hadoop3 伪分布式安装
1. 环境准备
- 最低硬件要求:CPU 2核、内存:4G、硬盘:100G
- CentOS7 最小安装
- JDK 1.8
- HADOOP 3.3.4
1.1. 主机名 和 IP 地址
# 编辑下方文件,修改内容为自己想要的主机名,如 mitchell-101
hostnamectl set-hostname mitchell-101
# 修改服务器为静态IP,并配置内容
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 在文件中 修改或者新增 以下几项
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.200.101
NETMASK=255.255.255.0
GATEWAY=192.168.200.2
DNS1=192.168.200.2
# 重启网卡
service network restart
# 检查是否能连接外网
ping www.baidu.com
如果是使用 vmware 虚拟机,IP 地址的详细配置请参考:https://www.cnblogs.com/lovling/p/7941201.html
1.2. 安装基础软件包
# 编辑器
yum -y install vim
# 文件上传和下载 rz 和 sz
yum -y install lrzsz
# 跨主机拷贝命令
yum -y install rsync
1.3. 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --state
1.4. 创建操用户
这里的用户名可以根据自己的喜好任意填写,本文使用 mitchell 作为用户
useradd mitchell
passwd mitchell
vim /etc/sudoers
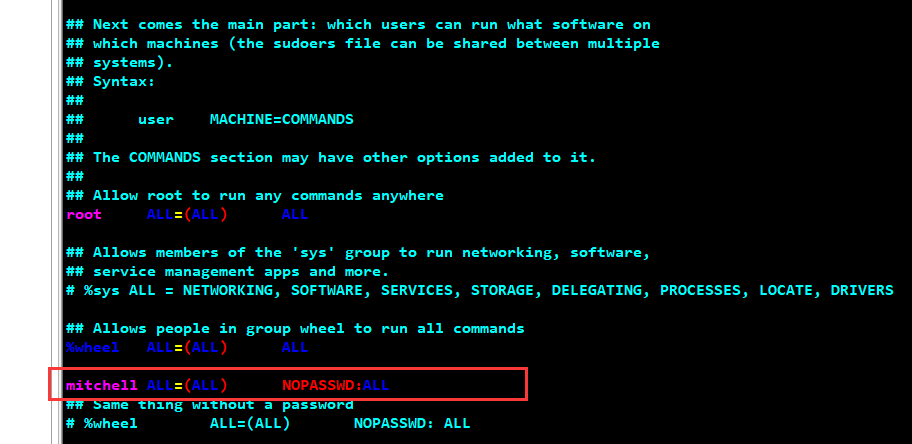
在 /etc/sudoers 文件内容的下图的位置添加如下内容,从而开启 sudo 权限并允许免密切换到 root
mitchell ALL=(ALL) NOPASSWD:ALL
1.5. 目录准备
# 登入 mitcehll 用户,进入 opt 目录
cd /opt
# 创建软件安装目录
sudo mkdir module
# 创金软件包目录
sudo mkdir software
# 将两个目录的拥有者设置为 mitchell 用户
sudo chown mitchell:mitchell module/ software/
1.6. 安装 JDK 和 HADOOP
1.6.1. 下载软件包
下载 jdk,这里选择 1.8
https://www.oracle.com/java/technologies/downloads/#java8
下载 hadoop,这里选择 3.3.4
https://dlcdn.apache.org/hadoop/common/
上传文件到服务器的 /opt/software 目录:可以使用 rz 命令,也可以使用 xftp(推荐)

