07-hive--高级部分1
一、 序列化与反序列化
1)什么时候需要序列化
只要碰到需要将对象存入硬盘或者需要在网络进行传输时,必须序列化。对象可以想象为活物。
1、Java的序列化(implements Serializable)。
2、MapReduce :Hadoop抛弃了Java的序列化方式,自己创建了一套序列化,implements Writable,原因:Java序列化出来的文件太大了,包含了太多信息。
3、Hive 比如select * from t_user ; --> 查询就是硬盘的数据变为控制台输出的数据,这个过程是反序列化的。
假如 insert into t_user values(1,"张三") ; --> 将一个对象变为了一个hdfs上的数据 ,这个过程是序列化。
- select过程
读取磁盘上的数据,创建row对象,这种从磁盘读取文件并转换为对象的过程称之为反序列化,底层用到了InputFormat。
- insert过程
将内存中的row对象,存储为磁盘上的数据,这个过程是序列化的过程,底层用到了OutputFormat。
2)如何序列化
序列化与反序列化需要用到分隔符,用好分隔符,序列化和反序列化就很容易。
序列化过程:
1|张三|20 解析分隔符 | --> Row对象 --> Hive --> HDFS 对象序列化
具体来讲:就是依据serDe这个工具包
- SerDe是“Serializer and Deserializer”的简称。
- Hive使用SerDe(和FileFormat)来读/写表的Row对象。
- HDFS文件-> InputFileFormat ->
-> Deserializer -> Row对象 - Row对象->Serializer ->
-> OutputFileFormat -> HDFS文件
SerDe:
分隔符:
l csv: 逗号分隔值
l tsv: tab分隔值
l json: json格式的数据 --在mr中,看见json数据,使用工具类解析 fastjson,jackson,gson等
l regexp: 数据需要复合正则表达式
默认列分隔符:^A 或 \001 行分隔符:\n
^A的的八进制体现 \001
每一个分隔符都对应serde工具包的一个类 ^A -->LazySimpleSerDe
ps:在Linux中,^A不能直接打出来,打出来是没有效果的,在vi编辑器下的insert模式使用ctrl+v打出^,使用ctrl+a打出A
练习:默认分隔符
制造数据:
csv1.txt:
1001^Azs^A23
1002^Alisi^A24
此处不要copy,copy出来的^A不是正确的,认真看注意事项中的文字

建表
create table if not exists csv1(
uid int,
uname string,
age int
);
-- 格式都没有指定,默认使用的就是LazySimpleSerde,记录分隔符是\n,列分隔符是^A
使用的默认分隔符,建表的时候不需要指定分隔符
加载数据:
load data local inpath '/home/hivedata/csv1.txt' overwrite into table csv1;查询结果,正常。
练习:使用逗号分隔符
制造数据:
1001,zs,23
1002,lisi,24
建表:
create table if not exists csv2(
uid int,
uname string,
age int
)row format delimited
fields terminated by ',';加载数据:
load data local inpath '/home/hivedata/csv2.txt' overwrite into table csv2;desc formatted csv2; 查看表结构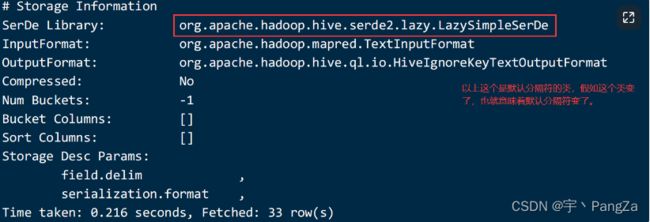
第二种建表语句:
create table if not exists csv2(
uid int,
uname string,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde';指定分隔符类: org.apache.hadoop.hive.serde2.OpenCSVSerde后就不用指明使用逗号分割了
OpenCSVSerde还可以自定义分隔符:
如下数据:使用数字7作为分隔符
10017zs723
10027lisi724
create table if not exists csv3(
uid int,
uname string,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties(
"separatorChar"="7"
);json serde:
1、理论
json serde 可以是自己写的jar包也可以是第三方的jar包,要把这种jar包添加到hive的class path中
2、实践
将jar包放置在/opt/modules文件夹下,然后在hive中执行如下命令:
add jar /opt/modules/json-serde-1.3.8-jar-with-dependencies.jar;

先有json数据:
{"uid":"1","uname":"gaoyuanyuan","age":"18"}
{"uid":"2","uname":"gaolaozhuang","age":"42"}
create table if not exists json1(
uid int,
uname string,
age int
)
row format serde 'org.openx.data.jsonserde.JsonSerDe';创建表时指定第三方类org.openx.data.jsonserde.JsonSerDe
正常加载数据即可。
第二个json解析的类,hive自带的:
'org.apache.hive.hcatalog.data.JsonSerDe'
新建表:
create table if not exists json2(
uid int,
uname string,
age int
