力扣429 - N叉树的层序遍历【BFS+DFS】
最近一直在做二叉树的层次遍历相关的题,挑了一道比较经典的题给大家讲解
N 叉树的层序遍历
- 原题描述
- 题型引入和分析
-
- 1、二叉树的层序遍历算法
- 2、思路分析与讲解
- 解法一:BFS(广度优先搜索)
-
- 1、万能模板(!!!)
- 2、分步详解(重要代码)
- 3、整体代码(Java、C++)
- 解法二:DFS(深度优先搜索)
-
- 1、万能模板(!!!)
- 2、分步详解
- 3、整体代码(Java、C++)
- 总结与拓展
原题描述
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
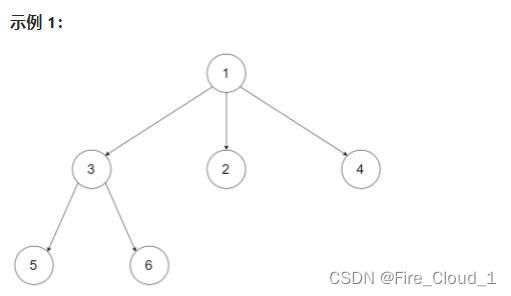
输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
题型引入和分析
从题目背景来看,是属于层序遍历之类的题目,但是对于二叉树的层序遍历我们还是比较熟悉(鉴于可能有同学不太清楚,稍微讲一下,作为引入)
1、二叉树的层序遍历算法
void LevelOrder(BTNode* b)
{
BTNode* p;
SqQueue* qu;
InitQueue(qu);
EnQueue(qu, b); //先将根结点入队
while (!QueueEmpty(qu))
{
DeQueue(qu, p);
printf("%c ", p->data);
//若有左/右孩子,则将其入队
if (p->lchild != NULL)
EnQueue(qu, p->lchild);
if (p->rchild != NULL)
EnQueue(qu, p->rchild);
}
DestroyQueue(qu);
}
- 对于二叉树的层序遍历是采用环形队列的方法来,首先是先将根节点入队,在队不空时循环。在队列中出队一个结点p,访问它,若有左孩子,则将其左孩子入队;若有右孩子,则将其右孩子入队,如此操作直到队空为止,为了理解地更加形象,配了一段动画给大家理解(微信手机端看不到动画)
当然这只是很普通的一种算法,也是比较受大众所接受的,比较好理解,有其他高效的算法也可以层序遍历二叉树,比如下面的BFS(广度优先搜索)就不错,也是蛮高效的。看过了二叉树的层序遍历,接下来回归正题,进入本题的讲解
2、思路分析与讲解
从题目背景可以看出,无论是对于二叉树还是N叉树的层序遍历,我们优先想到的肯定是BFS(广度优先搜索),去层层遍历它的每一个结点,在其中继续寻找其有多少孩子结点,最后将遍历到的结点放入小结果集,最后放入大结果集;DFS(深度优先搜索)也是一样的套路,就是需要进行不断地递归,去寻找孩子结点,最后将结果返回
解法一:BFS(广度优先搜索)
1、万能模板(!!!)
对于BFS解决二叉树的层次遍历,有固定的模板,只要把模板记下来,遇到类似的问题拿模板去套就能慢慢出思路了,具体题目只需要在放入结果的位置稍微判断和整改即可
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
int size = que.size();
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};
2、分步详解(重要代码)
- 首先看到题目要我们返回的是一个vector
queue<Node*> qu;
vector<vector<int>> result;
if(root != NULL) qu.push(root);
-
其次,就是要在队不为空时进行每层的遍历判断,一个循环便是一层,首先取到遍历当前层是队列的大小,然后去进行一个单层的遍历,取出当前队列的首元素,并将其出队,之后此结点放入小结果集,也就是为了存放一层的所有结点所定义的vec容器。
-
后面就是比较关键的一步,要对遍历到结点的孩子结点进行一个再次的内层遍历,去判断其是否有孩子结点,若有,则将它们全部入队
//将遍历到的孩子结点入队
for(int i = 0;i < node->children.size(); ++i)
if(node->children[i]) qu.push(node->children[i]);
//若有孩子结点,则将其入队,继而继续出队,而不是放进容器
结构顺序大致是这样

- 在存放完这一层的所有结点之后,因为孩子结点已入队,所以队列不为空,继续while循环的执行,这个时候就是下一层即是孩子结点所在的层的遍历,孩子结点可能又会有孩子结点,一层层遍历下去, 直到碰到叶子结点为止
3、整体代码(Java、C++)
class Solution {
public:
vector<vector<int>> levelOrder(Node* root) {
queue<Node*> qu;
vector<vector<int>> result;
if(root != NULL) qu.push(root);
while(!qu.empty())
{
int sz = qu.size();
vector<int> vec;
for(int i = 0;i < sz; ++i)
{
Node* node = qu.front();
qu.pop();
vec.push_back(node->val);
//将遍历到的孩子结点入队
for(int i = 0;i < node->children.size(); ++i)
if(node->children[i]) qu.push(node->children[i]);
//若有孩子结点,则将其入队,继而继续出队,而不是放进容器
}
result.push_back(vec);
}
return result;
}
};
再给一种Java版本的
class Solution {
public List<List<Integer>> levelOrder(Node root) {
Queue<Node> qu = new LinkedList<>();
List<List<Integer>> result = new ArrayList<>();
if(root != null) qu.offer(root);
while(!qu.isEmpty())
{
int sz = qu.size();
List<Integer> vec = new ArrayList<>();
while(sz > 0)
{
Node node = qu.poll();
vec.add(node.val);
qu.addAll(node.children);
sz--;
}
result.add(vec);
}
return result;
}
}
- 语言都是想通的,一般刷题的话我C++用的多一些,Java有时候也会用。这里整体思路也是一致,只是但是循环用的是while而已,add()是添加的意思,addAll()便是将所有此类型的结点添加,也就是将所有孩子结点入队即可,sz–直到其为0为止,就是单层的结点数量
解法二:DFS(深度优先搜索)
1、万能模板(!!!)
