FPGA HLS工具
HLS高层次综合
数据类型以及所要包含的头文件
引入了任意精度的数据类型

跟数据类型相关的一个函数–sizeof
对任意长度的数据类型使用sizeof

使用visual studio编写vivado的程序
需要对visual studio进行一定的修改,就可在visual studio编写vivado程序

数据类型的转化
变量的初始化
可拷贝初始化,也可以直接初始化
但是不支持初始化列表初始化
还可以通过声明所初始化数值的数据格式(例如二进制、八进制、十进制),来直接初始化变量
要避免每一行初始化多个变量,每一行只初始化一个变量

定点数的定义
分别解释WIQO四个字母的含义
W:整个定点数数据位数
I:整数部分的位数
Q:量化模式,针对低位部分
AP_RND:向正无穷舍入,其实就是舍去最低位,但是如果最低位是一个1,我们就要舍去最低位的值,并给高一位进位1
O:溢出模式,针对高位模式(默认为只整数部分的低位,AP_SAT是根据定点数的位宽决定,如果超出的位宽决定得最大值或者最小值,就会以位宽的最大值,最小值代替,下边两个都是有符号数,所以最大值为正数,最高位为0。)

单精度浮点数的定义必须要添加f,否则会定义为双精度
HLS还提供了数学库

数据类型转换
隐式数据类型转换
- 小范围向大范围的或者小类型向大类型的转换
对于有符号数,符号位的扩展,无符号数则是高位0的扩展

- 大范围的数向小范围的或者大类型向小类型的转换,会导致精度的丢失甚至错误。

显式类型转换
可以使用括号进行类型的转换,类似与c/c++中的使用方法

常用的算数运算 +和-统一为+
下面表格指定了对于运算结果所需要的最小保存位数
总之就是做到大数据不溢出,小数据不损失。

可以使用typeid函数来获取变量的类型,需要包含头文件typeinfo。

总结:创建变量的时候需要确保数据类型所用的正确性

复合数据类型在HLS中的应用
复合类型
-
c++中常用的复合数据类型就两类,一类是结构体,另一类是类
我们在我们定义的顶层函数中使用结构体时,
结构体中的标量成员会被映射为一个标量的端口,
结构体中的数组,会被映射为一个memory端口 -
结构体预先在头文件中进行声明
-
结构体中的元素,HLS提供了两种优化方式,好像叫做数据打包?
分为两种层次filed_level和struct_level

下边是执行程序,A是一个位宽为4位的数,B是一个位宽位4,深度为4的数组。

修改优化的方法需要使用HLS工具中的右侧的directive来指定对应的元素的优化方法

什么是field_level呢?
每个以元素都以8bit为边界,所以例子当中的每个元素都被从4位扩展到8位

struct_level呢?
每个元素的位宽还是保持不变,但是整个结构体的位宽是以8位边界

我们可以看到,不管是哪种优化方法,相对与原来的延时和间隔都有了很大提升,但是两种优化方法的效果是一样的,这是因为我们对for循环进行了展开。

枚举类型
枚举类型就是将数组定义为一个符号常量
需要使用enum关键字来定义
每个枚举类型中的定义元素都会被分到一个数值,就是c++中的枚举

枚举在HLS内的例子

vivado既支持结构体,也支持枚举
两种类型都可以在顶层中作为接口出现
如果是结构体出现在顶层函数中,它会通过data_pack的filed_level和struct_level来封装结构体。
如果枚举类型出现在顶层函数,它会被顶层函数自动的推断

基本运算操作
运算符

赋值运算符

例子:
当我们需要在程序中使用常数时,需要显示的指定转换的类型

自增自减运算符

条件或关系运算符

逻辑运算与位运算

复数乘法的例子
例子说明:
使用复数运算,首先我们需要包含复数的头文件,也可以说是模板类!真的有这个类!
头文件:< complex >
comple实在std的命名空间内
操作的函数是std的命名空间下的求实部和虚部函数real()和image()
总共进行了四次乘法和两次加法

下面的方法使用了三次乘法和五次加法

资源使用情况对比,可以看出不同算法,使用的资源也不同

注意:递归函数 vivodo HLS是不支持的
如何高效的描述一个ctestbench
testbetch使用来验证我们设计的算法或模型的正确性的环境
下图中的Driver/Stimulus是指的是输入激励,Reference是一个标准的参考值,DUT指的是我们写的算法,Monitor是指我们的激励通过算法产生的结果,scoreboard是对比板,用来对比我们算法激励得到的结果和参考值的一致性,我们通常认为Reference是一个正确的值

为什么要用ctestbench
- 目的当然是要验证算法的正确性
- c仿真的时候要比RTL仿真更快啊
- Vivado可以复用ctestbench来检验我们的RTL设计
- ctestbench文件既可以验证C函数的有效性,又可以验证RTL的设计

怎么样才算一个高效的testbench呢?
- 对于综合顶层函数可以用于多个事务,可以同时测试多个激励
- 函数输出与我们的正确的参考值进行对比
- 正确返回0,不正确返回1