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
导入数据:
load data local inpath '/home/hivedata/json1.txt' into table json2;
导入之后:查询 select * from json2;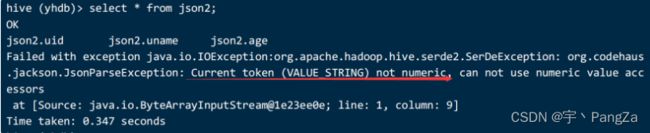
以上错误的意思是数据类型不匹配,表和数据的类型不匹配。
修改表的字段类型:
drop table json2;
create table if not exists json2(
uid string,
uname string,
age string
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';假如以上使用时报类找不到异常,需要指定hive中lib的位置,一般是不报错的。
json格式数据表需要通过serde机制处理
在/opt/installs/hive/conf 下 找到 hive-site.xml 修改里面的值
在hive-site.xml中设置三方jar包
hive.aux.jars.path
/opt/installs/hive/lib/
添加配置文件后还要重启metastore以及hive客户端。
4)复杂数据类型处理
数据如下所示:
json2.txt 中的数据如下:
zs math:100,98,76 chinese:98,96,100 english:100,99,90
ls math:60,80,70 chinese:90,66,91 english:50,51,70
思路是,将这个数据变为json(写java代码就可以)
{"uname":"zs","score":{"math":[100,98,76],"chinese":[98,96,100],"english":[100,99,90]}}
{"uname":"ls","score":{"math":[60,80,70],"chinese":[90,66,91],"english":[50,51,70]}}
建表:
create table if not exists complex(
uname string,
score map>
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile;
加载数据并查看是否正常解析:
load data local inpath '/home/hivedata/json2.txt' into table complex;
select * from complex; 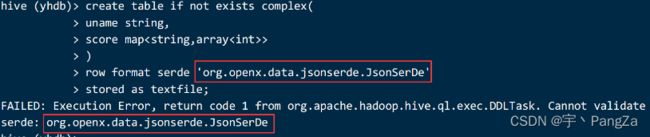
add jar /opt/modules/json-serde-1.3.8-jar-with-dependencies.jar;
一般将jar包上传至hdfs上,并且把这个语句添加到 .hiverc文件中
add jar hdfs:///lib/json-serde-1.3.8-jar-with-dependencies.jar;缺少jar包:为什么以前添加过了现在还要添加,原因是hive客户端关闭又开启,就需要重新添加

5) Regex Serde
数据准备:
01||zhangsan||23
02||lisi||24
create table if not exists t_regex(
id string,
uname string,
age int
)row format delimited
fields terminated by '||';
加载数据:
load data local inpath '/home/hivedata/regex.txt' into table t_regex;
hive (yhdb)> select * from t_regex;
OK
t_regex.id t_regex.uname t_regex.age
01 NULL
02 NULL
Time taken: 0.425 seconds, Fetched: 2 row(s)
发现解析是有问题的,只解析了一个 |
使用正则表达式解析:
drop table t_regex;
create table if not exists t_regex(
id string,
uname string,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
'input.regex'='(.*)\\|\\|(.*)\\|\\|(.*)',
'output.format.string'='%1$s %2$s %3$s'
)
stored as textfile;3、hive的存储格式
1) 四种存储格式
hive的存储格式分为两大类:一类纯文本文件,一类是二进制文件存储。
Hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET
第一类:纯文本文件存储
textfile: 纯文本文件存储格式,不压缩,也是hive的默认存储格式,磁盘开销大,数据解析开销大
第二类:二进制文件存储
- sequencefile:
会压缩,不能使用load方式加载数据
- parquet:
会压缩,不能使用load方式加载数据
- rcfile:
会压缩,不能load。查询性能高,写操作慢,所需内存大,计算量大。此格式为行列混合存储,hive在该格式下,会尽量将附近的行和列的块存储到一起。
- orcfile:rcfile的升级版。
2)列式存储和行式存储
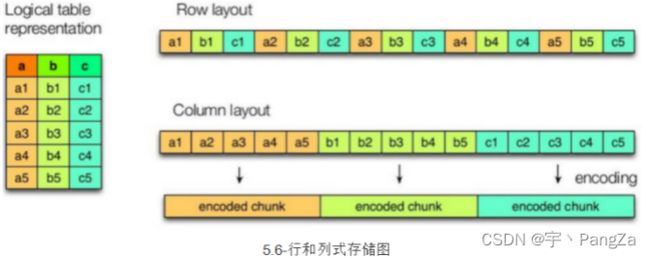
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;ORC和PARQUET是基于列式存储的。
行式存储:查找某一条整行数据比较快
列式存储:查找某个字段比较快 select name from user;
修改hive的默认存储格式:
hive.default.fileformat
TextFile
Expects one of [textfile, sequencefile, rcfile, orc].
