【论文阅读】PC-GAIN: Pseudo-label Conditional Generative Adversarial Imputation Networks for Incomplete Da
论文地址;[2011.07770] PC-GAIN: Pseudo-label Conditional Generative Adversarial Imputation Networks for Incomplete Data (arxiv.org)

摘要
有缺失值的数据集在实际应用程序中非常常见。GAIN是最近提出的用于缺失数据插补的深度生成模型,已被证明优于许多最先进的方法。但GAIN仅使用生成器中的重构损耗来最小化非缺失部分的插补误差,忽略了可以反映样本之间关系的潜在类别信息。本文提出了一种名为PC-GAIN的无监督缺失数据插补方法,该方法利用潜在的类别信息进一步增强了插补能力。具体来说,我们首先提出了一个预训练程序,以学习包含在低缺失率数据子集中的潜在类别信息。然后使用合成伪标签确定辅助分类器。此外,该分类器被整合到生成对抗框架中,以帮助生成器产生更高质量的插补结果。所提方法可显著提高GAIN的插补质量。在各种基准数据集上的实验结果表明,我们的方法也优于其他基线方法。
引言
有大量关于缺失数据插补的文献。这些文献主要可分为两类:判别模型和生成模型。具有最先进性能的判别模型的例子包括MICE(van Buuren&Groothuis-Oudshoorn,2011),MissForest(Buhlmann,2012)和Matrix Complete(Mazumder,Hastie,& Tibshirani,2009)。与判别模型相比,生成模型通常更擅长获取缺失数据中的复杂非线性相关性。基于高斯混合假设的EM算法(Garíca-Laencina等人,2010)是一种经典的生成模型。近年来,深度生成模型的进步使得显着提高插补结果的质量成为可能,例如Abiri等人(2019),Gondara和Wang(2017),Spinelli,Scardapane和Uncini(2020),Tran,Liu,Zhou和Jin(2017)以及Xu和Veeramachaneni(2018)。特别是,Yoon等人。Yoon,Jordon和Schaar(2018)提出了一种用于缺失数据插补的生成对抗插补网络(GAIN),其中生成器输出一个以实际观察到的内容为条件的完整向量,判别器试图确定已完成数据中的哪些数据为观察值以及哪些数据为插补值。GAIN已被证明优于许多最先进的插补模型。但是,请注意,在GAIN(Yoon等人,2018)的框架内,仅在生成器中使用重建损耗以最小化非缺失部分的插补误差。众所周知,许多现实生活中的数据集都包含与潜在特征分布密切相关的潜在类别信息。将此类信息整合到GAN的框架中可以进一步提高模型的性能(Liu,Wang,Bau,Zhu和Torralba,2020;Lucic et al., 2019;Sage, Agustsson, Timofte, & Gool, 2018)。
