【Flink】DataStream API—执行环境、源算子、转换算子、输出算子
目录
前言
一、执行环境
1、创建执行环境
2、执行模式(Execution Mode)
3、触发执行
二、源算子(Source)
1、读取数据的算子就是源算子。
2、源算子种类
3、Flink 支持的数据类型
三、转换算子(Transformation)
1、基本转换算子
2、聚合算子(Aggregation)
3、匿名函数(Lambda)
4、富函数类(Rich Function Classes)
5、物理分区
四、输出算子(Sink)
1、连接到外部系统
2、输出到文件
3、输出到 Kafka
4、输出到 Redis
5、输出到 Elasticsearch
6、输出到 MySQL(JDBC)
7、自定义 Sink 输出
前言
- 获取执行环境(execution environment)
- 读取数据源(source)
- 定义基于数据的转换操作(transformations)
- 定义计算结果的输出位置(sink)
- 触发程序执行(execute)

一、执行环境
1、创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();StreamExecutionEnvironment localEnv =
StreamExecutionEnvironment.createLocalEnvironment();StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager 主机名
1234, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);2、执行模式(Execution Mode)
- 流执行模式(STREAMING)
- 批执行模式(BATCH)
- 自动模式(AUTOMATIC)
(1)设置方式
- 通过命令行配置
- 通过代码配置
建议 : 不要在代码中配置,而是使用命令行。这同设置并行度是类似的:在提交作业时指定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理。而在 代码中硬编码(hard code )的方式可扩展性比较差,一般都不推荐。
3、触发执行
二、源算子(Source)
1、读取数据的算子就是源算子。
DataStream stream = env.addSource(...); POJO:一个简单的Java类,这个类没有实现/继承任何特殊的java接口或者类,不遵循任何主要java模型,约定或者框架的java对象。在理想情况下,POJO不应该有注解。方便数据的解析和序列化。
2、源算子种类
(1)从集合中读取数据
// 构建集合
ArrayList clicks = new ArrayList<>();
clicks.add(new Event("Mary","./home",1000L));
clicks.add(new Event("Bob","./cart",2000L));
DataStream stream = env.fromCollection(clicks); // 不构建集合,直接列出元素
DataStreamSource stream2 = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
); DataStream stream = env.readTextFile("clicks.csv"); 
(3)从 Socket 读取数据
DataStream stream = env.socketTextStream("localhost", 7777); (4)从 Kafka 读取数据
- 引入 Kafka 连接器的依赖
org.apache.flink
flink-connector-kafka_2.12
1.13.0
-
然后调用 env.addSource() ,传入 FlinkKafkaConsumer 的对象实例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop102:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource stream = env.addSource(new FlinkKafkaConsumer(
"clicks",
new SimpleStringSchema(),
properties
)); (5)自定义 Source
- run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
- cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
3、Flink 支持的数据类型
(1)类型系统
TypeInformation 类是 Flink 中所有类型描述符的基类。 它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
(2)基本类型
- Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多
- Scala 样例类及 Scala 元组:不支持空字段
- 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
- POJO:Flink 自定义的类似于 Java bean 模式的类

(5)辅助类型
Option、Either、List、Map 等
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));三、转换算子(Transformation)
1、基本转换算子
(1)映射(map) :就是一个“一一映射”,消费一个元素就产出一个元素

