全网最全tcpdump和Wireshark抓包实践
tcpdump和Wireshark抓包实践
- 1、wireshark基本使用
-
- 1.1、如何捕获报文
- 1.2、Wireshark 面板
- 1.3、快捷方式工具栏
- 1.5、设定时间显示格式
- 1.6、数据包列表面板的标记符号
- 1.7、文件操作
- 1.9、抓包文件常见几种类型
- 1.10、解析https报文,TSL报文
- 1.11、wireshark Expert Information信息详解
- 1.12、wireshark常用过滤器
- 1.13、设置裸序列号
- 1.14、TTL 详解
- 1.15、重复确认(DupAck)
- 1.16、Flow Graph
- 1.17、I/O Graph
- 1.18、TCP Stream Graphs
- 2、如何抓取报文?
- 3、如何读取抓包文件?
- 4、如何过滤报文?
- 5、如何过滤后转存?
- 6、如何让抓包时间尽量长一点?
- 7、怎么知道抓包文件是在哪一端抓取的?
- 8、如何定位到应用层的请求和返回的报文?
- 9、数据包乱序一定会引起问题吗?
1、wireshark基本使用
1.1、如何捕获报文
- 点击捕获——>选项,打开捕获窗口
- 网卡设备/流量/捕获过滤器,点击“开始”按钮开始抓包
- 输出(指定缓存文件)/选项(显示、名称解析、自动停止抓包条件) 面板
- 点击捕获——>停止,停止抓包
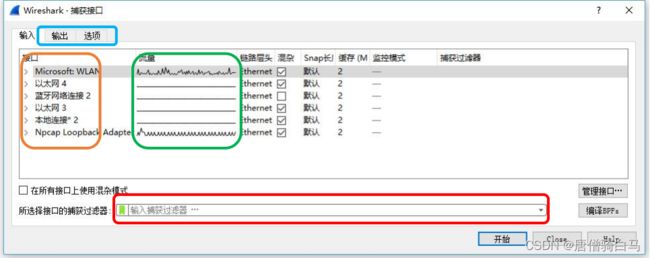
1.2、Wireshark 面板

1.3、快捷方式工具栏
##1.4、数据包的颜色(视图->着色规则)