在本文中,我们旨在利用不完整数据中包含的隐式类别信息,并开发一种新的伪标签条件GAN(PC-GAIN)以提高GAIN的插补质量(Yoon等人,2018)。我们方法的起点很简单。具体来说,我们首先选择低缺失率样本的子集,使用原始GAIN执行预训练,然后通过应用聚类算法合成它们的伪标签。仅使用低缺失率数据的子集对于确保伪标签的质量至关重要,并且对模型的性能具有至关重要的影响(第4.3节)。然后,根据这些插补样本和相应的伪标签确定辅助分类器。此外,分类器被合并到生成对抗框架中,以帮助生成器产生难以区分的插补结果,同时保留更好的类别信息。我们在具有各种缺失率的UCI和MNIST数据集上评估PC-GAIN。实验结果表明,我们的PC-GAIN优于包括GAIN在内的基本算法,特别是在缺失率较高的情况下。
本工作的主要贡献总结如下:
(1) 我们提出了一种新的条件生成对抗网络,它利用不完整数据中包含的隐式类别信息来进一步提高GAIN的插补质量(Yoon等人,2018)。
(2) 我们设计了一种高效的预训练程序,仅选择一部分低缺失率样本来执行插补,从而提高伪标签的质量。
(3) 辅助分类器与判别器一起旨在帮助生成器产生难以区分的插补结果,同时保留更好地类别信息。
(4) 事实表明,我们的方法在插补和预测准确性方面都优于最先进的方法,特别是当缺失率很高时。此外,无论类别的实际数量如何,选择较小的聚类数都可以确保模型在实践中的最佳性能,这一属性使方法更加灵活。
有三种类型的缺失机制(Little & Rubin, 2019):(1)完全随机缺失(MCAR);(2)随机缺失(MAR),其中数据项缺失的倾向与观测到的数据有关;(3)非随机缺失(MNAR),其中由于某些底层机制而缺失数据项。与Mottini等人(2018),Spinelli等人(2020),Yoon等人(2018)一样,我们考虑了本文中完全随机缺失(MCAR)的数据。这表明缺失是由意外的外部因素或测量系统的控制引起的。


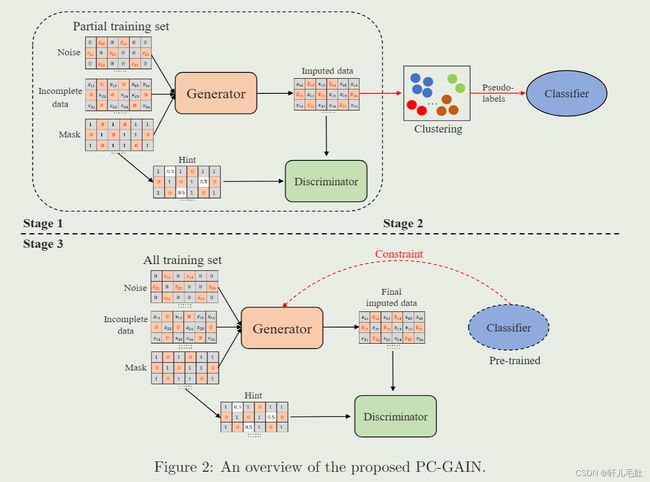

实验
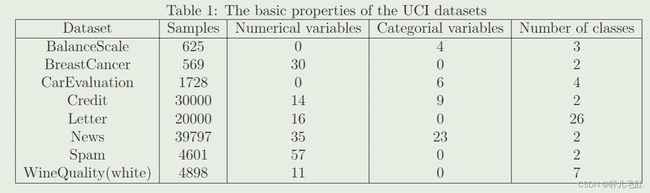
该表格为测试PC-GAIN模型能力的六个来自UCI的数据集,实际实验中还包括MNIST数据集。由于这些数据集不包含缺失数据,所以我们给定缺失率将数据集中的数据随机完全缺失。我们将PC-GAIN和自动编码器(Autoencoder),最大期望(EM),MissForest,MICE和GAIN进行比较。MissForest和MICE属于判别模型,Autoencoder,EM和GAIN属于生成模型。为了将PC-GAIN和GAIN进行比较,我们采用相同的生成对抗网络构架。实验中采用五倍交叉验证,每个实验重复十遍得到平均值。