Default file format for CREATE TABLE statement. Users can explicitly override it by CREATE TABLE ... STORED AS [FORMAT]
也可以使用set方式修改:
set hive.default.fileformat=TextFile3)实操一下:
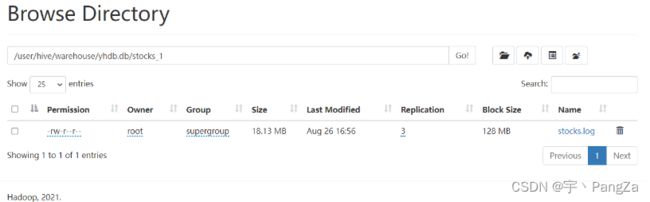
首先将一个18.1M的数据上传至 /home/hivedata/,这个文件叫做stocks.log
textfile类型演示:
create table stocks_1 (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/hivedata/stocks.log' into table stocks_1;
在linux的命令行上使用hdfs dfs -put方法去上传到指定目录下。可以查看到数据,说明是文本类型的。
sequencefile 的使用
create external table if not exists stocks_seq_1 (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as sequencefile;
由于不能load数据,从普通表中查询出来插入进入。
使用insert into的方式加载数据
insert into stocks_seq_1 select * from stocks_1 ;
或者使用克隆的方式:
create table stocks_seq_2 stored as sequencefile as select * from stocks_1;查看数据,是乱码,说明是二进制文件

parquetfile 类型
create external table if not exists stocks_parquet (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited
fields terminated by '\t'
stored as parquet;
使用insert into的方式加载数据
insert into stocks_parquet select * from stocks_1 ;
或者使用克隆的方式:
create table stocks_parquet_1 stored as parquet as select * from stocks_1;
rcfile类型:
create external table if not exists stocks_rcfile (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited
fields terminated by '\t'
stored as rcfile;
使用insert into的方式加载数据
insert into stocks_rcfile select * from stocks_1;
或者使用克隆的方式:
create table stocks_rcfile_2 stored as rcfile as select * from stocks_1;

orcfile类型:rcfile的升级版
create external table if not exists stocks_orcfile (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited
fields terminated by ','
stored as orcfile;
使用insert into的方式加载数据
insert into stocks_orcfile select * from stocks_1;
或者使用克隆的方式:
create table stocks_orcfile_2 stored as orcfile as select * from stocks_1;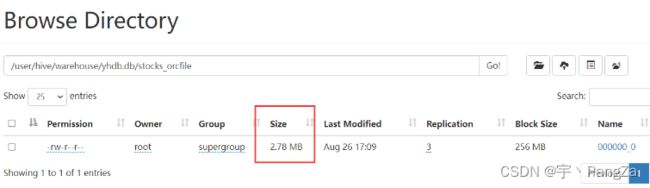

查询速度和压缩比例对比:
select count(*) from stocks_1;
select count(*) from stocks_seq_1;
select count(*) from stocks_parquet;
select count(*) from stocks_rcfile;
select count(*) from stocks_orcfile;
比较一下上述五个查询所需要的时间 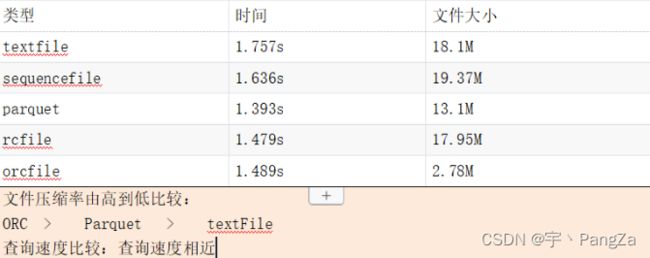
4、Hive的压缩【是优化手段之一】
hive的压缩使用的是工具压缩,跟存储格式自带压缩不是一回事儿。
HQL语句最终会被编译成Hadoop的Mapreduce job,因此hive的压缩设置,实际上就是对底层MR在处理数据时的压缩设置。
1)hive在map阶段压缩
map阶段的设置, 就是在MapReduce的shuffle阶段对mapper产生的中间结果数据压缩 。 在这个阶段,优先选择一个低CPU开销的算法。因为map阶段要将数据传递给reduce阶段,使用压缩可以提高传输效率。
hive-site.xml
hive.exec.compress.intermediate
false