例子


- Stimulus用来提供输入数据,可以使用数组或者额外的文件来提供激励
- Reference Model用来提供黄金参考值,可以使用数组、额外的文件或者由软件的计算来提供
- DUT就是我们要测试的算法,一般来说,它就是我们的顶层函数,用来被综合的,它接受激励,产生输出,输出的结果可以存储在数组或者额外的文件中
- Scoreboard是我们用来比较输出数据和黄金参考值的部分,提供了记录不相等的数据和个数,并且打印出来不相等的部分
框图下边将详细讲述各部分。
测试激励的来源
 可以直接定义变量、数组、或者外部文件,三者都可以用来产生激励。
可以直接定义变量、数组、或者外部文件,三者都可以用来产生激励。
使用数组作为测试激励

使用外部文件作为测试激励源
使用外部文件可以更方便的获取更多的数据,灵活性也更大
- 创建文件流 -> 读取数据 -> 将数据存储到数组中

- 从文件中读取数据的方法

- 具体例子 1
- 推荐将文件和测试的testbench同时加载进仿真设置选项,就如下图一样
- 在使用文件流的重载>>运算符读取数据是,需要注意,我们的例子中定义的数组是ap_int<8>类型,会导致我们直接将文件流中的数据通过重载>>的方法传递给数组会报错,所以我们需要一个int类型的变量作为中间桥梁

- 具体例子2 使用读取文件的函数模板方式
- 可以满足多种不同的数据要求
- 最好写在一个头文件中,在主函数中包含头文件

什么是得分板
得分板的主要功能就是比较DUT的在激励的输出和黄金数据,以及给错误数据一些信息
一般来说,两种得分板的比较方法是:1. 使用if判断 2. 使用system这个函数

两种方法的实现方法
- 有些时候,DUT的结果可能不是与黄金数据完全相等,比如浮点数情况。这个时候我们就要比较绝对值误差。
- 如果我们要使用system函数来做比较,我们必须首先要将DUT的输出数据写到一个外部文件夹里,并且将黄金数据存储在另一个外部文件,通过这种方法,system函数可以展示DUT函数的与黄金数据的区别。确保两个文件的格式是相同的。

如何将输入写到外部文件
- 首先fstream头文件需要包含,并且为了可复用性,我们可以定义一个模板,这个模板最好保存在头文件下,模板如下

输出格式的控制
- setw函数来保证输出的字符宽度,对齐方式为left、right、internal

整数的输出
- 对于二进制使用bitset类的方法强制类型转换
对与八进制使用cout<( 默认即为十进制 )
对与十六进制使用cout<- 使用to_string函数转换为对应进制的string类型,在使用c_str转换为C类型的字符串
对与二进制使用to_string(2)
对与八进制使用to_string(8)
对与十进制使用to_string(10) ( 默认即为十进制 )
对与十六进制使用to_string(16)

- 使用to_string函数转换为对应进制的string类型,在使用c_str转换为C类型的字符串
定点数输出
- 对于二进制使用bitset类的方法强制类型转换
对与八进制使用cout<( 默认即为十进制 )
对与十六进制使用cout<- 使用to_string函数转换为对应进制的string类型,在使用c_str转换为C类型的字符串
对与二进制使用to_string(2)
对与八进制使用to_string(8)
对与十进制使用to_string(10) ( 默认即为十进制 )
对与十六进制使用to_string(16)

- 使用to_string函数转换为对应进制的string类型,在使用c_str转换为C类型的字符串
浮点数输出
- 浮点数的格式控制主要十设置精度和输出模式
- setprecision() 设置小数点后的位数
- cout<
- cout<

- cout<
总结
我们可以使用system(“diff -w file1 file2”)函数来进行比较
通过控制输出格式,我们可以获取更多有用的信息
一般来说,推荐使用to_string()函数方式相比于cout<
接口综合
在综合后,会生成一些接口,在下例中,共有三类接口
- 第一类是块之间的接口,名字格式为ap_xxxxxx,输入输出类型都有。主要是起到块之间的控制作用,函数内是看不到这类端口的。
- 第二类是返回值接口,为输出类型,名字为ap_return
- 第三类是参数接口,也就是我们顶层函数的参数
- 注意: 这个列表中没有看到时钟
块层次接口协议可以特指在函数或者函数返回值
常用的接口模式可以选择ap_ctrl_hs(handshake)、ap_ctrl_none、ap_ctrl_chain三类

我们在上边的directive中配置INTERFACE接口默认分别为ap_ctrl_ts和ap_ctrl_none,发现ap_ctrl_hs会比ap_ctrl_none少出现四个接口。

下面波形图显示的是ap_ctrl_hs。 - ap_start 代表的是当此信号为高,开始处理数据
- ap_ready 代表此信号为高,这个块准备好接受新的输入
- ap_done代表此信号为高,处理操作完成
- ap_idle代表此信号为高,块出于空闲状态

端口层次的接口
ap_none协议
- 看in1和in2采用的是ap_none协议,他们正是我们的顶层函数所传入的两个参数in1、in2
- 指针相对性的信号被分为了两部分为in_out1_i和in_out1_o两个端口,并且还多一个指明in_out1输出有效的端口in_out1_o_ap_vid。
- ap_none协议针对的是这里的形参,并且默认针对的是标量输入
- 提一下,ap_stable协议指的是当我们的芯片在复位状态,我们这个端口的值会发生变化,我们需要使用ap_stable这个协议

ap_ovld协议
- ap_ovld被用于同时可以输入输出的参数
- 下面的输出输出被分为了输入端口和输出端口两部分,输入部分端口使用ap_none协议,可以输出部的端口使用ap_ovld协议。
- 对于指针参数,既可以用来读,也可以用来写,类似于函数中,指针传递的变量既可以做为左值又可以作为右值

