数据权限-字段权限【实践篇-结合相关业务详细讲解如何实现】(基于若依框架)
理论看这个
https://blog.csdn.net/weixin_41842550/article/details/119890216
这里写目录标题
-
- 按照部门结构和用户数据来实现数据权限
-
- 一 需要的基础数据
-
- 1 系统管理--部门管理--增加如下结构
- 2 系统管理--角色管理--增加两个角色
- 3 系统管理--用户管理--增加7个用户
- 二 截图和代码实现如下
-
- 1 建表
- 2 系统的BaseEntity
- 3 entity文件
- 4 xml文件
- 5 mapper文件
- 6 service和impl文件
- 7 controller文件
- 三 验证数据权限
-
- 1 部门基础数据如下
- 2 ask表基础数据
- 3 没加数据权限的数据
- 4 张三的数据
- 5 部门A经理的数据
- 6 部门A-员工1的数据
- 扩展-字段权限思路
-
-
- 1 字段信息表
- 2 和角色挂钩
- 3 动态拼接
-
按照部门结构和用户数据来实现数据权限
普通员工只能看自己的请假数据,领导可以看自己及自己所在部门所有员工的请假数据
这里以请假为例,其实只要是符合部门数据权限的任何业务数据均可以按照这个案例来实现
本篇采用电脑本地数据库mysql、本地启动java、本地启动vue。使用token来区别是否达到了数据权限,通过postman来调用接口测试
项目的端口上下文我都修改了
一 需要的基础数据
1 系统管理–部门管理–增加如下结构
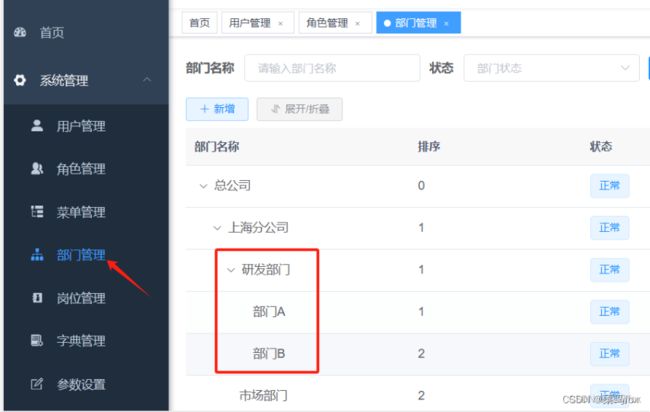
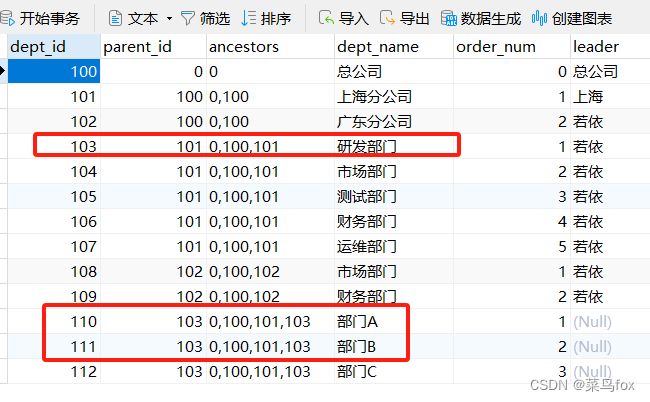
这里去数据库sys_dept表看一下dept_id,一会儿我们造假数据的时候用
ancestors是祖先dept_id多个逗号分开,有了这个字段就不用递归找了,效率提升了非常多
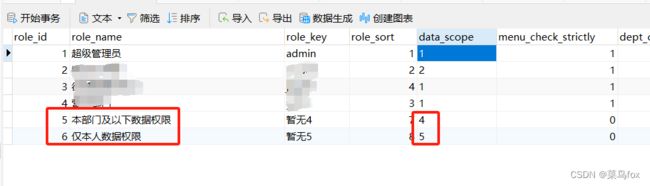
2 系统管理–角色管理–增加两个角色
4:本部门及以下数据权限;5:仅本人数据权限;【这两个均为系统保留的数据权限】
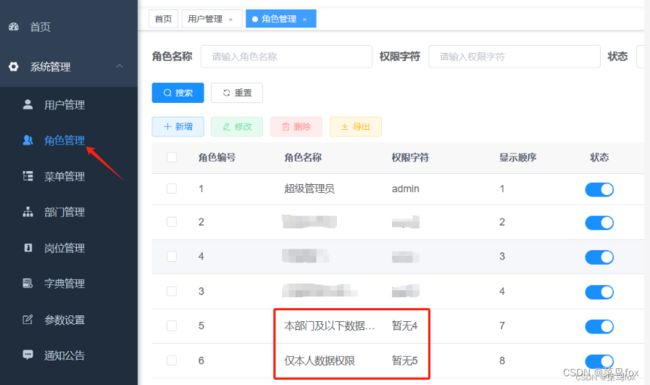