除非额外说明,实验中的数据采用50%缺失率,权重参数选取α=200,β=20,K=5,对于Credit,Letter,News采用λ=0.2,对于其他取λ=0.4。
在我们的PC-GAIN中,辅助分类器使用一个三层的全连接网络,采用ReLU激活函数,每个隐藏层的神经元数量与输入数据的维数相同。在UCI数据集上,采用KMeans++聚类插补结果;在MNIST数据集上,采用KMeans++聚类潜在特征空间。
KMeans:容易受初始质心的影响
1.从样本中选择k个点作为初始质心(完全随机)
2.计算每个样本到各个质心的距离,将样本划分到距离最近的质心所对应的簇中
3.计算每个簇内所有样本的均值,并使用该均值更新簇的质心
4.重复2,3,直至达到以下条件之一:质心的位置变化小于指定阈值/达到最大迭代次数
KMeans++:算法受初始质心影响较小
1.从样本中选择1个点作为初始质心(完全随机)
2.对于任意一个非质心样本x,计算x与现有最近质心距离D(x)
3.基于距离计算概率,来选择下一个质心 x,选择距离当前质心远的点作为质心
4.重复步骤 2 与 3 ,直到选择 k个质心为止

该表为不同模型在不同数据集上的均方根误差(RMSE),除了在WineQuality上不如MICE,PC-GAIN在其他数据集上表现最佳。
均方根误差计算
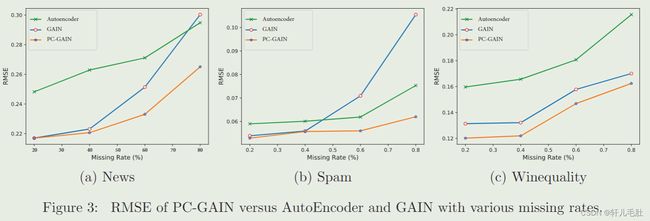
如图为在不同数据缺失率下Autoencoder,GAIN和PC-GAIN的均方根误差,这也体现了PC-GAIN的良好表现。特别是在数据缺失率提高的时候,该模型的优势就显得更为明显。
分类准确度计算
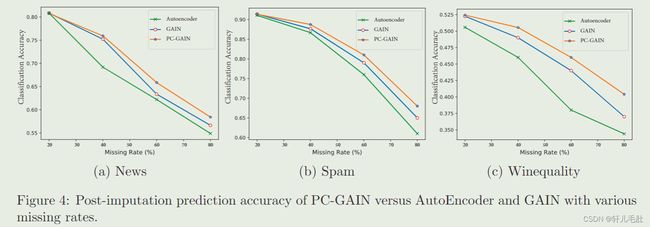
如图为三种模型对于数据分类的表现。我们采用相同的分类器(两层全连接网络,采用Softmax激活函数),考察插入后预测的准确度。可以看到PC-GAIN有最高的分类准确度。
灵敏度分析
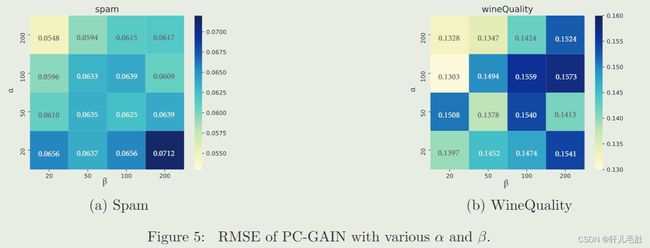
如图为不同α和β下PC-GAIN的均方根误差。相较于α,较小的β可以生成更好的结果。这表明在PC-GAIN中,分类器损失比判别器对于插补质量的影响更强。
在预训练阶段,比例系数λ控制预训练选取数据。
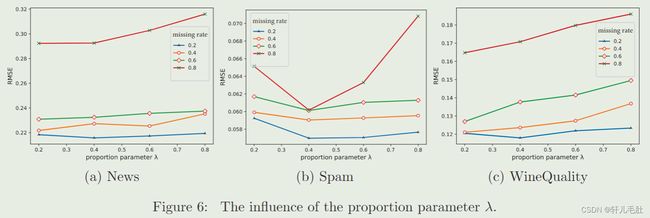
如图为不同比例系数λ和不同缺失率影响下模型的均方根误差。表明λ对于插补质量有决定性作用。当λ变得过大时,PC-GAIN的表现很快变坏。这可能是因为过多不完整数据可能会增加伪标签的不可靠性,从而降低插补质量。我们还发现在UCI数据集中理想的λ小于0.4.
