BI 数据可视化平台建设(2)—筛选器组件升级实践
作者:vivo 互联网大数据团队-Wang Lei
本文是vivo互联网大数据团队《BI数据可视化平台建设》系列文章第2篇 -筛选器组件。
本文主要介绍了BI数据可视化平台建设中比较核心的筛选器组件, 涉及组件分类、组件库开发等升级实践经验,通过分享一些对交互和业务耦合度高的组件开发迭代的思考,希望可以给正在做组件重构解耦的读者带来启发。
往期系列文章:BI 数据可视化平台建设(1)—交叉表组件演变实战
一、引言
BI产品通常包含大量复杂的数据信息,需要对其进行快速和准确的处理和分析。筛选器可以帮助BI产品的用户快速地定位所需信息,并从海量数据中筛选出有用的数据,以便进行深入的分析和决策。敏捷BI作为公司内部用户数最多的可视化平台,随着平台的业务增长和版本迭代,其筛选器功能也越来越丰富和完善,旧的设计架构也显得越来越臃肿且难以维护,为了提高筛选器使用的稳定性和降低后续迭代维护成本,筛选器的架构升级已经不可避免了,本文主要给大家介绍一下筛选器组件的架构升级实践经验。
二、前期设计
2.1 组件选型

前期筛选器组件的职责和交互比较简单,主要是对图表数据进行单向的数据过滤,并没有应用到其他的业务场景中,所以前期的组件设计主要以 业务组件 的思路进行开发实现。
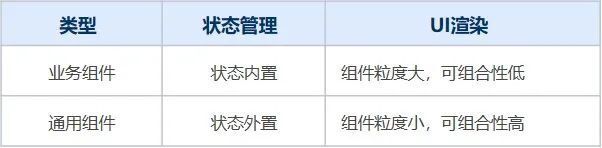
2.2 组件分类
组件类型主要可以分为业务组件和通用组件两种,它们在组件的状态管理和界面渲染的设计和实现上是完全不同的。
但无论是业务组件或者通用组件都具备组件本质所包含的三个性质 扩展、通用、健壮:
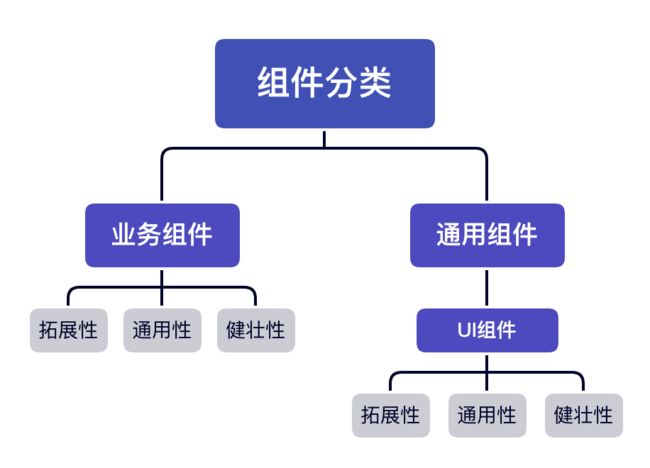
- 扩展性:在原有组件基础上可 二次封装 扩展成新的组件符合设计的开闭原则。
-
通用性:根据组件接受的参数和组件中与业务的解耦比来衡量组件的通用性,并不是通用性占比100%的组件就是最好的组件,需要根据 不同的场景 分析。
-
健壮性:避免组件中参数处理和函数执行过程可能出现的奔溃和错误导致程序的直接挂断,单测以对组件内部 做好边界处理,异常错误的捕获来衡量这一标准。
因此两种组件类型没有绝对优劣之分,重要的是在保证组件设计的基本原则不变的情况下,根据不同的业务场景和需求选择合适的类型 。无论哪种组件,随着不断扩展,使其通用性提升,必然就会降低组件的易用性质;而不断丰富一个组件,也会导致其组件代码过长、组件使命不单一、不易读、不易维护;因此组件设计除了要保证组件的基本性质,还要通过明确组件职责、组件拆分粒度以及良好的代码结构和Api设计规范对组件的迭代进行约束,避免代码逻辑的过度叠加和膨胀。
2.3 背景痛点
旧版筛选器组件设计存在维护成本高且问题BUG多等问题,主要由两个原因造成,第一个是业务发展,随着业务的快速增长,筛选器组件的功能也越来越丰富和完善,由原来的单一功能升级成可以支持数据预警、个性化分析等多种业务场景的核心模块;第二个是缺乏规范约束,主要是缺少良好的代码结构和清晰的组件职责等规范约束,导致业务逻辑过度叠加,粒度拆分不合理,文件多,且文件名不规范。最终导致了筛选器组件的稳定性越发不可控。