hive.intermediate.compression.codec
hive.intermediate.compression.type
2)hive在reduce阶段的压缩
hive.exec.compress.output
false
注意:如果开启,默认使用中间压缩配置的压缩编码器和压缩类型3)常见的压缩类型

企业中一般使用snappy和lzo进行压缩。
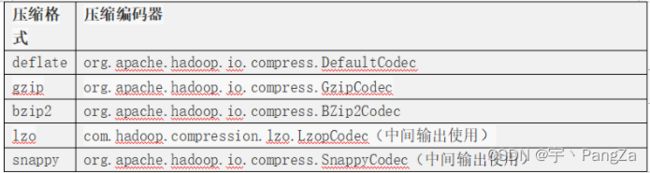
4)压缩编码器
5)实战一下
-- 开启中间压缩机制
hive (yhdb)> set hive.exec.compress.intermediate=true;
-- 设置中间压缩编码器
hive (yhdb)> set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.DefaultCodec;
-- 设置压缩类型
hive (yhdb)> set hive.intermediate.compression.type=RECORD;
-- 开启reduce端的压缩机制
hive (yhdb)> set hive.exec.compress.output=true;
-- 创建表
create external table if not exists stocks_seq_2 (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited
fields terminated by ','
stored as sequencefile;
--动态加载数据:
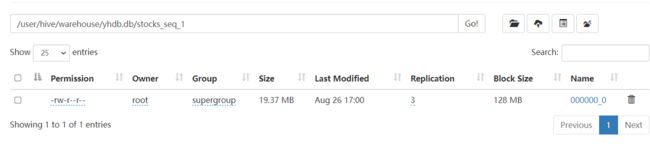
insert into stocks_seq_2 select * from stocks_1;使用压缩后:16.71M
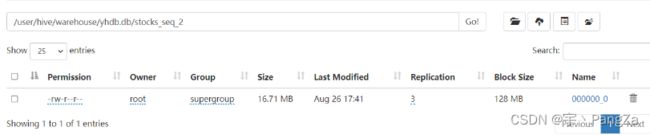
使用压缩前:19.37M
压缩工具如何判断好坏? 压缩比例高,解压速度快!
5、视图
这个来自于数据库,mysql就有视图。
复习mysql的视图:
类似于虚拟表或者临时表,本身不存储数据。
创建视图的语句:
create view 视图的名字 as select 语句。
跟虚拟表的区别是:创建了视图,可以反复使用,不会因为你关闭客户端而消失。
创建一个视图:
create view v_emp_dept as
select emp.*,dept.dname,dept.loc from emp join dept on emp.deptno=dept.deptno; 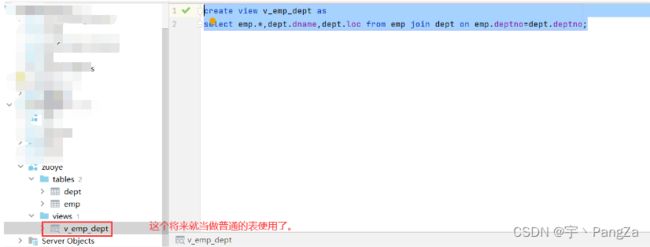
使用视图:
select * from v_emp_dept where deptno=30;删除视图:
drop view v_emp_dept;以上是mysql视图的演示,hive也支持视图:
create view if not exists v_1 as select * from t_user ;
show tables; 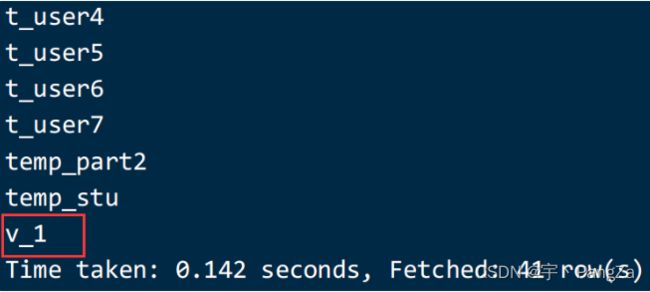
show create table v_1;
desc v_1; 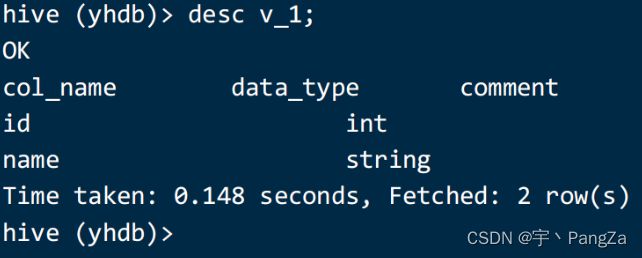

删除视图
drop view if exists v_1;二、Hive的函数、
1、如何查看自带的函数
show functions; --查看所有的函数
desc function functionName; -查看某个具体的函数如何使用
hive (yhdb)> desc function abs;
OK
tab_name
abs(x) - returns the absolute value of x
Time taken: 0.047 seconds, Fetched: 1 row(s)2、日期函数
当前系统时间函数:current_date()、current_timestamp()、unix_timestamp()
- 函数1:current_date();
当前系统日期 格式:"yyyy-MM-dd"
-- 函数2:current_timestamp();
当前系统时间戳: 格式:"yyyy-MM-dd HH:mm:ss.ms"
-- 函数3:unix_timestamp();
当前系统时间戳 格式:距离1970年1月1日0点的秒数。
select unix_timestamp(); //获取当前的时间戳
select unix_timestamp('2017/1/21','yyyy/MM/dd') ;
hive (yhdb)> select current_date();
OK
_c0
2023-08-26
Time taken: 1.032 seconds, Fetched: 1 row(s)
hive (yhdb)> select current_timestamp();
OK
_c0
2023-08-26 18:38:02.304
Time taken: 0.404 seconds, Fetched: 1 row(s)
日期转时间戳函数:unix_timestamp()
获取当前时间的时间戳
select unix_timestamp();
select unix_timestamp(current_timestamp());
hive (yhdb)> select unix_timestamp();
