2022-1-24 数据结构基础 链表
数据结构 1
- 资源
- 基础
-
- 基本概念和术语
-
-
- 复杂度
- 内存
- 算法
-
- 链表
-
- 单向链表
-
-
- 头插法和尾插法
- 遍历修改链表
- 插入链表
- 删除
-
- 双向链表
-
-
- 创建
- 插入
- 删除
- 遍历
-
- 循环链表
-
-
- 初始化
- 创建
- 合并
- 插入
- 删除
-
- 链式存储结构的优点:
资源
C语言网 数据结构
数据结构学习导图
c#实现的排序算法
B站数据结构学习笔记
B站数据结构课程
基础
程序=数据结构+算法

基本概念和术语
1)数据
数据(Data)是信息的载体,是可以被计算机识别,存储并加工处理的描述客观事物的信息符号的总称。数据不仅仅包括了整形,浮点数等数值类型,还包括了字符甚至声音,视频,图像等非数值的类型。
2)数据元素
数据元素(Data Element)是描述数据的基本单位,也被称为记录。一个数据元素有若干个数据项组成。
如禽类,鸡鸭都属于禽类的数据元素。
3)数据项
数据项(Data Item)是描述数据的最小单位,其可以分为组合项和原子项:
a)组合项
如果数据元素可以再度分割,则每一个独立处理单元就是数据项,数据元素就是数据项的集合。
b)原子项
如果数据元素不能再度分割,则每一个独立处理的单元就是原子项。
如日期2019年4月25日就是一个组合项,其表示日期,但如果单独拿25日这个数据出来观测,这就是一个原子项,因为其不可以再分割。
4)数据对象
数据对象(Data Object)是性质相同的一类数据元素的集合,是数据的一个子集。数据对象可以是有限的,也可以是无限的。
5)数据结构
数据结构(Data Structures)主要是指数据和关系的集合,数据指的是计算机中需要处理的数据,而关系指的是这些数据相关的前后逻辑,这些逻辑与计算机储存的位置无关,其主要包含以下四大逻辑结构

物理结构:数据的逻辑结构在计算机中(内存)的存储形式。分为顺序存储结构、链式存储结构、索引存储结构、散列存储结构。
1.顺序存储结构
顺序存储结构是把数据元素存放在连续的存储单元里,数据元素之间的逻辑关系是通过数据元素的位置。(在前面的数据元素就存在前面;在后面的数据元素就存在后面)C语言用数组来实现顺序存储结构
例:(bat,cat,eat_mat)
2.链式存储结构
用一组任意的存储单元存储数据元素(可能连续也可能不连续),数据元素之间的逻辑关系用指针来表示(用指针存放后继元素的存储地址)
C语言中用指针来实现链式存储结构
存放(bat,cat,eat_mat)

现在如银行、医院等地方,设置了排队系统,也就是每个人去了,先领一个号,等着叫号,叫到时去办理业务或看病。在等待的时候,你爱在哪在哪,可以坐着、站着或者走动,甚至出去逛一圈,只要及时回来就行。你关注的是前一个号有没有被叫到,叫到了,下一个就轮到了。
3.索引存储结构
在存储节点信息的同时,还建立附加索引
索引表中的每一项称为一个索引项,
索引项的一般形式是:(关键字,地址)
关键字是能唯一标识一个结点的那些数据项。
若每个结点在索引表中都有一个索引项,则该索引表称之为稠密索引(Dense Index)。若一组结点在索引表中只对应一个索引项,则该索引表称之为稀疏索引(Sparse Index)。
4.散列存储结构


