3.HiveSQL
3.Hive SQL
3.1 官网介绍
http://hive.apache.org/


3.2 数据库实例操作
https://cwiki.apache.org/confluence/display/Hive/Language
Manual+DDL
3.2.1 Create Database
语法如下:
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES(property_name=property_value, ...)];
** 遇到报错:**
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
原因是node3上metastore服务未开启
hive --service metastore &
- node4上创建一个数据库实例
hive> create database hivedb1;
OK
Time taken: 1.254 seconds

- 再次创建hivedb1
hive> create database hivedb1;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database hivedb1 already exists
hive> create database if not exists hivedb1;
OK
Time taken: 0.036 seconds
if not exists:作用是如果该数据库实例已经存在则不存在,反之才创建。
在hive中创建的数据库实例在hdfs上默认被放在hive.metastore.warehouse.dir参数指定的hdfs路径下:
hive.metastore.warehouse.dir</name>
/user/hive_remote/warehouse</value>
</property>
3.2.2 查看数据库实例
show的使用
语法格式如下
SHOW DATABASES [LIKE ``'identifier_with_wildcards'``];
- 显示所有的数据库实例
- 查询数据库实例名称以hivedb开头
- 查询数据库实例名称包含hivedb
hive> show databases;
OK
default
hivedb1
hivedb2
Time taken: 0.028 seconds, Fetched: 3 row(s)
hive> show databases like 'hivedb*';
OK
hivedb1
hivedb2
Time taken: 0.092 seconds, Fetched: 2 row(s)
hive> show databases like '*hivedb*';
OK
hivedb1
hivedb2
Time taken: 0.032 seconds, Fetched: 2 row(s)
- 切换数据库use
hive> show tables;
OK
Time taken: 0.121 seconds
DESCRIBE的使用
语法如下,小写也能使用:
DESCRIBE DATABASE [EXTENDED] db_name;
或者
DESC DATABASE [EXTENDED] db_name;
使用方法:
hive> desc database hivedb1;
OK
hivedb1 hdfs://mycluster/user/hive_remote/warehouse/hivedb1.db root USER
Time taken: 0.051 seconds, Fetched: 1 row(s)
显示数据库实例的详细信息
hive> desc database extended hivedb1;
OK
hivedb1 hdfs://mycluster/user/hive_remote/warehouse/hivedb1.db root USER
Time taken: 0.043 seconds, Fetched: 1 row(s)
3.2.3 修改数据库
修改的语法:
alter database database_name set dbproperties
(property_name=property_value, ...);
通过如上命令修改数据库的属性,比如:
hive> alter database hivedb1 set dbproperties('createtime'='20231110');
OK
Time taken: 0.119 seconds
hive> desc database extended hivedb1;
OK
hivedb1 hdfs://mycluster/user/hive_remote/warehouse/hivedb1.db root USER {createtime=20231110}
Time taken: 0.091 seconds, Fetched: 1 row(s)
其他修改命令:
#修改数据的所有者,或所属角色
alter database database_name set owner [user|role] user_or_role;
#修改指定数据库实例在hdfs上位置
alter database database_name set location hdfs_path;
3.2.4 删除数据库
删除命令的语法格式:
drop database [if exists] database_name [restrict|cascade];
如果数据库实例中是空的,并且这数据库实例是存在的,如下进行删除:
hive> create database hivedb3;
OK
Time taken: 0.071 seconds
hive> drop database hivedb3;
OK
Time taken: 0.277 seconds
如果数据库是不存在的:
hive> drop database hivedb3;
FAILED: SemanticException [Error 10072]: Database does not exist: hivedb3
hive> drop database if exists hivedb3;
OK
Time taken: 0.082 seconds
如果数据库实例中有数据,可以采用cascade命令,可以强制删除
hive> use hivedb2;
OK
Time taken: 0.054 seconds
hive> show tables;
OK
Time taken: 0.075 seconds
hive> create table psn(id int,age int);
OK
Time taken: 0.943 seconds
hive> insert into psn values(1,10);
Query ID = root_20211109152742_b31ea667-363f49f8-94f9-476fba5794a8
Total jobs = 3
Launching Job 1 out of 3
......
hive> drop database hivedb2;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database hivedb2 is not empty. One or more tables exist.)
