由一次安全扫描引发的思考:如何保障 api 接口的安全性?
引言
前段时间,公司对运行的系统进行了一次安全扫描,使用的工具是 IBM 公司提供的 AppScan 。
这个正所谓不扫不要紧,一扫吓一跳,结果就扫出来这么个问题。
我们的一个年老失修的内部系统,在登录的时候,被扫描出来安全隐患,具体学名是啥记不清了,大致就是我们在发送登录请求的时候,有个字段名是 password , AppScan 认为这个是不安全的,大概就是下面:
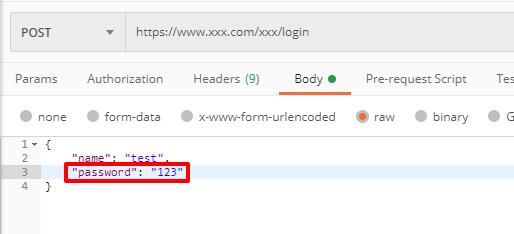
我第一个反应是把这个字段名字改一下,毕竟能简单解决就简单解决嘛,结果当然是啪啪啪打脸。
这个名字我不管是换成 aaa 还是 bbb ,再次扫描都还会报同样的问题,唯一不同的地方就是安全报告上的字段名换一换。
这个就有意思了,这个问题是来者不善啊,经过我一翻查找(别问我怎么查的,问就是瞎猜的),找到原因的所在了。
因为我们这个系统是一个内部系统,当时做登录这个人比较图懒,就在页面上简单的做了个 form 表单提交,就比如这样:
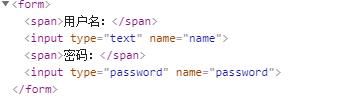
这个代码我曾经在大学的大作业上这么写过,没想到时隔多年我竟然又见到了这样的代码,竟然让我有一种老乡见老乡的特殊情感。
这个问题具体的原因是 AppScan 是直接检测页面上 type=‘password’ 的输入框,然后再检查请求中是否有对应的字段,别问我咋知道的,因为我干过把这里改成 type=‘text’ 就不报错了,唯一的缺点就是页面上的密码框将会明码显示密码。
虽然我可以通过 js 来把输入框里的值动态的替换成任何我想要的样子,比如点啊、星号啊以及一些其他的样式,但是这么干总归有点不道德。
问题找到了,那么怎么改呢?
到这里就涉及到了我今天要聊的内容了,如何保障 API 接口的安全性?
首先这个问题我们分成两个部分来看,客户端和服务端。
服务端
因为我本身是做服务端开发的,这个问题当然要从服务端聊起。
个人觉得安全措施主要体现在两个方面,一个是如何保证数据在传输过程中的安全性,另一个是如何在数据已经到达服务端后,服务端如何识别数据,保证不被攻击。
下面我们一条一条来聊:
1. HTTP 请求中的来源识别
HTTP 请求中的来源识别就是,服务端如何识别当前的请求是由自己的客户端发起的,而不是由第三方模拟的请求。
我们先看下一个正常的 HTTP 请求的头里面会有什么内容:

我打开百度的首页,通过 network 随便抓了一个请求,查看这个请求的请求头,这里面我要说的几个字段都用红框框起来了:
- Origin:用于指明当前请求来自于哪个站点。
- Referer:用于指明当前的请求是从哪个页面链接过来的
- User-Agent:用于标识当前的请求的浏览器或者系统的一些信息。
我们一般会对 HTTP 请求头中的 Origin 和 Referer 做白名单域名校验,先判断这个请求是不是由我们自己的域发出来的,然后再对 User-Agent 做一次校验,用来保证当前的请求是由浏览器发出来的,而不是由什么杂七杂八的模拟器发出来的。
当前,由于前端是完全不可被信任的,上面这几个字段都是可以被篡改和模拟的(我在前面写爬虫的文章中绝对写过),但是,能做的校验尽量做,我们不能一次把所有的漏洞都堵上,但是至少能堵上一部分。
2. 数据加密
数据在传输过程中是很容易被抓包的,如果直接传输比如通过 http 协议,那么用户传输的数据可以被任何人获取;所以必须对数据加密。
常见的做法对关键字段加密比如用户密码直接通过 md5 加密;现在主流的做法是使用 https 协议,在 http 和 tcp 之间添加一层加密层( SSL 层),这一层负责数据的加密和解密。
3. 数据签名
增加签名就是我们在发送 HTTP 请求的时候,增加一个无法伪造的字符串,用来保证数据在传输的过程中不被篡改。
