AWS 大数据实战 - 环境准备(一)
实验介绍
本次实战内容将教大家如何使用 AWS 的大数据和数据湖的相关服务和组件,顺利完成大数据的收集,存储,处理,分析和可视化的完整的流程,主要会介绍以下几个 AWS 大数据服务:
- Lab1:实时流数据处理,基于 Kinesis 产品家族实现
- Lab2:批量数据处理,基于 EMR(Spark) 实现
- Lab3:数据可视化,基于 Quicksight + Athena 实现
- Lab4:数据实时检索,基于 Elasticsearch 实现
- Lab5:数据仓库构建和数据可视化展现,基于 Redshift + Quicksight 实现
为了更好的模拟实际的业务需求,我们构建了一个数据库(模拟历史数据,或者部分客户已经存在的ODS库),我们构建了实时数据流(模拟例如电商,web等的点击流),我们构建了流式实时分析和批量分析的平台以及对应的可视化展现和数据实时检索的平台。如下是此次实验的整体的架构图:
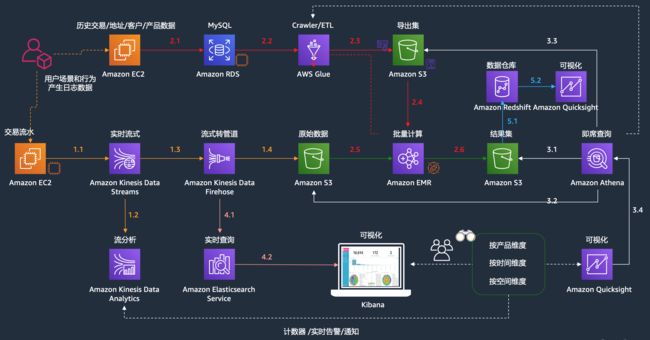
为了让大家对数据结构有个更清晰的认识,我们把RDS(关系型数据库)里面的数据表结构做了一层抽象,供参考:

实验准备
为了顺利完成全部的动手实验,需要做如下准备工作,所有的资源创建在了 AWS us-east-1 这个区域:
| 步骤 | 准备环境 | 准备内容描述 |
|---|---|---|
| 01 | 账号配置 | 熟悉AWS提供的账号和登录方式,并配置对应安全选项 |
| 02 | 部署EC2 | 部署一个EC2(Linux)用于操作的客户端并学会远程登录 |
| 03 | 配置KDS | 配置 Kinesis Data Streams 实时数据流用于产生数据 |
| 04 | 部署RDS | 配置数据库(在实验环境中,理解为历史数据或者ODS环境) |
| 05 | 部署EMR | 部署大数据平台 EMR |
| 06 | 部署ES | 部署实时分析平台 Elasticsearch |
账号配置
IAM(Identity and Access Management)是AWS和用户,权限以及认证等安全相关的服务,此处我们配置两个角色,一个是 EC2 访问云中一些资源使用的角色(ec2-role),还有一个是 Glue 访问云中资源使用的角色(glue-role)
为 EC2 配置角色权限
通过如下方式打开IAM控制台
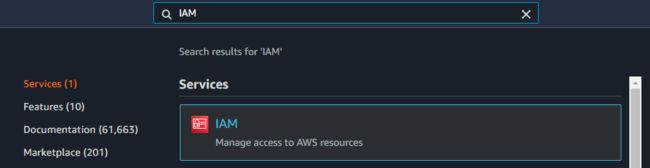
点击左边的“Role”菜单,然后选择“Create role”

在 AWS service 里面选择 EC2

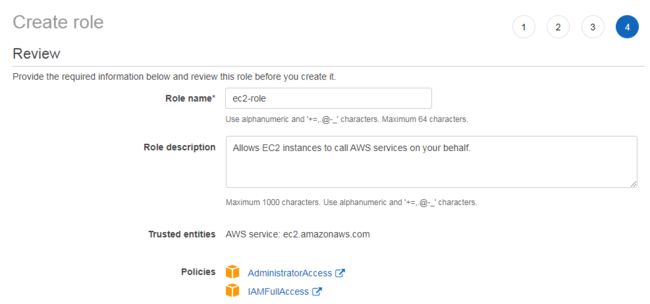
在设置权限的页面,点击“直接附加现有策略”,添加 AdministratorAccess 和 IAMFullAccess 两个权限