hive> drop database hivedb2 cascade;
OK
Time taken: 0.627 seconds
3.3 Hive数据类型
data_type
: primitive_type --基本数据类型
| array_type 数组
| map_type 键值对类型
| struct_type 结构体类型(类似于Java语言中的只有属性没有getters和setters方法的实体类)
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type --基本数据类型
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT
col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -
- (Note: Available in Hive 0.7.0 and later)
基本数据类型

复合数据类型

array字段的元素访问方式:
- 下标获取元素,下标从0开始
- 获取第一个元素:array[0]
map字段的元素访问方式
- 通过键获取值
- 获取a这个key对应的value:map[‘a’]
struct字段的元素获取方式
- 定义一个字段c的类型为struct{a int;b string}
- 获取a和b的值:使用c.a 和c.b 获取其中的元素值
- 这里可以把这种类型看成是一个对象
3.4 表基础知识
3.4.1 完整的DDL建表语法规则
create [temporary] [external] table [if not
exists] [db_name.]table_name
[(col_name data_type
[column_constraint_specification] [comment
col_comment], ... [constraint_specification])]
[comment table_comment] -- 表的注释
[partitioned by (col_name data_type [comment
col_comment], ...)] --分区
[clustered by (col_name, col_name, ...)
[sorted by (col_name [asc|desc], ...)] into
num_buckets buckets] 排序与分桶
[skewed by (col_name, col_name, ...)
on ((col_value, col_value, ...),
(col_value, col_value, ...), ...)
[stored as directories]
[
[row format row_format] -- 设置各种分隔符
[stored as file_format] --hdfs上存储时的文件格式
| stored by 'storage.handler.class.name'
[with serdeproperties (...)]
]
[location hdfs_path] --hdfs上的位置
[tblproperties (property_name=property_value,
...)] --表的属性
[as select_statement]; -- 查询子句
row_format
: delimited [fields terminated by char
[escaped by char]] [collection items terminated
by char]
[map keys terminated by char] [lines
terminated by char]
[null defined as char]
| serde serde_name [with serdeproperties
(property_name=property_value,
property_name=property_value, ...)]
file_format:
: sequencefile
| textfile
| rcfile
| orc
| parquet
| avro
| jsonfile
| inputformat input_format_classname
outputformat output_format_classname
column_constraint_specification:
: [ primary key|unique|not null|default
[default_value]|check [check_expression]
enable|disable novalidate rely/norely ]
default_value:
: [
literal|current_user()|current_date()|current_t
imestamp()|null ]
constraint_specification:
: [, primary key (col_name, ...) disable
novalidate rely/norely ]
[, primary key (col_name, ...) disable
novalidate rely/norely ]
[, constraint constraint_name foreign key
(col_name, ...) references table_name(col_name,
...) disable novalidate
[, constraint constraint_name unique
(col_name, ...) disable novalidate rely/norely
]
[, constraint constraint_name check
[check_expression] enable|disable novalidate
rely/norely ]
3.4.2 创建表
1,小明1,lol-book-movie,beijing:xisanqi-shanghai;pudong
create table person(
id int comment "唯一标识id",
name string comment "名称",
likes array comment "爱好",
address map,string> comment "地址"
)
row format delimited
fields terminated by "," 字段间分隔符
collection items terminated by "-" keyvalues中分隔符
map keys terminated by ":" map之间
lines terminated by "\n"; 换行之间
hive> create table person(
> id int comment "唯一标识id",
> name string comment "名称",
> likes array comment "爱好",
> address map,string> comment "地址"
> )
> row format delimited
> fields terminated by ","
> collection items terminated by "-"
> map keys terminated by ":"
> lines terminated by "\n";
OK
Time taken: 0.146 seconds
3.4.3 查看表描述信息
命令语法:
describe [extended|formatted] [db_name.]table_name
简写为:
desc [extended|formatted] [db_name.]table_name
实操演示:
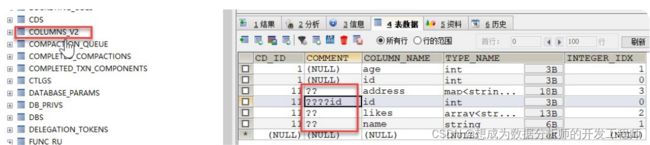
发现hive存在乱码问题
hive> desc formatted person;
OK
# col_name data_type comment
id int ????id
name string ??
likes array ??
address map,string> ??