值得注意的是 ap_hs协议,他有两个端口,分别别是ap_vld和ap_ack - ap_vld 代表的是有效信号
- ap_ack代表的是响应信号

下图是数据类型分别为标量,也就是变量或者指针或者引用的时候,接口协议的默认选择。
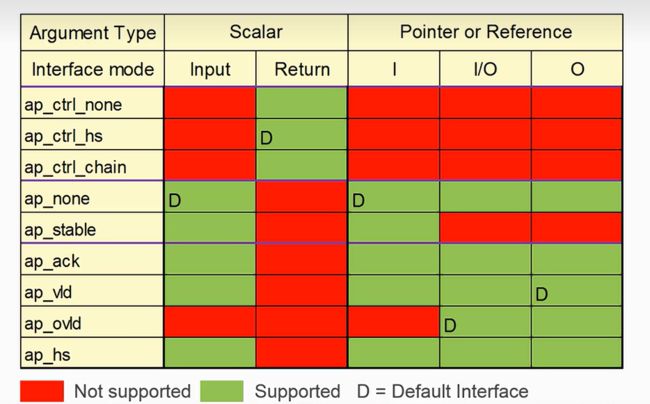
总结
- 对于块之间的协议(就类似与模块之间的协议选择),常用的就是ap_ctrl_hs和ap_ctrl_none
- 对于端口层面的协议,变量输入,指针输入,引用输入默认选择ap_none协议
- 对于端口层面的协议,return返回,指针输出、引用输出默认选择ap_vld协议
- 对于端口层面的协议,指针输入输出和引用输入输出默认选择ap_ovld协议

数组映射为端口
- 此处的数组是指的是顶层函数的形参,不是函数内的形参
- 子函数的形参后续再说
- 默认情况下,数组形参被映射为内存的端口,包含读写使能,读写地址和数据端口,也* 可以在hls中设置为单端口和双端口的RAM,如果没有指定且如果单端口可以满足,那就使用单端口
- 通过使用directives,你可以设置使用单端口还是双端口的内存接口
- 使用FIFO接口
- 分布成离散的端口

- 默认情况下ap_memory协议只被使用在顶层函数中的数组参数
- 不论这个数组是输出还是输出的,ap_memory协议都是默认的协议

- d_i_address0:方向为输出,输出读的内存地址
- d_i_ce0:方向为输出,输出的是片选的使能
- d_i_q0:方向为输入,输入的是从内存当中读到的数据
- d_o_address0:方向为输出,输出的是数据将要保存到内存中的哪块地址
- d_o_ce0:方向为输出,输出的是片选的使能
- d_o_we0:方向为输出,输出的是写使能信号
- d_o_d0:方向为输出,输出的是向内存块输出的数据

下图中间就是顶层函数对应的模块与左边的提供输入的内存和右边可以保存输出数据的内存的控制关系,所有的控制端口均有用到

ap_fifo协议
将顶层函数中的接口协议设置为ap_fifo协议,可以看出生成的端口包括fifo读/写控制信号、fifo的空/满标记信号、fifo的数据输入/输出的端口,数据必须要有一定的顺序才可以选择ap_fifo协议
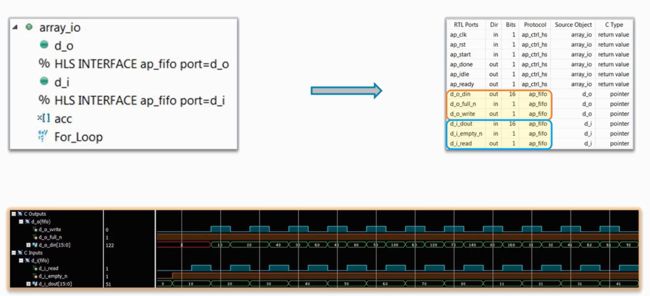
总结
- 默认情况下,数组会被映射为单端口或者双端口模式,这由HLS决定
- 数组可以被分离成离散的端口
- 数据是流的形式,也就是先进先出,ap_fifo协议也可以被选择

接口综合其他案例
输入输出端口添加寄存器
- 添加寄存器是一个解决时序问题的很好解决方法,默认,HLS不会为每个添加端口寄存器,需要我i们对directives中添加配置
- 对于输出端口,此例也就是函数返回值,需要在函数端口处配置directive添加寄存器
- 标量或者别的参数添加寄存器类似

- 下图就是添加上寄存器的情况。对顶层函数的返回值添加寄存器的时候需要选择协议ap_ctrl_hs。

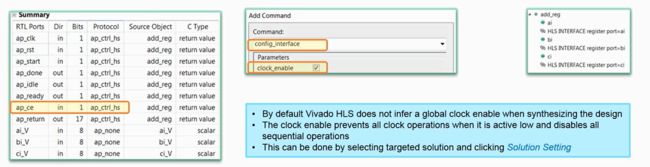
如何对全局添加时钟使能信号
- 添加上这个使能信号,会在端口列表中出现ap_ce端口,需要在solution setting层面下的configure setting添加中选择 config_interface,并勾选clock_enable;
- 默认情况下不会添加clock_enable
- 所有的电路只有在这个clock_enable使能的情况下才能工作,也就是说前期时钟可能不稳定,频率或者相位有偏差,对程序有影响,当时钟稳定时,使能时钟,就可以开始正常工作了
如何使顶层函数获取更低的延迟和更少的IO数
- 对于更低的延迟,我们可以使用pipeline来减少for循环
- 对于更少的IO呢?