数据签名使用比较多的算法是 MD5 算法,这个算法是将要提交的数据,通过某种方式组合成一个字符串,然后通过 MD5 算法生成一个签名。
我用前面那个登录的接口举个简单的例子:
srt:name={参数1}&password={参数2}&$key={用户密钥}
MD5.encrypt(str)
这里的 key 是一个密钥,由客户端和服务端各持有一份,最终登录请求要提交的 json 数据就会是下面这个样子:
{
"name": "test",
"password": "123",
"sign": "098f6bcd4621d373cade4e832627b4f6"
}
密钥是不参与数据提交,否则请求被劫持后,第三方就可以通过密钥自己生成签名,当然,如果觉得单纯的 MD5 不够安全的话,还可以在 MD5 的时候加盐和加 hash ,进一步降低请求被劫持后存在模拟的风险。
4. 时间戳
时间戳机制主要用来应对非法的 DDOS 攻击,我们的请求经过的加密和签名后,已经很难进行逆向破解了,但是有的攻击者他在抓包后,并不在意里面的具体数据,直接拿着抓的包进行攻击,这就是臭名昭著的 DDOS 攻击。
我们可以在参数中加上当前请求的时间戳,服务端拿到这个请求后会拿当前的时间和请求中的时间做比较,比如在 5 分钟之内的才会流转到后面的业务处理,在 5 分钟以外的直接返回错误码。
这里要注意的是客户端的时间和服务端的时间基本上是不可能一致的,加上请求本省在网络中传输还有耗时,所以时间限制的阀值不能设定的太小,防止合法的请求无法访问。
我还是拿上面的登录举例子,到这一步,我们的请求数据会变成下面这个样子:
{
"name": "test",
"password": "123",
"timestamp": 1590334946000,
"sign": "098f6bcd4621d373cade4e832627b4f6"
}
5. AppID
很多时候,我们一个 API 接口可能并不是只会有一个客户端进行调用,可能调用方会有非常多,我们的服务端为了验证合法的调用用户,可以添加一个 AppID 。
想要调用我们的 API 接口,必须通过线下的方式向我申请一个 AppID ,只有当这个 AppID 开通后,才能对我的接口进行合法的访问,在进行接口访问的时候,这个 AppID 需要添加到请求参数中,与其他数据一起提交。
到了这一步,我们上面那个登录接口的传入参数就变成了下面这样:
{
"appid": "geekdigging",
"name": "test",
"password": "123",
"timestamp": 1590334946,
"sign": "098f6bcd4621d373cade4e832627b4f6"
}
6. 参数整体加密
我们上面对请求的参数进行了一系列的处理,总体思想是防止第三方进行抓包和破解,但是如果我不是第三方呢,比如我就在浏览器的 network 中进行抓包,这个请求中的数据我就能看的清清楚楚明明白白,攻击者可以先通过正规的途径进行访问,当分析清楚我们的套路后再对请求进行伪造,开始攻击,这时我们前面的努力好像就都白费了。
不要说什么没有人会这么做,我就举一个例子,支付宝网页端的登录接口,如果能搞清楚其中请求的发送规则,攻击者就可以使用买来的用户数据库,进行批量撞库测试,通过请求响应的结果就可以验证一批的支付宝的账号密码(当然不会有这么简单哈,我只是举例子)。
我们接下来还能再对请求做一次整体加密,现在主流的加密方式有对称加密和不对称加密两种。
对称加密:对称密钥在加密和解密的过程中使用的密钥是相同的,常见的对称加密算法有 DES , AES , RC4 , Rabbit , TripleDes 等等。优点是计算速度快,缺点是在数据传送前,发送方和接收方必须商定好秘钥,然后使双方都能保存好秘钥,如果一方的秘钥被泄露,那么加密信息也就不安全了。