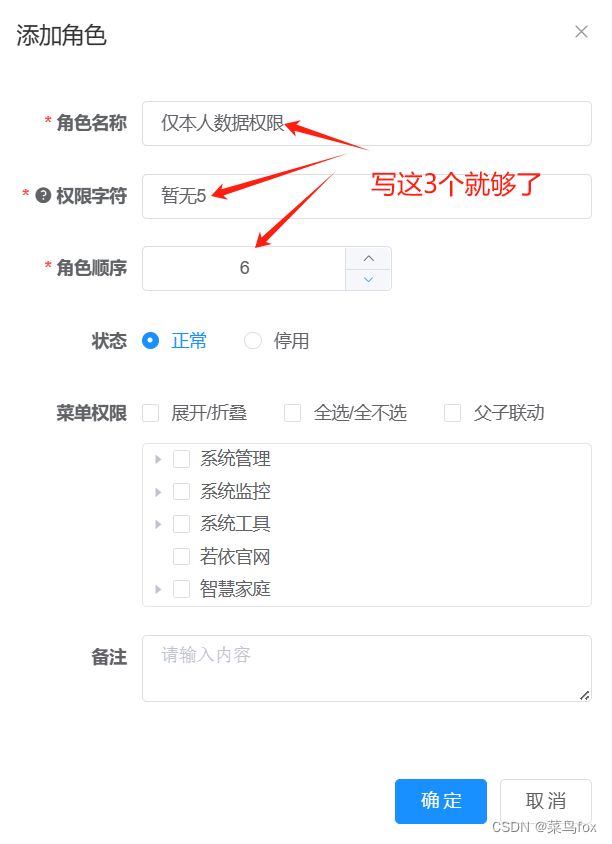
数据权限使用data_scope字段
data_scope字段不支持页面修改,需要自己手动改数据库
role key是菜单按钮权限,不建议和数据权限混着用。这里随便写
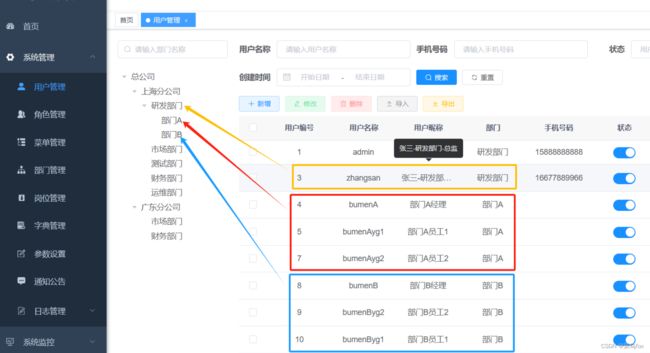
3 系统管理–用户管理–增加7个用户
张三–研发部门-总监:可以看到部门及以下的所有人的数据
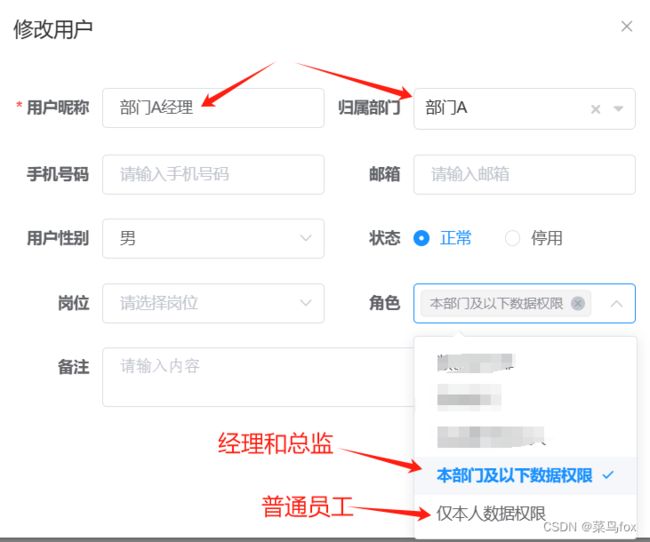
部门A经理:可以看到部门A及以下的所有人的数据,看不到总监-张三的数据(部门选部门A;角色选本部门及以下数据权限)
部门A员工1:部门选部门A;角色仅本人数据权限
部门A员工2:部门选部门A;角色仅本人数据权限
部门B经理:可以看到部门B及以下的所有人的数据,看不到总监-张三的数据(部门选部门B;角色选本部门及以下数据权限)
部门B员工1:部门选部门B;角色仅本人数据权限
部门B员工2:部门选部门B;角色仅本人数据权限
新增的时候选好对应的部门和角色
新增这里密码设置的简单些,一会需要登录拿token来验证,截图是修改
二 截图和代码实现如下
我这里方便演示就放到了SysConfigController及一系列service、mapper文件里面了
1 建表

CREATE TABLE `ask` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL COMMENT '请假标题',
`dept_id` int(11) DEFAULT NULL COMMENT '部门id',
`user_id` int(11) DEFAULT NULL COMMENT '用户id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
其他业务同理,只要加上dept_id和user_id就可以实现本人数据权限和部门数据权限
2 系统的BaseEntity

3 entity文件
这里需要继承BaseEntity,数据权限的sql片段就在BaseEntity里面的params属性中
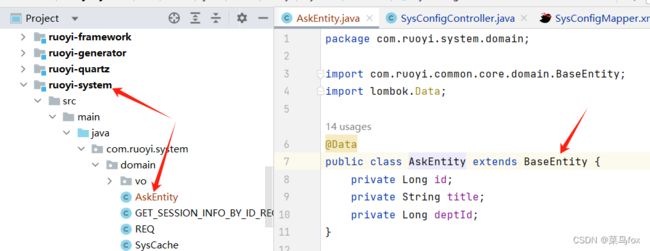
package com.ruoyi.system.domain;
