Python大神用的贼溜的九个技巧,超级实用~
文章目录
- 一、整理字符串输入
- 二、迭代器(切片)
- 三、跳过可对对象的开头
- 四、只包含关键字参数的函数 (kwargs)
- 五、创建支持「with」语句的对象
- 六、用「slots」节省内存
- 七、限制「CPU」和内存使用量
- 八、控制可以/不可以导入什么
- 九、实现比较运算符的简单方法
- 总结
-
-
- Python技术资源分享
-
- 1、Python所有方向的学习路线
- 2、学习软件
- 3、精品书籍
- 4、入门学习视频
- 5、实战案例
- 6、清华编程大佬出品《漫画看学Python》
- 7、Python副业兼职与全职路线
-

一、整理字符串输入
整理用户输入的问题在编程过程中很常见。有更好的方法来解决:
user_input = "This
string has some whitespaces...
"
character_map = {
ord(
) : ,
ord( ) : ,
ord(
) : None
}
user_input.translate(character_map) # This string has some whitespaces...
在本例中,你可以看到空格符「n」和「t」都被替换掉了几个空格,「r」都被替换掉了。
这只是个很简单的例子,我们可以更进一步,使用「 unicodedata”程序包生成大型重映射表,并使用其中的“combining()”进行生成和映射
二、迭代器(切片)
如果对返回一个对象进行简单的操作,会提示生成对象下的“TypeError”,但是我们可以用一个对象的方案来解决问题:
import itertools
s = itertools.islice(range(50), 10, 20) # <itertools.islice object at 0x7f70fab88138>
for val in s:
...
我们可以使用「itertools.islice」创建一个「islice」,该对象是一个迭代器,可以产生我们想要的项。但需要注意的是,该操作要使用对象以及对象的所有生成器项,「 islice」对象中的所有项。
三、跳过可对对象的开头
有时你要处理一些不需要的行(如注释)开头的文件。「itertools」再次提供了一种简单的解决方案:
string_from_file = """
// Author: ...
// License: ...
//
// Date: ...
Actual content...
"""
import itertools
for line in itertools.dropwhile(lambda line: line.startswith("//"), string_from_file.split("
")):
print(line)
这段代码只打印初始注释部分之后的内容。如果我们只想舍弃可迭代对象的开头部分(本示例中为开头的注释行),而又不知道要这部分有多长时,这种方法就很有用了。
四、只包含关键字参数的函数 (kwargs)
当我们使用下面的函数时,创建仅仅需要关键字参数作为输入的函数来提供更清晰的函数定义,会很有帮助:
def test(*, a, b):
pass
test("value for a", "value for b") # TypeError: test() takes 0 positional arguments...
test(a="value", b="value 2") # Works...
如你所见,在关键字参数之前加上一个「」就可以解决这个问题。如果我们将某些参数放在「」参数之前,它们显然是位置参数。
五、创建支持「with」语句的对象
举例而言,我们都知道如何使用「with」语句打开文件或获取锁,但是我们可以实现自己上下文表达式吗?是的,我们可以使用「enter」和「exit」来实现上下文管理协议:
class Connection:
def __init__(self):
...
def __enter__(self):
# Initialize connection...
def __exit__(self, type, value, traceback):
# Close connection...
with Connection() as c:
# __enter__() executes
...
# conn.__exit__() executes
这是在 Python 中最常见的实现上下文管理的方法,但是还有更简单的方法:
from contextlib import contextmanager
@contextmanager
def tag(name):
print(f"<{name}>")
yield
print(f"{name}>")
with tag("h1"):
print("This is Title.")
上面这段代码使用 contextmanager 的 manager 装饰器实现了内容管理协议。在进入 with 块时 tag 函数的第一部分(在 yield 之前的部分)就已经执行了,然后 with 块才被执行,最后执行 tag 函数的其余部分。
六、用「slots」节省内存
如果你曾经编写过一个创建了某种类的大量实例的程序,那么你可能已经注意到,你的程序突然需要大量的内存。那是因为 Python 使用字典来表示类实例的属性,这使其速度很快,但内存使用效率却不是很高。通常情况下,这并不是一个严重的问题。但是,如果你的程序因此受到严重的影响,不妨试一下「slots」:
class Person:
__slots__ = ["first_name", "last_name", "phone"]
def __init__(self, first_name, last_name, phone):
self.first_name = first_name
self.last_name = last_name
self.phone = phone
当我们定义了「slots」属性时,Python 没有使用字典来表示属性,而是使用小的固定大小的数组,这大大减少了每个实例所需的内存。使用「slots」也有一些缺点:我们不能声明任何新的属性,我们只能使用「slots」上现有的属性。而且,带有「slots」的类不能使用多重继承。