unix_timestamp(void) is deprecated. Use current_timestamp instead.
unix_timestamp(void) is deprecated. Use current_timestamp instead.
OK
_c0
1693046302
Time taken: 0.448 seconds, Fetched: 1 row(s)
hive (yhdb)> select unix_timestamp('2022-10-01 00:00:00');
OK
_c0
1664582400
Time taken: 0.322 seconds, Fetched: 1 row(s)
hive (yhdb)> select unix_timestamp('2022/10/01');
OK
_c0
NULL
Time taken: 0.473 seconds, Fetched: 1 row(s)
hive (yhdb)> select unix_timestamp('2022/10/01','yyyy/MM/dd');
OK
_c0
1664582400
Time taken: 0.336 seconds, Fetched: 1 row(s)时间戳转日期函数:from_unixtime
根据时间戳,指定输出日期的格式:
hive (yhdb)> select from_unixtime(1693046606);
OK
_c0
2023-08-26 10:43:26
Time taken: 0.39 seconds, Fetched: 1 row(s)
hive (yhdb)> select from_unixtime(1693046606,'yyyy/MM/dd HH~mm~ss');
OK
_c0
2023/08/26 10~43~26
Time taken: 1.367 seconds, Fetched: 1 row(s)unix_timestamp 函数是将一个字符串,变为了一个时间戳
from_unixtime 函数是将时间戳变为了一个字符串计算时间差函数:datediff()、months_between()
select datediff('2023-01-01','2023-02-01');
hive (yhdb)> select datediff('2023-01-01','2023-02-01');
OK
_c0
-31
出现负数,说明数据是前面的时间减去后面的时间,相差的天数。
hive (yhdb)> select months_between('2019-12-20','2019-11-01');
OK
_c0
1.61290323
Time taken: 0.3 seconds, Fetched: 1 row(s)
前面的时间减去后面时间的月数 ,可以精确到小数。日期时间分量函数:year()、month()、day()、hour()、minute()、second()
select month(current_date());
hive (yhdb)> select month(current_date());
OK
_c0
8
Time taken: 0.395 seconds, Fetched: 1 row(s)
hive (yhdb)> select year(current_date());
OK
_c0
2023
Time taken: 0.374 seconds, Fetched: 1 row(s)
hive (yhdb)> select year('2012-12-12');
OK
_c0
2012
Time taken: 0.395 seconds, Fetched: 1 row(s)日期定位函数:last_day()、next_day()
--月末:
select last_day(current_date);
--可以求出当前日期的下个星期几
select next_day(current_date,'thursday');日期加减函数:date_add()、date_sub()、add_months()
select date_add(current_date,1);
select date_sub(current_date,90);
select add_months(current_date,1);综合练习:
--当月第1天
当前月往前推一个月,7月,7月的最后一天,+1
select date_add(last_day(add_months(current_date,-1)),1);
--下个月第1天:
select date_add(last_day(current_date),1);
dayofmonth(日期): 当前时间是这个月的第几天
select add_months(date_sub(current_date,dayofmonth(current_date)-1),1)字符串转日期:to_date()
select to_date('2023-07-01');将日期转为字符串:date_format()
select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss');
select date_format(current_timestamp(),'yyyy/MM/dd');
select date_format('2017-01-01','yyyy-MM-dd HH:mm:ss');3、字符串函数