import com.ruoyi.common.core.domain.BaseEntity;
import lombok.Data;
@Data
public class AskEntity extends BaseEntity {
private Long id;
private String title;
private Long deptId;
private Long userId;
}
4 xml文件
<select id="selectAskList" parameterType="com.ruoyi.system.domain.AskEntity" resultType="com.ruoyi.system.domain.AskEntity">
select * from ask where 1=1 ${params.dataScope}
</select>
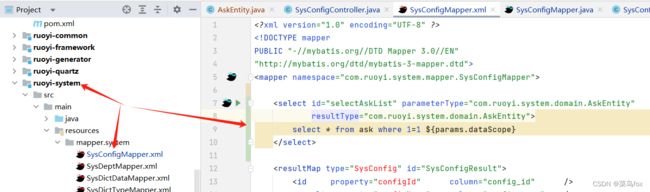
5 mapper文件
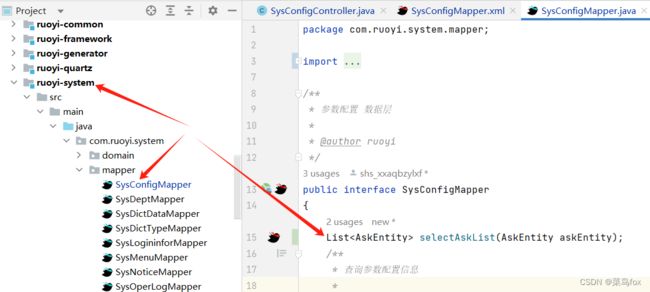
需要引入的包路径
import com.ruoyi.system.domain.AskEntity;
List<AskEntity> selectAskList(AskEntity askEntity);
6 service和impl文件
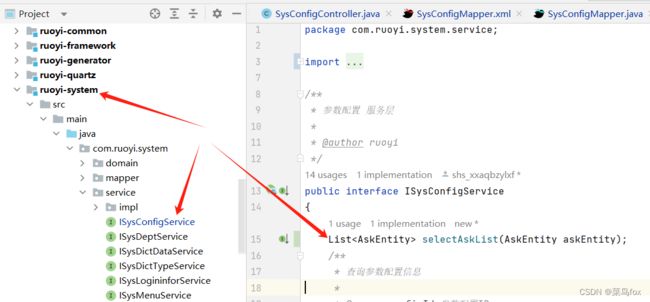
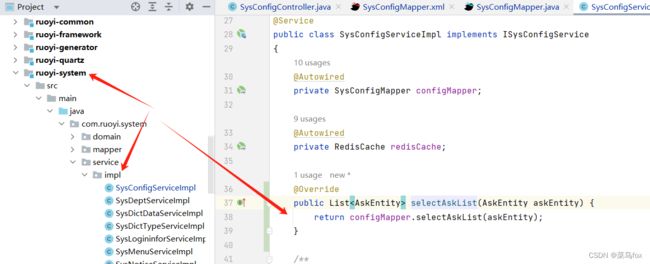
List<AskEntity> selectAskList(AskEntity askEntity);
@Override
public List<AskEntity> selectAskList(AskEntity askEntity) {
return configMapper.selectAskList(askEntity);
}
7 controller文件
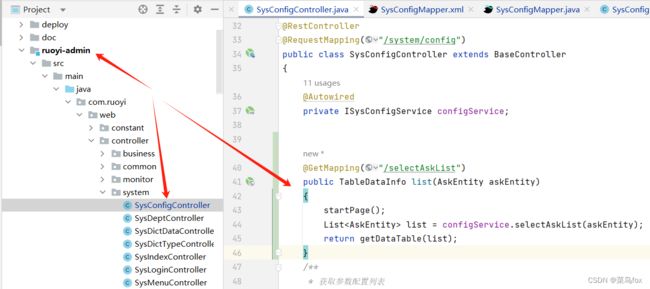
@GetMapping("/selectAskList")
public TableDataInfo list(AskEntity askEntity)
{
startPage();