下一步标签页面可以不配置,接着下一步审核页面,确认策略已经正确添加
为 Glue 配置角色权限
在 AWS service 里面选择 Glue
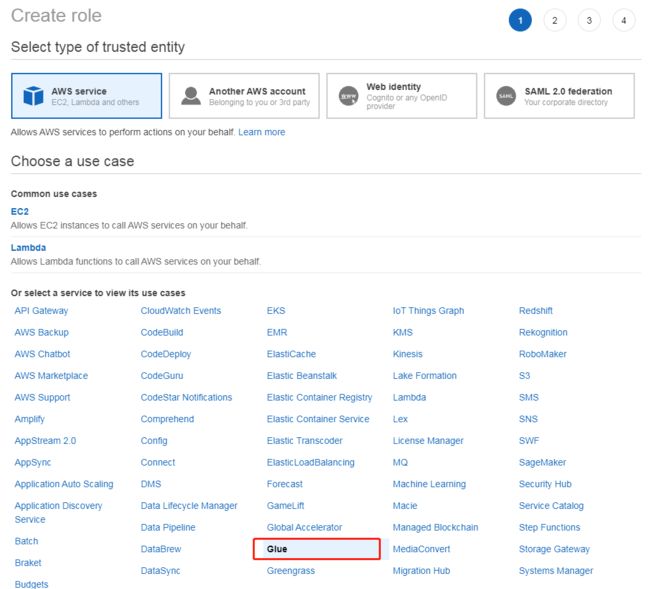
在筛选策略的页面,选中 AdministratorAccess 和 IAMFullAccess,然后点击下一步,不配置标签,直接审核角色配置,设置名字(此处为glue-role),确认策略,然后确认即可

部署EC2
EC2简单理解为AWS云上的虚拟机即可。打开EC2控制台,选择AMI(Amazon Machine Image)类型为“Amazon Linux 2”,并确认架构为64位x86

机型选择t2.large或者t2.xlarge都可以(t3对应系列也可以,基本没什么负载,本着节俭的原则,选个2G以上内存的都可以满足需求)

实例配置这一页,IAM role 给我们刚刚创建的 ec2-role
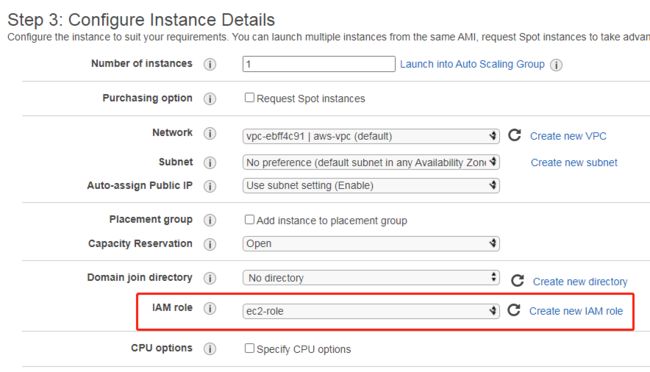
下一步标签页面,我们添加一个“键”为“Name”(注意大小写),“值”为“LinuxClient”的标签,供参考(标签可以不设置)

下一步配置安全组的时候,直接给一个网络全部放开的安全组,没有的话自己去创建一个

下一步审核页面可以确认下配置,然后直接点击“启动”,接下来会提示使用哪个密钥对(keypair)部署这个EC2,此处我们选择新建一个,并保存到本地(注意:也只有这一次可以保存,后续不能再下载了,如果要更换密钥很麻烦)
登陆 EC2
创建好之后,我们使用 SSH 客户端登陆到机器,然后查看一下
wangzan:~ $ ssh -i ~/.ssh/bmc-aws.pem [email protected]
The authenticity of host '44.192.79.152 (44.192.79.152)' can't be established.
ECDSA key fingerprint is SHA256:/BosjrkiuZkSIsuSlUHRt2CPITqx8hh8IMfSv9mJVzo.
ECDSA key fingerprint is MD5:88:bc:5c:f0:c8:87:76:da:48:2b:24:06:6b:63:54:92.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '44.192.79.152' (ECDSA) to the list of known hosts.
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-2/
[ec2-user@ip-172-31-77-126 ~]$ aws sts get-caller-identity
{
"Account": "921283538843",
"UserId": "AROA5NAGHF6NUFMB62LS2:i-03c9b3efdb246a085",
"Arn": "arn:aws:sts::921283538843:assumed-role/ec2-role/i-03c9b3efdb246a085"
}配置 KDS
本章节内容主要配置两个 Kinesis Data Streams 数据流(有时简称为 kds,作为 Lab1/4 持续产生数据的来源)。
创建 KDS 流
Kinesis 是 AWS 云上的流计算相关服务,包括流数据接收和承载平台 Kinesis Data Streams(对标 Kafka),流处理管道 Kinesis Data Firehose,流分析平台 Kinesis Data Analytics,流视频处理平台 Kinesis Video Streams。此处我们主要配置 2 个 Kinesis Data Streams,分别用于 Lab1/4 使用。
打开 Kinesis 控制台,选择左侧菜单的“Data streams”,在打开的页面中,选择“Create data stream”

