APM-Skywalking调研及实施报告
第一部分:APM介绍
第二部分:SkyWalking介绍
第三部分:使用jar包、容器、K8S三种不同方式部署SkyWalking
第四、五、六部分:结合实际,介绍将后端java服务(容器化和非容器化)、前端js服务端和前端js浏览器端接入SkyWalking的方法
第七部分:UI界面介绍
第八部分:实例分析,结合具体服务,使用UI排查问题,包括拓扑图和调用链分析
文章目录
- 一、 APM介绍
-
- 1、 背景
- 2、 应用APM的效果
- 3、 调用链的基本概念
- 4、 开源APM选型
- 二、 SkyWalking介绍
-
- 1、 探针协议
- 2、 JaveAgent(Java探针)
- 3、 skywalking-client-js(JS浏览器端探针)
- 4、 高性能+高可拓展的流计算框架
- 三、 skywalking部署
-
- 1、 以jar包形式部署
- 2、 以docker形式部署
- 3、 在K8s中部署
- 四、 java服务接入skywalking
-
- 1、 非容器化服务接入
- 2、 容器化服务接入
-
- 2.1、未部署在K8s上
- 2.2、 部署在K8s上
- 五、 javascript服务接入skywalking(内网)
- 六、 浏览器端js接入skywalking
- 七、 UI介绍
-
- 1、仪表盘
- 2、拓扑图
- 3、 追踪
- 八、 UI基础使用方法示例(实例分析)
-
- 1、 使用性能剖析,分析线程堆栈,排查某个端点慢的具体原因
- 2、 使用拓扑图和追踪链进行排查(浏览器端可在WebBrowser直接查看dom加载时间)
-
- (1) 通过拓扑图排查A调用链慢的原因
- (2) 通过追踪链路图排查A调用链慢的原因。
- 3、 使用追踪连查看调用失败的服务
- 附录:Zipkin介绍及接入方法
-
- 1、 Java的brave库
- 2、 js服务端的zipkin-js库
一、 APM介绍
APM全称是Application Performance Monitor,即应用性能监控。
1、 背景
微服务的普及,使得一次请求会涉及多个服务,而这些服务由不同语言和团队分别进行开发,并且部署在n个服务器上,涉及n个数据库。此时,如果使用传统的监控系统,一旦机器或者服务出现问题时,研发或者运维人员无法及时知道具体错误的发生环节,需要到日志中一一排查,耗费大量时间和精力。
在这种背景下,应用基于分布式追踪的全链路监控系统就显得极为重要。
2、 应用APM的效果
节省研发人员排查问题的时间。
通过将业务系统接入分布式追踪系统中,可以实现:
(1)故障快速定位,能够看到整个跨语言和团队业务请求的链路,可以通过链路信息结合业务日志,快速定位错误。
(2)各个调用环节的性能分析,分析调用链的各个环节耗时,找到薄弱环节进行优化。
效果图:由于信息敏感,已去除效果图。
3、 调用链的基本概念
上图效果图中服务A到服务B就是一个调用链Trace。一个 trace 对应一个唯一的 traceId,而一个 trace 内部包含多个 span,即服务A中的所有子节点就是一个span。
Span 是Trace 中的一个基本单元。一个 span 同样对应一个唯一的 spanId。例如一个 HTTP 请求到响应过程中,内部可能会访问型数据库执行一条 SQL,这是一个新的 span,或者内部调用另外一个服务的 HTTP API 也是一个新的 span。一个 trace 中的所有 span 是一个树形结构,树的根节点叫做 root span。除 root span 外,其他 span 都会包含一个 parentId,表示父级 span 的 spanId。
每个 span 中又包含多个 annotation,用来记录关键事件的时间点。例如一个对外的 HTTP 请求从开始到结束,依次有以下几个annotation:
cs Client Send,客户端发起请求的,这是一个 span 的开始
sr Server Receive,服务端收到请求开始处理
ss Server Send,服务端处理请求完成并响应
cr Client Receive,客户端收到响应,这个 span 到此结束
记录了以上的时间点,就可以很容易分析出一个 span 每个阶段的耗时:
cr - cs 是整个流程的耗时
sr - cs 以及 cr - ss 是网络耗时
ss - sr 是被调用服务处理业务逻辑的耗时
