Pandas最详细教程来了!

导读:在Python中,进行数据分析的一个主要工具就是Pandas。Pandas是Wes McKinney在大型对冲基金AQR公司工作时开发的,后来该工具开源了,主要由社区进行维护和更新。
Pandas具有NumPy的ndarray所不具有的很多功能,比如集成时间序列、按轴对齐数据、处理缺失数据等常用功能。Pandas最初是针对金融分析而开发的,所以很适合用于量化投资。
作者:赵志强 刘志伟
来源:大数据DT(ID:hzdashuju)

在使用Pandas之前,需要导入Pandas包。惯例是将pandas简写为pd,命令如下:
import pandas as pd
Pandas包含两个主要的数据结构:Series和DataFrame。其中最常用的是DataFrame,下面我们先来学习一下DataFrame。
01 DataFrame入门
DataFrame是一个表格型的数据结构。每列都可以是不同的数据类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,这两种索引在DataFrame的实现上,本质上是一样的。但在使用的时候,往往是将列索引作为区分不同数据的标签。DataFrame的数据结构与SQL数据表或者Excel工作表的结构非常类似,可以很方便地互相转换。
下面先来创建一个DataFrame,一种常用的方式是使用字典,这个字典是由等长的list或者ndarray组成的,示例代码如下:
data={'A':['x','y','z'],'B':[1000,2000,3000],'C':[10,20,30]}
df=pd.DataFrame(data,index=['a','b','c'])
df
运行结果如图3-2所示。

▲图3-2
我们可以看到,DataFrame主要由如下三个部分组成。
数据,位于表格正中间的9个数据就是DataFrame的数据部分。
索引,最左边的a、b、c是索引,代表每一行数据的标识。这里的索引是显式指定的。如果没有指定,会自动生成从0开始的数字索引。
列标签,表头的A、B、C就是标签部分,代表了每一列的名称。
下文列出了DataFrame函数常用的参数。其中,“类似列表”代表类似列表的形式,比如列表、元组、ndarray等。一般来说,data、index、columns这三个参数的使用频率是最高的。
data:ndarray/字典/类似列表 | DataFrame数据;数据类型可以是ndarray、嵌套列表、字典等
index:索引/类似列表 | 使用的索引;默认值为range(n)
columns:索引/类似列表 | 使用的列标签;默认值为range(n)
dtype:dtype | 使用(强制)的数据类型;否则通过推导得出;默认值为None
copy:布尔值 | 从输入复制数据;默认值为False
其中data的数据类型有很多种。
下文列举了可以作为data传给DataFrame函数的数据类型。
可以传给DataFrame构造器的数据:
二维ndarray:可以自行指定索引和列标签
嵌套列表或者元组:类似于二维ndarray
数据、列表或元组组成的字典:每个序列变成一列。所有序列长度必须相同
由Series组成的字典:每个Series会成为一列。如果没有指定索引,各Series的索引会被合并
另一个DataFrame:该DataFrame的索引将会被沿用
前面生成了一个DataFrame,变量名为df。下面我们来查看一下df的各个属性值。
获取df数据的示例代码如下:
df.values
输出结果如下:
array([['x', 1000, 10],
['y', 2000, 20],
['z', 3000, 30]], dtype=object)
获取df行索引的示例代码如下:
df.index
输出结果如下:
Index(['a', 'b', 'c'], dtype='object')
获取df列索引(列标签)的示例代码如下:
df.columns
输出结果如下:
Index(['A', 'B', 'C'], dtype='object')
可以看到,行索引和列标签都是Index数据类型。
创建的时候,如果指定了列标签,那么DataFrame的列也会按照指定的顺序进行排列,示例代码如下:
df=pd.DataFrame(data,columns=['C','B','A'],index=['a','b','c'])
df
运行结果如图3-3所示。