创建 lab1 需要用到的数据流(设置流名称和分片数量,此处设置为 1 即可)

用同样的方式创建 lab2(在我们实验的过程中暂时用不到,此处仅供演示)和 lab4 需要用到的数据流,创建完毕后如下

现在我们创建好了 kds,目前可以进行 lab1-流数据处理的实验了。
部署RDS
本章节内容主要是部署一个关系型数据库(RDS,MySQL 5.7),并导入对应数据。
登录RDS控制台
RDS 是 AWS 云上的数据库平台服务,包括自主研发的 Aurora,也包括基于 MySQL/MariaDB/Oracle/SQL Server/PostgreSQL 等不同引擎的关系型数据库,此处我们部署的 RDS(MySQL 5.7)主要用于 Lab2 使用。
配置参数组和选项组
选择左侧菜单“参数组”,然后点击右侧“创建参数组”,选择参数组系列为“mysql5.7”,然后输入对应的名字和描述,点击“创建”即可
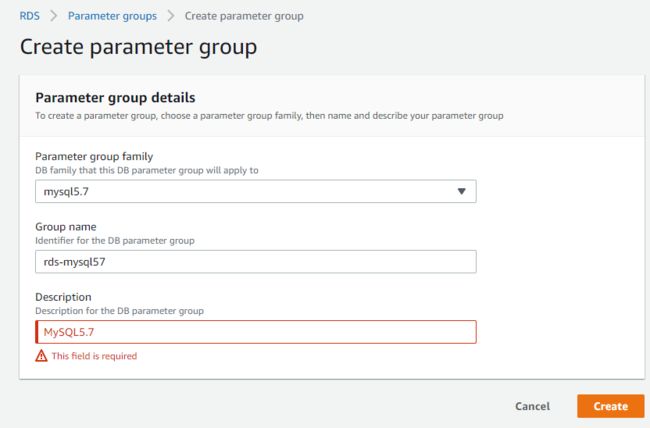
创建完毕后,点击参数组名字后打开刚才创建的参数组,在参数那里输入character_,并选择“编辑参数”,因为我们要在命令行操作中文内容的记录,所以需要修改数据库的编码,否则容易出现乱码的问题。此处我们把所有能修改的“值”全部改成utf8mb4,并点击“保存更改”即可

选择左侧菜单“Option groups”,然后点击右侧“Create group”

部署RDS数据库
选择左侧菜单“数据库”,然后点击右侧“创建数据库”,接下来选择数据库的引擎,版本和模板,如截图所示

接下来设置数据库实例名称,管理员名称和密码(此处为:wzlinux2021,可自定义,主要是自己要记住别忘记)以及选择数据库类型

存储,可用性和网络连接选默认值即可,点开“其他配置”,输入数据库名字(此处为bdd),选择刚才创建的“参数组”和“选项组”,其他全部默认,拉到最下面点击“创建数据库”即可