乱码解决方案
检查hive_remote数据库创建,使用的utf8:
mysql> show create database hive_remote;
+-------------+----------------------------------------------------------------------+
| Database | Create Database |
+-------------+----------------------------------------------------------------------+
| hive_remote | CREATE DATABASE `hive_remote` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+-------------+----------------------------------------------------------------------+
1 row in set (0.00 sec)
检查表COLUMNS_V2的创建语句,发现表和COMMENT使用的latin1编码格式,所以出现中文乱码:
mysql> use hive_remote;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show create table COLUMNS_V2;
| Table | Create Table |
| COLUMNS_V2 | CREATE TABLE `COLUMNS_V2` (
`CD_ID` bigint(20) NOT NULL,
`COMMENT` varchar(256) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`COLUMN_NAME` varchar(767) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`TYPE_NAME` mediumtext,
`INTEGER_IDX` int(11) NOT NULL,
PRIMARY KEY (`CD_ID`,`COLUMN_NAME`),
KEY `COLUMNS_V2_N49` (`CD_ID`),
CONSTRAINT `COLUMNS_V2_FK1` FOREIGN KEY (`CD_ID`) REFERENCES `CDS` (`CD_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
导致字符集编码使用latin1的原因在哪里:
文件是/opt/hive-3.1.2/scripts/metastore/upgrade/mysql/hive-schema3.1.0.mysql.sql文件中。
[root@node3 ~]# vim /opt/hive-3.1.2/scripts/metastore/upgrade/mysql/hive-schema-3.1.0.mysql.sql
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE IF NOT EXISTS `BUCKETING_COLS` (
`SD_ID` bigint(20) NOT NULL,
`BUCKET_COL_NAME` varchar(256) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`INTEGER_IDX` int(11) NOT NULL,
PRIMARY KEY (`SD_ID`,`INTEGER_IDX`),
KEY `BUCKETING_COLS_N49` (`SD_ID`),
CONSTRAINT `BUCKETING_COLS_FK1` FOREIGN KEY (`SD_ID`) REFERENCES `SDS` (`SD_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
/*!40101 SET character_set_client = @saved_cs_client */;
如何解决集编码使用latin1?
修改表字段注解和表注解(在mysql上执行)
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
实操如下
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
Query OK, 6 rows affected (0.03 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
Query OK, 14 rows affected (0.02 sec)
Records: 14 Duplicates: 0 Warnings: 0
修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
删除表hive中person,然后创建person表,再查看表的信息, 乱码问题就解决了。
hive> drop table person;
OK
Time taken: 1.22 seconds
hive> show tables;
OK
Time taken: 0.048 seconds
hive> create table person(
> id int comment "唯一标识id",
> name string comment "名称",
> likes array comment "爱好",
> address map,string> comment "地址"
> )
> row format delimited
> fields terminated by ","
> collection items terminated by "-"
> map keys terminated by ":"
> lines terminated by "\n";
OK
Time taken: 0.085 seconds
hive> desc formatted person;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array 爱好
address map,string> 地址
# Detailed Table Information
Database: hivedb1 #数据库实例
OwnerType: USER #归属root用户
Owner: root
CreateTime: Sun Apr 16 16:56:18 CST 2023 # 创建时间
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/user/hive_remote/warehouse/hivedb1.db/person #hdfs路径
Table Type: MANAGED_TABLE # 表类型:管理表 通常称内部
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"address\":\"true\",\"id\":\"true\",\"likes\":\"true\",\"name\":\"true\"}}
bucketing_version 2
numFiles 0 # 有多少文件
numRows 0 # 有多少行
rawDataSize 0
totalSize 0 # 多大
transient_lastDdlTime 1681635378
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No ## 未使用压缩
Num Buckets: -1 # 分桶的数量
Bucket Columns: [] # 分桶的列
Sort Columns: [] # 排序的列
Storage Desc Params: #分隔符
collection.delim - #数组元素与元素之间,map的kv与kv之间的分隔符
field.delim , # 列与列之间分隔符
line.delim \n # 记录与记录之间的分隔符
mapkey.delim : # map的key与value之间的分隔符
serialization.format ,
Time taken: 0.079 seconds, Fetched: 38 row(s)
3.4.4 删除表
语法格式:
drop table [if exists] table_name
实操
hive> drop table person;
OK
3.5.1 Load添加数据
数据集:
id,姓名,爱好,地址
1,小明1,lol-book-movie,beijing:xisanqishanghai:pudong
2,小明2,lol-book-movie,beijing:xisanqishanghai:pudong
3,小明3,lol-book-movie,beijing:xisanqishanghai:pudong
4,小明4,lol-book-movie,beijing:xisanqishanghai:pudong
5,小明5,lol-movie,beijing:xisanqishanghai:pudong
6,小明6,lol-book-movie,beijing:xisanqishanghai:pudong
7,小明7,lol-book,beijing:xisanqishanghai:pudong
8,小明8,lol-book,beijing:xisanqishanghai:pudong
9,小明9,lol-book-movie,beijing:xisanqishanghai:pudon
语法格式
load data [local] inpath 'filepath' [overwrite] into table tablename [partition (partcol1=val1, partcol2=val2 ...)]
