HBase的compaction和split流程总结
目录
HBase的compaction和split总结
1、compaction介绍
2、compaction方式
Minor compaction
Major compaction
3、split介绍
参考
HBase的compaction和split总结
1、compaction介绍
在HBase中,每当memstore的数据flush到磁盘后,就形成一个storefile,当storefile的数量越来越大时,会严重影响HBase的读性能 ,所以必须将过多的storefile文件进行合并操作。Compaction是Buffer-flush-merge的LSM-Tree模型的关键操作,主要起到如下几个作用:
(1)合并文件
(2)清除删除、过期、多余版本的数据
(3)提高读写数据的效率
2、compaction方式
Minor compaction
Minor操作只用来做部分文件的合并操作以及包括minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作。主要是将选择少量相邻的小文件,读取出来重新写回去,进行一个小的合并。

Major compaction
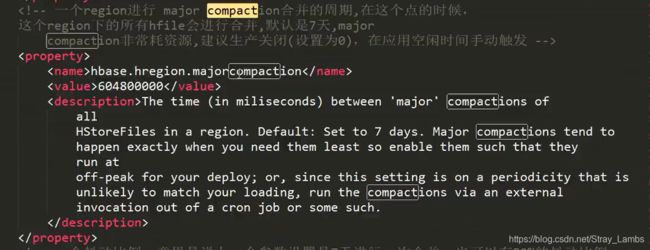
这是一个大合并,默认值是7天,这个合并是非常消耗资源的,因为会将所有的文件读取出来,建立一个临时的文件,然后过一定的时间,删除其他文件,只保留新的这个文件。相当于就是所有的HStoreFile合并成了一个。所以,生产环境中一般设置为0,即应该在空闲时间手动触发。
顺便提一下,在数据被真正删除的时候:1、flush操作的时候会将内存的时间戳小的数据进行删除,不会flush进磁盘当中;2、在major compaction的时候,会将标记为delete的数据进行删除。

3、split介绍
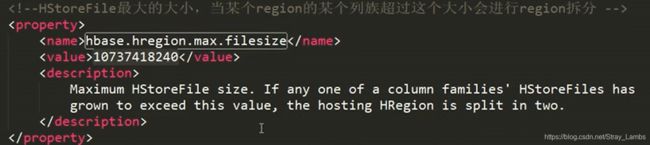
Hbase版本是0.94之后,那么默认的有三种自动split的策略,ConstantSizeRegionSplitPolicy,IncreasingToUpperBoundRegionSplitPolicy还有 KeyPrefixRegionSplitPolicy.。IncreasingToUpperBoundRegionSplitPolicy 是默认的split策略。公式是:
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”) R为同一个table中在同一个region server中region的个数。hbase.hregion.memstore.flush.size 默认值 128MB。hbase.hregion.max.filesize默认值为10GB 。并且,分割的点都是从rowkey的中间点进行切分。
split的时机:
每当执行完flush或者是compaction操作之后,都会判断是否需要进行split。

这里放个大神记录的split流程的源码, 有兴趣的可以去看看。
https://www.iteye.com/blog/blackproof-2037159
split流程(搬运大佬的博客):
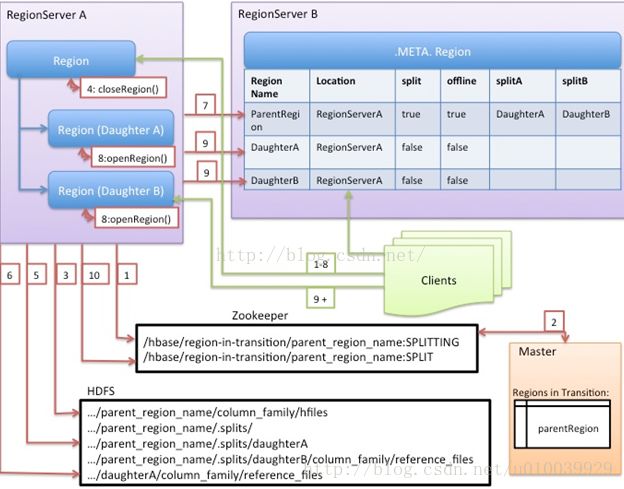
1.RegionServer触发在本地进行split,并准备split。第一步就是在zk的/hbase/region-in-transition/region-name的节点下创建一个znode节点,并置为SPLITTING状态;
2.因为Master一直watch着zk的znode,发现parentregion需要split。
3.region server 在hdfs的parent region的目录下创建一个名为“.splits”的子目录。
4.region server关闭parent region。强制flush缓存,并且在本地数据结构中标记region为下线状态。如果这个时候客户端刚好请求到parent region,会抛出NotServingRegionException。这时客户端会进行重试。
5.region server在.split目录下分别为两个daughter region(A,B)创建目录和必要的数据结构。然后创建两个引用文件指向parent regions的文件。
6.region server在HDFS中,创建真正的region目录,并且把引用文件移到对应的目录下。
7.region server发送一个put的请求到.META.表中,并且在.META.表中设置parent region为下线状态,并添加关于daughter regions的信息。但是这个时候在.META.表中daughter region 还不是独立的row,客户端在此时scan .META.表时会发现parent region在split,但是还不能获得daughter region的信息,直到她们独立的出现.META.表中。如果此时这个往.META.表中的put操作成功,parent region会高效的split,如果此时rs在RPC请求成功前失败,Master和下一个regionserver会重新打开这个parent region并将之前产生的split的脏数据清掉,.META.表成功更新后,HBase继续进行下面split的流程。
8.region server并行打开两个daughter region接受写操作。
9.region server在.META.表中增加daughters A和 B region的相关信息,在这以后,client就能发现这两个新的regions并且能发送请求到这两个新的region了。client本地具体有.META.表的缓存,当他们访问到parent region的时候,发现parent region下线了,就会重新访问.META.表获取最新的信息,并且更新本地缓存。
10.region server 更新znode 的状态为SPLIT。master就能知道状态更新了,master的平衡机制会判断是否需要把daughter regions 分配到其他region server中。
11.在split之后,meta和HDFS依然会有引用指向parentregion.当compact操作发生在daughter regions中,会重写数据file,这个时候引用就会被逐渐的去掉。GC任务会定时检测daughter regions是否还有引用指向parent files,如果没有引用指向parent files的话,parent region 就会被删除。
参考
https://blog.csdn.net/u010039929/article/details/74295869 split流程详解
https://www.bilibili.com/video/BV1Y4411B7jy?p=23&spm_id_from=pageDriver
https://www.iteye.com/blog/blackproof-2037159 split源码