1.5、设定时间显示格式

1.6、数据包列表面板的标记符号

1.7、文件操作
- 标记报文 Ctrl+M
- 导出标记报文(文件->导出特定分组),亦可按过滤器导出报文
- 合并读入多个报文(文件->合并)
##1.8、如何快速抓取移动设备的报文?
- 在操作系统上打开 wifi 热点
- 手机连接 wifi 热点
- 用 Wireshark 打开捕获——>选项面板,选择 wifi 热点对应的接口设备抓包
1.9、抓包文件常见几种类型
- pcap
这个是 libpcap 的格式,也是 tcpdump 和 Wireshark 等工具默认支持的文件格式。pcap 格式的文件中除了报文数据以外,也包含了抓包文件的元信息,比如版本号、抓包时间、每个报文被抓取的最大长度,等等。
- capcap
文件可能含有一些 libpcap 标准之外的数据格式,它是由一些 tcpdump 以外的抓包程序生成的。比如 Citrix 公司的 netscaler 负载均衡器,它的 nstrace 命令生成的抓包文件,就是以.cap 为扩展名的。这种文件除了包含 pcap 标准定义的信息以外,还包含了 LB 的前端连接和后端连接之间的 mapping 信息。Wireshark 是可以读取这些.cap 文件的,只要在正确的版本上。
- pcapng
pcap 格式虽然满足了大部分需求,但是它也有一些不足。比如,现在多网口的情况已经越来越常见了,我们也经常需要从多个网络接口去抓取报文,那么在抓包文件里,如果不把这些报文跟所属的网口信息展示清楚,那我们的分析,岂不是要张冠李戴了吗?
为了弥补 pcap 格式的不足,人们需要有一种新的文件格式,pcapng 就出现了。有了它,单个抓包文件就可以包含多个网络接口上,抓取到的报文了。
1.10、解析https报文,TSL报文
在用户环境变量新建一个SSLKEYLOGFILE变量,然后填写一个日志文件
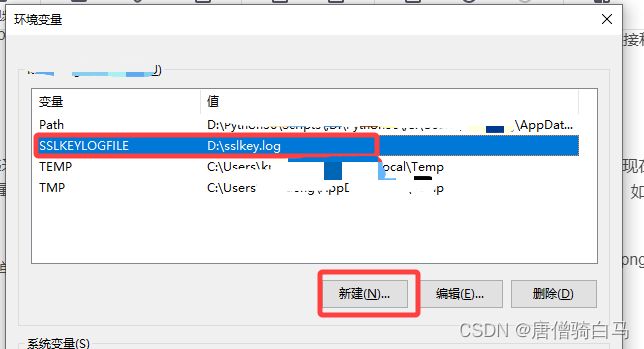
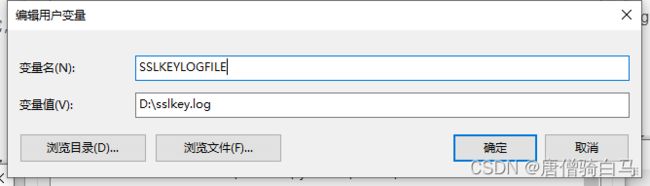
重启浏览器,打开wireshark,编辑——>首选项——>Protocols——>TLS,填写环境变量里面编写的文件路径,然后重新打开wireshark即可生成环境变量里的文件(不需要新建这个文件,打开wireshark会自动生成)
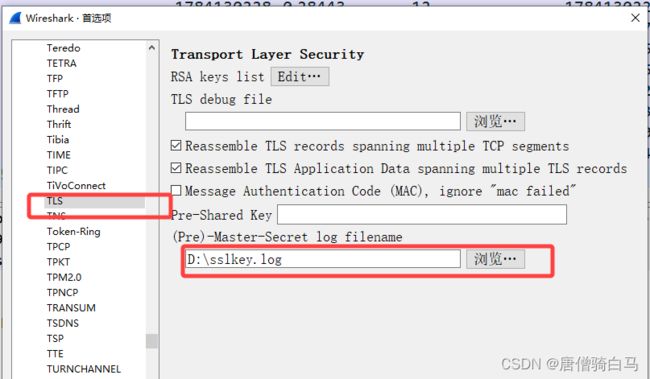
自动生成的文件

1.11、wireshark Expert Information信息详解
- Warning 条目的底色是黄色,意味着可能有问题,应重点关注。
- Note 条目的底色是浅蓝色,是在允许范围内的小问题,也要关注。什么叫“允许范围内的小问题”呢?举个例子,TCP 本身就是容许一定程度的重传的,那么这些重传报文,就属于“允许范围内”。
- Chat 条目的底色是正常蓝色,属于 TCP/UDP 的正常行为,可以作为参考。比如你可以了解到,这次通信里 TCP 握手和挥手分别有多少次,等等。