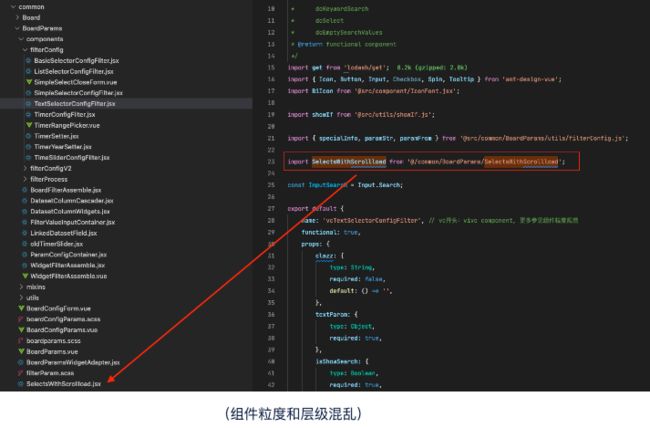
由于前期设计不合理和缺乏规范约束,筛选器组件经过了一段时间的野蛮式迭代扩展带来了以下的痛点问题:
-
重复代码多,复用性差:相同的业务逻辑需要维护多份代码,导致出现bug的概率大大增加,后期维护成本增加;
-
业务耦合度高,缺乏设计模式进行管理:更新迭代过程中处理逻辑需要兼容多种场景代码越来越复杂,导致问题难以跟踪,难以定位问题意味着你可能需要花大部分的时间处理问题;
-
编码风格不一致,维护成本高: 项目主要技术栈是Vue,但是代码风格有大部分格使用的React的jsx形式进行开发;项目存在多人维护,个人技术参差不齐;导致后续学习成本增加;
-
组件嵌套层级深,存在双向数据流:不符合Vue 单向数据流状态管理理念,无法追踪局部状态的变化,增加了出错时 debug 的难度,经常出现修改一个模块bug而引起其他模块bug的情况。
三、新版架构设计
3.1 设计思路
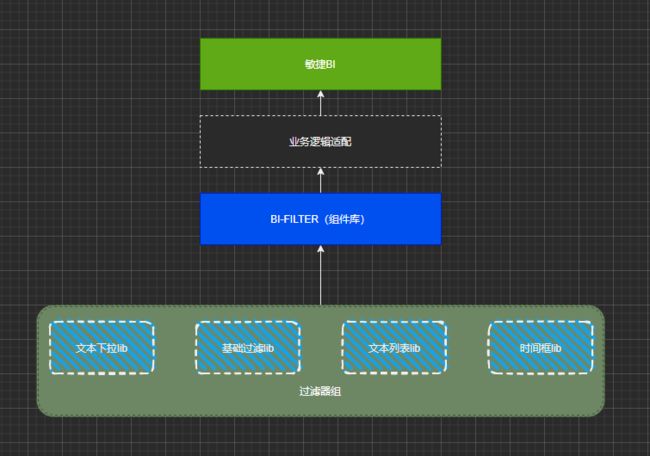
旧版的组件随着业务发展迭代,已经混杂着大量的业务逻辑,组件耦合严重,职责也越发不清晰,因此为了合理的划分组件职责和清晰代码结构,新的架构设计将基于 通用组件 的设计思路,将筛选器组件抽离出BI业务;从BI项目的架构、技术选型、文档使用等多个方面进行考虑,在原来的基础上改造太复杂,可行性低,所以搭建了一个新的项目,将之前所有的筛选器组件迁移到新项目上,稳定后替换BI项目上所有旧版筛选器组件,后续统一只需维护一个组件库(bi-filters)。