复杂度
- 时间复杂度
时间复杂度表示一个程序运行所需要的时间,其具体需要在机器环境中才能得到具体的值,但我们一般并不需要得到详细的值,只是需要比较快慢的区别即可,为此,我们需要引入时间频度(语句频度)的概念。
时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。一般情况下,算法中的基本操作重复次数的是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
- 空间复杂度
一个程序的空间复杂度是指运行完一个程序所需内存的大小,其包括两个部分。
a)固定部分。这部分空间的大小与输入/输出的数据的个数多少、数值无关。主要包括指令空间(即代码空间)、数据空间(常量、简单变量)等所占的空间。这部分属于静态空间。
b)可变空间,这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等。这部分的空间大小与算法有关。
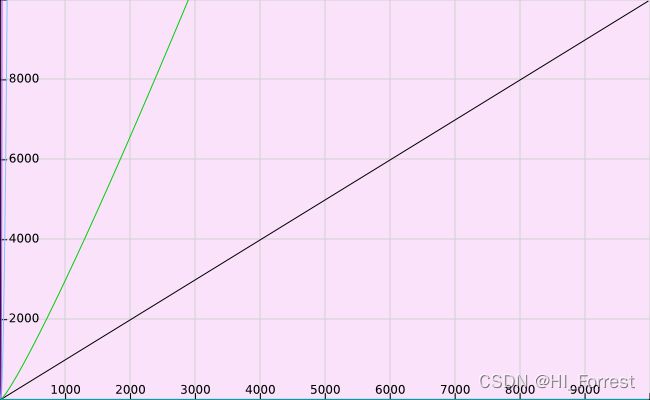
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
内存
#include很显然,我们设计一个数据结构程序的过程是先定义所需要的变量与指针变量---->进行内存分配---->判断是否分配成功(分配不成功就报错或者退出程序)---->对指针空间中的数据进行操作(如赋值,修改,查询,删除) ---->完成操作后释放指针
算法
算法的特性(确定、有穷、可行、输入、输出)
1.有穷性:算法在执行有限步骤之后,自动结束而不会出现无限循环,并且每一个步骤都在可接受的时间范围内完成。当然这里的有穷并不是纯数学意义的,而是在实际应用中合理的、可以接受的“边界”。你说你写一个算法,计算机需要算上20年,一定会结束,他在数学上是有穷的,媳妇都熬成婆了,算法的意义
就不大了。
2.确定性:算法的每一个步骤都有确定的含义,不会出现二义性(不会有歧义)。
3.可行性:算法中的所有操作都可以通过已经实现的基本操作运算执行有限次来实现。
4.输入:一个算法有零个或多个输入。当用函数描述算法时,输入往往是通过形参表示的,在它们被调用时,从主调函数获得输入值。
5.输出:一个算法有一个或多个输出,它们是算法进行信息加工后得到的结果,无输出的算法没有任何意义。当用函数描述算法时,输出多用返回值或引用类型的形参表示。
算法的设计要求
好的算法应该具有正确性、可读性、健壮性、时间效率高和存储量低的特征。
1.正确性(Correctness):能正确的反映问题的需求,能得到正确的答案。
分以下四个层次:
a.算法程序没有语法错误;
b.算法程序对n组输入产生正确的结果;
c.算法程序对典型、苛刻、有刁难性的几组输入可以产生正确的结果;
d.算法程序对所有输入产生正确的结果;
但我们不可能逐一的验证所有的输入,因此算法的正确性在大多数情况下都不可能用程序证明,而是用数学方法证明。所以一般情况下我们把层次3作为算法是否正确的标准。
2.可读性(Readability):算法,首先应便于人们理解和相互交流,其次才是机器可执行性。可读性强的算法有助于人们对算法的理解,而难懂的算法易于隐藏错误,且难于调试和修改。
3.健壮性(Robustness):当输入的数据非法时,好的算法能适当地做出正确反应或进行相应处理,而不会产生一些莫名其妙的输出结果。【健壮性又叫又名鲁棒性即使用棒子粗鲁地对待他也可以执行类似于Java预料到可能出现的异常并对其进行捕获处理】
4.(高效性)时间效率高和存储量低
链表
链表的基本思维是,利用结构体的设置,额外开辟出一份内存空间去作指针,它总是指向下一个结点,一个个结点通过NEXT指针相互练习,串联,这就形成了我们的链表。