上图展示的就是客户端抓包文件的情况,我们逐个来解读这三种不同级别的 Severity(严重级别)。 - Warning:有 7 个乱序(Out-of-Order)的 TCP 报文,6 个未抓到的报文(如果是在抓包开始阶段,这种未抓到报文的情况也属正常)。
- Note:有 1 个怀疑是快速重传,5 个是重传(一般是超时重传),6 个重复确认。
- Chat:有 TCP 挥手阶段的 20 个 FIN 包,握手阶段的 10 个 SYN 包和 10 个 SYN+ACK 包。
1.12、wireshark常用过滤器
ip.addr eq my_ip:过滤出源IP或者目的IP为my_ip的报文
ip.src eq my_ip:过滤出源IP为my_ip的报文
ip.dst eq my_ip:过滤出目的IP为my_ip的报文
tcp.seq eq 1 and tcp.ack eq 1 RST 的序列号是 1,确认号也是 1
frame.time >="dec 01, 2015 15:49:48" and frame.time <="dec 01, 2015 15:49:49" #frame.time 过滤器
frame.time >="dec 01, 2015 15:49:48" and frame.time <="dec 01, 2015 15:49:49" and ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 or tcp.ack eq 1)
# 对于 RST 报文,过滤条件就是
tcp.flags.reset eq 1
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1
下面这个过滤器,就可以找到含有这个字符串的报文:
tcp contains "id=abcdafeafeagfeagfaraera1242dfea"
frame contains "id=abcdafeafeagfeagfaraera1242dfea"
ip contains "id=abcdafeafeagfeagfaraera1242dfea"
http contains "id=abcdafeafeagfeagfaraera1242dfea"
tcp.len eq 长度
tcp.flags.fin eq 1
tcp.flags.reset eq 1
tcp.payload eq 数据
利用各层的 contains 动词来写过滤器。比如:
# 应用层可以是 http contains "abc"
# 传输层可以是 tcp contains "abc"
# 网络层可以是 ip contains "abc"
# 数据链路层可以是 frame contains "abc"
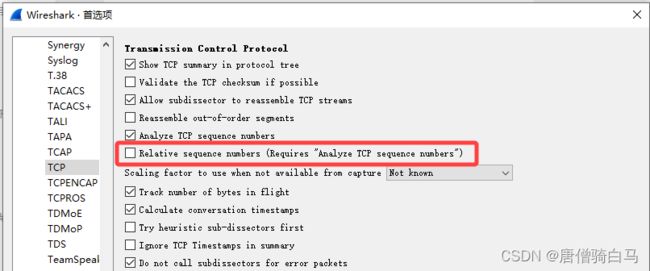
1.13、设置裸序列号
打开wireshark,编辑——>首选项——>Protocols——>tcp,把“Relative sequence numbers”前面的勾去掉,就可以显示裸序列号了:
用 TCP 确认号,比如下面这个过滤器:
tcp.ack_raw == 754313633
1.14、TTL 详解
TTL 是 IP 包(网络层)的一个属性,字面上就差不多是生命长度的意思,每一个三层设备都会把路过的 IP 包的 TTL 值减去 1。而 IP 包的归宿,无非以下几种:
- 网络包最终达到目的地;
- 进入路由黑洞并被丢弃;
- 因为网络设备问题被中途丢弃;
- 持续被路由转发并 TTL 减 1,直到 TTL 为 0 而被丢弃。
不同的操作系统其初始 TTL 值不同,一般来说 Windows 是 128,Linux 是 64。由此,我们就可以做一些快速的判断了。
假如百度服务端是 Windows,那么 Windows 类系统一般 TTL 为 128,减去 52,得到 76。那就意味着这个回包居然要途经 76 个三层设备,这显然就违背常识了,所以反证这个百度服务端不会是 Windows。这就是我想说的第一点:TTL 的值是反映了网络路径跳数的,也可以通过它间接推导出对端的 OS 类型。
第二点:内网同一个连接中的报文,其 TTL 值一般不会变化。

你也能很清楚地看到,同样的服务端,在三次握手中(SYN+ACK 报文)的 TTL 是 59,在导致连接中断的 RST 包里却变成了 64!显然,这个 RST 包并不是跟我们握手的那个服务端发出的,否则 TTL 值就不会变化。发出这个包的会是谁呢?
其实,一般就是防火墙设备。由于防火墙也遵循 IP 协议,而这里的 TTL 值是 64,这就说明这个防火墙跟客户端之间没有别的三层环节,或者说是三层直连的。
1.15、重复确认(DupAck)
重复确认在 TCP 里面有很重要的价值,它的出现,一般意味着传输中出现了丢包、乱序等情况。我们来看看这两个重复确认报文的细节。
![]()
1.16、Flow Graph
你可以这样找到它:点开 Statistics 菜单,在下拉菜单中找到 Flow Graph,点击它,就可以看到这个抓包文件的“二维图”了。不过,因为我们要查看的是过滤出来的 TCP 流,而 Flow Graph 只会展示抓包文件里所有的报文,所以,我们需要这么做:先把过滤出来的报文,保存为一个新的抓包文件;然后打开那个新文件,再查看 Flow Graph。
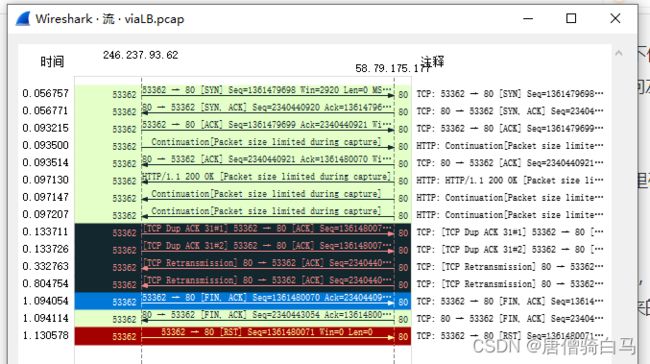
上图读起来,是不是感觉信息量要比主界面要多一些?特别是有了左右方向箭头,给我们大脑形成了“第二个维度”,报文的流向可以直接看出来,而不再去看端口或者 IP 去推导出流向了。
1.17、I/O Graph
这个工具在 Statistics 下拉菜单中,I/O Graph
点击 I/O Graph 后,Wireshark 会弹出一个趋势图,其 X 轴是时间,Y 轴是性能指标:
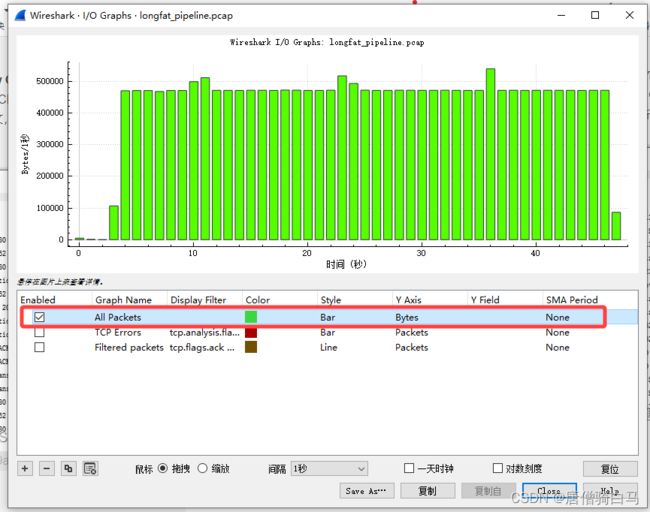
注意,这时的图是不准确的,所以我们需要做一些调整。既然我们关注传输速度,所以就选择 All Bytes 这个指标项(也是默认选中的那项)作为 Y 轴,然后修改它的计量单位。很可能你的 Wireshark 默认选中的是 AVG(Y Field),而这并不是我们要关注的字节数。我们可以双击 AVG(Y Field) 进入编辑模式,把它改为 Bytes:

