MHA的集群架构实现高可用
MHA架构的部署
-
-
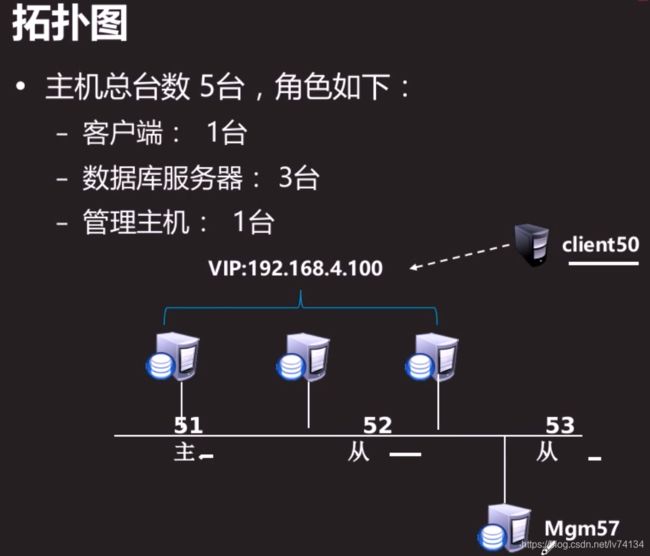
- 实验环境
- 实验准备
-
- 一,安装MHA
-
- 1、安装依赖环境
- 2、安装MHA的node组件
- 3、在MHA节点上安装manager组件
- 4、四台服务器设置ssh免密登录
- 5、配置MHA
-
- (1)设置脚本管理vip
- (2)配置MHA的配置文件
- 6,检查和启动manager
-
- 7、验证
- 二、故障修复步骤
-
- 1、修复db
- 2、修复主从
- #3、修改配置文件
-
- 4、启动manager

