【文件包含、宏、条件编译】(学习笔记21--预处理命令)
目录
- 文件包含
-
- 头文件
- #include命令
- 多文件编译
- 宏
-
- 宏的定义
- 宏的取消定义
- 带参宏
-
- 将参数转换为字符串常量
- 参数结合
- 宏的嵌套使用
- 转换宏
- 条件编译
-
- #if命令
- #ifdef命令
- #ifndef命令
文件包含
由源代码得到可执行的程序,会经过预处理、编译、汇编、链接几个过程。预处理就是在编译之前,通过一些预处理命令对源代码进行管理和控制的过程。预处理命令本身并非C语言范畴,预处理命令也不会参与到编译过程中。预处理命令是由预处理器来执行和处理的指令,经过预处理之后,在进行编译之前,源代码中就已不再含有预处理命令了。预处理命令大致可以分为文件包含、宏和条件编译几个部分,所有的预处理命令都是以#开头的
头文件
头文件也是一个文本文件,它是和源文件相对应的,在C语言中,源文件通常都是以.c作为文件名的后缀,而头文件则是以.h作为文件名的后缀。在进行程序的编译时,需要对源文件进行编译,而头文件是不参与编译过程的
在之前的代码中,已经用到了许多标准库提供的头文件,例如stdio.h、stdlib.h、string.h、ctype.h等等。通常会将一些类型的定义和函数的声明放到头文件中,当程序需要使用这些类型或函数的时候,包含相应的头文件即可
除了使用标准库所提供的头文件外,也可以自己创建头文件
在E盘下GCC下tenth下创建文件夹Demo,然后在该文件夹下新建文本文档,并将该文件命名为sample.h。在sample.h文件中输入并保存如下内容
//add函数的声明,函数功能为返回参数a与参数b的和
int add(int a,int b);
//subtract函数的声明,函数功能为返回参数a与参数b的差
int subtract(int a,int b);
头文件sample.h中就有了add、subtract两个函数的声明

#include命令
#include命令用于包含头文件,即将一个指定的头文件的内容包含至当前文件中
在Demo文件夹中新建一个文本文档,将文件命名为test.c
#include "sample.h"
int main()
{
return 0;
}
在源文件test.c中,使用了#include命令来包含之前所编写的头文件sample.h。由于头文件sample.h是自己编写的,并且在当前目录下,因此此处使用的是双引号,而不是尖括号
为了能看到预处理器对源代码的处理结果,在使用gcc编译命令的时候,加上一个-E选项,表示只对源文件进行预处理,不进行编译
gcc -E test.c
按下回车键后,预处理器会对源文件test.c进行预处理
由结果可见,预处理器会用头文件sample.h中的内容,替换到源文件test.c中原#include命令的位置。同时,经过预处理后,代码中的注释部分已被忽略掉,不会出现在结果内容部分

也可以将编译命令修改为gcc -E test.c -o test.i,即载加上一个-o选项,用来将预处理后的结果输出到指定的文件test.i中。这样预处理结果就不会打印在控制台窗口,而是保存到文件test.i中


多文件编译
在上面的例子中,只是简单地使用#include命令包含头文件sample.h,并没有使用add函数或subtract函数。接下来就在主函数中调用这两个函数,并打印输出结果。将源文件test.c的内容修改如下

对test.c进行编译时,就会出现编译错误
原因是在头文件中只有add函数和subtract函数的声明,并没有这两个函数的实现

在Demo文件夹下再创建一个文本文档,命名为sample.c
int add(int a,int b)
{
return a + b;
}
int subtract(int a,int b)
{
return a - b;
}
现在程序拥有了3个文件,一个头文件sample.h,和两个源文件sample.c、test.c。头文件中包含了add函数和sample函数的声明,源文件sample.c中是对两个函数的实现,源文件test.c是主程序文件,即文件中拥有主函数。
下面,就来对这个程序进行编译,虽然头文件是不需要参与编译的,但源文件必须参与编译。由于这里的源文件不止一个,因此,需要使用多文件编译的方式。可以在编译命令中,把两个源文件都列在gcc之后
gcc test.c sample.c -o test.exe