注意:使用overwrite表示覆盖,没有它表示追加
local:load的是本地文件,将filepath指定的本地文件上传到hdfs指定的目录(对应表目录)
无local:filepath是hdfs上一个文件,将他移动到指定目录(对应表的目录)
实操
# 添加本地文件 准备工作
[root@node4 ~]# mkdir data
[root@node4 ~]# cd data
[root@node4 data]# cat person.txt
1,小明1,lol-book-movie,beijing:xisanqishanghai:pudong
2,小明2,lol-book-movie,beijing:xisanqishanghai:pudong
3,小明3,lol-book-movie,beijing:xisanqishanghai:pudong
4,小明4,lol-book-movie,beijing:xisanqishanghai:pudong
5,小明5,lol-movie,beijing:xisanqishanghai:pudong
6,小明6,lol-book-movie,beijing:xisanqishanghai:pudong
7,小明7,lol-book,beijing:xisanqishanghai:pudong
8,小明8,lol-book,beijing:xisanqishanghai:pudong
9,小明9,lol-book-movie,beijing:xisanqishanghai:pudon
添加本地文件:
hive> load data local inpath '/root/data/person.txt' into table person;
Loading data to table default.person
OK
Time taken: 2.649 seconds
hive> select * from person;
OK
1 小明1 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
2 小明2 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
3 小明3 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
4 小明4 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong"}
5 小明5 ["lol","movie"] {"beijing":"xisanqishanghai:pudong "}
6 小明6 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
7 小明7 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
8 小明8 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
9 小明9 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudon"}
Time taken: 4.358 seconds, Fetched: 9 row(s)
在hdfs文件系统上的对应目录/user/hive_remote/warehouse/person下多出一个person.txt文件
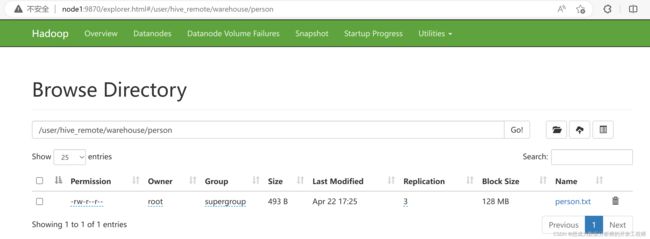
上传hdfs上的文件
# 上传文件到hdfs
[root@node4 ~]# cd data/
[root@node4 data]# hdfs dfs -put person.txt /
2023-04-22 17:35:24,121 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
# 查看文件
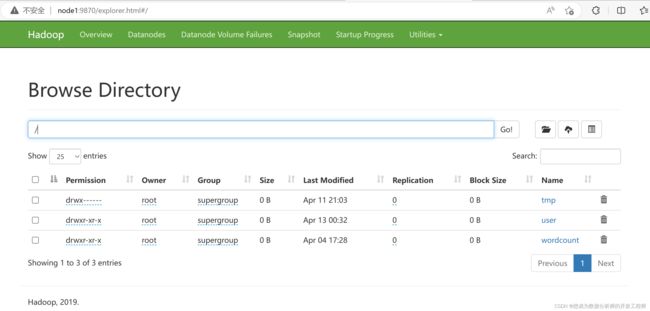
[root@node4 data]# hdfs dfs -ls /
Found 4 items
-rw-r--r-- 3 root supergroup 493 2023-04-22 17:35 /person.txt
drwx------ - root supergroup 0 2023-04-11 21:03 /tmp
drwxr-xr-x - root supergroup 0 2023-04-13 00:32 /user
drwxr-xr-x - root supergroup 0 2023-04-04 17:28 /wordcount
# 使用load向person表添加数据
hive> load data inpath '/person.txt' into table person;
Loading data to table default.person
OK
Time taken: 0.808 seconds
# 查看表
hive> select * from person;
OK
1 小明1 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
2 小明2 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
3 小明3 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
4 小明4 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong"}
5 小明5 ["lol","movie"] {"beijing":"xisanqishanghai:pudong "}
6 小明6 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
7 小明7 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
8 小明8 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
9 小明9 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudon"}
1 小明1 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
2 小明2 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
3 小明3 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
4 小明4 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong"}
5 小明5 ["lol","movie"] {"beijing":"xisanqishanghai:pudong "}
6 小明6 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
7 小明7 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
8 小明8 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
9 小明9 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudon"}
Time taken: 0.421 seconds, Fetched: 18 row(s)
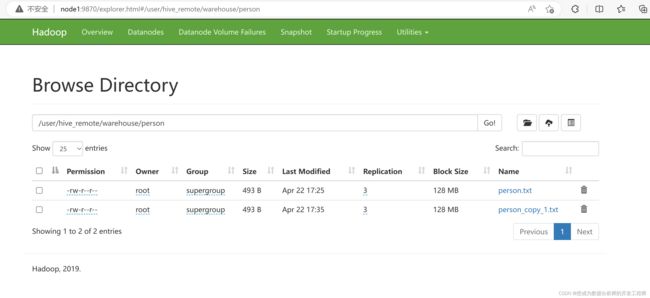