定义节点服务器名称
hostnamectl set-hostname manager
su
hostnamectl set-hostname master
su
hostnamectl set-hostname slave1
su
hostnamectl set-hostname slave2
su
实验环境
主:192.168.100.7
从1:192.168.100.5
从2:192.168.100.6
#配置主从复制和mha的vip等
MHA管理服务器:192.168.100.8 #安装了mha服务
client客户端:192.168.100.3
实验准备
三台服务器安装mysql并初始化(参考:https://blog.csdn.net/lv74134/article/details/118149487?spm=1001.2014.3001.5501)
三台mysql服务设置主从
可参考文章:https://blog.csdn.net/lv74134/article/details/118858341?spm=1001.2014.3001.5501
#配置MySQL 一主两从
⭐⭐#在所有数据库节点上授权两个用户,一个是从库同步使用,另一个是manager使用
grant replication slave on *.* to 'myslave'@'192.168.100.%' identified by '123456';
grant all privileges on *.* to 'mha'@'192.168.100.%' identified by 'manager';
⭐⭐#下面三条授权理论上不用添加,但是实验环境通过MHA检查MySQL主从报错,
报两个从库通过主机名连接不上主库,所以所有数据库都需要添加以下授权
通过mha检查的时候,是通过主机名的形式进行监控,这种情况会容易报错
grant all privileges on *.* to 'mha'@'master' identified by 'manager';
grant all privileges on *.* to 'mha'@'slave1' identified by 'manager';
grant all privileges on *.* to 'mha'@'slave2' identified by 'manager';
#所有从库开启只读功能(不会对超级管理员super生效,普通用户)
set global read_only=1;
flush privileges;
#在master上查看二进制文件和同步点
show master status;
#在两台节点服务器进行同步
change master to master_host='192.168.100.7',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=2963;
start slave;
show slave status\G;
一,安装MHA
1、安装依赖环境
给集群内四台(主从3,mha1)的服务器每个都安装mha的依赖环境
[root@master ~]# systemctl stop firewalld
[root@master ~]# setenforce 0
[root@master ~]# yum install epel-release --nogpgcheck -y
//--nogpgcheck 不进行gpg检查
yum install -y perl-DBD-MySQL \
perl-Config-Tiny \
perl-Log-Dispatch \
perl-Parallel-ForkManager \
perl-ExtUtils-CBuilder \
perl-ExtUtils-MakeMaker \
perl-CPAN
解析
[root@master ~]# yum install -y perl-DBD-MySQL \ //perl 针对mysql数据库的包
perl-Config-Tiny \ //从配置文件中去提取数据
perl-Log-Dispatch \ //日志
perl-Parallel-ForkManager \ //多线程管理
perl-ExtUtils-CBuilder \ //扩展工具
perl-ExtUtils-MakeMaker \
perl-CPAN //程序库
ntpdate ntp.aliyun.com #同步时间
2、安装MHA的node组件
MHA软件包对于每个操作版本不一样,这里centos7.4必须选择0.57版本
在所有(四台)服务器上必须先安装node组件,最后再manager节点上安装manager组件
因为manager依赖node组件,下面都是在master上操作演示安装node组件
上传mha4mysql-node-0.57.tar.gz到/opt
tar zxvf /opt/mha4mysql-node-0.57.tar.gz -C /root
cd /root/mha4mysql-node-0.57
perl Makefile.PL
make && make install
3、在MHA节点上安装manager组件
(必须先安装node才能安装manager组件)
mha4mysql-manager-0.57.tar.gz上传到/opt下
tar zxvf /opt/mha4mysql-manager-0.57.tar.gz -C /root
cd mha4mysql-manager-0.57
perl Makefile.PL
make && make install
4、四台服务器设置ssh免密登录
ssh-keygen -t rsa
ssh-copy-id 192.168.226.128
ssh-copy-id 192.168.226.129
ssh-copy-id 192.168.226.131
ssh-copy-id 192.168.226.132
5、配置MHA
(1)设置脚本管理vip
在MHA节点上复制相关脚本到/usr/local/bin目录
cp -ra /root/mha4mysql-manager-0.57/samples/scripts/ /usr/local/bin
#-a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容
#-r: 递归
cp /usr/local/bin/scripts/master_ip_failover /usr/local/bin
vim /usr/local/bin/master_ip_failover (#删除原有内容,直接复制)
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1.log
master_binlog_dir=/usr/local/mysql/data
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
password=manager
ping_interval=1
remote_workdir=/tmp
repl_password=123123
repl_user=myslave
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.100.5 -s 192.168.100.6
shutdown_script=""
ssh_user=root
user=mha
[server1]
hostname=192.168.100.7
port=3306
[server2]
candidate_master=1
hostname=192.168.100.6
check_repl_delay=0
port=3306
[server3]
hostname=192.168.247.5
port=3306
(2)配置MHA的配置文件
mkdir /etc/masterha
cp /root/mha4mysql-manager-0.57/samples/conf/app1.cnf /etc/masterha/
vim /etc/masterha/app1.cnf
解析
[server default]
manager_log=/var/log/masterha/app1/manager.log //manager日志
manager_workdir=/var/log/masterha/app1.log //manager工作目录
master_binlog_dir=/usr/local/mysql/data //master保存binlog的位置,这里的路径要与master里配置的binlog的相同
master_ip_failover_script=/usr/local/bin/master_ip_failover //设置自动failover时候的切换脚本。也就是上边的那个脚本
master_ip_online_change_script=/usr/local/bin/master_ip_online_change //设置手动切换时候的切换脚本
password=manager //这个密码是前文中创建监控用户的那个密码
ping_interval=1 //设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp //设置远程mysql时在发生切换时的日志binlog的保存位置
repl_password=123456 //设置复制同步用户密码
repl_user=myslave //设置复制同步用户的用户
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.100.5 -s 192.168.100.6 //设置发生切换后发生报警的脚本,后面跟两个从服务器地址
shutdown_script="" //设置故障发生关闭故障脚本主机,此处没有指定脚本,代表不关闭
ssh_user=root //设置ssh的登录用户名
user=mha //设置监控用户
#[server1]
#hostname=192.168.100.7
#port=3306
#这个是master的ip
[server2]
candidate_master=1 //设置为候选master,如果设置该参数以后,MHA发送主从切换以后将会从此从库升级为主库,即使这个主库不是集群中事件最全的
hostname=192.168.100.6
check_repl_delay=0 //检查repl延迟为0,支持:默认情况下如果一个slave落后master 100M的relay logs话,MHA将不会选择该slave作为一个新的master,
port=3306
[server3]
hostname=192.168.100.5
port=3306
6,检查和启动manager
#测试无密码认证,如果正常会输出successfully
masterha_check_ssh -conf=/etc/masterha/app1.cnf
#测试主从复制
masterha_check_repl -conf=/etc/masterha/app1.cnf
#需注意:第一次配置需要在master节点上手动开启虚拟IP
/sbin/ifconfig ens32:1 192.168.100.100