宏
最初设计宏的目的就是为了便于代码的维护,而随着技术的不断发展,目前可以通过宏实现代码管理、流程控制、错误和异常检测等功能
宏根据有无参数可以分为无参宏和有参宏,而每个宏又可以分为宏名和宏值部分,在对源文件进行编译前,预处理器会对源代码中的宏进行文本替换处理,即将宏名部分替换为所对应的宏值部分。因此,也常将这种宏处理的行为称为宏替换或宏展开
宏的定义
可以通过#define命令来定义一个宏
#define 宏名 宏值
宏名是一个标识符,为所定义宏的名字,可使用在源代码中。宏值为宏名所对应的值,它可以是一个常数、表达式、字符、字符串等。需要注意的是,宏定义并非C语言的语句,因此最后不需要加上分号
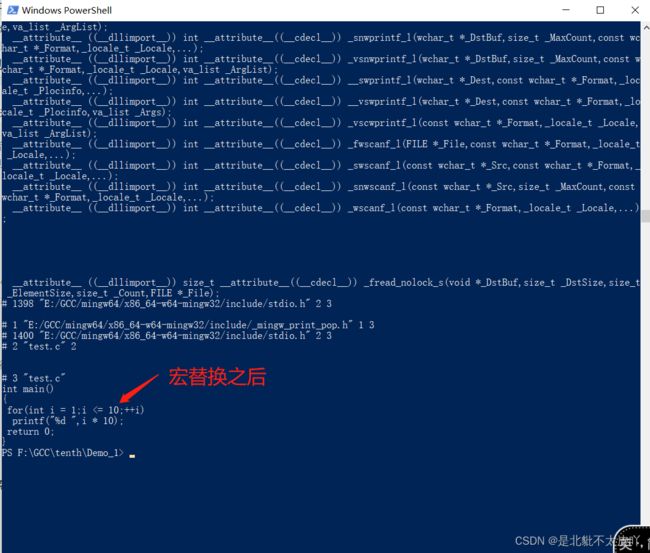
在这段代码中,通过#define命令进行宏定义,宏名为LEN,宏值为常数10.在for循环中用到了这个宏
#include 在gcc加上-E选项对源文件进行预处理,便可以得到宏替换之后的内容
由于程序包含了头文件stdio.h,因此,在对源代码预处理后,前面的大部分内容都是头文件中的内容。从结果可见,原先宏定义的部分已经没有了,但在for循环中用到宏LEN的地方,已被替换为它所对应的宏值(10)
预处理器对宏的处理只是简单的替换行为,因此,稍不小心就可能会产生令人匪夷所思的结果
#define NUM 2 + 3
下面在主函数中使用这个宏
int main()
{
int n = NUM * NUM;
printf("n = %d\n",n);
return 0;
}
定义了int类型变量n,并将NUM*NUM作为其初始化的值。按照最初设想,宏NUM的值为2与3的和,即5,变量n的值应该为5与5的乘积,即25.但对该程序编译运行后,发现结果如下
n = 11
n的值为11,并非25,这是什么原因呢
下面来看一下对源代码预处理之后的内容
从预处理的结果可见,经过宏替换之后,源代码中的语句int n = NUM*NUM会被替换为int n = 2 + 3*2 + 3,由于乘法的优先级高于加法,因此,结果便为2 + 6 + 3的值,即11

解决这个问题,给宏值加上小括号就可以了
#define NUM (2 + 3)
经过宏替换之后,源代码中的语句int n = NUM*NUM会被替换为int n = (2 + 3)(2 + 3),结果便为55的值,即25
最后要注意的是,不要重复定义相同的宏,不然编译的时候会给出重复定义的警告信息。另外,宏的作用域是从宏定义处开始,直至文件末。因此不能在宏定义之前使用宏,不然编译时,就会给出undeclared的错误提示
宏的取消定义
可以通过#undef命令来取消一个宏的定义
#undef 宏名
只要在#undef命令之后,写上想要取消的宏的名字,那么这个宏就被取消了,不可再被使用了。如果继续使用,就会在编译时得到undeclared的错误提示
#include 由于在使用宏NUM之前,通过#undef对宏NUM进行了定义取消,因此,在编译时会得到错误信息