- 在对for循环添加pipeline,将会导致单端口变成双端口,可以使延时降低,但是端口数量增加。
- 如何能使它的延时降低还能保证使单端口

- 对数组进行约束,可以实现端口数量大致不增加,同时还降低了延迟
怎么对数组进行约束呢? - 来了!!!
- 我们需要只改变数组的实现方式,还是编辑数组的Dircetive,选择RESOURCE,在core选择RAM_1P


config_rtl的配置
- 可以帮助我们去指定状态机的编码方式
- 同时还可以帮助我们指定复位的相关属性
- 同步还是异步
- 高有效还是低有效
- 也是在添加寄存器的地方选择config_rtl来进行配置

总结
HLS提供了
- 可以向IO添加寄存器
- 全局的时钟使能
- 设置复位属性
- 控制IO的个数

for循环优化
- for循环的基本概念
- pipeline在for循环中的应用
- for循环中流水的优化
- for循环中的数据类型是否对综合后的资源有影响

for循环的性能指标
- 循环次数:for循环执行了多少次
- 循环迭代等待时间:本次for单次循环执行的时间
- 循环迭代间隔时间:本次单次for循环到下次单词for循环所需要的时间
- 循环等待时间: 循环过程执行的时间
- 函数延迟: 函数从开始执行for循环(包括读取数据),到循环执行结束的时间
- 函数初始化间隔: 从第一次循环初始化(读取不变数据)到下一次初始化数据的时间
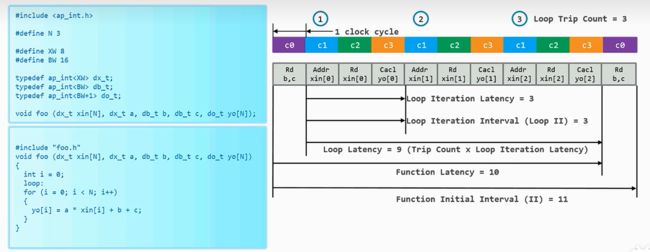
- ap_start开始为高的时刻到ap_done开始为高的时候为函数的执行时间
- ap_done开始为高的时候到下一次ap_done开始为高的时候为函数的执行间隔时间
- 对于硬件来说,需要消耗额外的时钟周期来判断对应的i是否超过了循环边界

对for循环的优化
流水线方式
- 对for循环的标号选择编辑directive,在directive下选择pipiline
下边就是降低延时和间隔原因,有一定的并行性在里边
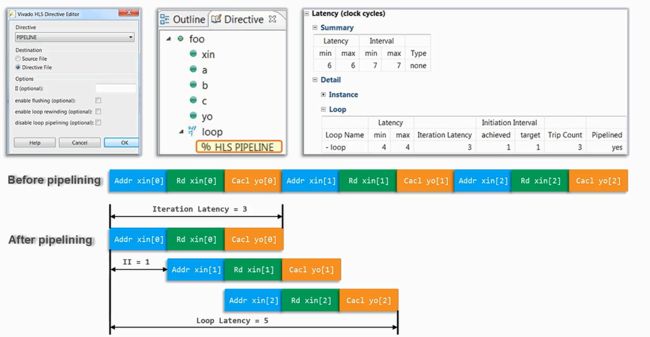
在波形图中查看信息 - 函数延时:ap_start开始为高到ap_end开始为高的时间段,也可以理解为函数执行时间
- 函数初始化间隔:ap_done开始为高的时间到下一次ap_done开始为高的时间

for循环展开
- 默认情况下,for循环是折叠的
- 折叠可以这样理解,每一次循环都是采用同一套电路,只是电路被分时复用了
- 展开意思就是这个电路被复制了n份、或者n/2份等等,可以并行的进行计算
- 例如下图乘法器,对于循环次数为3,如果展开,那么相同的电路将被复制为3份,并行进行计算

- 也可以使用将循环进行分组,分别使用不同的电路
- 例如下边程序就是将循环次数为6次的循环,修改为3个循环次数2的循环进行并行计算

- 在for循环的标号进行directive的编辑,Directive选择为UNROLL,factor代表为复制几份,DSP48E就是乘法器

- 对于for循环的循环变量i,它的数据类型不影响最后的结果,它的最大值会被使用,但是不影响电路的实现

总结
- 理解II(执行间隔)和执行时间
- pipeline是提高循环的执行时间十分有用
- 可以允许部分展开循环
- 部分展开时是循环的速度和资源的折中
- 循环的变量i的类型不影响结果

for循环的合并
- 以下就是两个可以并行执行的for循环,怎么将他们并行执行的呢?

- 假如我们不对两个循环进行一定的改进,那么执行时按照顺序执行的,并不能体现出并行性

- 使用新建一个合并方法,新建一个标号loop_region,并在其后添加上{},包含下边的两个循环,再添加其directive,设置directive为LOOP_MERGE

- 合并之后,两个循环就公用了一套电路,进行了并行的执行

- 循环的合并降低了for循环执行的延时
- 默认情况下,for循环会创建额外的状态机,状态机一定会占用额外的时钟周期和额外的时钟资源,会导致循环执行的时间增加。
- 因此合并之后,就会引起性能方面的提升

对于不同的边界的for循环的合并(两个边界都是常数)
- 两个不同边界的for循环,会以两个for循环中最大的边界进行循环的合并

对于不同的边界的for循环的合并(一个边界是常数,一个边界为不定数)
- 没想到吧,HLS不支持这样的两种循环的合并

对于不同的边界的for循环的合并(一个边界是不定数,一个边界为不定数)
- 这种情况也是不可以进行循环合并的,但是假如K小于J,有没有别的办法进行合并呢?