然而,sr 和 ss 两个 annotation 依赖被调用方,如果被调用方没有相应的记录,例如下游服务没有对接 instrumentation 库,或者像执行一条 SQL 这样的场景,被调用方是一个数据库服务,不会记录 sr 和 ss,那么这个 span 就只有 cs 和 cr。
4、 开源APM选型
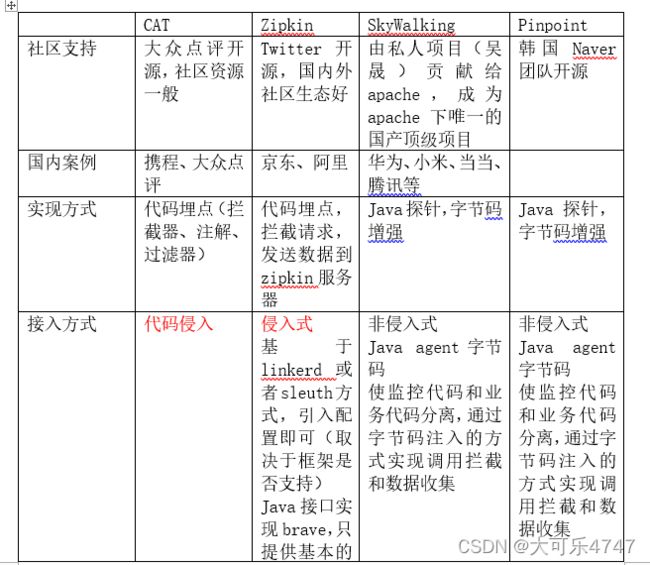

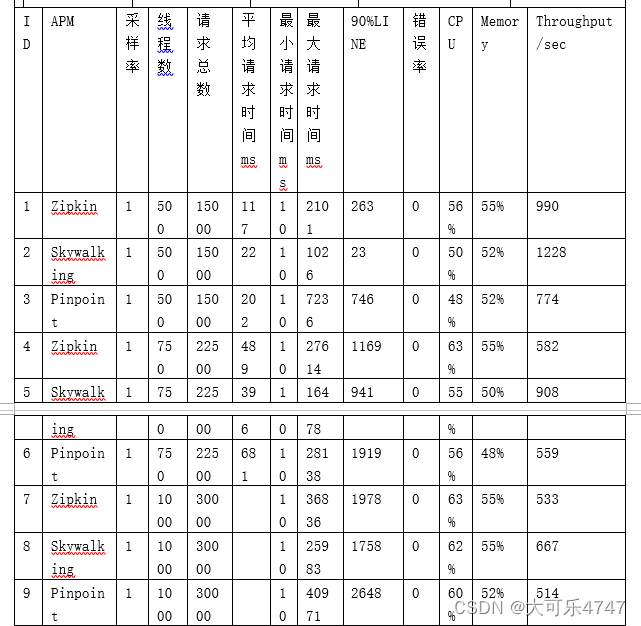
由上表可见,在分布式链路追踪中有两个流派:代码埋点和字节码增加。
结合目前生产实际需求,监控工具需要满足以下几个条件:
(1) 低侵入性
(2) 低性能影响
(3) 丰富的数据报表分析
(4) 高时效性
(5) 易部署,易运维
根据表1和表2中调研结果,初步筛选了Zipkin和Skywalking进行下一步调研,主要为代码侵入性对比和服务响应延时对比,发现Zipkin接入方法的侵入性远强于Skywalking。
对于应用服务接入Skywalking的方法可见第四五六节,应用服务接入Zipkin的方法可见附录一。
而对于服务添加skywakling-agent前后的响应延时对比,则随机选取了服务A的接口a,使用了Jmeter进行并行调用,线程数量为n个,运行测试大于n次。通过结果发现Skywalking性能影响不大。
所以根据调研结果,最终选用Skywalking。
二、 SkyWalking介绍
SkyWalking是中国唯一一个发展成为Apache顶级项目的个人开源项目,作者为吴晟,是一个为微服务、容器化和分布式系统而生的高度组件化、可插拔的APM项目。
Skywalking与zipkin、jaeger的核心理念是有巨大差异的。skywallking是为应用性能监控服务的,提供了高性能、自动探针、轻量级分析拓扑图和应用性能指标等功能,而zipkin和jaeger专注于追踪本身,得到尽可能细致的调用链,系统之间提供的追踪结构有较大差别。
方法级别追踪是skywalking技术栈能够做到的技术,但是官方不推荐,特别是生产环境中,方法级别追踪是性能诊断工具的工作,而不是APM系统的工作。APM系统要求在有限性能消耗下,在生产环境长时间低消耗运行,而方法监控会消耗大量内存和性能,不适合大流量系统。
如果想进行方法级别追踪,可直接使用插件(目前社区插件仅支持Spirng托管的类),或者见第八节的使用方法。
1、 探针协议
SkyWalking包含四类探针协议
(1) 语言探针上报协议:包括语言探针的注册、Metrics数据上报、Tracing数据上报、命令下行,和Service Mesh中使用的Telemetry协议,此协议以gRPC服务方式对外提供。
(2) 语言探针交互协议:因为分布式追踪,探针间需要借助HTTP Header、MQHeader等应用间通信管道进行交互。此协议规定了交互格式。
(3) Service Mesh协议:针对Service Mesh的专有协议,任何Mesh类的服务都可以通过此协议直接上行Telemetry数据,用户计算Metrics和拓扑图。
(4) 第三方协议:针对大型的第三方开源项目提供,如istio和envoy,提供核心适配。
2、 JaveAgent(Java探针)
启动时加载的JavaAgent是JDK1.5之后引入的新特性,为用户提供了在JVM将字节码读入内存之后,使用对应的字节流在java堆中生成一个Class对象之前,对其字节码进行修改的能力,而JVM也会使用用户修改过的字节码进行Class对象的创建。
Skywalking探针依赖于JavaAgent在一些特殊点拦截对应的字节码数据并进行AOP修改,当某个调用链路运行至已经被Skywalking代理过的方法时,Skywalking会通过代理逻辑进行这些关键节信息的收集、传递和上报,从而还原出整个分布式链路。
3、 skywalking-client-js(JS浏览器端探针)
官方提供skywalking-client-js库,用于追踪JS异常和性能,并拓展至浏览器,让浏览器成为分布式追踪的起点。
主要功能有:获取浏览器性能数据,捕获前端错误,统计页面访问数量信息和追踪浏览器端请求,下面会详细介绍。
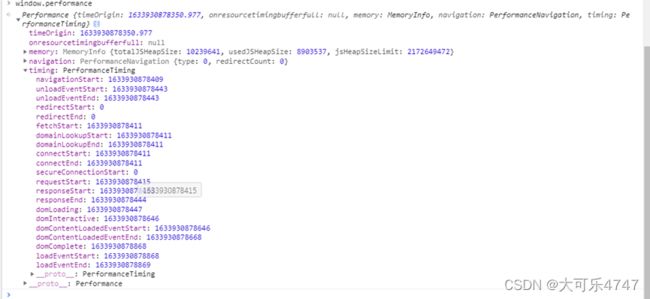
(1)skywalking-client-js获取的所有性能指标都是根据performanceAPI计算获取,其收集数据,发送给OAP服务器,服务器在后台汇总处理数据,然后再在UI展示。
