性能提升30%以上,实时实例分割算法SOLOv2实现产业SOTA
点击左上方蓝字关注我们

如何兼顾目标检测和语义分割的能力,并实现大幅性能提升?本文介绍了产业 SOTA 的实时实例分割算法 SOLOv2。
目标检测无法精细获得目标边界形状和面积,语义分割无法区分不同目标个体,并分别获得位置。小伙伴们可能会疑惑,以上动图展示的实例分割效果显然兼具了目标检测和语义分割二者的能力,是通过什么技术实现的呢?
下面给大家介绍的这类相当牛气的方法:实时实例分割算法 SOLOv2!

SOLOv2 算法可以按位置分割物体,完成实例分割任务,同时还兼具实时性。由于其出色地兼顾了精度和速度,已经被广泛应用于自动驾驶、机器人抓取控制、医疗影像分割、工业质检和遥感图像分析等领域。
相较于目标检测和语义分割,实例分割算法的构建和训练难度是非常复杂、且具有挑战性的。如果要同时兼顾精度和速度,难度又上了一个台阶。不过莫慌,本文不仅为大家准备了极其干货的实力分割算法原理和优化方法讲解,还为大家准备了产业 SOTA 的实例分割算法在「实现机器人抓取」和「工业质检」这两个产业实践中的案例解析。
惊不惊喜?意不意外?值不值得关注、学习以及 Star?<(罒ω罒)>
着急的小伙伴可以 Github 传送门直接走起:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/0.5/configs/solov2
也可以加入 SOLOv2 技术交流群,与业界开发者一同交流学习。


