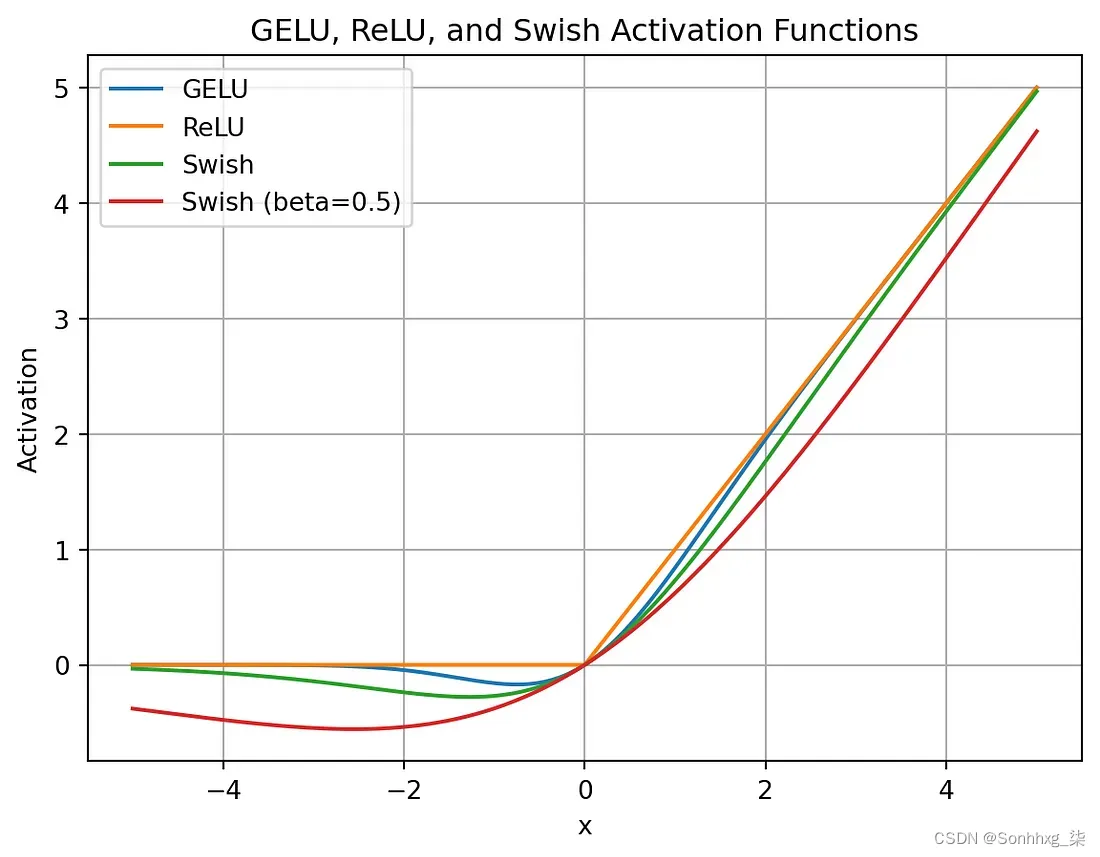
不同 GLU 激活的比较
def sigmoid(x, beta=1):
return 1 / (1 + torch.exp(-x * beta))
def swiglu(x, beta=1):
return x * sigmoid(x, beta)Feedforward
在 Transformer 架构中,前馈层起着至关重要的作用,通常位于注意力层和归一化层之后。前馈层由三个线性变换组成。
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
hidden_dim = 4 * config['embed_dim']
hidden_dim = int(2 * hidden_dim / 3)
if config['ffn_dim_multiplier'] is not None:
hidden_dim = int(config['ffn_dim_multiplier'] * hidden_dim)
# Round the hidden_dim to the nearest multiple of the multiple_of parameter
hidden_dim = config['multiple_of'] * ((hidden_dim + config['multiple_of'] - 1) // config['multiple_of'])
self.w1 = nn.Linear(config['embed_dim'], hidden_dim, bias=False)
self.w2 = nn.Linear(config['embed_dim'], hidden_dim, bias=False)
self.w3 = nn.Linear(hidden_dim, config['embed_dim'], bias=False)
def forward(self, x: torch.Tensor):
# (m, seq_len, dim) --> (m, seq_len, hidden_dim)
swish = swiglu(self.w1(x))
# (m, seq_len, dim) --> (m, seq_len, hidden_dim)
x_V = self.w2(x)
# (m, seq_len, hidden_dim)
x = swish * x_V
# (m, seq_len, hidden_dim) --> (m, seq_len, dim)
return self.w3(x)在前向传递过程中,输入张量x经历多层线性变换。第一次转换后应用的SwiGLU激活函数增强了模型的表达能力。最终的变换将张量映射回其原始维度。SwiGLU 激活和多个前馈层的这种独特组合增强了模型的性能。
最终Transformer模型
Llama2 的最终巅峰是一个强大的Transformer模型,汇集了我们迄今为止讨论的一系列先进技术。DecoderBlock 是该模型的基本构建块,它结合了 KV 缓存、分组查询注意力、SwiGLU 激活和旋转嵌入的知识,创建了一个高效且有效的解决方案。
class DecoderBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.n_heads = config['n_heads']
self.dim = config['embed_dim']
self.head_dim = self.dim // self.n_heads
self.attention = SelfAttention(config)
self.feed_forward = FeedForward(config)
# rms before attention block
self.attention_norm = RMSNorm(self.dim, eps=config['norm_eps'])
# rms before feed forward block
self.ffn_norm = RMSNorm(self.dim, eps=config['norm_eps'])
def forward(self, x, start_pos, freqs_complex):