检查hdfs上文件,得出:在hdfs文件系统中的/person.txt没有了,然后在hdfs文件系统中的/user/hive_remote/warehouse/person目录下多出一个person_copy_1.txt。就相当于将hdfs上的文件从目录"/"下移动到/user/hive_remote/warehouse/person下(由于该目录下已经有一个名称为person.txt的文件,所以移动过来的person.txt使用一个新的名称)。
3.5.2 insert添加数据
语法规则
insert overwrite table tablename1 [partition (partcol1=val1, partcol2=val2 ...) [if not
exists]] select_statement1 from from_statement;insert into table tablename1 [partition
(partcol1=val1, partcol2=val2 ...)]select_statement1 from from_statement;
insert overwrite:表示覆盖的方式
insert into:表示追加的方式
实际操作
首先创建一个Person2
hive> create table person2(
> id int comment "唯一标识id",
> name string comment "名称",
> likes array comment "爱好",
> address map,string> comment "地址"
> )
> row format delimited
> fields terminated by ","
> collection items terminated by "-"
> map keys terminated by ":"
> lines terminated by "\n";
OK
Time taken: 0.222 seconds
将person表中的数据添加到person2中
hive> insert into table person2 select * from
person;
Query ID = root_20211111150434_2efb7477-d01a4d04-a41b-408e06454a67
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since
there's no reduce operator
......
Stage-Stage-1: Map: 1 Cumulative CPU: 3.2 sec
HDFS Read: 6448 HDFS Write: 568 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 200
msec
OK
Time taken: 40.463 seconds
hive> select * from person2;
OK
1 小明1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
2 小明2 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3 小明3 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
4 小明4 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
5 小明5 ["lol","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
6 小明6 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
7 小明7 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
8 小明8 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
9 小明9 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
Time taken: 0.601 seconds, Fetched: 9 row(s)
hive> insert into table person2 select * from
person;
Query ID = root_20211111150539_7e3d0282-1a93-
4d73-a31a-5c45c3bbf518
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since
there's no reduce operator
......
SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 570
msec
OK
Time taken: 34.366 seconds
hive> select * from person2;
OK
1 小明1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
2 小明2 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3 小明3 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
4 小明4 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
5 小明5 ["lol","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
6 小明6 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
7 小明7 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
8 小明8 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
9 小明9 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
1 小明1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
2 小明2 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3 小明3 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
4 小明4 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
5 小明5 ["lol","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
6 小明6 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
7 小明7 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
8 小明8 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
9 小明9 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
insert overwrite:清空之前数据,新入新的数据
hive> insert overwrite table person2 select *
from person;
Query ID = root_20211111150904_3ccbd244-dd24-
4a51-9b40-eef5fe85ede9
Total jobs = 3
Launching Job 1 out of 3
......