聚类个数的影响
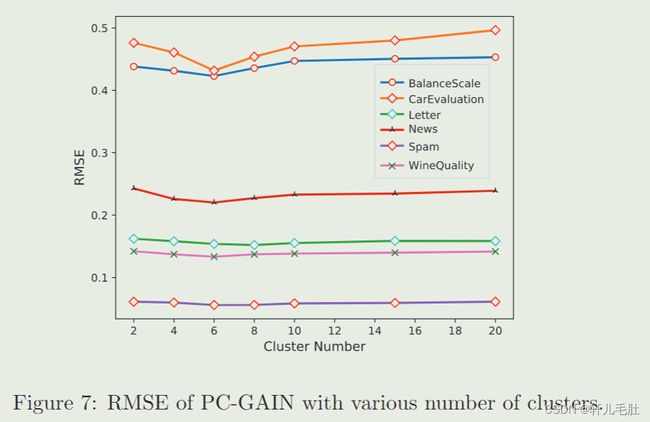
如图为在不同聚类个数下不同数据集的均方根误差。这表明不管真实分类有几个,PC-GAIN在K在4-8之间结果最好。
分析最终插补结果和分类与聚类方法的关系
采用如下分类方法:多分类支持向量机(multiclass SVM),完全训练的神经网络分类器,不完全训练的神经网络分类器和未训练的神经网络分类器。聚类方法包括:KM(KMeans),SC(SpectralClustering),KMPP(KMeans++)和AC(AgglomerativeClustering)。并用Ca(方差比准则)和Si(轮廓系数)分别测量不同聚类的质量。
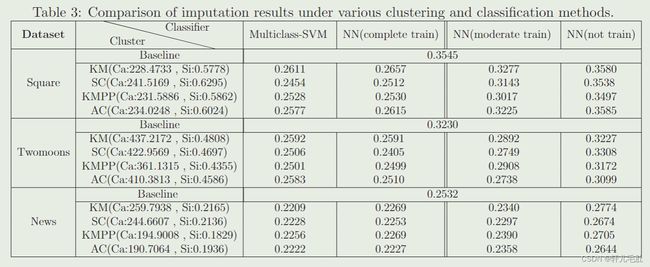
该表格展示了在不同聚类和分类方法下两个玩具数据集和真实UCI数据集的均方根误差结果。其中baseline使用的时原始的GAIN。由最后三列可以看出:随着分类器训练的增加,其监督插补网络的能力也逐渐提高。
图像修补
利用PC-GAIN对图像进行插补。我们选取MNIST手写数据集,分别移除50%和80%的像素点,进过插补之后计算FID至评估由生成对抗网络生成的图像质量(较低的分数与较高质量的图像有很高的相关性)。


图8和图9展示了在50%和80%缺失率下生成的图片。可以看出由PC-GAIN得到的FID值更小,图片形状更为平滑。
结论
基于Yoon等人(2018)的最新工作,我们提出了一种名为PC-GAIN的新型生成模型,用于缺失数据插补。借助辅助分类器(该分类器已使用低缺失率样本子集和相应的伪标签进行预训练),生成器尝试生成具有明显分类特征的难以区分的插补结果。值得注意的是,该分类器在生成对抗网络训练过程中始终是固定的,因此所提出的方法易于实现。总的来说,PC-GAIN可以被视为GAIN的改进版本(Yoon等人,2018),它在不使用任何监督的情况下显着提高了原始模型的性能,特别是在高缺失率下。
PC-GAIN的关键是利用缺失数据中包含的潜在类别信息来增强插补结果。这个新颖的想法非常通用,可以应用于其他现有的框架,只要能够准确捕获潜在的类别信息。然而,与传统和其他深度学习方法相比,我们的框架中需要额外的预训练步骤,这需要在训练过程中花费更多的时间,并且有更多超参数需要调整。
虽然我们在本文中只关注随机完全缺失(MCAR)案例,但我们的方法可以扩展到处理随机缺失(MAR)和非随机缺失(MNAR)机制。请注意,所选的预训练子集对伪标签的质量有重要影响,从而影响插补结果。对于随机缺失(MAR),我们仍然可以预先训练一些低缺失率的数据,以确保伪标签的质量。但是,对于非随机缺失(MNAR)来说,简单地选择一个缺失度低的子集并不是一个好主意,这可能会导致选择偏差并降低伪标签的准确性。应根据相应的缺失机制选择更合适的预训练子集。将PC-GAIN的主要思想应用于其他框架来处理非随机缺失(MNAR)问题将是一项有意义的工作。