- 当然有!!!!!
- 通过修改循环边界大的循环,拆分成一个和小的循环边界相等的循环和剩余的循环,这样就得到了两个循环边界相等的循环,这两个循环边界相等的循环就可以进行合并

合并for循环的规则
- 如果循环边界为常数,那么合并后的循环边界将以最大的循环边界常数为循环边界。
- 如果两个循环的边界都为变量,那么这两个变量必须相等才可以合并,或者大的边界分解成为一个和小的边界相等的循环和剩余循环,两个相等的部分可以进行合并
- 一个边界为常数,一个边界为变量,那么就不能进行合并

总结
- 一个区域就是两个括号之间的部分
- 合并for循环将会降低所需要的时钟周期的数量并且降低执行的间隔
- 不是任何类型的循环都可以合并,需要遵循上述规则

for循环的优化------数据流
- 对于下属的三个循环,是存在一个依赖的关系,那么我们如何降低执行时间或者延迟时间呢
- 添加pipeline的directives可以嘛,当然可以,这样就降低了每个for循环的执行时间或者延迟时间
- Loop merge可以嘛,显然是不行的,三个循环之间没有独立性。

- 在两个循环中间添加通道,这里的通道可以是ping-pong 内存、FIFO、或者是寄存器
- 只要上一个循环有输出数据,下一个循环就能使用它
- for循环具有一定的交叠,这种交叠提供了延迟的降低

- 在有依赖关系的循环之间添加通道,可以使for循环的延迟和执行时间有所降低
- 需要在solution setting下的general configuration选择add command,选择config_dataflow。默认channel选择的使ping-pong,这里也可以被替换为fifo
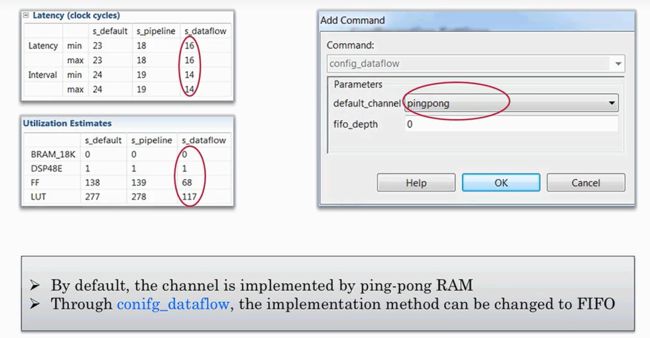
适用情形
最常用的使前两种
- 单-生产者-消费者的冲突
- 旁路任务

单-生产者-消费者的冲突
Loop1的资源将被loop2和loop3使用,且没有冲突,那么我们有什么降低延迟的方法呢?
- 可以合并loop2和loop3这两个循环或者为循环添加pipeline的directive
- 我们可以使用数据流方法来优化吗,显然是不可以的,因为loop1同时在两个for循环中都被使用

- 那么怎样进行处理,才可以使用数据流方式来进行优化,将loop生成的结果分为两份,一份给loop2,一份给loop3,这样就可以使用data-flow(数据流)方式来进行优化

旁路任务
- Loop1同时生成temp1和temp2两个数组,但是temp1又经过一个for生成了temp3,temp1和temp3在loop3中进行运算,loop1生成的数据直接抵达loop3这种情况可视为旁路
- 显然,可以使用pipeline方式降低循环执行的延时
- 循环合并,for循环之间没一定的可以公用一套电路的情况,所以不能使用循环合并
- 所以,我们也使不可以使用data-flow,不存在单一的依赖关系

- 但是我们通过对循环进行一定的改造就可以使用data-flow方式!!!!在loop2中创建一个复制loop2的情况,就可以使用data-flow了
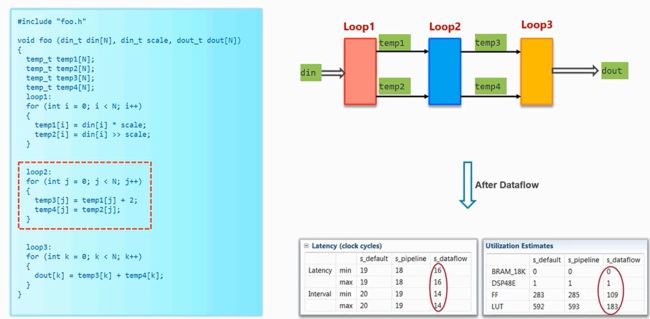
- channel可以使ping-pong RAM和FIFO,那么使怎么进行选择呢?
- 对于标量,指针,或者引用,HLS选择channel为FIFO
- 对于数组中的元素,可以使用ping-pong RAM也可以使用FIFO
- 如果数据访问有序,那么会被执行为深度为1的FIFO
- 如果没有顺序或者随机的,那么就会使用ping-pong FIFO