七、限制「CPU」和内存使用量
如果不是想优化程序对内存或 CPU 的使用率,而是想直接将其限制为某个确定的数字,Python 也有一个对应的库可以做到:
import signal
import resource
import os
# To Limit CPU time
def time_exceeded(signo, frame):
print("CPU exceeded...")
raise SystemExit(1)
def set_max_runtime(seconds):
# Install the signal handler and set a resource limit
soft, hard = resource.getrlimit(resource.RLIMIT_CPU)
resource.setrlimit(resource.RLIMIT_CPU, (seconds, hard))
signal.signal(signal.SIGXCPU, time_exceeded)
# To limit memory usage
def set_max_memory(size):
soft, hard = resource.getrlimit(resource.RLIMIT_AS)
resource.setrlimit(resource.RLIMIT_AS, (size, hard))
我们可以看到,在上面的代码片段中,同时包含设置最大 CPU 运行时间和最大内存使用限制的选项。
在限制 CPU 的运行时间时,我们首先获得该特定资源(RLIMIT_CPU)的软限制和硬限制,然后使用通过参数指定的秒数和先前检索到的硬限制来进行设置。
最后,如果 CPU 的运行时间超过了限制,我们将发出系统退出的信号。
在内存使用方面,我们再次检索软限制和硬限制,并使用带「size」参数的「setrlimit」和先前检索到的硬限制来设置它。
八、控制可以/不可以导入什么
有些语言有非常明显的机制来导出成员(变量、方法、接口),例如在 Golang 中只有以大写字母开头的成员被导出。然而,在 Python 中,所有成员都会被导出(除非我们使用了「all」):
def foo():
pass
def bar():
pass
__all__ = ["bar"]
在上面这段代码中,我们知道只有「bar」函数被导出了。同样,我们可以让「all」为空,这样就不会导出任何东西,当从这个模块导入的时候,会造成「AttributeError」。
九、实现比较运算符的简单方法
为一个类实现所有的比较相似(如 lt , le , gt , ge)是很繁琐的。有更简单的方法可以做到这一点吗?这种时候,「functools.total_ordering」就是一个很好的帮手:
from functools import total_ordering
@total_ordering
class Number:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value < other.value
def __eq__(self, other):
return self.value == other.value
print(Number(20) > Number(3))
print(Number(1) < Number(5))
print(Number(15) >= Number(15))
print(Number(10) <= Number(2))
这里的工作原理究竟是怎样的呢?我们用「total_ordering」装饰器简化实现对类实例排序的过程。我们只需要定义「LT」和「当量」就可以了,它们是实现其余操作所需要的最小的集合(这里也表现了装饰器的作用——为我们操作空白)。
总结
并非本文中所有相关的功能在日常使用的 Python 编程中都是特定的或有用的,但某些功能可能不会时派上用场,而且它们也可能很简单一些就很冗长且令人厌烦的任务。
还需指出的是,所有这些功能都是 Python 标准库的一部分。
功能时,请先看 Python 标准库,如果你不能找到想要的功能,可能只是因为你还没有努力寻找(如果真的没有,那肯定也存在于一些可用库中)。
【最新Python全套从入门到精通学习资源,文末免费领取!】
Python技术资源分享
如果你对Python感兴趣,学好 Python 不论是就业、副业赚钱、还是提升学习、工作效率,都是非常不错的选择,但要有一个系统的学习规划。
小编是一名Python开发工程师,自己整理了一套 【最新的Python系统学习教程】,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。
如果你是准备学习Python或者正在学习,下面这些你应该能用得上:
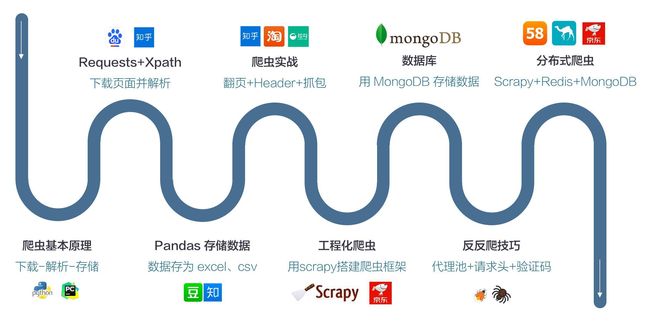
1、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
2、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
3、精品书籍
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

4、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
5、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

6、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。

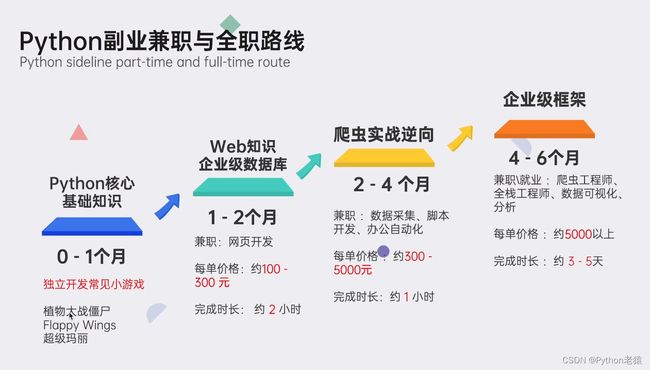
7、Python副业兼职与全职路线
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
CSDN大礼包:《Python入门资料&实战源码&安装工具】免费领取(安全链接,放心点击)