performance是W3C性能小组引入的一个API,可以用于检测白屏时间、首屏时间、用户可操作时间、总下载时间等。
具体数值见下图:
(2)Skywalking-client-js可以捕捉到5种浏览器错误,如下:
1.window.addeventlistenr(‘error’,callback,true)捕捉资源加载错误
2.window.onerror 抓取JS执行错误
3.window.addEventListener(‘unhandledrejection’,callback)用来捕捉Promise错误
4.Vue错误
5.Ajax错误
同样skywalking-client-js将错误数据追踪到OAP服务器,最后在UI端将数据可视化呈现。
(3)获取浏览器页面PV、UV数。
在SPA(单页应用)中,页面只会被刷新一次。传统方法只在页面加载后报告一次PV,但无法统计每个子页面的PV,无法使其他类型的日志按子页面进行汇总。
Skywalking浏览器监控侦控SPA提供了两种处理方式。
1.启用SPA自动解析。该方法适用于大多数以URL哈希为路由的单页应用场景。在初始化配置项中,将enableSPA设置为true,将开启页面的哈希变化事件监听器,在其他数据报送中使用URL哈希作为页面字段。
2.手动上报。
4、 高性能+高可拓展的流计算框架
Skywalking并没有因为追求简单,可插拔而降低对性能要求,其内置了一套针对分布式监控专门设计的可扩展流计算框架,针对监控数据设计了特定的流程,并利用字节码技术来兼顾扩展性和系统性能。
典型案例:永辉超市,使用15台OAP节点和20台ES节点,支撑了250多个服务,每天高达3TB监控数据,数据流量超过百亿。
三、 skywalking部署
调研过程中,使用功能了3种方式在开发环境进行部署试验,分别为jar包部署,dokcer环境容器部署和在K8s环境中部署
1、 以jar包形式部署
使用安装包:apache-skywalking-apm-8.7.0.tar.gz、elasticsearch-6.6.1.tar.gz、kibana-6.6.1-linux-x86_64.tar.gz
安装方法:
确保使用的端口没有被占用
查询方法:lsof –i:9200
必须先启动ES,然后再启动Skywalking
(1)安装ES
1、解压
tar –zxvf elasticsearch-6.6.1.tar.gz
2.修改/elasticsearch-6.6.1/config/elasticsearch.yml
3.修改network.host: 192.168.19.116(改成虚拟机IP)
4.修改http.port: 9200
5.修改配置,所有修改使用root登录
vim /etc/security/limits.conf
在末尾添加:
* soft nofile 1024000
* hard nofile 1024000
* soft memlock 24586731
* hard memlock 24586731
es - memlock unlimited
es - nofile 65536
然后再编辑,添加
vim /etc/sysctl.conf
vm.max_map_count = 262144
执行:
sysctl –p
然后所有用户重新登录
视情况决定是否修改vim /elasticsearch-6.6.1/config/jvm.options
vim /elasticsearch-6.6.1/config/jvm.options,末尾增加 –XX:-AssumeMP
6、启动es,需要新增用户启动
adduser zyxtest
password zyxtest
su zyxtest
su root,赋予权限 chown -R zyxtest /opt/elasticsearch-6.6.1
登录新用户执行./bin/elasticsearch –d
日志查看: logs/elasticsearch.log
验证是否启动成功:浏览器访问http:// 192.168.19.116:9200
(2) 安装kibana
1.解压tar包
2.修改config/kibana.yml,修改kibana的host和es库的host,完成后,启动kibana,在浏览器访问
(3)安装skywalking
tar –zxvf apache-skywalking-apm-8.7.0.tar.gz