List<AskEntity> list = configService.selectAskList(askEntity);
return getDataTable(list);
}
三 验证数据权限
增加对应的数据,这里dept_id和user_id我就直接写死在数据库了,理论上来说是需要在新增某些业务数据的时候把dept_id设置进去
import com.ruoyi.common.utils.SecurityUtils;
代码获取deptId,前提是用户列表已经配置好部门了
Long deptId = SecurityUtils.getLoginUser().getDeptId();
Long userId = SecurityUtils.getLoginUser().getUserId();
1 部门基础数据如下
dept_id dept_name
103 研发部门
110 部门A
111 部门B
2 ask表基础数据
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (1, '研发部门-总监-张三请假', 103, 3);
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (2, '部门A-经理请假', 110, 4);
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (3, '部门B-经理请假', 111, 8);
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (4, '部门A-员工1请假', 110, 5);
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (5, '部门A-员工2请假', 110, 6);
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (6, '部门B-员工1请假', 111, 10);
INSERT INTO `ruoyi`.`ask` (`id`, `title`, `dept_id`, `user_id`) VALUES (7, '部门B-员工2请假', 111, 9);

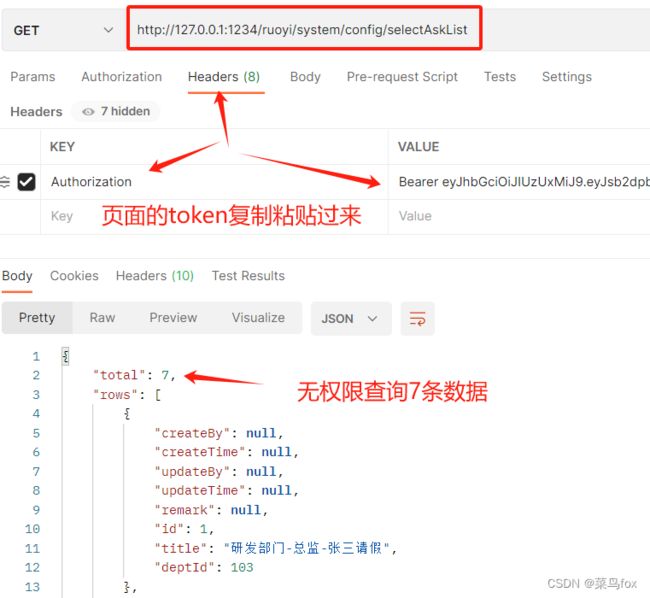