1.6.2. 安装
将软件解压到 /opt/module 目录
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/module
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/module
配置环境变量
# 创建并编辑环境变量文件
sudo vim /etc/profile.d/my_env.sh
文件中新增以下内容
# JAVA
export JAVA_HOME=/opt/module/jdk1.8.0_321
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP
export HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
读取文件并测试是否安装成功
source /etc/profile.d/my_env.sh
2. 伪分布式集群搭建
我们在学习的过程中,很难有资源同时准备几台服务器来安装 hadoop,那样成本太高了,即使我们选择虚拟机安装 linux 服务器,宿主机也很难有那么大的内存供我们使用,但是 hadoop 是天然分布式的,为了方便我们学习,hadoop 支持了伪分布式的安装模式
2.1. 修改 hosts 文件
sudo vim /etc/hosts
# 添加以下配置
192.168.200.101 mitchell-101
2.2. hadoop 相关配置
2.2.1. core 配置
cd /opt/module/hadoop-3.3.4/etc/hadoop/
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://mitchell-101:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-3.3.4/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>mitchellvalue>
property>
configuration>
2.2.2. hdfs 配置
cd /opt/module/hadoop-3.3.4/etc/hadoop/
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>mitchell-101:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>mitchell-101:9868value>
property>
configuration>
2.2.3. yarn 配置
cd /opt/module/hadoop-3.3.4/etc/hadoop/
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mitchell-101value>
property>
<property>
<name>yarn.application.classpathname>
<value>/opt/module/hadoop-3.3.4/etc/hadoop:/opt/module/hadoop-3.3.4/share/hadoop/common/lib/*:/opt/module/hadoop-3.3.4/share/hadoop/common/*:/opt/module/hadoop-3.3.4/share/hadoop/hdfs:/opt/module/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.3.4/share/hadoop/hdfs/*:/opt/module/hadoop-3.3.4/share/hadoop/mapreduce/*:/opt/module/hadoop-3.3.4/share/hadoop/yarn:/opt/module/hadoop-3.3.4/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.3.4/share/hadoop/yarn/*value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://mitchell-101:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation-secondsname>
<value>604800value>
property>
configuration>
2.2.4. mapred 配置
cd /opt/module/hadoop-3.3.4/etc/hadoop/
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>mitchell-101:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>mitchell-101:19888value>
property>
configuration>
2.2.5. worker 配置
vim workers
# 加入以下内容
mitchell-101
2.2.6. 配置免密登入
我们在执行上面脚本的时候,每次都需要输入密码,很是麻烦,这里我们可以通过配置 ssh 免密从而减少操作
最好是三台机器都依次配置一下,方便我们在运行分发脚本时,不用每次都输入密码
# 进入 ssh 目录,如果用户目录下没有 .ssh 目录,需要执行一次 ssh 命令
cd /home/mitchell/
ll -a
cd .ssh
# 生成秘钥(执行命令后连续三次回车即可)
ssh-keygen -t rsa
# 分发秘钥到需要免密登入的机器,这样 102 这台机器就可以不用密码直接控制 103 和 104 了
# 注意自己也需要分发,如当前是 102 也需要 分发 102
ssh-copy-id mitchell-101
# 查看是否免密设置成功,三台机器分别执行,如下图为设置成功
cat /home/mitchell/.ssh/authorized_keys

2.3. 启动集群
2.3.1. 常用启动命令
# 【102】初始化,只需要执行一次,后续可以直接启动
hdfs namenode -format
# 【102】启动 和 关闭 hdfs
start-dfs.sh
stop-dfs.sh
# 【103】启动 和 关闭 yarn
start-yarn.sh
stop-yarn.sh
# 【102】启动 和关闭 历史服务器
mapred --daemon start historyserver
mapred --daemon stop historyserver
2.3.2. 集群开关脚本
脚本内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "NO Args Input"
exit;
fi
case $1 in
"start")
echo "=============================== 启动 hadoop 伪集群 ==============================="
echo "------------------------------- 启动 hdfs -------------------------------"
/opt/module/hadoop-3.3.4/sbin/start-dfs.sh
echo "------------------------------- 启动 yarn -------------------------------"
/opt/module/hadoop-3.3.4/sbin/start-yarn.sh
echo "------------------------------- 启动 historyserver -------------------------------"
/opt/module/hadoop-3.3.4/bin/mapred --daemon start historyserver
;;
"stop")
echo "=============================== 关闭 hadoop 伪集群 ==============================="
echo "------------------------------- 关闭 historyserver -------------------------------"
/opt/module/hadoop-3.3.4/bin/mapred --daemon stop historyserver
echo "------------------------------- 关闭 yarn -------------------------------"
/opt/module/hadoop-3.3.4/sbin/stop-yarn.sh
echo "------------------------------- 关闭 hdfs -------------------------------"
/opt/module/hadoop-3.3.4/sbin/stop-dfs.sh
;;
*)
echo "Input Args Error..."
;;
esac
服务器上的操作
# 编辑一个文件写入上面的内容
vim /home/mitchell/bin/myhadoop.sh
# 赋予执行权限
chmod +x /home/mitchell/bin/myhadoop.sh
# 启动 或者 关闭 集群
myhadoop.sh start
myhadoop.sh stop
2.3.3. 测试集群
先准备一个文件
cd /opt/module/hadoop-3.3.4
mkdir wcinput
vim wcinput/word.txt
# word.txt 文件中写入一些单词。如
haha hello name
nihao sima wo
haha cls
cks haha cls
文件上传到集群,并且做文件分析
# 创建文件夹:其中 /input 为相对于 hdfs 的文件路径
hadoop fs -mkdir /input
# 上传文件:其中 wcinput/word.txt 磁盘下文件,/input 为上一步创建的相对 hsfs 的路径
# 我们在 word.txt 中写入一些单词,单词和单词之间用 空格隔开
hadoop fs -put wcinput/word.txt /input
# 测试 MR
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
出现如下命令则一切 OK

2.4. 可视化界面
hdfs 界面:http://mitchell-101:9870/explorer.html#/
yarn 界面:http://mitchell-101:8088/cluster
其它还有 历史服务器 和 日期服务器,可以从 yarn 点击进入