从文章开篇的动图里我们可以看到,算法可以同时检测并精细分割不同快速移动的球员个体。而这个算法,使用的是 PaddleDetection 研发团队深度优化过的实时实例分割算法 SOLOv2。经过一系列的优化后,SOLOv2-Enhance(PaddleDetection 提供的 SOLOv2 的增强模型,如图五角星所示)的性能表现如下图所示:
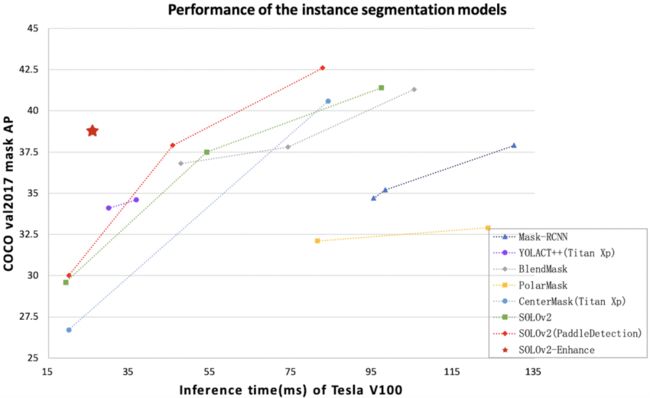
Tesla V100-SXM2 的单 GPU 环境中预测速度达到 38.6FPS,提升了 31.2%;
COCO val2017 数据集上 mask AP 达到 38.8%,提升 2.4 个百分点;
单机 8 卡训练速度是 SOLOv2 官方 PyTorch 版本的 2.4 倍;
在精度和预测速度性价比方面达到业界 SOTA 级别。
PaddleDetection 提供的 SOLOv2 为何有如此优势呢?下面从实例分割算法、SOLO 算法演进历程及 PaddleDetection 对于 SOLOv2 深度优化等几方面为大家逐层剖析背后的设计和实现思想。
实例分割算法
实例分割一般分为自上而下和自下而上两种方法。
自上而下的实例分割方法
简单地说,这种方法就是先检测后分割。这类方法的代表选手是 Mask R-CNN。它的优点是定位精度高,但也有一定的局限,比如:预测时延高,达不到实时,实例分割结果在物体检测框的束缚下等。
业界很多大神都在持续尝试基于 Mask R-CNN 算法进行改进,希望解决上述局限问题,GCNet、PANet、HTC、DetectoRS 等网络就是在 Mask R-CNN 算法上优化、演进而来的。但是预测速度慢的问题仍得不到解决。
第一类可以被称为实时的实例分割的模型是 YOLACT 和 YOLACT++,它们基于 RetainNet,将实例分割分为两个并行的子任务,采用单阶段的网络结构,使网络计算量尽量小,后者训练 54 个 epoch 左右,最终在 COCO test-dev 数据集上的 mask AP 达到 34.6%,在 Titan Xp 的 GPU 环境中达到 27.3~33.5FPS。
而 CenterMask 算法则基于 Anchor Free 模型 FCOS 更进一步提升了实例分割的精度和速度,改进了 backbone,提出 VoVNetV2,同时基于 Mask R-CNN 的 mask 分支,引入 Spatial Attention-Guided Mask(空间注意力模块),实时的 CenterMask-Lite 模型在 COCO Test-dev 数据集上的 mask AP 达到 36.3%,在 Titan Xp 的 GPU 环境中达到 35.7FPS,成为新的 SOTA 模型。
自下而上的实例分割方法
这类方法比较好理解,先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。PolarMask、SOLO 系列算法就是其中的代表。
PolarMask 基于 FCOS 的思想,将回归到检测框四边的距离问题转换为回归基于中心点不同角度的 36 根射线的距离问题,通过联通整个区域获得分割结果。这种方法创新性很高,但问题也很明显,如:通过角点确定分割区域的方法不够准确,mask AP 较低,预测速度也很慢。
而 SOLO 系列算法经过不断的优化,在精度和预测速度的性价比方面均超越了 YOLACT++ 和 CenterMask 算法,下面我们就着重介绍一下 SOLO 系列算法的发展历程及 PaddleDetection 针对 SOLOv2 算法进行的优化。
SOLO 算法发展历程
SOLO(Segmenting Objects by Locations)算法的核心思想是将分割问题转化为位置分类问题,从而做到不需要 anchor(锚框)及 bounding box,而是根据实例的位置和大小,对每个实例的像素点赋予一个类别从而达到对实例对象进行分割的效果。
具体而言,就是如果物体的中心落在了某个网格内,该网格就负责预测该物体的语义类别,并给每个像素点赋一个位置类别。
SOLOv1
在 SOLOv1 中有两个分支:类别分支和 mask 分支。类别分支预测语义类别;mask 分支则分割物体实例。同时,使用 FPN 来支持多尺度预测,FPN 的每一个特征图后都接上述两个并行的分支。
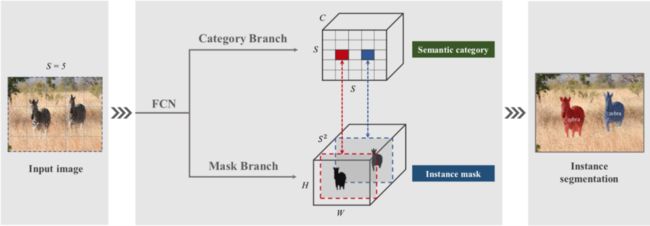
来自论文《SOLO: Segmenting Objects by Locations》
其中,类别分支负责预测物体的语义类别,共产出 S×S×C 大小的预测结果。Mask 分支中每个有类别输出的网格(正样本)都会输出对应类别的 mask,这里一个通道负责预测一个网格的 mask,因此输出维度是 H×W×S2。同时基于 SOLOv1,作者又提出了 Decoupled-SOLO 改进算法,将 S2 个分类器解耦为两组分类器,每组 S 个,分别对应 S 个水平位置类别和 S 个垂直位置类别,优化之后的输出空间就从 H×W×S2 降低到了 H×W×2S,从而降低了网络计算量,如下图 (b) 所示,最后将两个通道的特征图做 element-wise 乘,进行特征的融合。