▲图3-3
如果某列不存在,为其赋值,会创建一个新列。我们可以用这种方法来添加一个新的列:
df['D']=10
df
运行结果如图3-4所示。

▲图3-4
使用del命令可以删除列,示例代码如下:
del df['D']
df
运行结果如图3-5所示。

▲图3-5
添加行的一种方法是先创建一个DataFrame,然后再使用append方法,代码如下:
new_df=pd.DataFrame({'A':'new','B':4000,'C':40},index=['d'])
df=df.append(new_df)
df
运行结果如图3-6所示。

▲图3-6
或者也可以使用loc方法来添加行,示例代码如下:
df.loc['e']=['new2',5000,50]
df
运行结果如图3-7所示。

▲图3-7
loc方法将在后面的内容中详细介绍。
索引的存在,使得Pandas在处理缺漏信息的时候非常灵活。下面的示例代码会新建一个DataFrame数据df2。
df2=pd.DataFrame([1,2,3,4,5],index=['a','b','c','d','z'],columns=['E'])
df2
运行结果如图3-8所示。

▲图3-8
如果现在想要合并df和df2,使得df有一个新的列E,那么可以使用join方法,代码如下:
df.join(df2)
运行结果如图3-9所示。

▲图3-9
可以看到,df只接受索引已经存在的值。由于df2中没有索引e,所以是NaN值,而且df2索引为z的值已经丢失了。为了保留df2中索引为z的值,我们可以提供一个参数,告诉Pandas如何连接。示例代码如下:
df.join(df2,how='outer')
运行结果如图3-10所示。
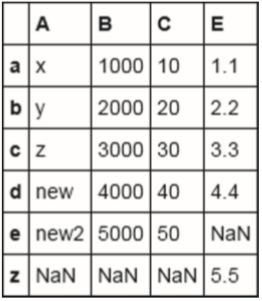
▲图3-10
在上述代码中,how='outer'表示使用两个索引中所有值的并集。连接操作的其他选项还有inner(索引的交集)、left(默认值,调用方法的对象的索引值)、right(被连接对象的索引值)等。
在金融数据分析中,我们要分析的往往是时间序列数据。下面介绍一下如何基于时间序列生成DataFrame。为了创建时间序列数据,我们需要一个时间索引。这里先生成一个DatetimeIndex对象的日期序列,代码如下:
dates=pd.date_range('20160101',periods=8)
dates
输出结果如下:
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06', '2016-01-07', '2016-01-08'],dtype='da
tetime64[ns]', freq='D')
可以看到,使用Pandas的date_range函数生成的是一个DatetimeIndex对象。date_range函数的参数及说明如下所示:
start:字符串/日期时间 | 开始日期;默认为None
end:字符串/日期时间 | 结束日期;默认为None
periods:整数/None | 如果start或者end空缺,就必须指定;从start开始,生成periods日期数据;默认为None
freq:dtype | 周期;默认是D,即周期为一天。也可以写成类似5H的形式,即5小时。其他的频率参数见下文
tz:字符串/None | 本地化索引的时区名称
normalize:布尔值 | 将start和end规范化为午夜;默认为False
name:字符串 | 生成的索引名称
date_range函数频率的参数及说明如下所示:
B:交易日
C:自定义交易日(试验中)
D:日历日
W:每周
M:每月底
SM:半个月频率(15号和月底)
BM:每个月份最后一个交易日
CBM:自定义每个交易月
MS:日历月初
SMS:月初开始的半月频率(1号,15号)
BMS:交易月初
CBMS:自定义交易月初
Q:季度末
BQ:交易季度末
QS:季度初
BQS:交易季度初
A:年末
BA:交易年度末
AS:年初
BAS:交易年度初
BH:交易小时
H:小时
T,min:分钟
S:秒
L,ms:毫秒
U,us:微秒
N:纳秒
接下来,我们再基于dates来创建DataFrame,代码如下:
df=pd.DataFrame(np.random.randn(8,4),index=dates,columns=list('ABCD'))
df
运行结果如图3-11所示。