# (m, seq_len, dim)
h = x + self.attention.forward(
self.attention_norm(x), start_pos, freqs_complex)
# (m, seq_len, dim)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Transformer(nn.Module):
def __init__(self, config):
super().__init__()
self.vocab_size = config['vocab_size']
self.n_layers = config['n_layers']
self.tok_embeddings = nn.Embedding(self.vocab_size, config['embed_dim'])
self.head_dim = config['embed_dim'] // config['n_heads']
self.layers = nn.ModuleList()
for layer_id in range(config['n_layers']):
self.layers.append(DecoderBlock(config))
self.norm = RMSNorm(config['embed_dim'], eps=config['norm_eps'])
self.output = nn.Linear(config['embed_dim'], self.vocab_size, bias=False)
self.freqs_complex = precompute_theta_pos_frequencies(
self.head_dim, config['max_seq_len'] * 2, device=(config['device']))
def forward(self, tokens, start_pos):
# (m, seq_len)
batch_size, seq_len = tokens.shape
# (m, seq_len) -> (m, seq_len, embed_dim)
h = self.tok_embeddings(tokens)
# (seq_len, (embed_dim/n_heads)/2]
freqs_complex = self.freqs_complex[start_pos:start_pos + seq_len]
# Consecutively apply all the encoder layers
# (m, seq_len, dim)
for layer in self.layers:
h = layer(h, start_pos, freqs_complex)
h = self.norm(h)
# (m, seq_len, vocab_size)
output = self.output(h).float()
return output
model = Transformer(config).to(config['device'])
res = model.forward(test_set['input_ids'].to(config['device']), 0)
print(res.size())Transformer 模型包含一堆DecoderBlock,以创建强大且高效的深度学习架构。随附的代码展示了DecoderBlock及其SelfAttention、FeedForward和RMSNorm层如何有效处理数据。该代码还强调了更大的 Transformer 架构的结构,包括令牌嵌入、层堆叠和输出生成。此外,预计算频率和先进技术的使用,与定制配置相结合,确保了模型在各种自然语言理解任务中的卓越性能和多功能性。
结论
在这次全面了解 Llama2 Transformers 先进技术的旅程中,我们深入研究了理论和复杂的代码实现。然而,值得注意的是,我们讨论的代码主要不是用于训练或生产用途,而是更多地作为 Llama 卓越推理能力的演示和展示。它强调了如何在现实世界中应用这些先进技术,并展示了 Llama2 在增强各种自然语言理解任务方面的潜力。