数据库准备好以后,点击数据库名字,出现连接和安全性页面,把对应的终端节点内容复制出来,此处为
bdd.ccganutjnmfy.us-east-1.rds.amazonaws.com导入数据
大家把如下 sql 下载到部署好的 EC2 客户端里面
https://imgs.wzlinux.com/aws/bdd.sql
然后登陆 EC2 客户端,安装 mysql 客户端
sudo yum install mysql -y然后使用 mysql 客户端用如下命令登录数据库(紧接着需要输入密码)
mysql -h bdd.ccganutjnmfy.us-east-1.rds.amazonaws.com -u admin -p bdd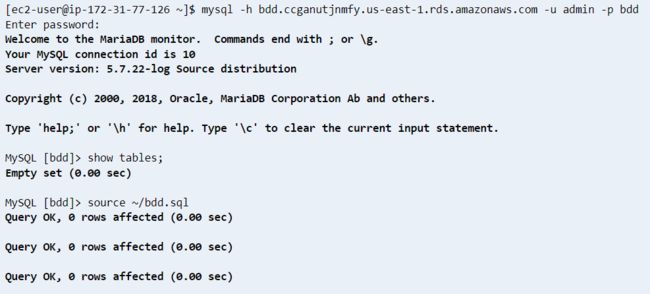
然后检查数据库内容是否和截图匹配
MySQL [bdd]> show tables;
+-----------------+
| Tables_in_bdd |
+-----------------+
| tbl_address |
| tbl_customer |
| tbl_product |
| tbl_transaction |
+-----------------+
4 rows in set (0.00 sec)
MySQL [bdd]>此处我们有4个表,内容分别如下
| 表名 | 内容 | 行数 |
|---|---|---|
| tbl_address | 客户地址信息表 | 1084 |
| tbl_customer | 客户表 | 1084 |
| tbl_product | 产品信息表 | 100 |
| tbl_transaction | 历史交易记录表 | 49874 |
现在我们已经部署好了 RDS,接下来部署 EMR。
部署 EMR
EMR(Elastic MapReduce)是 AWS 上的一个托管集群平台,可简化在 AWS 上运行大数据框架(如 Apache Hadoop 和 Apache Spark 等)以处理和分析海量数据的操作。
打开 EMR 控制台,直接选择“创建集群”,出现创建页面的时候,选择“转到高级选项”,选择对应的版本(默认最新版),选择Spark(Lab2需要用到),勾选使用Glue做Catalog,然后进入下一步

第二步的硬件配置页面,全部选默认即可,第三步的配置集群信息,参考如下截图
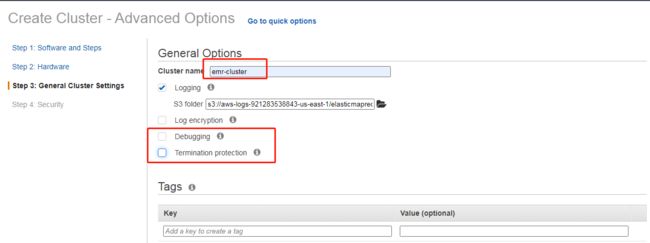
然后选择对应的密钥对,点击“创建集群”即可

集群全部部署完毕需要5分钟左右,创建完成之后,我们就可以进行 Lab2-批量数据处理的操作了。
部署 Elasticsearch
本章节内容只需要部署一个 Elasticsearch 集群,暂时不做其他配置。
Elasticsearch Service (Amazon ES) 是一种托管服务,可以让您轻松在 AWS 云中部署、操作和扩展 Elasticsearch 集群。
通过如下方式打开ES控制台

如果是第一次使用,会出现如下页面,选择“创建新域”即可

我们选择开发测试和最新版
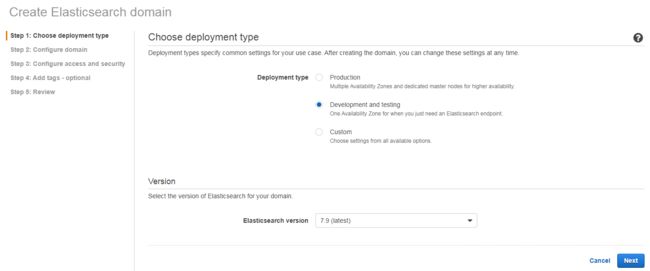
在配置页面我们设置集群名字(此处为lab-es),并设置数据节点的 EBS 磁盘大小为 100G


在安全配置页面,我们选择部署 Public access,这样方便我们访问,精细访问里面选择 Create master user,这里创建的用户具有 ES 的最高权限,并且选择开放的资源访问策略,如下图所示:



其他设置默认,审核请确认后创建集群。集群 Domain 全部部署完毕需要 10 分钟左右,等创建完成之后,我们就可以开始 Lab4-数据实时检索的实验了。
环境清理
主要需要清除的内容如下
1.删除掉部署的 EC2(这是数据的源头),先清除 EC2 能避免后续的数据产生;
2.删除 Kinesis 的各个流,管道和分析;
3.删除 RDS 数据库;
4.删除 EMR 集群;
5.删除 Elasticsearch 集群;
6.删除 Redshift 集群;
7.删除Glue的相关配置爬虫和任务等;
8.删除实验过程中创建的 S3 存储桶;
【注意】如果没有其他任何地方使用到了 Quicksight 服务,也建议把此服务注销,请参考官方文档
https://docs.aws.amazon.com/zh_cn/quicksight/latest/user/closing-account.html欢迎大家扫码关注,获取更多信息