▲图3-11
有了df,我们就可以使用多个基于DataFrame的内建方法了,下面来看看相关的示例。
按列求总和,代码如下:
df.sum()输出结果如下:
A 0.241727
B -0.785350
C -0.547433
D -1.449231
dtype: float64
按列求均值,代码如下:
df.mean()输出结果如下:
A 0.030216
B -0.098169
C -0.068429
D -0.181154
dtype: float64
按列求累计总和,代码如下:
df.cumsum()运行结果如图3-12所示。

▲图3-12
使用describe一键生成多种统计数据,代码如下:
df.describe()运行结果如图3-13所示。
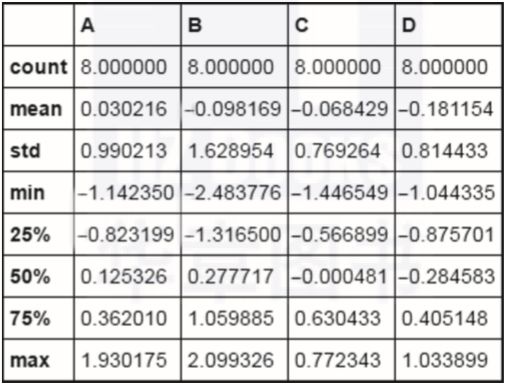
▲图3-13
可以根据某一列的值进行排序,代码如下:
df.sort_values('A')运行结果如图3-14所示。

▲图3-14
根据索引(日期)排序(这里是倒序),代码如下:
df.sort_index(ascending=False)运行结果如图3-15所示。
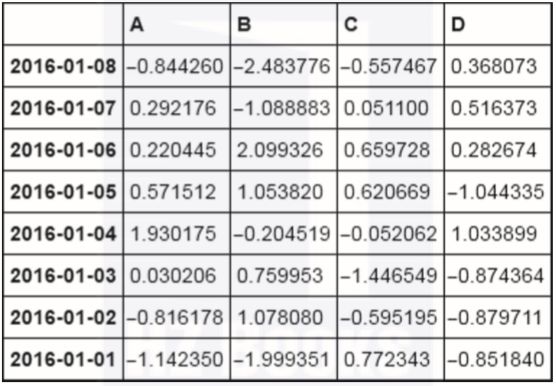
▲图3-15
选取某一列,返回的是Series对象,可以使用df.A,代码如下:
df['A']
输出结果如下:
2016-01-01 -1.142350
2016-01-02 -0.816178
2016-01-03 0.030206
2016-01-04 1.930175
2016-01-05 0.571512
2016-01-06 0.220445
2016-01-07 0.292176
2016-01-08 -0.844260
Freq: D, Name: A, dtype: float64
使用[]选取某几行,代码如下:
df[0:5]
运行结果如图3-16所示。

▲图3-16
根据标签(Label)选取数据,使用的是loc方法,代码如下:
df.loc[dates[0]]
输出结果如下:
A -1.142350
B -1.999351
C 0.772343
D -0.851840
Name: 2016-01-01 00:00:00, dtype: float64
再来看两个示例代码。
df.loc[:,['A','C']]
运行结果如图3-17所示。

▲图3-17
df.loc['20160102':'20160106',['A','C']]
运行结果如图3-18所示。

▲图3-18
需要注意的是,如果只有一个时间点,那么返回的值是Series对象,代码如下:
df.loc['20160102',['A','C']]
输出结果如下:
A -0.816178
C -0.595195
Name: 2016-01-02 00:00:00, dtype: float64
如果想要获取DataFrame对象,需要使用如下命令:
df.loc['20160102':'20160102',['A','C']]
运行结果如图3-19所示。

▲图3-19
上面介绍的是loc方法,是按标签(索引)来选取数据的。有时候,我们会希望按照DataFrame的绝对位置来获取数据,比如,如果想要获取第3行第2列的数据,但不想按标签(索引)获取,那么这时候就可以使用iloc方法。
根据位置选取数据,代码如下:
df.iloc[2]
输出结果如下:
A 0.030206
B 0.759953
C -1.446549
D -0.874364
Name: 2016-01-03 00:00:00, dtype: float64
再来看一个示例:
df.iloc[3:6,1:3]
运行结果如图3-20所示。