OK
Time taken: 29.986 seconds
hive> select * from person2;
OK
1 小明1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
2 小明2 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3 小明3 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
4 小明4 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
5 小明5 ["lol","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
6 小明6 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
7 小明7 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
8 小明8 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
9 小明9 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
Time taken: 0.289 seconds, Fetched: 9 row(s)
**适用场景:**将一个复杂的表tableA(假如有100个列),向将该表中的一些列的数据添加tableB中,另外一些列的数据放到tableC中。
create table person2_1(
id int comment "唯一标识id",
name string comment "名称"
)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n";
create table person2_2(
id int comment "唯一标识id",
likes array comment "爱好",
address map,string> comment "地址"
)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n";
将这两张表也添加hive中:
hive> show tables;
OK
person
person2
person2_1
person2_2
将表person2中的数据分别放入到person2_1和person2_2中:
解决办法一:
insert into table person2_1 select id,name
from person2;
insert into table person2_2 select
id,likes,address from person2;
如上解决版本会执行两次查询,效率较低。
解决办法二:
语法格式:
from from_statement
insert overwrite table tablename1 [partition
(partcol1=val1, partcol2=val2 ...) [if not
exists]] select_statement1
[insert overwrite table tablename2 [partition
... [if not exists]] select_statement2]
sql语句:
from person2
insert into table person2_1 select id,name
insert into table person2_2 select
id,likes,address;
hive> from person2
> insert into table person2_1 select
id,name
> insert into table person2_2 select
id,likes,address;
Query ID = root_20211111152050_79d388d9-3af3-
47d3-88ab-57a2c67e5921
Total jobs = 3
Launching Job 1 out of 3
......
Time taken: 60.344 seconds
hive> select * from person2_1;
OK
1 小明1
2 小明2
3 小明3
4 小明4
5 小明5
6 小明6
7 小明7
8 小明8
9 小明9
Time taken: 0.304 seconds, Fetched: 9 row(s)
hive> select * from person2_2;
OK
1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
2 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
4 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
5 ["lol","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
6 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
7 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
8 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
9 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3.6 HiveSQL默认分隔符
创建表
create table person3(
id int comment "唯一标识id",
name string comment "名称",
likes array comment "爱好",
address map,string> comment "地址"
);
准备数据
[root@node4 data]# pwd
/root/data
[root@node4 data]# ls
person.txt
[root@node4 data]# cp person.txt person3.txt
[root@node4 data]# vim person3.txt
1^A小明3^Alol^Bbook^Bmovie^Abeijing^Bxisanqi^Bshanghai^Cpudong
^A:如何输入 ^A ,ctrl+v ctrl+A
将数据load到person3中
hive> load data local inpath
'/root/data/person3.txt' into table person3;
Loading data to table default.person3
OK
Time taken: 0.59 seconds
hive> select * from person3;
OK
1 小明1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
Time taken: 0.298 seconds, Fetched: 1 row(s)
hive> desc formatted person3;
OK
# col_name data_type
comment
id int
唯一标识id
name string
名称
likes array
爱好
address map,string>
地址
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Thu Nov 11 15:36:10 CST
2021
LastAccessTime: UNKNOWN
Retention: 0
Location:
hdfs://mycluster/user/hive_remote/warehouse/per
son3
Table Type: MANAGED_TABLE
Table Parameters:
bucketing_version 2
numFiles 1
numRows 0
rawDataSize 0
totalSize 57
transient_lastDdlTime 1636616468
# Storage Information
SerDe Library:
org.apache.hadoop.hive.serde2.lazy.LazySimpleSe
rDe
InputFormat:
org.apache.hadoop.mapred.TextInputFormat
OutputFormat:
org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextO
utputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1 #没有自定义的分隔符
了。
自定义的方式指定默认的分隔符(了解):
create table person3_1(
id int comment "唯一标识id",
name string comment "名称",
likes array comment "爱好",
address map,string> comment "地址"
)
row format delimited
fields terminated by "\001"
collection items terminated by "\002"
map keys terminated by "\003";
hive>
> desc formatted person3_1;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array 爱好
address map,string> 地址
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Sat Apr 22 18:44:40 CST 2023
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/user/hive_remote/warehouse/person3_1
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"address\":\"true\",\"id\":\"true\",\"likes\":\"true\",\"name\":\"true\"}}
bucketing_version 2
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1682160280
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
collection.delim \u0002
field.delim \u0001
mapkey.delim \u0003
serialization.format \u0001
Time taken: 0.338 seconds, Fetched: 37 row(s)
3.7 HiveSQL删除表中数据
hive> select * from person;
OK
1 小明1 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
2 小明2 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
3 小明3 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
4 小明4 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
5 小明5 ["lol","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
6 小明6 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
7 小明7 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
8 小明8 ["lol","book"]
{"beijing":"xisanqi","shanghai":"pudong"}
9 小明9 ["lol","book","movie"]
{"beijing":"xisanqi","shanghai":"pudong"}
Time taken: 4.691 seconds, Fetched: 9 row(s)
hive> delete from person;
FAILED: SemanticException [Error 10294]:
Attempt to do update or delete using
transaction manager that does not support these
operations.