你可能也注意到了,在 X 时间轴上看,一开始几秒速度比较低,第 7 秒才达到 400KB/s 以上。为什么一开始速度这么低呢?其实,这正是 TCP 慢启动的一个缩影:初始阶段,速度是特别低的,但是会很快爬高。
1.18、TCP Stream Graphs
还是到 Statics 下拉菜单,选择 TCP Stream Graphs,在子菜单中选择 Time sequence (Stevens)。

然后就能看到时间为 X 轴、TCP 序列号为 Y 轴的图了。你应该知道,序列号其实就等于字节数,那么显然,这里这条线的斜率也就是传输速率了。
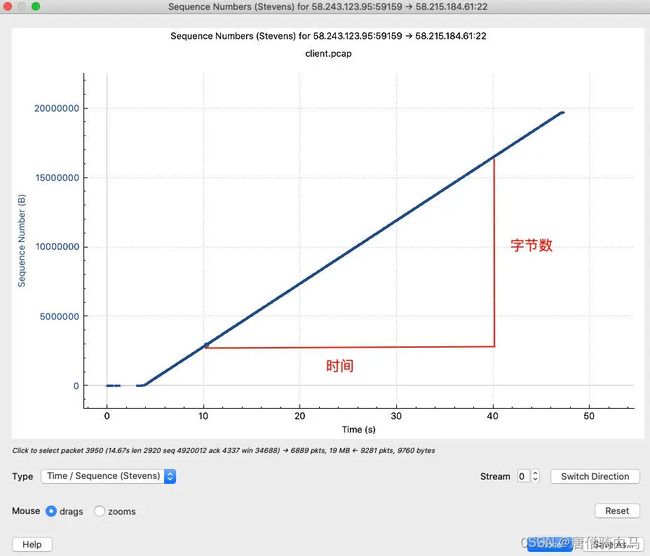
我们可以自己计算这个斜率(速率) 是多少。比如可以计算 10 秒和 40 秒两处的序列号的差距,再除以 (40-10) 秒,就是速率了。10 秒处的序列号是 2800092,40 秒处是 16480292,那么速率就是 (16480292-2800092)/(40-10)=456KB/s。