▲图3-20
注意:对于DataFrame数据类型,可以使用[]运算符来进行选取,这也是最符合习惯的。但是,对于工业代码,推荐使用loc、iloc等方法。因为这些方法是经过优化的,拥有更好的性能。
有时,我们需要选取满足一定条件的数据。这个时候可以使用条件表达式来选取数据。这时传给df的既不是标签,也不是绝对位置,而是布尔数组(Boolean Array)。下面来看一下示例。
例如,寻找A列中值大于0的行。首先,生成一个布尔数组,代码如下:
df.A>0
输出结果如下:
2016-01-01 False
2016-01-02 False
2016-01-03 True
2016-01-04 True
2016-01-05 True
2016-01-06 True
2016-01-07 True
2016-01-08 False
Freq: D, Name: A, dtype: bool
可以看到,这里生成了一个Series类型的布尔数组。可以通过这个数组来选取对应的行,代码如下:
df[df.A>0]
运行结果如图3-21所示。

▲图3-21
从结果可以看到,A列中值大于0的所有行都被选择出来了,同时也包括了BCD列。
现在我们要寻找df中所有大于0的数据,先生成一个全数组的布尔值,代码如下:
df>0
运行结果如图3-22所示。

▲图3-22
下面来看一下使用df>0选取出来的数据效果。由图3-23可以看到,大于0的数据都能显示,其他数据显示为NaN值。
df[df>0]
运行结果如图3-23所示。

▲图3-23
再来看一下如何改变df的值。首先我们为df添加新的一列E,代码如下:
df['E']=0
df
运行结果如图3-24所示。

▲图3-24
使用loc改变一列值,代码如下:
df.loc[:,'E']=1
df
运行结果如图3-25所示。

▲图3-25
使用loc改变单个值,代码如下:
df.loc['2016-01-01','E'] = 2
df
运行结果如图3-26所示。

▲图3-26
使用loc改变一列值,代码如下:
df.loc[:,'D'] = np.array([2] * len(df))
df运行结果如图3-27所示。

▲图3-27
可以看到,使用loc的时候,x索引和y索引都必须是标签值。对于这个例子,使用日期索引明显不方便,需要输入较长的字符串,所以使用绝对位置会更好。这里可以使用混合方法,DataFrame可以使用ix来进行混合索引。比如,行索引使用绝对位置,列索引使用标签,代码如下:
df.ix[1,'E'] = 3
df
运行结果如图3-28所示。