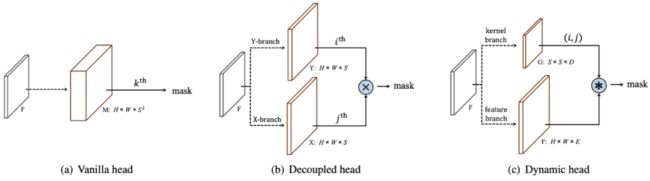
来自论文《SOLOv2: Dynamic and Fast Instance Segmentation》
SOLOv2
SOLOv2 继承了 SOLOv1 中的一些设定,将原来的 mask 分支解耦为 mask 核分支和 mask 特征分支,分别预测卷积核和卷积特征,如上图 (c) 中的 Dynamic head 所示。
输入为 H×W×E 的特征,F、E 是输入特征的通道数,输出为卷积核 S×S×D,其中 S 是划分的网格数目。
Mask 核分支位于预测 head 内,平行的有语义类别分支。预测 head 的输入是 FPN 输出的特征图。Head 内的 2 个分支都有 4 个卷积层来提取特征,和 1 个最终的卷积层做预测。Head 的权重在不同的特征图层级上共享。同时作者在 kernel 分支上增加了空间性,做法是在第一个卷积内加入了 CoordConv,即输入后面跟着两个额外的通道,操作如下图所示。
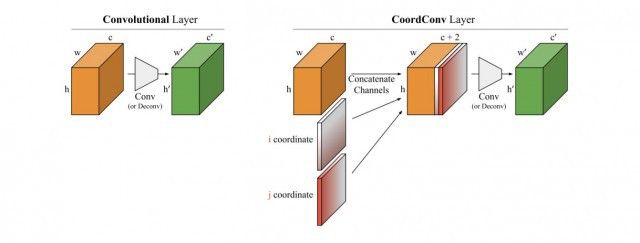
来自论文《An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution》
我们知道深度学习里的卷积运算是具有平移不变性的,这样可以在图像的不同位置共享统一的卷积核参数,但是这样卷积学习过程中是不能感知当前特征在图像中的坐标的。CoordConv 就是通过在卷积的输入特征图中新增对应的通道来表征特征图像素点的坐标,让卷积学习过程中能够一定程度感知坐标来提升检测精度。
同时 SOLOv2 也使用了 Matrix NMS,通过矩阵运算所有的操作都可以单阶段地实现,不需要递归,比传统的 NMS 快 9 倍。
经过以上的迭代,SOLOv2 成为当前产业最实用的实例分割算法。而飞桨 PaddleDetection 不仅复现了该模型,还对其进行了一系列的深度优化,使其精度和速度相较原网络有了进一步的提升。
PaddleDetection 中的 SOLOv2
经过 PaddleDetection 深度优化后的 SOLOv2 在具有如下五大亮点:
更优的骨干网络:ResNet50vd-DCN + 蒸馏
更稳定的训练方式:EMA、Sync-BN
更多的数据增强方法
更快的训练方式
多种部署方式
更优的骨干网络: ResNet50vd-DCN + 蒸馏
针对 SOLOv2,飞桨使用更加优异的 ResNet50vd-DCN 作为模型的骨干网络,它相比于原始的 ResNet,可以提高 1%-2% 的检测精度,且推理速度基本保持不变。
而 DCN(Deformable Convolution)可变形卷积的特点在于:其卷积核在每一个元素上额外增加了一个可学习的偏移参数。这样的卷积核在学习过程中可以调整卷积的感受野,从而能够更好的提取图像特征,以达到提升目标检测精度的目的,是一种引入极少计算量并提升模型精度的最佳策略。
进一步地,PaddleDetection 采用飞桨自研的 SSLD 知识蒸馏方法优化过的 ResNet50vd,在 ImageNet 上的 Top-1 分类精度从 79.1% 优化到 82.4%。感兴趣的同学可以到 PaddleClas 中了解 SSLD 知识蒸馏方案详情。
PaddleClas:
https://github.com/PaddlePaddle/paddleclas
SOLOv2 模型在使用了 ResNet50vd 的 SSLD 知识蒸馏之后更优的预训练权重进行训练后,COCO minival 数据集的精度提升了 1.4%(36.4%->37.8%)。在 V100 上的预测速度上,从 29.4FPS 提升至 38.6FPS。
更稳定的训练方式:EMA、Sync-BN
飞桨团队采用了 EMA(Exponential Moving Average)滑动平均方案,将参数过去一段时间的均值作为新的参数,让参数学习过程中变得更加平缓,有效避免异常值对参数更新的影响,提升模型训练的收敛效果。实验发现,使用 EMA 后网络收敛速度明显加快。
一般情况下,Batch Norm 实现只会计算单卡上的均值和方差,相当于「减小了」批大小。SOLOv2 实际训练比较耗费显存,单卡的 batch size 较小,为 2。针对这种情况,我们引入了同步的 Batch Norm,即:Sync-BN,它可以统计全局的均值和方差,获得更稳定的统计值,相当于「增大了」批大小。
综上,通过训练过程中的指数滑动平均、Sync-BN 的 Trick,SOLOv2 模型又提升了 0.6%(37.8%->38.4%)。
更多的数据增强方法
在 SOLOv2 中除了采用空间变换(随机尺度变换、随机裁剪图片、随机翻转等)、颜色扭曲(透明度、亮度、饱和度等)、信息删除 (增加随机噪声、随机遮挡等) 等常用数据增强方法之外,还使用了一种新颖的信息删除方法:Grid-Mask 方法。