带参宏
还可以定义像函数的宏,即带参数的宏
#define MAX(a,b) ((a) > (b) ? (a) : (b))
它的作用是在两个参数中找到相对较大的那个。宏MAX带了两个参数a和b。宏值部分((a) > (b) ? (a) : (b))是一个表达式,通过三目运算符来获取并返回参数a和b中相对较大的那一个
下面在主函数中使用宏MAX
int main()
{
printf("MAX:%d\n",MAX(10,20));
return 0;
}
在对源码进行预处理后会发现,经宏替换之后,MAX(10,20)被替换成了
((a) > (b) ? (a) : (b))
即先将宏值部分的参数a替换成10,参数b替换成20,然后再将宏值部分替换至使用宏MAX的地方
编译运行,结果如下
MAX:20
虽然带参宏的定义和使用方式与函数非常相似,但带参宏和函数还是有很大区别的
1.函数需要进行编译,而宏是由预处理器来处理,在进行代码编译阶段,宏已经不存在了
2.函数有函数体和返回值类型,而带参宏只有对应的宏值
3.函数在调用时会对参数进行求值,而带参宏只是对参数的简单替换,不会对参数进行求值。
因此,在宏定义时,宏值部分的每个参数都加上了小括号,这是一个好习惯。
定义一个计算平方的宏SQUARE
#define SQUARE(n) (n * n)
在主函数中使用宏SQUARE
printf("Result:%d\n", SQUARE(1 + 2));
结果
Result:5
打印的结果不是9,而是5
对源代码进行预处理后,会发现宏SQUARE被替换为
(1 + 2 * 1 + 2)
将宏SQUARE的定义修改如下
#define SQUARE(n) ((n) * (n))
对源代码进行预处理后,会发现宏SQUARE被替换为
((1 + 2) * (1 + 2))
结果
Result:9
将参数转换为字符串常量
在带参宏的定义中,可以使用#来将参数转换为字符串常量
#define STR(s) #s
在宏STR的定义中,在参数s的前面加上#作为宏值部分,这样就可以达到将参数s转换为字符串常量的功能
#include 对源代码进行预处理,进行宏替换之后,printf语句已经变为
printf("Result:%s\n","1 + 2");
可见,原先的整型常量表达式1 + 2已经变成了字符串常量"1 + 2"
参数结合
使用##来对带参宏中的参数进行结合
#define COMB(a,b) a##b
定义了带参宏COMB,它有两个参数a和b。该宏的功能是通过##符号将两个参数结合在一起,组成一个新的字符序列(并非字符串)
下面来使用这个宏
printf("Result: %d\n",COMB(10,20));
对宏COMB预处理后的结果为
printf("Result: %d\n",1020);
宏COMB将参数10和20结合在一起,组成1020,printf函数会将其作为一个整型常量来进行打印输出
结果
Result: 1020
宏的嵌套使用
也可以将一个宏作为另一个宏的参数,进行宏的嵌套使用
#include 对程序代码进行预处理后的printf函数语句
printf("Result: %d\n",((10) + 5));
可见,宏ADD会被替换为((10) + 5),而宏NUM会被替换为10。即带参宏中的参数本身又是一个宏时,预处理器会对这个参数宏先进行替换处理。也就是宏在嵌套使用时,会从内到外依次替换作为参数的宏
但有一种特殊情况是例外,就是当带参宏值部分含有#或##符号时,则作为参数的宏是不会被展开的
#include 预处理之后的printf函数调用语句如下
printf("Result: %s\n", "NUM");
预处理之后的STR宏部分,并非是10,而被替换为NUM,也就是作为参数的宏NUM并未被替换。导致参数宏未被替换的原因,就是在宏STR的定义中使用了#符号
转换宏
为了解决上面遗留的问题
可以使用一个不包含#和##符号的转换宏
#include 现在来看一下预处理之后的printf函数调用语句
printf("Result: %s\n", "10");
从结果可见,作为参数的宏NUM被替换成10了,这是因为在宏TOSTR中并没有使用#或##符号,因此,作为参数的宏NUM会被进行替换处理,然后将替换处理后的结果作为参数再来使用宏STR,将其转换为对应的字符串常量
条件编译
#if命令
#if命令的使用格式
#if 表达式
语句块1
#else
语句块2
#endif