hive> truncate table person;
OK
Time taken: 3.225 seconds
hive> select * from person;
O
delete使用的更多内容见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML#LanguageManualDML-Delete
delete需要经过事务,一般不用。
truncate:不经过事务,作用是将指定表的数据全部清空。
3.8 内部表与外部表
(1) Hive 内部表
CREATE TABLE [IF NOT EXISTS] table_name
删除表时,元数据与数据都会被删除
Table Type: MANAGED_TABLE 内部表
(2) Hive 外部表
CREATE EXTERNAL TABLE [IF NOT EXISTS]
table_name LOCATION hdfs_path
删除外部表只删除metastore的元数据,不删除hdfs中的表数据
Table Type: EXTERNAL_TABLE external
首先将person.txt文件上传到hdfs的/usr目录
# 在hdfs上创建文件目录
[root@node4 ~]# hdfs dfs -mkdir /usr
# 上传本地文件到hdfs目录上
[root@node4 ~]# hdfs dfs -put /root/data/person.txt /usr
2023-04-22 19:04:13,645 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
# 查看hdfs文件目录
[root@node4 ~]# hdfs dfs -ls /usr
Found 1 items
-rw-r--r-- 3 root supergroup 493 2023-04-22 19:04 /usr/person.txt
# 创建表
create external table person4(
id int comment "唯一标识id",
name string comment "名称",
likes array comment "爱好",
address map,string> comment "地址"
)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n"
location '/usr/external';
#创建目录
[root@node4 ~]# hdfs dfs -put /root/data/person.txt /usr/external
建表脚本
# 创建表的信息
create external table person4(
id int comment "唯一标识id",
name string comment "名称",
likes array comment "爱好",
address map,string> comment "地址"
)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n"
location '/usr/external';
hive> desc formatted person4;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array 爱好
address map,string> 地址
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Sat Apr 22 19:16:53 CST 2023
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/usr/external
Table Type: EXTERNAL_TABLE # 表示外部表
Table Parameters:
EXTERNAL TRUE
bucketing_version 2
transient_lastDdlTime 1682162213
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
collection.delim -
field.delim ,
line.delim \n
mapkey.delim :
serialization.format ,
Time taken: 0.295 seconds, Fetched: 34 row(s)
查询表中数据:由于在指定位置有数据,所以没有添加就存在数据
hive> select * from person4;
OK
1 小明1 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
2 小明2 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
3 小明3 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
4 小明4 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong"}
5 小明5 ["lol","movie"] {"beijing":"xisanqishanghai:pudong "}
6 小明6 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "}
7 小明7 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
8 小明8 ["lol","book"] {"beijing":"xisanqishanghai:pudong "}
9 小明9 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudon"}
Time taken: 0.463 seconds, Fetched: 9 row(s)
删除外部表
外部表删除前

hive> drop table person4;
OK
外部表删除后:元数据被删除、数据文件存在
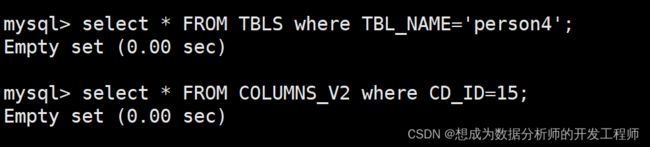
![]()
内部表和外部表的区别:
1、创建表的时候,内部表直接存储在默认的hdfs路径(/user/hive_remote/warehouse),外部表需要自己指定路径
2、删除表的时候,内部表会将数据和元数据全部删除,外部表只删除元数据,数据不删除
注意:hive:读时检查(实现解耦,提高数据加载的效率)
关系型数据库:写时检查