你可能发现了,两个 Graph 算出来的速度怎么有点差异?一个是 480KB/s 左右,一个是 456KB/s,相差有 5% 左右。
其实,这是正常的。因为 I/O Graph 统计的 Bytes 是二层帧的大小,而 TCP Stream Graphs 关注的是四层 TCP 段的大小。后者比前者少了二层到四层的头部。严格来说,TCP Stream Graphs 的斜率,只是 TCP payload 的速率;而 I/O Graph 展示的,才是我们一般谈论的传输速度。当然,在定性的讨论中,这点差异是可以忽略的
2、如何抓取报文?
用 tcpdump 抓取报文,最常见的场景是要抓取去往某个 ip,或者从某个 ip 过来的流量。我们可以用 host {对端 IP} 作为抓包过滤条件,比如:
tcpdump host 10.10.10.10
另一个常见的场景是抓取某个端口的流量,比如,我们想抓取 SSH 的流量,那么可以这样:
tcpdump port 22
还有不少参数我们也经常用到,比如:
-w 文件名,可以把报文保存到文件;
-i,指定抓包网卡
-r,读取抓包文件
c 数量,可以抓取固定数量的报文,这在流量较高时,可以避免一不小心抓取过多报文;
-s 长度,可以只抓取每个报文的一定长度,后面我会介绍相关的使用场景;
-n,不做地址转换(比如 IP 地址转换为主机名,port 80 转换为 http);
-v/-vv/-vvv,可以打印更加详细的报文信息;
-e,可以打印二层信息,特别是 MAC 地址;
-p,关闭混杂模式。所谓混杂模式,也就是嗅探(Sniffering),就是把目的地址不是本机地址的网络报文也抓取下来。
-X, 有时候你想看 TCP 报文里面的具体内容,比如应用层的数据,那么你可以用 -X 这个参数,以 ASCII 码来展示 TCP 里面的数据
$ sudo tcpdump port 80 -X
......
05:06:57.394573 IP _gateway.52317 > victorebpf.http: Flags [P.], seq 1:17, ack 1, win 65535, length 16: HTTP: GET / HTTP/1.1
0x0000: 4500 0038 282d 0000 4006 3a83 0a00 0202 E..8(-..@.:.....
0x0010: 0a00 020f cc5d 0050 0502 3a02 3ed1 3771 .....].P..:.>.7q
0x0020: 5018 ffff 4421 0000 4745 5420 2f20 4854 P...D!..GET./.HT
0x0030: 5450 2f31 2e31 0d0a TP/1.1..
读取抓包文件也可以使用-X参数
[root@localhost ~]# tcpdump -r 1201.pcap -X
reading from file 1201.pcap, link-type EN10MB (Ethernet)
03:19:38.035436 IP localhost.localdomain.http > 192.168.192.120.47958: Flags [R.], seq 0, ack 3193167715, win 0, length 0
0x0000: 4510 0028 0000 4000 4006 3888 c0a8 c06e E..(..@[email protected]....n
0x0010: c0a8 c078 0050 bb56 0000 0000 be53 df63 ...x.P.V.....S.c
0x0020: 5014 0000 543a 0000 P...T:..
03:19:38.998385 IP localhost.localdomain.http > 192.168.192.120.47962: Flags [R.], seq 0, ack 4061809141, win 0, length 0
0x0000: 4510 0028 0000 4000 4006 3888 c0a8 c06e E..(..@[email protected]....n