▲图3-28
ix的处理方式是,对于整数,先假设为标签索引,并进行寻找;如果找不到,就作为绝对位置索引进行寻找。所以运行效率上会稍差一些,但好处是这样操作比较方便。
对于ix的用法,需要注意如下两点。
假如索引本身就是整数类型,那么ix只会使用标签索引,而不会使用位置索引,即使没能在索引中找到相应的值(这个时候会报错)。
如果索引既有整数类型,也有其他类型(比如字符串),那么ix对于整数会直接使用位置索引,但对于其他类型(比如字符串)则会使用标签索引。
总的来说,除非想用混合索引,否则建议只使用loc或者iloc来进行索引,这样可以避免很多问题。
02 Series
Series类似于一维数组,由一组数据以及相关的数据标签(索引)组成。示例代码如下:
import pandas as pd
s=pd.Series([1,4,6,2,3])
s
Out:
0 1
1 4
2 6
3 2
4 3
在这段代码中,我们首先导入pandas并命名为pd,然后向Series函数传入一个列表,生成一个Series对象。在输出Series对象的时候,左边一列是索引,右边一列是值。由于没有指定索引,因此会自动创建0到(N-1)的整数索引。也可以通过Series的values和index属性获取其值和索引。示例代码如下:
s.values
Out:
array([1, 4, 6, 2, 3], dtype=int64)s.index
Out:
Int64Index([0, 1, 2, 3, 4], dtype='int64')
当然,我们也可以对索引进行定义,代码如下:
s=pd.Series([1,2,3,4],index=['a','b','c','d'])
s
Out:
a 1
b 2
c 3
d 4
在这里,我们将索引定义为a、b、c、d。这时也可以用索引来选取Series的数据,代码如下:
s['a']
Out:
1s[['b','c']]
Out:
b 2
c 3
对Series进行数据运算的时候也会保留索引。示例代码如下:
s[s>1]
Out:
b 2
c 3
d 4s*3
Out:
a 3
b 6
c 9
d 12
Series最重要的功能之一是在不同索引中对齐数据。示例代码如下:
s1=pd.Series([1,2,3],index=['a','b','c'])
s2=pd.Series([4,5,6],index=['b','c','d'])
s1+s2
Out:
a NaN
b 6
c 8
d NaN
Series的索引可以通过赋值的方式直接修改,示例代码如下:
s.index
Out:
Index([u'a', u'b', u'c', u'd'], dtype='object')s.index=['w','x','y','z']
s.index
Out:
Index([u'w', u'x', u'y', u'z'], dtype='object')
s
Out:
w 1
x 2
y 3
z 4
关于作者:赵志强,金融量化与建模专家,目前在金融科技公司负责金融大数据产品工作,专注于研究Al在金融领域的落地应用。曾在由诺奖得主Robert Engle领导的上海纽约大学波动研究所研究全球金融风险,并和上交所、中金所合作完成多项科研项目。曾在摩根士丹利华鑫基金、明汯投资负责量化投资研究工作,内容包括股票多因子、期货CTA和高频交易等。
刘志伟,在中国银联云闪付事业部从事数据分析、数据挖掘等工作。对自然语言处理、文本分类、实体识别、关系抽取、传统机器学习,以及大数据技术栈均有实践经验。目前正在探索相关技术在金融场景内的落地应用,包括自动知识图谱、大规模文本信息抽取结构化、异常识别等领域,关注人工智能行业前沿技术发展。
本文摘编自《Python量化投资:技术、模型与策略》,理论与实践相结合,基于Python阐述量化投资理论和策略,深入分析Python在量化投资分析中具体的应用案例。

直播预告
华章特别邀请到《Python量化投资:技术、模型与策略》的作者赵志强老师作客华章直播间,重含量、高价值、超干货的大咖分享,等你来!

直播主题:Python量化投资如何入门?
直播时间:4月24日 20:00-21:00
主讲人:赵志强,金融量化与建模专家,目前在金融科技公司负责金融大数据产品工作,专注于研究Al在金融领域的落地应用。曾在由诺奖得主Robert Engle领导的上海纽约大学波动研究所研究全球金融风险,并和上交所、中金所合作完成多项科研项目。曾在摩根士丹利华鑫基金、明汯投资负责量化投资研究工作,内容包括股票多因子、期货CTA和高频交易等。
直播介绍:介绍Python在量化投资中的各种应用场景,新手应该如何入门,学习阶梯是什么?


扫码关注【华章计算机】视频号
每天来听华章哥讲书

更多精彩回顾
书讯 | 4月书讯 | 好书和最美四月天一起来了...
资讯 | DB-Engines 4月数据库排名:Redis有望甩掉“千年老七”?
书单 | 8本书助你零基础转行数据分析岗
干货 | 什么是架构?网络架构中都有什么?终于有人讲明白了
收藏 | 终于有人把Scrapy爬虫框架讲明白了
上新 | 河马书来了!线上实验领域的“圣经”火热预售中
直播 | 筑牢“数据基座” 掘金数字经济——5位大咖畅聊金融科技
活动 | Book多得的奇遇,给爱读书的你们最大的优惠力度
赠书 | 【第51期】推荐几本深入学习Java的书,助你走向Java技术的巅峰


点击阅读全文观看直播