3.2 实现方案
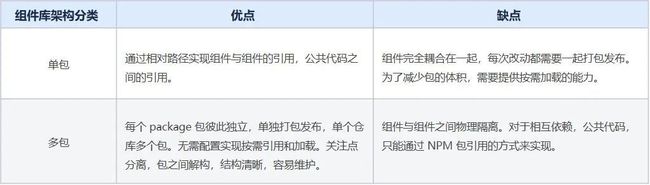
筛选器组件库(bi-filters)主要 基于Vue CLI 的 开发/构建目标/库 能力以及 Lerna 包管理工具 进行设计开发,这种组件库设计集成了以下特点:
-
按需引入:每个UI组件都是一个npm包,多语言、工具和样式都是自成体系的npm包,可被业务或UI组件灵活引用,同时天然支持按需加载。
-
配置简单:如果需要进行构建处理,那么每个npm包可单独进行构建配置,配置变得更加简单。结合Vue CLI的构件库能力,对于简单UI组件的构建几乎可以做到webpack零配置。
-
独立部署:组件库的版本迭代可以更快,不需要进行整体构建,每个组件可单独快速发布。
1. 利用 Lerna工具进行多包管理,快速对组件库进行版本发布
组件库目录结构:

2. 组件设计和实现
参考 装饰器设计模式,对组件进行抽象设计,从而达到业务状态与 UI 状态隔离,UI 状态与交互呈现隔离的目的。具体实现是先按功能将组件拆成展示层,逻辑层,容器层,达到组件分层可复用。再通过
$attrs/$listeners对antd组件进行二次封装,抽离成在筛选器组件库内的公共组件,达到交互可组合。最终使得组件边界清晰,符合设计规范中提到的开闭原则、单一职责原则、里氏替换原则。
以文本下拉筛选器组件(TextDropDownFilter)实现为例:

(1)按功能将组件拆分成 容器层、逻辑层(搜索框逻辑层、 下拉列表逻辑层 )、展示层(搜索框展示层、下拉列表展示层):


(2)BI项目中使用 :引入筛选器组件后, 在BI应用层处理业务场景,将处理业务后的状态信息通过 Vue 插槽(Slots)的方式传递给底层的筛选器组件 。
(3)搜索框逻辑层:接收业务处理后的状态,进行不同的UI组合展示
(4)搜索框展示层:由 antd 基础组件组成,提供交互单一且可复用的UI组件
3. 最后利用 Vue CLI 的构建库功能,对不同类型的筛选器组件进行单独构建打包
vue cli 的构建库能力可以通过 --target 选项指定不同的构建目标。它允许你将相同的源代码根据不同的用例生成不同的构建。


在组件库项目的 packages 目录下,每一个筛选器组件的目录下都需要创建 package.json文件,用于组件的构建信息配置:
{
"name": "@bigdata/TextDropDownFilter", //包名
"version": "0.0.0", // 版本号
"private": false, // 为true时不会被发布
"main": "dist/编译文件名.umd.min.js",
"scripts": {
"build": "vue-cli-service build --target lib --name 编译文件名 --dest dist ./index.js",
"lint": "",
"test:unit": ""
},
"files": [
"dist"
],
"author": "",
"license": "ISC",
"description": ""
}四、效果收益
1. BI项目整体代码量减少,组件目录结构清晰,只需要专注维护业务逻辑

2. BI业务抽离后,筛选器组件可进行独立维护迭代,减少代码耦合,只需专注功能交互和性能优化,提高组件稳定性。
五、总结
从上述的升级过程可以看出,组件的抽象与抽象粒度是没有一成不变的统一标准,也没有对与错。组件的设计更多的应该去关注如何适配不同的业务场景和需求要求,追求更多的是“适合”。有的时候,同样的业务场景,组件粒度的标准也会随业务场景变化而变化,甚至可能随场景增加而持续重构,因此为了代码更好的维护和分层,以及避免代码逻辑的过度叠加和膨胀,必须制定一些组件抽象的规范加以约束。总的来说,组件开发的方法论可能是相对中立和普适的,但组件库的整体建设方案,与所在的行业和业务有很大的关系。不同的行业领域,对交互展现的掌控程度是不一样的,因此设计组件库方案的时候,应该优先从产品项目的集成关系角度出发看待问题,这样可以保证业务的拓展和可用性尽可能不被技术方案限制。