在#if命令之后是一个表达式,若表达式的值为真,则让语句块1参与编译;若表达式的值为假,则让语句2参与编译。#endif是条件编译结束的标记,所有的条件编译都必须以#endif来结束
接下来用一个小程序来演示
#include 对程序进行预处理后的最后一部分内容为
int main()
{
printf("AAA\n");
return 0;
}
可见,由于#if命令之后的表达式为1,这会让语句printf(“AAA\n”);参与编译,而语句printf(“BBB\n”);不会参与编译
若将源代码中#if命令之后表达式的值修改为0
#include 再对代码进行预处理,会发现结果为
int main()
{
printf("BBB\n");
return 0;
}
最后要说明的是,在使用#if命令进行条件编译时,#else为可选部分,可以省略
#if 表达式
printf("AAA\n");
#endif
若表达式的值为真,则printf语句参与编译,否则printf语句不会参与编译
#ifdef命令
#ifdef命令是与宏一起配合使用的
#ifdef 宏名
语句块1
#else
语句块2
#endif
若指定的宏是已经被定义的,则让语句块1参与编译;若宏没有被定义,则让语句块2参与编译。同样地,其中的#else部分是可选的,而#endif为条件编译的结束标记
下面用一个程序代码来演示#ifdef命令的使用
int main()
{
#ifdef MAC
printf("AAA\n");
#else
printf("BBB\n");
#endif
return 0;
}
对源代码进行预处理后的内容如下
int main()
{
printf("BBB\n");
return 0;
}
可见,由于源代码中并未对宏MAC进行宏定义,因此,预处理后的结果,只会让第二个printf语句参与编译
若在源代码中加入对宏MAC的定义
int main()
{
#define MAC //定义宏MAC
#ifdef MAC
printf("AAA\n");
#else
printf("BBB\n");
#endif
return 0;
}
在条件编译之前,通过#define命令定义了宏MAC。这时再对源代码进行预处理
int main()
{
printf("AAA\n");
return 0;
}
可见,在定义宏MAC之后,第一个printf语句参与编译了
我们在定义宏MAC时,只标明了宏名,并没有给出对应的宏值。这时因为在条件编译中只会去检测这个宏是否被定义,并不会真正去使用这个宏值
#ifndef命令
#ifndef是与#ifdef意思相反的一个预处理命令,中间的n表示non的意思
#ifndef 宏名
语句块1
#else
语句块2
#endif
若指定的宏没有被定义,则让语句块1参与编译;若宏已经被定义,则让语句块2参与编译
#ifdef命令和#ifndef命令经常使用在头文件中,这样做的好处是,能够防止头文件的重复包含
有一个头文件head.h
struct STU
{
int num;
char name[20];
float score;
};
接下来在源文件中通过#include命令包含头文件head.h
#include "head.h"
#include "head.h"
int main()
{
return 0;
}
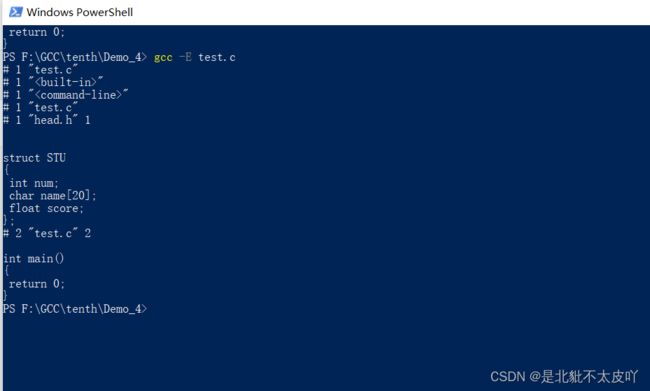
代码中包含了两次头文件head.h
编译该程序,会得到如下的错误信息

错误的原因在于两次包含了头文件head.h,每个包含命令都会被替换为结构体STU的定义语句,结果造成了结构体STU的重定义。如果对程序进行预处理,会发现预处理后的源代码为
从结果可以清晰地看到,预处理后的代码的确出现了两次结构体STU的定义

可以在头文件中加入条件编译来解决,修改后的head.h
#ifndef _HEAD_H_
#define _HEAD_H_
struct STU
{
int num;
char name[20];
float score;
};
#endif
当源文件中第一次包含头文件head.h时,由于没有定义过宏_HEAD_H_,因此,便会定义宏_HEAD_H_,并将结构体STU的定义替换进来。当第二次包含头文件head.h时,由于之前已经定义了宏_HEAD_H_,因此,结构体STU的定义就不会再被替换进来。即使对头文件head.h包含多次,也不会造成结构体STU的重复定义了
经过预处理之后,源文件代码中只会出现一份结构体STU的定义。对该源文件进行编译也可以顺利通过,不会产生错误了