- 我们可以手动进行配置,但是需要注意,在使用fifo的时候,推荐使用默认深度。

总结
data-flow可以看作一种特殊的流水线方式,只要前一级循环有输出数据,那么后一级循环就可以使用这组数据进行运算,也就降低了for循环的执行时间

嵌套for循环的优化
嵌套循环的分类
- 完美的嵌套循环
内外两个循环边界相等,并且只有在内循环才有执行语句 - 半完美的嵌套循环
外循环边界为变量,内循环边界为常数,并且只有在内循环才有执行语句 - 不完美的嵌套循环
- 内外循环边界都为常量,但是在内外循环中都有函数的执行语句
- 外循环边界为常量,内循环边界为变量,并且只有在内循环中才有执行语句
对于不完美的嵌套循环,我们通过使用代码优化的方式,或者展开循环的方式来改造成一个完美的嵌套循环或者半完美的嵌套循环

完美的嵌套循环
- 对外部分for循环做pipeline,对应的循环执行时间会大幅降低,同时消耗的资源数量会增加。这里会将外侧循环展开,所以需要用到的资源会增加。

- 对内部循环做pipeline,也会降低循环执行的时延,注意这里的循环次数,是为内循环边界和外循环边界的乘积
- 上述两种优化只能用在完美嵌套循环和半完美嵌套循环

不完美的嵌套循环(对矩阵乘法的优化)
对最内的for循环进行pipeline
- 内层for循环没有被展开

对中间层for循环进行pipeline
- 可以看出最内侧的for循环被展开,加快了执行速度

对最外部的for循环进行展开
- 对最上层for循环进行展开,最内层和中间层for循环都会被展开,整体循环速度也被加快了

对上边三种for循环的优化情况进行比较
- 对最外层的for循环做流水处理,也就是pipeline directive,那么将会最大程度的加快循环的执行速度,但是最外层for循环占用的资源也是最多的

对整个函数做流水
- 对整个函数做流水,所有的for循环都被展开,这种加速效果是最好的,但是消耗的资源也最多的

执行过程
- 可以分解为下边的执行过程
- 怎么还能对其进行优化呢?
- 我们可以发现,在计算结果矩阵res的元素时,假如我们计算res[0][0]、res[0][1]、res[0][1]时,我们只用读取一次a矩阵的第零行元素即可,也就是只用读取一次a[0][0]、a[0][1]、a[0][2],对矩阵res每一行均是如此。
- 对与矩阵res的列的计算,我们可以发现,这里以res[0][0]、res[1][0]、res[2][0]为例,发现只需要对b矩阵的第零列元素读取一次即可,也就是只用读取一次b[0][0]、b[1][0]、b[2][0],对矩阵res的每一列均是如此
- 所以我们可以对程序进行进一步的优化

- 优化方式,在cache_row中,当计算矩阵res新的一行时,才会读取对应的行,在cache_col中,每当进行一次计算矩阵的元素需要新的列时,才读进所需要的列。计算矩阵res元素的值的时候使用我们提前读取的值

总结
- 当对循环或者函数做流水的时候,这个循环或者函数里包含的循环都会被展开
- 通常建议对最内层的for循环进行流水,这样既能加快速度,又能节约资源

for循环优化的其它方法
所要介绍的东西
- for循环的并行性
- for循环在做流水(pipeline)的时候使用rewind这个选项
- for循环的循环边界时变量的时候如何进行处理
for循环的并行性
- 两个相互独立的for循环是可以并行执行的,但是默认情况下是会进行顺序执行的

- 可以使用for循环的合并来加快执行速度,但是假如两个循环,一个是边界时常量,另一个边界时变量时,就不能使用循环合并的方法来解决了
- 若将for循环的执行过程封装为函数,函数执行还是会按照顺序执行的方式
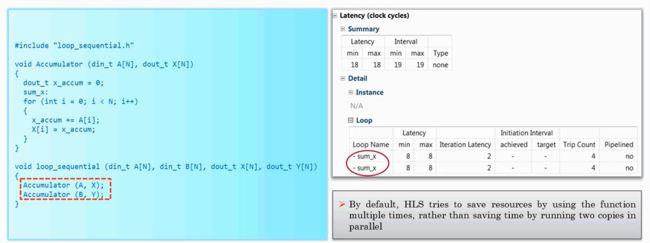
- 那么有没有什么方法,使函数并行执行呢?当然有,需要在函数的directive edit中选择ALLOCATION,将limit设置为2,这样就相当于电路复制为两份,加快了执行的速度。即选择了封装为函数,并且还对函数内的循环计算进行了pipeline流水展开


for循环在做流水(pipeline)的时候使用rewind这个选项
-
在我们开启了for循环的pipeline的大前提之下,在我们不对这个for循环开启rewind这个选项的时候,两次for循环之间会有停止的时钟间隔,但是如果开启了rewind这个选项,两次for循环之间会持续的进行流水线的执行

-
如何开启见下图

-
在波形图中,我们也可以清楚的看出,开启rewind,两次for循环之间是没有间隔的

-
当函数中有多个for循环的时候,开启pipeline中的rewind就会报错,所以可以看出,rewind并不是适合所有的for循环,它是有条件的。

-
自动添加流水 ,使用set solution中的configuration setting中添加config_compile,设置pipeline_loop,当循环的次数低于设置的pipeline_loop时,就会自动添加pipeline流水,在编辑for循环的directive,选择INTERFACE,可以设置不使用pipeline流水,这样for循环自动添加流水就不会影响到此for循环