单向链表
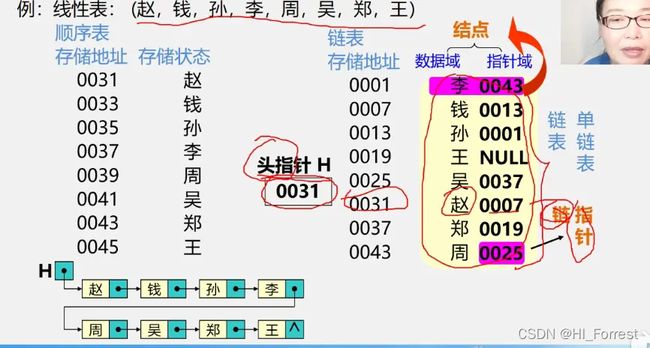
头指针:
指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针;
头指针具有标识作用,所以常用头指针冠以链表的名字;
无论链表是否为空,头指针均不为空。头指针是链表的必要元素
头结点:
头结点是为了操作的统一和方便而设立的,放在第一元素的结点之前,其数据域一般无意义(也可存放链表的长度)
有了头结点,对在第一元素结点前插入结点和删除第一结点,其操作与其它结点的操作就统一了
头结点不一定是链表必须要素
首元结点:是指链表中存储第一个数据元素a1的结点

有头结点有什么好处?
①有了头结点,对在第一元素结点前插入结点和删除第一结点,其操作与其它结点的操作就统一了
②便于空表和非空表的统一处理
当链表不设头结点时,假设L为单链表的头指针,它应该指向首元结点,则当单链表为长度n为0的空表时,L指针为空(判定空表的条件可记为:LNULL)。增加头结点后,无论链表是否为空,头指针都是指向头结点的非空指针。头指针指向头结点。若为空表,则头结点的指针域为空(判定空表的条件可记为:L ->next NULL)
顺序表每个元素的存储位置都可从线性表的起始位置计算得到。而在单链表中,各个元素的存储位置都是随意的。取得第i个数据元素必须从头指针出发顺链进行寻找,也称为顺序存取的存取结构。之前说的顺序表是随机存取而链表是顺序存储
单链表是由若干个结点构成,所以先定义一下结点。每一个结点都是有两部分组成,一部分是数据元素本身(数据域data)其数据类型根据实际问题的需要确定。另一部分是指向下一个元素(结点)的指针(指针域next)存放下一个元素的地址,结点可以用C语言中的结构体实现当中包含两个成员。
头插法和尾插法




遍历修改链表
//链表内容的修改,再链表中修改值为x的元素变为为k。
LinkedList LinkedListReplace(LinkedList L,int x,int k) {
Node *p=L->next;
int i=0;
while(p){
if(p->data==x){
p->data=k;
}
p=p->next;
}
return L;
}
插入链表
//单链表的插入,在链表的第i个位置插入x的元素
LinkedList LinkedListInsert(LinkedList L,int i,int x) {
Node *pre; //pre为前驱结点
pre = L;
int tempi = 0;
for (tempi = 1; tempi < i; tempi++) {
pre = pre->next; //查找第i个位置的前驱结点
}
Node *p; //插入的结点为p
p = (Node *)malloc(sizeof(Node));
p->data = x;
p->next = pre->next;
pre->next = p;
return L;
}
删除
//单链表的删除,在链表中删除值为x的元素
LinkedList LinkedListDelete(LinkedList L,int x) {
Node *p,*pre; //pre为前驱结点,p为查找的结点。
p = L->next;
while(p->data != x) { //查找值为x的元素
pre = p;
p = p->next;
}
pre->next = p->next; //删除操作,将其前驱next指向其后继。
free(p);
return L;
}
双向链表
在单链表的基础上,产生了双向链表的概念,即: 在单链表的基础上,对于每一个结点设计一个前驱结点,前驱结点与前一个结点相互连接,构成一个链表。
双向链表可以简称为双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点

双向链表结构有对称性(设指针p指向某一个结点)
p->prior->next=p=p->next->prior(前进一步后退一步相当于原地踏步)