3 没加数据权限的数据
谁便找个接口,请求头里面的Authorization就是token

postman调佣接口,上面的token复制过来
没加数据权限有7条数据
4 张三的数据
这里稍微改一下之前的代码,xml里面的表增加了别名ask
<select id="selectAskList" parameterType="com.ruoyi.system.domain.AskEntity"
resultType="com.ruoyi.system.domain.AskEntity">
select * from ask as ask
where 1=1
${params.dataScope}
</select>
ServiceImpl累里面增加了数据权限的注解
@DataScope(deptAlias = "ask", userAlias = "ask")
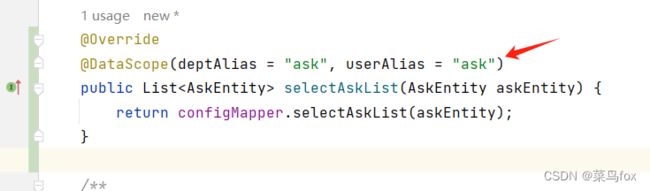
使用张三的token查询数据

打印的sql如下
SELECT
*
FROM
ask AS ask
WHERE
1 = 1
AND (
ask.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = 103 OR find_in_set( 103, ancestors ) )
)
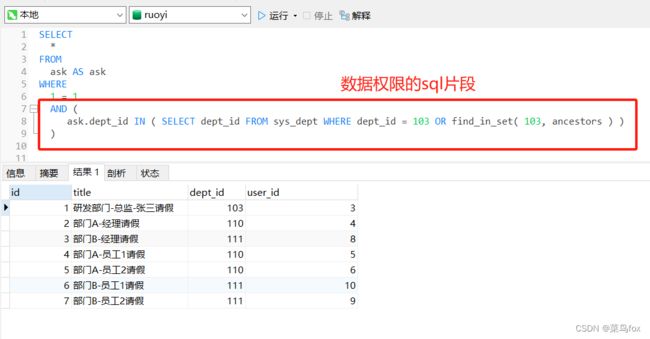
主要是查了部门表
dept_id = 103【dept_id103代表研发部门的id,也就是自己的数据】
find_in_set( 103, ancestors )【祖先dept_id有103研发部门的,也就是103部门下面的所有子级的部门】这里的祖先id设计的非常巧妙,真的不用递归就能实现一棵树的向下查询
5 部门A经理的数据
同理如上

sql如下,其实就是dept_id 不一样了
SELECT
*
FROM
ask AS ask
WHERE
1 = 1
AND (
ask.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = 110 OR find_in_set( 110, ancestors ) )
)

6 部门A-员工1的数据
同理如上