// 传入匿名类,实现 MapFunction
stream.map(new MapFunction() {
@Override
public String map(Event e) throws Exception {
return e.user;
}
});
// 传入 MapFunction 的实现类
stream.map(new UserExtractor()).print(); (2)过滤:filter 转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。
// 传入匿名类实现 FilterFunction
stream.filter(new FilterFunction() {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
}); (3)扁平映射:
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten) 和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。 flatMap 并没有直接定义返回值类型,而是通过一个(Collector)来 指定输出。
同 map 一样,flatMap 也可以使用 Lambda 表达式或者 FlatMapFunction 接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
2、聚合算子(Aggregation)
(1)按键分区(keyBy):在 Flink 中,需要先进行分区,再做聚合; 这个操作就是通过 keyBy 来完成的。keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应 着任务槽(task slot)。
// 使用 Lambda 表达式
KeyedStream keyedStream = stream.keyBy(e -> e.user);
// 使用匿名类实现 KeySelector
KeyedStream keyedStream1 = stream.keyBy(new KeySelector() {
@Override
public String getKey(Event e) throws Exception {
return e.user;
}
}); (2)简单聚合
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
stream.keyBy(r -> r.f0).min(1).print();
stream.keyBy(r -> r.f0).min("f1").print();
stream.keyBy(r -> r.f0).maxBy(1).print();
stream.keyBy(r -> r.f0).maxBy("f1").print();
stream.keyBy(r -> r.f0).minBy(1).print();
stream.keyBy(r -> r.f0).minBy("f1").print();
// 如果数据流的类型是 POJO 类,那么就只能通过字段名称来指定,不能通过位置来指定了。
(3)归约聚合(reduce)
public interface ReduceFunction extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
} 3、匿名函数(Lambda)
//map 函数使用 Lambda 表达式,返回简单类型,不需要进行类型声明
DataStream stream1 = clicks.map(event -> event.url);
// flatMap 使用 Lambda 表达式,必须通过 returns 明确声明返回类型
DataStream stream2 = clicks.flatMap((Event event, Collector
out) -> {
out.collect(event.url);
}).returns(Types.STRING);
// 使用显式的 ".returns(...)"
DataStream> stream3 = clicks
.map( event -> Tuple2.of(event.user, 1L) )
.returns(Types.TUPLE(Types.STRING, Types.LONG));
stream3.print(); 4、富函数类(Rich Function Classes)
- open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。
- close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
一个常见的应用场景就是,如果我们希望连接到一个外部数据库进行读写操作,那么将连接操作放在 map() 中显然不是个好选择——因为每来一条数据就会重新连接一次数据库;所以 我们可以在 open() 中建立连接,在 map()中读写数据,而在 close() 中关闭连接。
public class MyFlatMap extends RichFlatMapFunction> {
@Override
public void open(Configuration configuration) {
// 做一些初始化工作
// 例如建立一个和 MySQL 的连接
}
@Override
public void flatMap(IN in, Collector 5、物理分区

// 经洗牌后打印输出,并行度为 4
stream.shuffle().print("shuffle").setParallelism(4);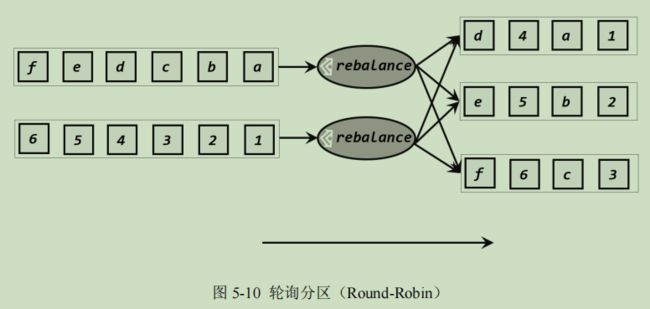
// 经轮询重分区后打印输出,并行度为 4
stream.rebalance().print("rebalance").setParallelism(4);
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new Partitioner() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
}, new KeySelector() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
})
.print().setParallelism(2); 四、输出算子(Sink)
stream.addSink(new SinkFunction(…));1、连接到外部系统

2、输出到文件

3、输出到 Kafka
Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。具体步骤如下:
(1)添加 Kafka 连接器依赖
(2)启动 Kafka 集群
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092");
DataStreamSource stream = env.readTextFile("input/clicks.csv");
stream
.addSink(new FlinkKafkaProducer(
"clicks",
new SimpleStringSchema(),
properties
));
env.execute();
} 4、输出到 Redis
5、输出到 Elasticsearch
ElasticSearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据。ElasticSearch 有着简洁的 REST 风格的 API,以良好的分布式特性、速度和可扩展性而闻名,在大数据领域 应用非常广泛。
6、输出到 MySQL(JDBC)
org.apache.flink flink-connector-jdbc_${scala.binary.version} ${flink.version} mysql mysql-connector-java 5.1.47
mysql> create table clicks(-> user varchar(20) not null,-> url varchar(100) not null);
stream.addSink(JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
// MySQL5.7的写法
.withUrl("jdbc:mysql://localhost:3306/ct_2022")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("root")
.build()
)
);7、自定义 Sink 输出
org.apache.hbase hbase-client ${hbase.version}