#启动MHA
#启动时会进行日志记录(在后台开启)
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &

#查看到当前的master节点是谁
[root@manager masterha]# masterha_check_status --conf=/etc/masterha/app1.cnf app1 (pid:116353) is running(0:PING_OK), master:192.168.100.7
#查看当前日志信息
cat /var/log/masterha/app1/manager.log
#查看MySQL的VIP地址 192.168.100.100是否存在,这个VIP地址不会因为manager节点停止MHA服务而消失
ifconfig

7、验证
(1)在原master上模拟故障,查看master变化
pkill -9 mysql
tail -f /var/log/masterha/app1/manager.log #在manager上查看日志,100.6正常转换到新的master

在100.5上查看主服务器的ip
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.6 #变换成的100.6
Master_User: myslave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 154
Relay_Log_File: relay-log-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
.........
(2)、观察中继日志relay
在新master上插入新数据
mysql> create database info;
Query OK, 1 row affected (0.00 sec)
mysql> use info;
Database changed
mysql> create table info (id int);
Query OK, 0 rows affected (0.01 sec)
观察新master的二进制和中继日志
cd /usr/local/mysql/data
mysqlbinlog --no-defaults --base64-output=decode-rows -v master-bin.0000003
mysqlbinlog --no-defaults --base64-output=decode-rows -v relay-log-bin.000001
查询100.5上的中继日志
mysqlbinlog --no-defaults --base64-output=decode-rows -v relay-log-bin.000002
# at 479
#210721 21:15:46 server id 6 end_log_pos 378 CRC32 0x443c8c45 Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=no
SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;
# at 544
#210721 21:15:46 server id 6 end_log_pos 478 CRC32 0x673bd143 Query thread_id=47 exec_time=0 error_code=0
use `info`/*!*/;
SET TIMESTAMP=1626873346/*!*/;
create table info (id int) #新建的数据通过relay同步到了从服务器上
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
二、故障修复步骤
1、修复db
在原来的主服务器上,开启中继日志功能、注释允许同步,
log_bin=master-bin
#log_slave=updates=true
server_id=7
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
systemctl restart mysqld.service
2、修复主从
主备服务器:show master status;
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000003 | 154 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
#修复的master:
change master to master_host='192.168.100.7',master_user='myslave',master_password='123456',master_log_file='master-bin.000003',master_log_pos=154;
start slave;
set global read_only=1;
flush privileges;
#3、修改配置文件
(再把这个记录添加进去,因为它检测到失效时候会自动消失
[server1]
hostname=192.168.226.129
port=3306
4、启动manager
(在manager那台机器上)
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
masterha_check_status --conf=/etc/masterha/app1.cnf
#查看到当前的master节点是谁
masterha_check_status --conf=/etc/masterha/app1.cnf
#解决中英字不兼容报错的问题
dos2unix /usr/local/bin/master_ip_failover