修改配置文件,将存储库改为ES库
默认selector: ${SW_STORAGE:H2},改为selector: ${SW_STORAGE:elasticsearch},或者其他版本
修改12800和11800端口地址
修改webapp/config端口号和12800地址
修改agent/config的11800地址
执行./bin/startup.sh 启动OAP和UI界面,输出为success成功
访问8080可以看到UI页面
2、 以docker形式部署
使用镜像:busybox:1.34.1、elasticsearch: 7.14.2、skywalking-ui: 8.7.0、skywalking-oap-server: 8.7.0-es7、kibana: 7.14.2
执行命令前,修改host.port,ip等参数,安装之后都需要检查是否安装、配置成功
(1) 安装ES:
docker run --name es7 -d --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -v /data/elasticsearch/data:/usr/share/elasticsearch/data -v /data/elasticsearch/logs:/usr/share/elasticsearch/logs caas-harbor:5001/public/elasticsearch:7.14.2
(2) 安装kibana
docker run -it -d --name kb -e elasticsearch.host=http://95.100.23.135:9200 --restart=always -p 5601:5601 caas-harbor:5001/public/kibana:7.14.2
(3) 安装oap
docker run --name oap -d --restart always -p 11800:11800 -p 12800:12800 -e SW_STORAGE=elasticsearch7 -e SW_STORAGE_ES_CLUSTER_NODES=95.100.23.135:9200 caas-harbor:5001/public/skywalking-oap-server:8.7.0-es7
(4) 安装UI
docker run --name ui -d --restart always -p 9210:8080 -e SW_OAP_ADDRESS=http://95.100.23.135:12800 caas-harbor:5001/public/skywalking-ui:8.7.0
3、 在K8s中部署
使用工具:helm-v3.7.1-linux-amd64.tar.gz.tar、elasticsearch:7.14.2、skywalking-ui: 8.7.0、skywalking-oap-server: 8.7.0-es7、kibana: 7.14.2、skywalking-kubernetes-4.1.0
(1)下载helm3.7.1安装包
tar -zxvf helm-v3.7.1-linux-amd64.tar.gz.tar
mv helm /usr/local/bin
查看是否安装成功
helm version
(2)启动es容器(此处单独使用docker部署,也可以选择集群部署)
docker run --name es7 -d --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -v /data/elasticsearch/data:/usr/share/elasticsearch/data -v /data/elasticsearch/logs:/usr/share/elasticsearch/logs -v /etc/localtime:/etc/localtime caas-harbor:5001/public/elasticsearch:7.14.2
(3)修改skywalking-kubernetes-4.1.0
cd /opt/skywalking-kubernetes-4.1.0/chart/skywalking
value.yaml具体修改字段如下:
Oap信息:
Oap.service.type改为NodePort
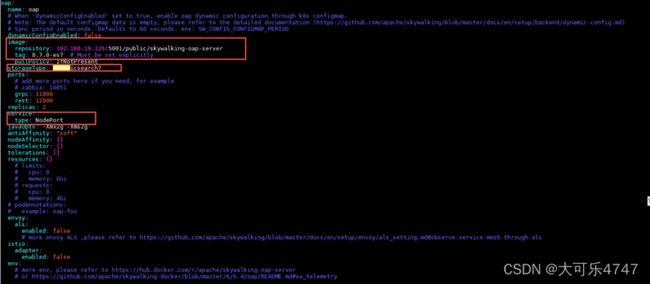