-
什么时候添加pipeline会失效呢?当函数和for循环被添加pipeline时,函数和for循环里面的运算就会被展开,但是如果循环的边界是一个变量的时候,HLS就会阻止这样的pipeline流水,原因是因为HLS并不知道这样的循环何时会停止

如何处理循环边界时变量的这种情况呢
-
当循环边界是变量的时候,HLS会无法确定整个循环的执行时间,进一步也就无法确定整个函数的执行时间,这时候相应的执行时间会以❓的形式来代替

-
对于这种情况,我们有如下三种处理方式
- 使用LOOP_TRIPCOUNT这种directive
- 将循环边界的数据类型声明为ap_int类型
- 使用C语言的assert宏
-
使用LOOP_TRIPCOUNT这种directive,不会对综合的结果有任何影响,只对报告有影响

-
将循环边界的数据类型声明为ap_int类型

对于综合后的结果会有影响,使所使用的资源降低

-
使用C语言的assert宏,需要包含
这个头文件,并且需要在函数中使用assert (width < 5),所用到的资源也会进一步的减少


-
三种方法进一步比较,assert所消耗的资源是最少的,循环执行的时间也是最少的

总结
- 默认情况下,HLS会对具有并行性的循环进行顺序执行,只有对其进行设置并行执行时,才会进行并行执行
- 使用pipeline的rewind可以改善for循环的执行速度,但是并不是所有的for循环都可以使用rewind这个pipeline选项
- 有三种方法可以处理循环边界时变量的问题,推荐C语言assert宏这种方式,加快循环执行速度最明显,消耗的资源最少

数组的优化
数组的分割
-
对于数组,可以resource这个directive可以明确告知HLS当前这个数组是使用什么样的memory来实现的,比如通过分布式的还是block ram,是采用单端口,还是双端口,如果没有使用这个resource这个directive,HLS会自动推断出是单端口还是双端口,取决于哪种方式可以有效地加快执行速度
-
在综合后,数组最终会以memory这种形式出现,包含了RAM,ROM,或者FIFO这三种形式
- 如果数组作为顶层函数的参数形式出现, 它最终会映射为memory相应的端口来呈现,包含相应的读写地址和数据,还有读写使能。
- 如果这个数组是在函数的内部,那么这个数组会被映射为block RAM,LUTRAM,UltraRAM或者寄存器取决于我们在设计中使用的策略和优化方法
-
下边图片描述有错误应该是在sum处,添加directive,选择SOURCE选项,在core选择RAM_2P_BRAM,同时for循环也进行pipeline展开流水,这样就通过设置数组加快了循环的执行速度。

-
HLS提供了三种对数组分割的方法
- 按照块来进行分割
- 按照循环顺序来进行分割即分割的类型选择为cyclic
- 选择完全分割,也就是register/complete
-
都是在array_partition的directive下进行类型(type)选择,同时需要设置数量(完全分割除外)

*三种数组分割方式对数组的操作执行均有加速的效果
-
是不是意味着越多的block越多,效果越好呢?
-
实际上,block的数量取决于真是的数据流,因为上面例子我们一次运算只需要3个数据,我们使用两个block,并且一个block有两个端口,对于我们来说,数据也是够用的

对于多维数组,应该如何分割?
- My_array为一个三维数组,当partition_dim为3和1时,三维数组被分割成了不同的情况,其中partition_dim是指的是按哪一个维度来分割数组

下面是对一个实际的二维数组进行不同的block分割

从仿真的结果,我们可以看出分割的方式和我们上述推断的是一致的

总结
- 数组的分割分为完全分割,块分割,和循环分割三种
- 数组的分割可以改变吞吐率

数组的映射和重组
- 在我们的C代码下,如果我们有小的数组,那么我们可以通过合并,通过映射使小的数组合并成为一个大的数组,大的数组会消耗相应的内存,来降低资源的用量
- HLS对数组的映射提供了两种方式,一种是横向,另一种是纵向

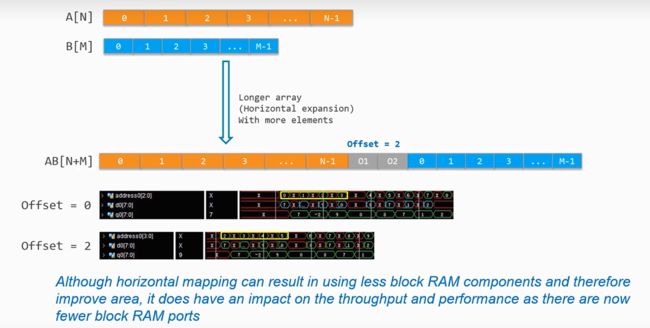
- 横向映射
合并后的数组长度会增加为原来数组们的和,两个数组存储的宽度可以不一致,我们可以在ARRAY_MAP的directive中进行相关的设置,mode设置为horizontal,instance设置为合并后数组的名字

