Jmeter添加变量的四种方法
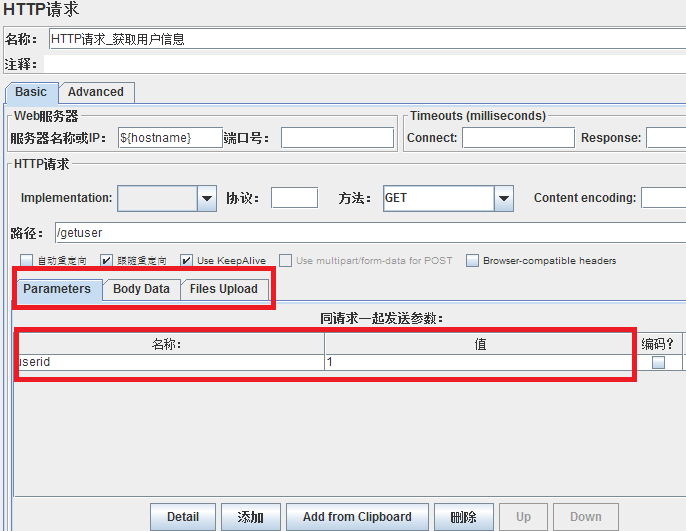
一、在样本中添加同请求一起发送的参数。根据服务器设置的数据类型,来添加不同类型的参数
二、用户定义的变量
1、创建:添加->配置元件->用户定义的变量
2、作用:当前的线程组内所有Sampler都可以引用变量,方便脚本更新;当参数发生变化时,只要在【用户定义的变量】中更新对应变量的参数即可,不需要逐个修改每个http中的参数

3、变量定义:可以是具体的值,也可以是函数(函数可自动生成:选项->函数助手对话框)

4、变量引用:Sample中引用变量的格式为${变量名}
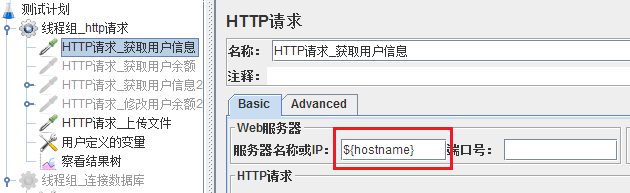
三、函数助手对话框-常用的Jmeter函数(一级菜单栏->选项->函数助手对话框)
1、__Random:在最大值和最小值之间取一个随机值。有三个参数:最大值,最小值,获取的随机值的变量名
例如,生成[1,100]内的随机函数

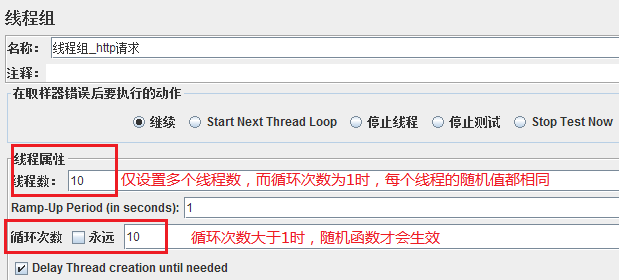
注意:在设置线程属性时,循环次数必须大于1,随机函数才会生效
例如${__Random(1,100,)},当设置线程数=10,循环次数=1时,10次随机函数的结果都是1;当循环次数>1时,才会随机取值
2、__P:设置属性的默认值。有两个参数:变量名,默认值(默认值为1)。例如:${__P(hostname,XXX)}:返回属性hostname的值,如果没有定义该属性则返回值XXX
3、__CSVRead:从CSV文件中读取字符串。有两个参数:文件名,第几列(0表示第一列)
4、${__UUID}:随机取值,且结果唯一;区别于__Random(随机取值,结果有可能相同)
四、创建CSV Data Set Config
1、创建:添加->配置元件->CSV Data Set Config
2、作用:可以从.csv、.dat等文件中获取数据,并将这些数据参数化。当数据发生变化时,只需要改原始文件,不需要改脚本
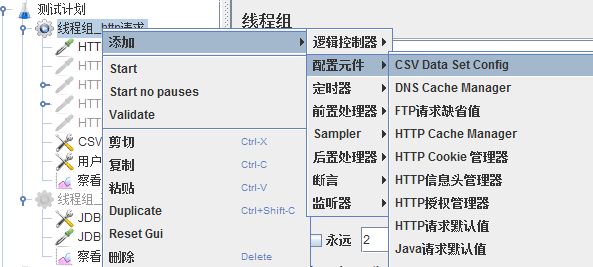
3、参数含义
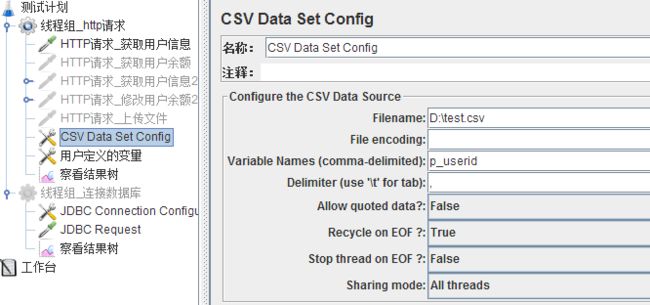
1)Filename:文件路径(如果和脚本同路径,只需要输入文件名;否则要输入全路径)
2)File encoding:编码和文件格式保持一致,如果有中文,最好用UTF-8
3)Variable names:参数名称,参数之间用,隔开
4)Delimiter:输入文件(csv/dat等)中的分割符号;用\t代替tab键
5)Allow quoted data:当获取的数据中包含"时,要设置为True
6)Recycle on EOF: 设置为True后,允许循环取值
7)Stop Thread EOF: 当Recycle on EOF为false并且Stop Thread EOF 为true,则读完csv文件中的记录后,停止运行,线程数及执行次数无效
8)Sharing Mode:共享模式: All threads:所有线程,所有线程循环取值,线程1取第一行,线程二取下一行;Current thread group:当前线程组,各个线程组分别循环取值;Current thread:该测试计划内的所有线程都取第一行
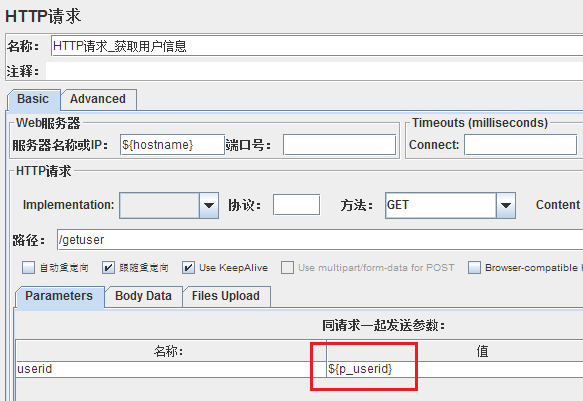
4、调用CSV Data Set Config中的变量
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取