UI信息:

Es信息不修改,单独部署docker
(4)修改Chart.yaml
/opt/skywalking-kubernetes-4.1.0/chart/skywalking
注释掉ES的依赖
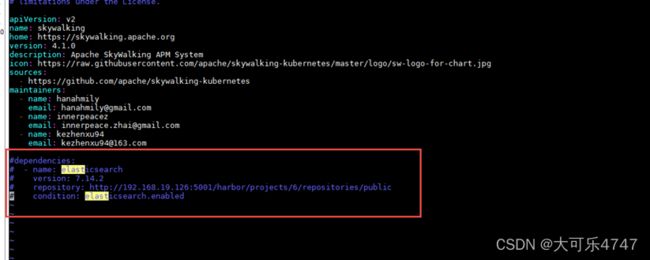
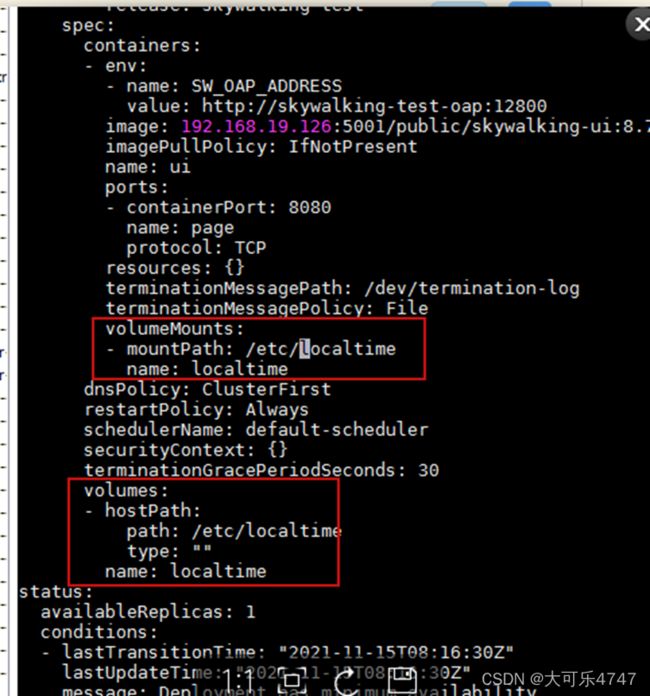
(5)修改oap-svc.yaml
位置:
/opt/skywalking-kubernetes-4.1.0/chart/skywalking/templates

设置容器内时间与容器外时间一致
或者启动pod后直接edit deployment
(6)安装skywalking (修改releasename和namespace)
kubectl create ns sw
/opt/skywalking-kubernetes-4.1.0/chart/skywalking
helm install sw-v4 ./ -n sw --set elasticsearch.enabled=false --set elasticsearch.config.host=95.100.23.135 --set elasticsearch.config.port.http=9200 --set elasticsearch.config.user="" --set elasticsearch.config.password=""
查看日志,是否成功启动(ES是关键)
四、 java服务接入skywalking
服务接入所需要的agent包和镜像等资源由测试人员提供。
1、 非容器化服务接入
将整个/agent目录拷贝到需要监控的服务器上如/usr/local,根据需要修改/agent/config配置
启动java进程增加参数 需要放置在-jar前面,修改agent_name,oap的地址等。
java -javaagent:/opt/apache-skywalking-apm-bin/agent/skywalking-agent.jar=agent.service_name=zyxtest_demo4 -jar demo-1.0.0.jar &
如果参数里有-Djava.ext.dir,需要指明agent位置
2、 容器化服务接入
2.1、未部署在K8s上
(1)将skywalking agent 的整个agent文件夹都复制到要进行埋点的项目中
(2)修改项目的dockerfile,,主要修改两句代码
# 将项目中的agent文件拷贝到容器中的/usr/local/agent文件夹中
COPY agent /usr/local/agent
# -jar前面添加javaagent参数
ENTRYPOINT [“sh”,”-c”,”java –javaagent:/usr/local/agent/skywalking-agent.jar=agent.service_name=zyxtest_demo4 –Djava.security.egd=file:/dev/./urandom –jar /app.jar”]
2.2、 部署在K8s上
修改deployment,添加sidecar,注意参数内容和yaml格式。
initContainers:
- name: sw-es7-agent-sidecar
image: caas-harbor:5001/public/sw-es7-agent-sidecar:8.7.0
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c", "mkdir -p /skywalking/agent && cp -r /usr/skywalking/agent/* /skywalking/agent"]
volumeMounts:
- mountPath: /skywalking/agent
name: sw-agent
# 容器变量
env:
- name: JAVA_TOOL_OPTIONS
value: -javaagent:/usr/skywalking/agent/skywalking-agent.jar
- name: SW_AGENT_NAME
value: case-manage-service
- name: SW_AGENT_COLLECTOR_BACKEND_SERVICES
value: 95.100.23.135:11800