0x0010: c0a8 c078 0050 bb5a 0000 0000 f21a 49f5 ...x.P.Z......I.
0x0020: 5014 0000 b5dd 0000 P.......
3、如何读取抓包文件?
tcpdump 加上 -r 参数和文件名称,就可以读取这个文件了,而且也可以加上过滤条件。比如:
tcpdump -r file.pcap 'tcp[tcpflags] & (tcp-rst) != 0'
4、如何过滤报文?
tcp 标记值有 tcp-fin, tcp-syn, tcp-rst, tcp-push, tcp-push, tcp-ack, tcp-urg
# 过滤出 TCP RST 报文
tcpdump -w file.pcap 'tcp[tcpflags]&(tcp-rst) != 0'
# 用偏移量的写
tcpdump -w file.pcap 'tcp[13]&4 != 0'
5、如何过滤后转存?
有时候,我们想从抓包文件中过滤出想要的报文,并转存到另一个文件中。比如想从一个抓包文件中找到 TCP RST 报文,并把这些 RST 报文保存到新文件。那么就可以这么做:
tcpdump -r file.pcap 'tcp[tcpflags] & (tcp-rst) != 0' -w rst.pcap
6、如何让抓包时间尽量长一点?
前面我提到过 -s 这个长度参数,它的使用场景其实就包括了延长抓包时间。我们给 tcpdump 加上 -s 参数,指定抓取的每个报文的最大长度,就节省抓包文件的大小,也就延长了抓包时间。
一般来说,帧头是 14 字节,IP 头是 20 字节,TCP 头是 20~40 字节。如果你明确地知道这次抓包的重点是传输层,那么理论上,对于每一个报文,你只要抓取到传输层头部即可,也就是前 14+20+40 字节(即前 74 字节):
tcpdump -s 74 -w file.pcap
而如果是默认抓取 1500 字节,那么生成的抓包文件将是上面这个抓包文件的 20 倍。反过来说,使用同样的磁盘空间,上面这种方式,其抓包时间可以长达默认的 20 倍!
7、怎么知道抓包文件是在哪一端抓取的?
这是一个有趣的问题。尽管我们做抓包的时候很清楚是在哪端做了抓包,但是把文件传给别人后,对方就未必知道这一点,甚至我们自己过段时间也迷糊了:我上次这个抓包文件到底是在客户端上,还是服务端上抓取的?
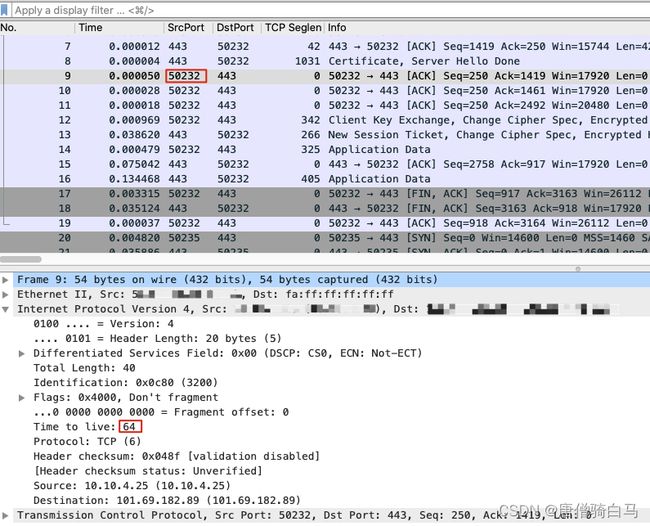
要搞清楚这一点也很简单,我们可以利用 IP 的 TTL 属性。显然,无论是哪一端,它的报文在发出时,其 TTL 就是原始值,也就是 64、128、255 中的某一个。而对端报文的 TTL,因为会经过若干个网络跳数,所以一般都会比 64、128、255 这几个数值要小一些。
所以,我们只要看一下抓包文件中任何一个客户端报文(也就是源端口为高端口)的 TTL,如果它是 64、128 或 255,那说明这个抓包文件就是在客户端做的。反之,就是在服务端做的。
8、如何定位到应用层的请求和返回的报文?
在众多报文中找到应用层请求和对应的响应报文,这个任务用人工去做的话是很繁琐的。还好,用 Wireshark 就很方便。在 Wireshark 界面中,我们很容易找到请求和返回的报文。比如这样:

我们只要选中请求报文,Wireshark 就会自动帮我们匹配到对应的响应报文,反过来也一样。从图上看,应用层请求(这里是 HTTP 请求)是一个向右的箭头,表示数据是进来的方向;应用层响应是一个向左的箭头,表示数据是出去的方向。
9、数据包乱序一定会引起问题吗?
乱序(Out-of-Order),也是我们时常能在 Wireshark 里看到的一类现象。那么,乱序一定会引起问题吗?有一句话叫“脱离了剂量谈毒性就是耍流氓”。其实,乱序是否是问题,也取决于乱序的严重程度。
那第二个问题随之就来了:乱序包达到什么程度,就会真的引起问题?
这个问题,跟实际场景的具体情况也有很大的关系,不同的操作系统以及 TCP 实现细节,都可能有挺大的差异。不过,我还是想正面回答一下这个问题。我的经验是,如果乱序报文达到 10% 以上,就是严重的传输质量问题了,甚至可能导致传输失败,或者应用层的各种卡顿、报错等症状。所以,你可以统计一下乱序包的占比,如果它超过了 10%,就要重视了。