不仅是BFS有万能模板,DFS也有,一样先展示给大家
class Solution {
public:
void order(TreeNode* cur, vector<vector<int>>& result, int depth)
{
if (cur == nullptr) return;
if (result.size() == depth) result.push_back(vector<int>());
result[depth].push_back(cur->val);
order(cur->left, result, depth + 1);
order(cur->right, result, depth + 1);
}
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
int depth = 0;
order(root, result, depth);
return result;
}
};
2、分步详解
if(cur == NULL) return;
void dfs(Node* cur,int dep,vector<vector<int>>& res)
dfs(root,0,result);
- 首先讲解一下递归参数,一个是Node*结点类型,主要用用于判断当前所遍历到的结点,开始是用于判断根节点是否为空,若为空,则直接返回,dep就是遍历到的此树的深度,也就是用于控制在每一层的结点,将他们放入小结果集,最后的res则是大结果集,用于接收最后整棵树的结果,这里有一个细节要注意,就是这个&取址,准确的说应该是引用,只有加上了这个,才能将递归函数的中所收集的结果传出去,否则只会出现如下情况,主函数接口中就接受不到最终的结果,即传不出去

- 然后是递归内部的主要代码,res[dep]便是上面讲到的控制每一层的遍历并加入这一层的结点的值,也就是cur->val,因为这个dep在递归其孩子结点的时候是会增加的,所以将其设置为数组的下标,当这个dep == res.size()时,是递归出口,将vector<>()是开辟一个小结果集,将所收集每一层的结点放入这个大结果集
if(dep == res.size())
res.push_back(vector<int>());
res[dep].push_back(cur->val);
- 最后,便是对于孩子结点的遍历,采取for循环的方式进行遍历,这里的auto&是正常for循环的简写,这样比较方便,也简洁易懂,设置引用变量x,对cur->children所指向的孩子结点做一一的遍历,dfs继续递归,进入函数,这里可以看到dep每递归一次便会增加,也是相当于将其添加进结果集的一个标记
for(auto& x : cur->children)
dfs(x,dep + 1,res);
3、整体代码(Java、C++)
class Solution {
private:
void dfs(Node* cur,int dep,vector<vector<int>>& res)
{
if(cur == NULL) return;
if(dep == res.size())
res.push_back(vector<int>());
res[dep].push_back(cur->val);
//递归孩子结点
for(auto& x : cur->children)
dfs(x,dep + 1,res);
}
public:
vector<vector<int>> levelOrder(Node* root) {
vector<vector<int>> result;
dfs(root,0,result);
return result;
}
};
一样提供一下Java版本
class Solution {
private void dfs(Node cur,int level,List<List<Integer>> res)
{
if(cur == null) return;
List<Integer> list = res.size() <= level ? new ArrayList<Integer>() : res.get(level);
list.add(cur.val); //添加当前结点到每一树层
if(level >= res.size())
res.add(list); //若level首次到达下一树层,则上一树层放入结果集
//孩子结点递归
for(Node ChildrenNode : cur.children)
dfs(ChildrenNode, level + 1, res);
}
public List<List<Integer>> levelOrder(Node root) {
List<List<Integer>> result = new ArrayList<>();
dfs(root,0,result);
return result;
}
}
略微做一些讲解
Java里面的容器主要还是用ArrayList,内部类型名称要写成Integer,不能写成Int,其他思路也是相似,就是这里在递归内部用了一个三元运算符(主要是可以装一下),比较长一些,也就是判断一下当前的level值是否到达容器的大小,若是,则新开辟一个小的结果集用于放入新的结点,若还未到,则使用get()获取到当前level位置所在值的结点
list.add(cur.val);
这个就是将当前做遍历到的结点放入新开辟的小结果集的一个操作。其他操作均是一个意思,便不做说明
总结与拓展
看完了两种BFS和DFS对N叉树的遍历,你有没有对这两种遍历搜索算法有了一个初步的了解呢,DFS的话在回溯里比较多,BFS在图里比较多,但是对于二叉树的层次遍历,这两种方法用的都挺多的,大家记住我提供的这个模板就可以秒杀这下面的题了
102.二叉树的层序遍历
107.二叉树的层序遍历Ⅱ
199.二叉树的右视图
637.二叉树的层平均值
515.在每个树行中找最大值
116.填充每个节点的下一个右侧节点指针
117.填充每个节点的下一个右侧节点指针Ⅱ
104.二叉树的最大深度
111.二叉树的最小深度