对于这个横向映射,可以存在地址的偏移,对于这种方式,尽管可以减少消耗的资源,但是对于执行速度上来说,并没有提升
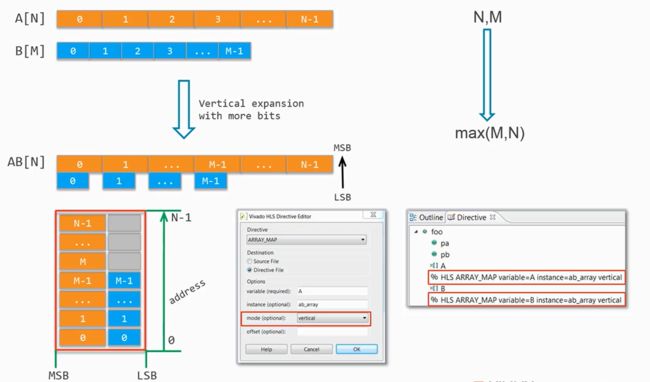
- 纵向映射
将相应的元素进行位拼接,所以合并后数组的长度不变,但是数据相当于加宽了
数组的映射与合并的结合
- 前两行是将数组进行分割
- 后两行是将数组进行映射后的合并
这样就即节省了资源,有提高了吞吐速率

数组重组
- 将数组的分割和数组的纵向映射合并在了一起,可以降低资源用量,提高数据的并行性。由于数组的分割有三种方式,所以数组的重组也有三种方式。数组重组是针对同一个数组的,不是多个数组

- 代码第一部分
对数组pa的奇偶数位进行不同的操作 - 代码第二部分
对数组pa前后两部分进行不同的操作 - 对处理后的两个数组分别进行操纵,再回写到原来的数组

- 结果对比
数组映射可以对所用资源进行降低,但是对数据吞吐率没有减少
数组重组可以对资源进行降低,还可以对吞吐率有所提高

总结
- HLS提供了纵向和横向两种映射方式来减小我们所使用的RAM数量,但是都不能提高数据吞吐率
- 数组重组可以降低我们对资源的消耗,同时又可以提高吞吐率

数组优化的其他方法
如何定义一个ROM
- 最简单的方法就是 const + 初始值,优点就是简单易行,缺点如果数据量大,那么将在代码里书写值将会很繁琐,代码管理也将很不方便,占用量也很大。

- 采用头文件的方法来定义一个rom,将会更见简单,并且灵活性也大,而且管理起来也更加方便,注意包含头文件的方法,头文件里的内容如下注意逗号和空格。


- 如果ROM里的存储值是通过数学公式的计算得到的,HLS会帮我们推断出一个ROM来存储数据

- 默认情况下,ROM的输出延迟为2,增加ROM的输出延迟会有助于改善时序。可以通过修改变量的directive下的RESOURCE接口,修改ROM的输出延迟。

数组的初始化
- 如果映射为memory,需要在数组名前面添加static,这样就能保证数组的实现是以memory的形式实现的,而且可以保证它的初始化类型与RTL实现的类型是一致的。
- 当数组有初始值的时候,如果没有加static这个关键字,对这个RAM/ROM进行操作的时候,先会对这个memory进行初始化的操作,那么这个初始化的过程所需要的时间是与这个memory的尺寸是有很大关系的。如果数组前面加了static,这个数组是提前被初始化好的,更加节约时间。

总结
- 如果我们这个数组要对应RTL中的ROM需要加const,也可以使用头文件的方式在代码里进行赋值
- 如果我们这个数组要对应RTL中的memory需要加static

函数层面的优化
函数的代码风格
- 函数的主要风格就是函数的参数和接口
- 在HLS中,我们需要使用任意精度的数据类型,所以当我们一定要将变量定义为任意精度的数据类型
- 使用默认数据类型和使用任意精度的数据类型,将会导致使用的资源数量不同

inline
- 也就是内联函数,去除了函数的层次化,可以使用函数的directive中的INLINE来使用
- 使用inline可以改善资源,这是因为使用inline后,就可以不用再使用调用函数的逻辑
- 对于小的函数,HLS将会自动进行inline处理
- 如果我们不喜欢inline,我们可以通过使用directive中的INLINE的-off选项来关闭此函数的inline

ALLOCATION
- ALLOCATION定义了函数与相应的RTL模块的关系
- 使用调用函数的函数的directive中的ALLOCATION选项,配置函数名和实例的次数

- ALLOCATION的影响
ALLOCATION是执行效率和资源的折中,即提高了执行速度,又不会消耗过多的资源

函数中的DATAFLOW
- 将函数之间穿行执行,转换为并行执行

- DATAFLOW可以应用于顺序执行的一些任务,例如函数或者循环或者两者都有
- 将顺序处理机制转换为并行处理机制
- 当前任务并不需要等到前一个任务执行完毕,它们是可以并行执行的
- 提高了数据吞吐率,降低了执行的延时

- 可以在函数的directive中选择DATAFLOW开启数据流模式

总结
- 任意精度数据类型可以帮助我们降低资源的使用
- inline可以帮助我们提高执行速度
- ALLOCATION可以帮助我们实现资源和执行速度的折中
- DATAFLOW可以有效改善数据的吞吐率
案例
可以用作改善吞吐率的directive
- 我们可以发现,改善吞吐率是通过提高并行度来实现的

PIPELINE在函数和循环上的区别
- 函数上函数按照指令连续执行,在IO访问上是一个流水线的方式
- 循环在中间会又一个时钟的停止,在IO访问上,中间会存在一段空白期

DIRECTIVE在延迟上的优化
- LOOP_MERGE针对可以并行的循环,提高吞吐率的
- LOOP_FLATTEN是针对嵌套的循环,实现流水线操作,进而提高吞吐率

DIRECTIVE在资源上的优化

例子实现
- 分为预处理、中间的运算单元和后处理