Grid-Mask 方法属于信息删除的方法。其实现方式是随机在图像上丢弃一块区域,作用相当于是在网络上增加一个正则项,避免网络过拟合,相比较改变网络结构来说,这种方法只需要在数据输入的时候进行增广,简单便捷。
经过数据增强之后,SOLOv2 模型在保持原有速度的情况下,精度又提升了 0.4%(38.4%->38.8%)。
更快的训练方式
而实际的训练过程往往是艰辛和漫长的,往往一次训练实验要耗费十几甚至几十个小时,PaddleDetection 在网络训练层面,针对损失函数 (loss) 计算进行了针对性的工程优化,从而加快了训练速度。
预取 Target: 在计算 loss 时,输入 ground truth 需要经过一定的映射转换,将此流程放到数据预处理中进行,因数据预处理和模型计算是异步进行,起到了预取的作用。
减少数据拷贝并 GPU 计算: 在官方 PyTorch 实现中,损失函数计算通过 Numpy 计算,在 PaddleDetection 中,由于飞桨框架提供了丰富算子,损失计算采用框架算子组合计算,不仅减少了数据的拷贝时间,还可以使用 GPU 计算加速。
Batch 计算: 在官方 PyTorch 实现版本中,Loss 计算时,循环计算每张图的损失,在 PaddleDetection 中,采用 batch 计算(比如 batch size=2,那么同时对 2 张图运算),加快了整体的训练速度。
采用飞桨分布式训练能力,在 8 卡 Tesla V100-SXM2 上,COCO 数据集上训练一个 SOLOv2-R50-1x 的模型,训练 12 个 epoch,只需要 10 小时就能完成。
多种部署方式
除了科研、学习使用外,PaddleDetection 还充分考虑了产业用户的需求,使 SOLOv2 支持多种环境、多种语言的预测方法,包括:
服务器端 Python 部署和 C++ 部署:多用于工业、互联网等拥有服务器、工控机的环境;
Paddle-Serving 服务部署:多用于希望进行云端部署的场景;
Paddle-Lite 轻量化部署:多用户在边缘、轻量化设备、国产芯片等进行部署的场景;
Windows 系统部署:充分考虑工业场景多为 windows 系统的现状。
优化前后的 SOLOv2 性能对比
经过网络优化后,SOLOv2 算法在 COCO minival 数据集上的 mask AP 达到 38.8%,在单张 Tesla V100 上单卡预测速度达到 38.6FPS。相比于原论文,精度提升 2.4%,预测速度提升 31.2%。
除此之外,PaddleDetection 还集成了基于 MobileNetv3 的轻量化模型,在最小输入尺寸 448 像素时,可以在 V100 上达到 50FPS,COCO val2017 数据集上 mask AP 达到 30.0%,预测速度进一步提升。实验具体数据指标如下表所示:

产业实践
如开篇所说,实例分割算法在产业中有非常广泛的应用场景,如:自动驾驶、机器人抓取控制、医疗影像分割、工业质检和遥感图像分析。下面我们就通过机器视觉导视和机械总院带钢表面缺陷检测两个案例,介绍下实例分割在产业中的应用。

机器视觉导视
2D 机械手抓取的思路往往是将算法提供的图像位置坐标信息转化为机械手的世界坐标,进而指导机械手实现抓取。实际的视觉导视里不仅需要了解目标的位置,还需要进一步了解目标的角度信息,因此实例分割逐渐被使用在了视觉导视中。
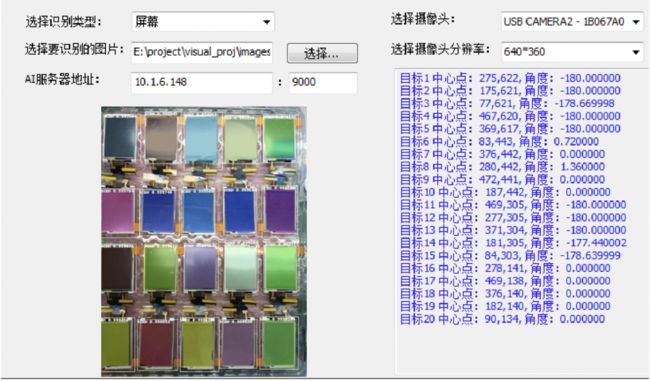
下面是利用机械手吸盘抓取屏幕实现自动化装配的案例图像。我们可以看到,单纯使用目标检测虽然可以得到坐标信息,但对于倾斜的产品的定位却很难做到精确,而使用 SOLOV2 实例分割,是可以精确的得到目标的轮廓信息。

再通过将 SOLOv2 输出得到的结果进行转化,将 Mat 图像转换成散点图坐标,得到整个点的位置坐标,根据产品的质心和轮廓点判断出经过计算传输给机械手较好的抓取坐标,进而实现精准抓取。
工业质检
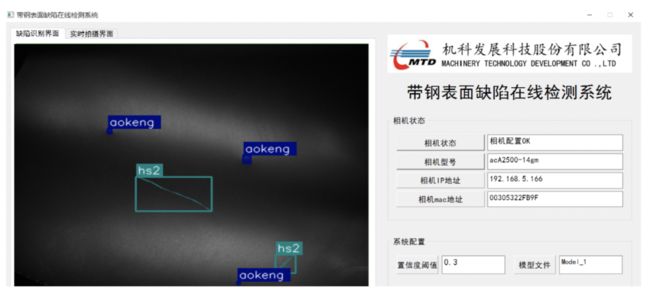
在工业质检中,要求标准精细化与出货灵活化,因此需要对缺陷的精细量化,让厂家更好的控制产品的良品率。比如在 A 产品上,5mm 的缺陷是 NG 产品;但是在 B 产品上,即使是 10mm 也属于 OK 产品。在工厂中产品有着严格的等级标准,质检人员通常使用菲林比对卡来看缺陷的大小。因此如果深度学习想要进一步的利用在缺陷检测中,不仅仅要实现对于缺陷的定性分析,也需要定量计算缺陷的大小。通过实例分割,可以实现对于缺陷的像素级别分割,通过单像素精度的换算可以算得缺陷的实际物理尺寸,进而配合质量标准进行产品管控。

实例分割算法就很好地实现对缺陷的位置及大小精确的捕捉量化,并且可以对缺陷类型进行分类。机械总院在带钢表面缺陷检测系统中采用 PaddleDetection 中提供的 SOLOv2 算法实现对于缺陷的识别和大小的计数,达到了良好的效果,在被生产监测系统集成后,直接推动产线质检效率、精度大幅度提升。
写到这里,你还不心动嘛!赶紧前往飞桨 PaddleDetection 项目地址,学习、试用吧!!!记得顺手帮我们点亮 Star 哦~
感兴趣的小伙伴也可以加入 SOLOv2 技术交流群,与业界开发者一同交流学习。
·飞桨PaddleDetection项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddleDetection
Gitee:
https://Gitee.com/PaddlePaddle/PaddleDetection
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。

扫描二维码 | 关注我们
微信号 : PaddleOpenSource
END
精彩活动