# 容器挂载目录,共享intialContainer挂载的agent
volumeMounts:
- mountPath: /usr/skywalking/agent
name: sw-agent
# 服务器挂载目录
volumes:
- name: sw-agent
emptyDir: {}
五、 javascript服务接入skywalking(内网)
1、 区分webpack版本5-和5(5以后不会在自动引入nodejs的核心库)+,nodejs>10官方下载skywalking-nodejs的npm包
2、 区分内网和外网,安装grpc如果是内网的话需要参数指定使用的mirror地址
3、 前端研发将提供的node-v72-linux-x64-glibc.tar.gz包放在可访问路径下(如tomcat),路径格式必须是:http://${ip:port}/grpc/v1.24.11/node-v72-linux-x64-glibc.tar.gz
4、 将npm包上传到私有npm库
5、 研发安装npm包(如在jenkins流水线上统一安装)
npm install - -save skywalking-backend-js - -unsafe-perm --grpc_node_binary_host_mirror=http://${ip:port}/
6、 在应用入口第一行,引入其他模块之前启动agent
import agent from 'skywalking-backend-js’
agent.start({
serviceName: 'your-service-name',
collectorAddress: '95.100.23.135:11800'
})
如果使用的是require,则为:
Const skywalking = require(‘skywalking-backend-js’);
Skywalking.default.start({
serviceName: 'your-service-name',
collectorAddress: '95.100.23.135:11800'
})
六、 浏览器端js接入skywalking
服务接入使用的npm包由测试人员提供。
1、 安装依赖
npm install skywalking-client-js --save
2、 引入依赖
import ClientMonitor from ‘skywalking-client-js’
3、 注册(自动上报方式)
# 在页面首个调用的js前加入即可
ClientMonitor.register({
service:’服务标识’,
serviceVersion:’服务版本号’,
pagePath:”/current/page/home”, //服务路径
collector:’http://95.100.23.201:12800’ ,//信息采集器
detailMode:false //关闭http请求追踪
});
另外:
1、研发需解决JS跨域问题
2、ES库需要配置跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
七、 UI介绍
(由于数据私密,所有图片已删除)
1、仪表盘
service:一组工作负载
endpoint:url或者接口名称
instance:具体的一个工作负载,主要格式为“进程号:主机IP”或者K8s中的podIP
endpoint和instance无任何关系。
见下图:
APM模块
Global
主要数据板块为:服务调用次数、慢服务排行、Apdex指数排行(用户满意程度)、慢端点排行、响应时间百分比图、响应时间热力图
如下图:
Service
主要数据板块为:服务的Apdex平均数值(用户满意程度)、响应时间、响应成功率、调用次数,实例调用次数,慢实例排行和实例响应成功率
如下图:
Instance
主要数据板块为:实例调用次数、实例响应成功率、实例响应延时、实例JVM CPU占比,实例JVM 内存占比、实例JVM GC时间和次数、实例中的线程、类的数量状态等
如下图:
Endpoint
主要数据板块为:端点调用次数、慢端点排行、成功率、响应时间等
如下图:
Database模块
主要数据板块为:数据库响应时间、响应成功率、调用次数、响应延时,慢查询列表
慢查询列表可查看具体sql语句。
见下图:
Web Browser模块
Web App