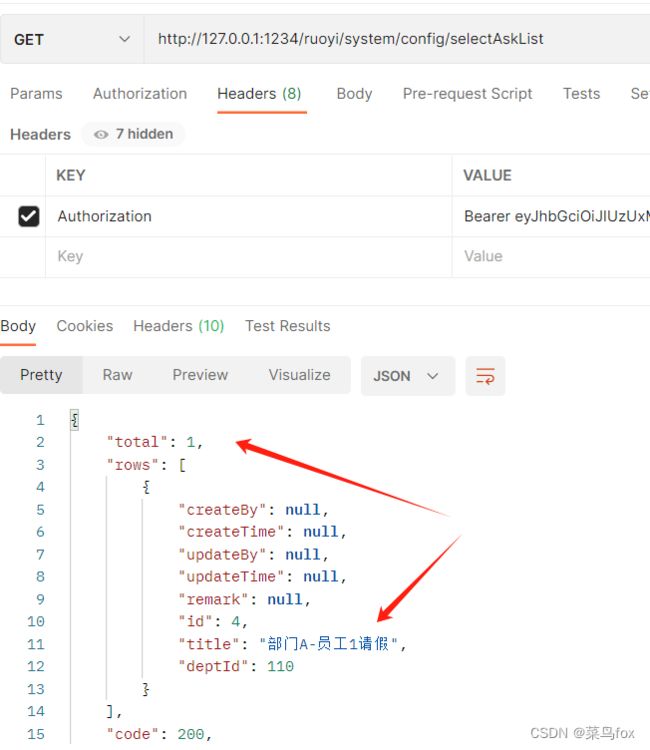
select * from ask as ask where 1=1 AND (ask.user_id = 5 )
这个sql就比较简单了,就查了一个user_id 为自己的
部门B-员工2 的数据也是同理,换一下user_id就行
扩展-字段权限思路
基于数据权限的基础,实现字段权限就非常简单了
比如经理可以查看10个字段,普通员工查看5个字段
1 字段信息表
首先得有一个字段信息表,用来维护需要做字段权限的表的字段信息
CREATE TABLE `sys_field` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`table_name` varchar(255) DEFAULT NULL COMMENT '表名字英文',
`table_remark` varchar(255) DEFAULT NULL COMMENT '表备注中文',
`field_list` varchar(2000) DEFAULT NULL COMMENT '字段信息',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;

field_list里面最好放一个数组,里面有多个对象,每个对象都是一个字段信息。这个信息可以做一个页面来增删改查,也可以有开发人员自己维护
[{"field":"title","remark":"请假标题"},{"field":"center","remark":"请假内容"},{"field":"f3","remark":"字段3"},{"field":"f4","remark":"字段4"}]

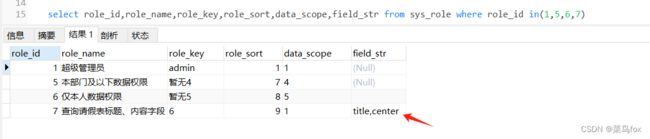
2 和角色挂钩
角色表新增一个字段field_str用来存放需要查询的字段,最好是一个角色一组字段字符串信息
新增角色的时候可以增加一个选取字段的多选框或者多选的下拉框,具体的值就是刚才的field_list里面的多个对象的field字段的值。选好后最终存储到角色表的field_str多个逗号分开
3 动态拼接
还是利用AOP来实现动态组装字段,存放到map里面去
通过注解来决定那些查询需要动态字段
mapper.xml文件里面再拿出来就可以了