创建
对于创建双向链表,我们需要先创建头结点再逐步的进行添加,请注意,双向链表的头结点是有数据元素的,也就是头结点的data域中是存有数据的,这与一般的单链表是不同的。
对于逐步添加数据,我们采取的做法是,开辟一段新的内存空间作为新的结点,为这个结点进行的data进行赋值,然后将已成链表的上一个结点的next指针指向自身,自身的pre指针指向上一个结点。
//创建双链表
line* initLine(line * head){
int number,pos=1,input_data;
//三个变量分别代表结点数量,当前位置,输入的数据
printf("请输入创建结点的大小\n");
scanf("%d",&number);
if(number<1){return NULL;} //输入非法直接结束
//头结点创建///
head=(line*)malloc(sizeof(line));
head->pre=NULL;
head->next=NULL;
printf("输入第%d个数据\n",pos++);
scanf("%d",&input_data);
head->data=input_data;
line * list=head;
while (pos<=number) {
line * body=(line*)malloc(sizeof(line));
body->pre=NULL;
body->next=NULL;
printf("输入第%d个数据\n",pos++);
scanf("%d",&input_data);
body->data=input_data;
list->next=body;
body->pre=list;
list=list->next;
}
return head;
}
插入
对于每一次的双向链表的插入操作,我们首先需要创建一个独立的结点并通过malloc操作开辟相应的空间,其次我们选中这个新创建的独立节点,将其的pre指针指向所需插入位置的前一个结点,同时,其所需插入的前一个结点的next指针修改指向为该新的结点,同理,该新的结点的next指针将会指向一个原本的下一个结点,而修改下一个结点的pre指针为指向新结点自身,这样的一个操作我们称之为双向链表的插入操作。


//插入数据
line * insertLine(line * head,int data,int add){
//三个参数分别为:进行此操作的双链表,插入的数据,插入的位置
//新建数据域为data的结点
line * temp=(line*)malloc(sizeof(line));
temp->data=data;
temp->pre=NULL;
temp->next=NULL;
//插入到链表头,要特殊考虑
if (add==1) {
temp->next=head;
head->pre=temp;
head=temp;
}else{
line * body=head;
//找到要插入位置的前一个结点
for (int i=1; i<add-1; i++) {
body=body->next;
}
//判断条件为真,说明插入位置为链表尾
if (body->next==NULL) {
body->next=temp;
temp->pre=body;
}else{
body->next->pre=temp;
temp->next=body->next;
body->next=temp;
temp->pre=body;
}
}
return head;
}
删除