主要数据模块为:所有页面调用次数排行、页面错误率排行、页面错误数量排行、APP打开次数排行、APP错误率排行、APP错误数量排行等。
Pages
页面调用次数排行、页面稳定性排行、页面加载性能(dom加载)、DOMReady延时等。
2、拓扑图
以接入三个服务为例,如下图,当某个服务响应成功率低于95%时,该端点会变为红色警示。
具体使用方法,将在第八节进行说明。
3、 追踪
具体使用方法将在第八节进行说明。
八、 UI基础使用方法示例(实例分析)
由于数据私密,所有图片已删除。
测试使用服务为ABC,举例几种使用方法。
1、 使用性能剖析,分析线程堆栈,排查某个端点慢的具体原因
1.登录skywalking,查看APM-Global
发现A的用户满意度为0.86,A - SpringScheduled/org…*.Utils.ServiceCall…vProxy…端点排列在慢端点排行第一位。
2.进入APM-Service查看A服务的具体信息
A服务的P99值在1秒上下。
3.查看APM-Endpoint,选择端点A - SpringScheduled/org…*.Utils.ServiceCall…vProxy…进行查看

显示该端点平均响应时间较高。
4.查看该服务响应慢的原因。
进入性能剖析,查看该端点的线程堆栈
发现该端点大量调用端点/…rManagement/rest/…tService/qu…fo
分析其堆栈
发现SpringScheduled/org…*.Utils.ServiceCall…vProxy…111耗时7.7秒,再继续展开查看
发现java.net.SocketInputStream.socketRead:116耗时6秒多
至此问题定位结束。
2、 使用拓扑图和追踪链进行排查(浏览器端可在WebBrowser直接查看dom加载时间)
(1) 通过拓扑图排查A调用链慢的原因
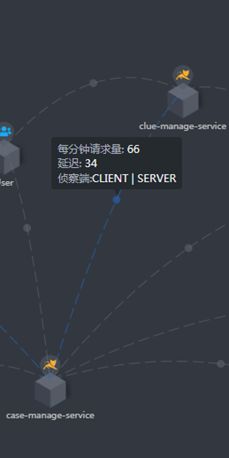
能够在图中可以看到调用链:user到A,A又调用了6个外部服务,分别为B、C、D、E、F和G。其中B和C已经接入skywalking,且正在发生调用。
User节点为OAP服务自动增加,代表某个操作产生了调用A的行为,且 user到B的监控数据全部来自于server端,见下图:

首先查看A的百分比响应时间:
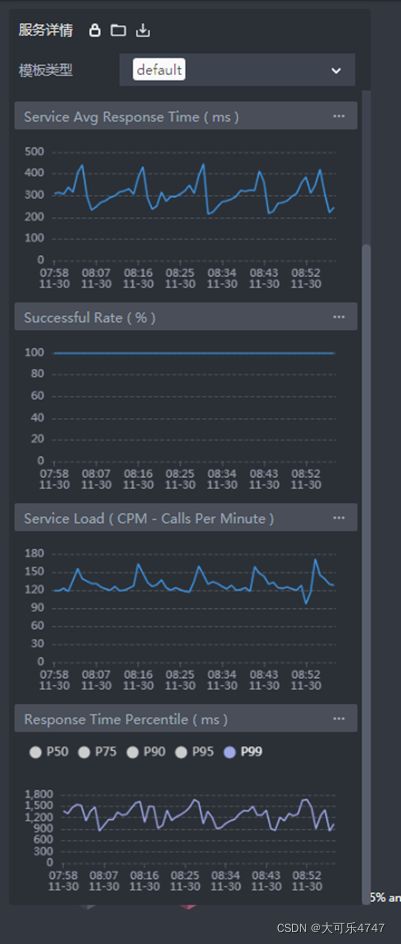
可以看到A的p99数字在1秒上下,平均响应时间在300毫秒上下。
查看A到B的链路,此段监控信息是由A和B共同上报,如下图:
查看此条调用链具体的监控数据如下,分别为server端和client端:
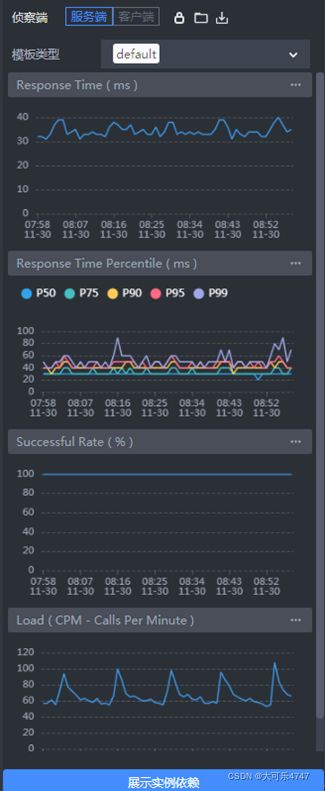
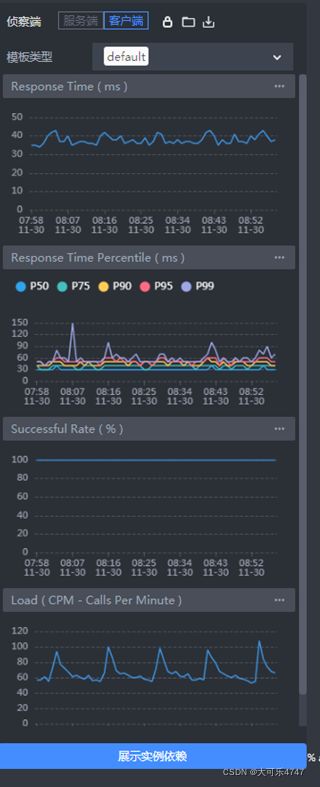
可以明显看出两者的数据相差不大,client端响应时间会比server更大一些。
如果A和B之间存在proxy,如istio-sidecar,发生丢包时,会明显看到client端的平均响应时间小于server端,此时通过对比server和client监控数据可以发现异常。
在上图中查看client端的响应时间P99数值在60毫秒上下,而A的P99数值为1秒上下,所以基本可以排除是B的问题。
再看A到C的链路信息,与B相同,此段链路的监控信息是由A和C共同上报,如下图,分别为server端和client端。


可以发现server端和client端响应时间基本相同,且A调用C次数较少,所以可以基本排除是C的问题。
所以可以把问题定位到A本身,再结合endpoint的相关监控数据,进一步缩小范围。
(2) 通过追踪链路图排查A调用链慢的原因。
进入追踪模块后,筛选服务A,并按照持续时间进行排序,如图:
可以看到调用时间最长的端点,持续时间为8.5秒,span数量达到278个。切换统计形式,如图:
可以看到在一条调用链内,调用了…eInfo次数达到274次,平均返回时间30毫秒,总耗时8.3秒。
3、 使用追踪连查看调用失败的服务
进入追踪模块,筛选状态为error的端点,如图:
如A调用链,在调用**时发生错误,点击查看原因,如图:
可以看到错误信息为:503 Service Unavailable,以及详细的堆栈信息。
附录:Zipkin介绍及接入方法
Zipkin 是一个分布式链路追踪系统。它可以收集并展示一个 HTTP 请求从开始到最终返回结果之间完整的调用链.