-- lower(转小写)
select lower('ABC');
--upper(转大写)
select upper('abc');
--length(字符串长度,字符数)
select length('abc');
-- concat(字符串拼接)
select concat("A", 'B');
-- concat_ws(指定分隔符)
select concat_ws('-','a' ,'b','c');
-- substr(求子串)
select substr('abcde',3);
-- split(str,regex) 切分字符串,返回数组
select split("a-b-c-d-e-f","-");
-- 上面将字符串切割成数组,咱们就可以用爆炸函数(展开函数)给它炸开:
select explode(split('h-e-l-l-o','-'));4、类型转换函数
select cast('123' as int)+1;
select cast(sal as string) from emp ;
select cast(1.5 as int);5、数学函数
--round 四舍五入((42.3 =>42))
select round(42.3);
--ceil 向上取整(42.3 =>43)
select ceil(42.3);
--floor 向下取整(42.3 =>42)
select floor(42.3);6、hive的其他函数
1)nvl 判断一个数值是否为null,如果为null,给一个默认值
--第一个参数为null,用第二个参数替代
select nvl(null,100);
--第一个参数不为null,就返回它本身
select nvl(200,100);
select nvl(comm,0)+sal from emp;2) 函数case when then ....when ...then.. else... end
举例说明:
数据如下:
张三 A 男
李四 A 男
王五 B 男
赵六 A 女
琪琪 B 女
巴巴 B 女
求男女数量。
建表:
create table emp_sex(
name string,
dept_id string,
sex string)
row format delimited fields terminated by "\t";
导入数据:
load data local inpath '/home/hivedata/test_a.txt' into table emp_sex;
sql 编写:
select sex,count(1) from emp_sex group by sex;
还有其他写法:
select
sum(case when sex='男' then 1 else 0 end) as `男` ,
sum(case when sex='女' then 1 else 0 end) as `女`
from emp_sex;
还可以使用类似于switch的写法:
select
sum(case sex when '男' then 1 else 0 end) as `男` ,
sum(case sex when '女' then 1 else 0 end) as `女`
from emp_sex;3)get_json_object 从json数据中获取值
select get_json_object('{"name":"jack","age":19}','$.age');4) parse_url 解析一个字符串中的url参数
举例: 获取url中的HOST
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','HOST');
OK
www.baidu.com
Time taken: 0.437 seconds, Fetched: 1 row(s)
-- 获取PROTOCOL中的协议
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','PROTOCOL');
-- 获取Path
OK
http
Time taken: 0.194 seconds, Fetched: 1 row(s)
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','PATH');
OK
/path1/path2
Time taken: 0.183 seconds, Fetched: 1 row(s)
// 区分大小写
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','path');
OK
_c0
NULL5)if(p1,p2,p3)
语法格式:
if和case差不多,都是处理单个列的查询结果
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值: T
e.g.
select if(1==1,1,2) ;
select if(name!='a',name,'aaa') from user01;
select source,if(source='猎聘',1,2) as flag from t_cal_dowell_resume;6) coalesce(col1,col2,col3...)返回第一个不为空的
select coalesce(null,1,23,4);
返回结果为1