//删除元素
line * deleteLine(line * head,int data){
//输入的参数分别为进行此操作的双链表,需要删除的数据
line * list=head;
//遍历链表
while (list) {
//判断是否与此元素相等
//删除该点方法为将该结点前一结点的next指向该节点后一结点
//同时将该结点的后一结点的pre指向该节点的前一结点
if (list->data==data) {
list->pre->next=list->next;
list->next->pre=list->pre;
free(list);
printf("--删除成功--\n");
return head;
}
list=list->next;
}
printf("Error:没有找到该元素,没有产生删除\n");
return head;
}
遍历
如同单链表的遍历一样,利用next指针逐步向后进行索引即可,注意判断这里,我们既可以用while(list)的操作直接判断是否链表为空,也可以使用while(list->next)的操作判断该链表是否为空,其下一节点为空和本结点是否为空的判断条件是一样的效果,当然了,善用双向链表的pre指针进行有效的遍历也是值得去尝试的。
其简单的代码可以表示为:
//遍历双链表,同时打印元素数据
void printLine(line *head){
line *list = head;
int pos=1;
while(list){
printf("第%d个数据是:%d\n",pos++,list->data);
list=list->next;
}
}
循环链表
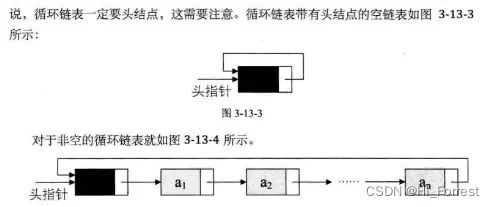
循环链表是头尾相接的链表(即表中最后一个结点的指针域指向头结点,整个链表形成一个环)(circular linked list) 
初始化
其代码可以表示为:
//初始结点
list *initlist(){
list *head=(list*)malloc(sizeof(list));
if(head==NULL){
printf("创建失败,退出程序");
exit(0);
}else{
head->next=NULL;
return head;
}
}
在主函数重调用可以是这样
在主函数重调用可以是这样
//初始化头结点//
list *head=initlist();
head->next=head;
创建
通过逐步的插入操作,创建一个新的节点,将原有链表尾结点的next指针修改指向到新的结点,新的结点的next指针再重新指向头部结点,然后逐步进行这样的插入操作,最终完成整个单项循环链表的创建。
//创建——插入数据
int insert_list(list *head){
int data; //插入的数据类型
printf("请输入要插入的元素:");
scanf("%d",&data);
list *node=initlist();
node->data=data;
//初始化一个新的结点,准备进行链接
if(head!=NULL){
list *p=head;
//找到最后一个数据
while(p->next!=head){
p=p->next;
}
p->next=node;
node->next=head;
return 1;
}else{
printf("头结点已无元素\n");
return 0;
}
}
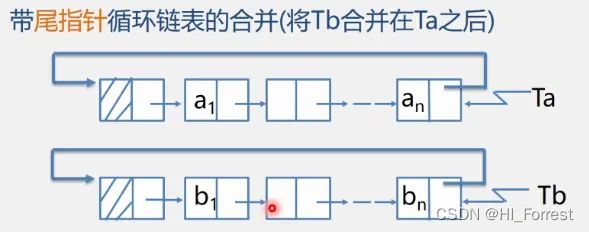
合并


插入
//插入元素
list *insert_list(list *head,int pos,int data){
//三个参数分别是链表,位置,参数
list *node=initlist(); //新建结点
list *p=head; //p表示新的链表
list *t;
t=p;
node->data=data;
if(head!=NULL){
for(int i=1;i<pos;i++){
t=t->next; //走到需要插入的位置处
}
node->next=t->next;
t->next=node;
return p;
}
return p;
}
删除
循环单链表的删除操作可以参考单链表的删除操作,其都是找到需要删除的结点,将其前一个结点的next指针直接指向删除结点的下一个结点即可,但需要注意的是尾节点和头结点的特判,尤其是尾结点,因为删除尾节点后,尾节点前一个结点就成了新的尾节点,这个新的尾节点需要指向的是头结点而不是空,其重点可以记录为【当前的前一节点.next=自身结点.next】这样的操作可以省去头尾结点的特判:
//删除元素
int delete_list(list *head) {
if(head == NULL) {
printf("链表为空!\n");
return 0;
}
//建立临时结点存储头结点信息(目的为了找到退出点)
//如果不这么建立的化需要使用一个数据进行计数标记,计数达到链表长度时自动退出
//循环链表当找到最后一个元素的时候会自动指向头元素,这是我们不想让他发生的
list *temp = head;
list *ptr = head->next;
int del;
printf("请输入你要删除的元素:");
scanf("%d",&del);
while(ptr != head) {
if(ptr->data == del) {
if(ptr->next == head) {
temp->next = head;
free(ptr);
return 1;
}
temp->next = ptr->next; //核心删除操作代码
free(ptr);
//printf("元素删除成功!\n");
return 1;
}
temp = temp->next;
ptr = ptr->next;
}
printf("没有找到要删除的元素\n");
return 0;
}
链式存储结构的优点:
结点空间可以动态申请和释放;
数据元素的逻辑次序靠结点的指针来指示,插入和删除不需要移动元素。
链式存储结构的缺点:
存储密度小,每个结点的指针域需额外占用存储空间。当每个结点的数据域所占的字节数不多时,指针域所占的存储空间的比重显得很大。
存储密度是指结点数据本身占用的空间/结点占用的空间总量