1、 Java的brave库
brave库是分布式追踪的埋点库。大致接入方法如下:
(1) Maven依赖管理
首先加入一个 dependencyManagement,这样就不需要在各个依赖包中添加版本号了:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-bom</artifactId>
<version>5.11.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
(2) 创建Tracing对象,首先需要添加依赖:
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-context-slf4j</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-sender-okhttp3</artifactId>
</dependency>
然后创建对象(JAVA配置方式,springboot或者spring项目):
@Configuration
public class TracingConfiguration {
@Bean
public Tracing tracing() {
Sender sender = OkHttpSender.create("http://127.0.0.1:9411/api/v2/spans");
Reporter<Span> spanReporter = AsyncReporter.create(sender);
Tracing tracing = Tracing.newBuilder()
.localServiceName("my-service")
.spanReporter(spanReporter)
.currentTraceContext(ThreadLocalCurrentTraceContext.newBuilder() .addScopeDecorator(MDCScopeDecorator.get()).build())
.build();
return tracing;
}
}
该对象是单实例的,如果想要在其他地方获取到这个对象,可以通过静态方法 Tracing tracing = Tracing.current() 来获取。
Tracing 对象提供了一系列 instrumentation 所需要的工具,例如 tracing.tracer() 可以获取到 Tracer 对象。
currentTraceContext 指定一个 CurrentTraceContext 对象来设置 TraceContext 对象的作用范围,通常会使用 ThreadLocalCurrentTraceContext,也就是用 ThreadLocal 来存放 TraceContext。TraceContext 包含了一个 trace 的相关信息,例如 traceId。
由于在 Spring MVC 应用中,一个请求的业务逻辑通常在同一个线程中(暂不考虑异步 Servlet)。一个请求内部的所有业务逻辑应该共用一个 traceId,自然是把 TraceContext 放在 ThreadLocal 中比较合理。这也意味着,默认情况下 traceId 只在当前线程有效,跨线程会失效。当然,跨线程也有对应的方案。
在 CurrentTraceContext 中可以添加 ScopeDecorator ,通过 MDC (Mapped Diagnostic Contexts) 机制关联一些日志框架:
brave-context-slf4j SLF4J
brave-context-log4j2 Log4J 2
brave-context-log4j12 Log4J v1.2
以 Logback 为例(本文中案例使用的方式),可以配置下面的 pattern 在日志中输出 traceId 和 spanId:
<pattern>%d [%X{traceId}/%X{spanId}] [%thread] %-5level %logger{36} - %msg%n</pattern>
(3) Spring MVC 埋点,需要添加依赖:
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-spring-webmvc</artifactId>
</dependency>
(4) 创建 HttpTracing对象,用于链路跟踪:
@Bean
public HttpTracing httpTracing(Tracing tracing){
return HttpTracing.create(tracing);
}
(5) 添加 DelegatingTracingFilter(SpringBoot项目)
用于处理外部调用的 HTTP 请求,记录 sr(Server Receive) 和 ss(Server Send) 两个 annotation。
@Bean
public FilterRegistrationBean delegatingTracingFilterRegistrationBean() {
FilterRegistrationBean registration = new FilterRegistrationBean();
registration.setFilter(new DelegatingTracingFilter());
registration.setName("tracingFilter");
return registration;
}
到此,Spring MVC 项目已经完成了最基本的 Brave 埋点和提交 Zipkin 的配置。如果有现有的 Zipkin 服务,将创建 OkHttpSender 提供的接口地址换成实际地址,启动服务后通过 HTTP 请求一下服务,就会在 Zipkin 上找到一个对应的 trace。
(6) brave-instrumentation-mysql的使用
由于每个服务内部还会调用其他服务,例如通过 HTTP 调用外部服务的 Api、连接远程数据库执行 SQL,此时还需要用到其他 instrumentation。
brave-instrumentation-mysql 可以为 MySQL 上执行的每条 SQL 语句生成一个 span,用于分析 SQL 的执行时间。
首先添加依赖:
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-mysql</artifactId>
</dependency>
然后在JDBC连接地址末尾加上参数:
statementInterceptors=brave.mysql.TracingStatementInterceptor
2、 js服务端的zipkin-js库
这是一组用于检测 Node.js 和浏览器应用程序的库。该zipkin库可以在 Node.js 和浏览器中运行。
(1) 安装zipkin
npm install zipkin --save
(2) 安装zipkin-instrumentation-express
npm install zipkin-instrumentation-express
(3) 完成基本设置
var express = require('express');
var path = require('path');
var favicon = require('serve-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var index = require('./routes/index');
var users = require('./routes/users');
var app = express();
const {Tracer, ExplicitContext, BatchRecorder} = require('zipkin');
const {HttpLogger} = require('zipkin-transport-http');
const zipkinMiddleware = require('zipkin-instrumentation-express').expressMiddleware;
const ctxImpl = new ExplicitContext();
const recorder = new BatchRecorder({
logger: new HttpLogger({
endpoint: 'http://106.28.56.127:9411//api/v1/spans'
})
});
const tracer = new Tracer({ctxImpl, recorder}); // configure your tracer properly here
// Add the Zipkin middleware
app.use(zipkinMiddleware({
tracer,
serviceName: 'service-li' // name of this application
}));
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'jade');
// uncomment after placing your favicon in /public
//app.use(favicon(path.join(__dirname, 'public', 'favicon.ico')));
app.use(logger('dev'));
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
app.use(cookieParser());
app.use(express.static(path.join(__dirname, 'public')));
app.use('/', index);
app.use('/users', users);
// catch 404 and forward to error handler
app.use(function(req, res, next) {
var err = new Error('Not Found');
err.status = 404;
next(err);
});
// error handler
app.use(function(err, req, res, next) {
// set locals, only providing error in development
res.locals.message = err.message;
res.locals.error = req.app.get('env') === 'development' ? err : {};
// render the error page
res.status(err.status || 500);
res.render('error');
});
module.exports = app;