不对称加密:服务端会生成一对密钥,私钥存放在服务器端,公钥可以发布给任何人使用。优点就是比起对称加密更加安全,但是加解密的速度比对称加密慢太多了。广泛使用的是 RSA 算法。
对上面我们提交的数据做一次 DES 加密,密钥使用 123456 ,我们可以得到这样一个结果:
U2FsdGVkX18D+FiHsounFbttTFV8EToywxEHZcAEPkQpfwJqaMC5ssOZvf3JJQdB
/b6M/zSJdAwNg6Jr8NGUGuaSyJrJx7G4KXlGBaIXIbkTn2RT2GL4NPrd8oPJDCMk
y0yktsIWxVQP2hHbIckweEAdzRlcHvDn/0qa7zr0e1NfqY5IDDxWlSUKdwIbVC0o
mIaD/dpTBm0=
然后我们把这个字符串放到请求中进行请求,我们刚才的登录请求就会变成这样:
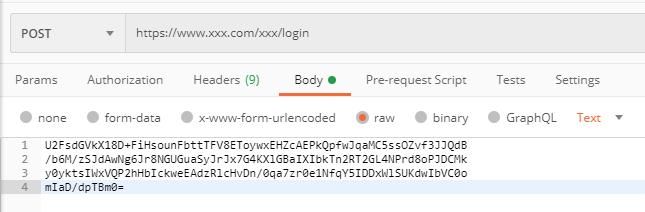
相信这样一来,超过 99% 的攻击者看到 network 中这样的抓包请求都会放弃,但是还剩下 1% 的人会打开 Chrome 提供的开发者工具进行一行一行的 debug ,针对这部分人,我们下面在客户端的段落里再聊如何对付他们。
7. 限流
很多时候,在某些并发比较高的场景下,基于对业务系统的保护,我们需要对请求访问速率进行限制,防止访问速率过高,把业务系统撑爆掉。
尤其是一些对外的接口,给客户或者供应商使用的接口,因为调用方我们自己无法控制,天知道对方的代码会怎么写。
我曾经见过供应商把我们提供的修改数据的接口拿来当做批量接口跑批,每天晚上都能把那个服务跑挂掉,后来直到我们去问,供应商他们才说每天晚上会用这个接口做上千万的数据同步,我也是醉了。
出于安全的角度考虑,在服务端做限流就显得十分有必要。
服务端限流的算法常见的有这么几种:令牌桶限流、漏桶限流、计数器限流。
令牌桶限流:令牌桶算法的原理是系统以一定速率向桶中放入令牌,填满了就丢弃令牌;请求来时会先从桶中取出令牌,如果能取到令牌,则可以继续完成请求,否则等待或者拒绝服务;令牌桶允许一定程度突发流量,只要有令牌就可以处理,支持一次拿多个令牌。
漏桶限流:漏桶算法的原理是按照固定常量速率流出请求,流入请求速率任意,当请求数超过桶的容量时,新的请求等待或者拒绝服务;可以看出漏桶算法可以强制限制数据的传输速度。
计数器限流:计数器是一种比较简单粗暴的算法,主要用来限制总并发数,比如数据库连接池、线程池、秒杀的并发数;计数器限流只要一定时间内的总请求数超过设定的阀值则进行限流。
实现方面来讲, Guava 提供了 RateLimiter 工具类是基于基于令牌桶算法,有需要的同学可以自己度娘一下。
8. 黑名单
黑名单机制已经有点风控的概念了,我们可以对非法操作进行定义。
比如记录每个 AppID 的访问频次,如果在 30 分钟内,发生了 5 次或者以上的超频访问并且超出了 10 倍以上的访问量,这时可以将这个 AppID 放入黑名单中, 24 小时以后或者调用方线下联系才能将这个 AppID 取出。
再比如记录 AppID 超时访问次数,正常来讲,超时访问不会频繁发生,如果在某个时间段内,大量的出现超时访问,这个 AppID 一定存在问题,也可以将其先放入黑名单中让它冷静冷静。
黑名单实际上更多的是应用在业务层面,比如大家可能碰到过的拼爹爹的风控,直接把账户扔到黑名单里面,禁止这个账户对某些补贴商品的下单。
客户端
在当今的互联网时代,网页和 APP 成为了主流的信息载体。
其中 APP 是可以使用一些加固技术对 APP 进行加固,防止别人进行暴力破解。
而网页就比较困难了,网页的动态都是依靠 JavaScript 来完成的,逻辑是依赖于 JavaScript 来实现的,而 JavaScript 又有下面的特点:
- JavaScript 代码运行于客户端,也就是它必须要在用户浏览器端加载并运行。
- JavaScript 代码是公开透明的,也就是说浏览器可以直接获取到正在运行的 JavaScript 的源码。
基于这两点,导致了 JavaScript 代码是不安全的,任何人都可以读取、分析、盗用、篡改 JavaScript 代码。
所以说, JavaScript 如果不进行一些处理,不管使用了如何高超的加解密方案,在被人找到其中的逻辑后,被模拟或者复制将变得在所难免。
前端 JavaScript 常见的加固方案有这么几种:压缩、混淆、加密 。
1. 压缩
代码压缩,就是去除 JavaScript 代码中不必要的空格、换行等内容,把一些可能公用的代码进行处理实现共享,最后输出的结果都压缩为一行或者几行内容,代码可读性变得很差,同时也能提高网站加载速度,就像下面这样:

这个是我从百度的页面上随便找了一个 js 截出来。
如果是单纯从去除空行空格这个角度上来对代码进行压缩,其实几乎是没有任何防护作用的,因为这种压缩方式仅仅是降低了代码的直接可读性。
我们可以通过各种工具对代码进行格式化,包括 Chrome 浏览器本身就提供了这个功能。
目前主流的前端技术都会使用 Webpack 进行打包,Webpack 会对源代码进行编译和压缩,输出几个打包好的 JavaScript 文件,其中我们可以看到输出的 JavaScript 文件名带有一些不规则字符串,同时文件内容可能只有几行内容,变量名都是一些简单字母表示。
这其中就包含 JavaScript 压缩技术,比如一些公共的库输出成 bundle 文件,一些调用逻辑压缩和转义成几行代码,这些都属于 JavaScript 压缩。另外其中也包含了一些很基础的 JavaScript 混淆技术,比如把变量名、方法名替换成一些简单字符,降低代码可读性。
整体上来讲, JavaScript 压缩术只能在很小的程度上起到防护作用,要想真正提高防护效果还得依靠 JavaScript 混淆和加密技术。
2. 混淆
JavaScript 混淆是完全是在 JavaScript 上面进行的处理,它的目的就是使得 JavaScript 变得难以阅读和分析,大大降低代码可读性,是一种很实用的 JavaScript 保护方案。
JavaScript 混淆器大致有两种:
- 通过正则替换实现的混淆器
- 通过语法树替换实现的混淆器
第一种实现成本低,但是效果也一般,适合对混淆要求不高的场景。第二种实现成本较高,但是更灵活,而且更安全,更适合对抗场景。
通过语法树替换实现的混淆器,这种混淆方式的实现有点复杂了,我这里就不展开去聊了,有兴趣的同学可以参考这篇文章:https://www.zhihu.com/question/47047191/answer/121013968 。
针对修改语法树进行混淆的方式,目前有一家做的比较好并且提供商业服务的是 jscrambler ,他们的官网地址:https://jscrambler.com/ 。
总之,以上方案都是 JavaScript 混淆的实现方式,可以在不同程度上保护 JavaScript 代码。
在一般的场景中,第一种混淆方式足够我们使用,现在 JavaScript 混淆主流的实现是 javascript-obfuscator 这个库,利用它我们可以非常方便地实现页面的混淆,它与 Webpack 结合起来,最终可以输出压缩和混淆后的 JavaScript 代码,使得可读性大大降低,难以逆向。
3. 加密
不同于 JavaScript 混淆技术,JavaScript 加密技术可以说是对 JavaScript 混淆技术防护的进一步升级,其基本思路是将一些核心逻辑使用诸如 C/C++ 语言来编写,并通过 JavaScript 调用执行,从而起到二进制级别的防护作用。
其加密的方式现在有 Emscripten 和 WebAssembly 等,其中后者越来越成为主流。
感兴趣的同学可以自行度娘了解下。
小结
上面介绍了这么多,只是为了我们的程序能够更加安全稳定的运行,减少因为攻击而产生的损失(加班)。