Git 分支( 二 )
3.6 Git 分支 - 变基
变基
在 Git 中整合来自不同分支的修改主要有两种方法:merge 以及 rebase。 在本节中我们将学习什么是“变基”,怎样使用“变基”,并将展示该操作的惊艳之处,以及指出在何种情况下你应避免使用它。
变基的基本操作
请回顾之前在 分支的合并 中的一个例子,你会看到开发任务分叉到两个不同分支,又各自提交了更新。
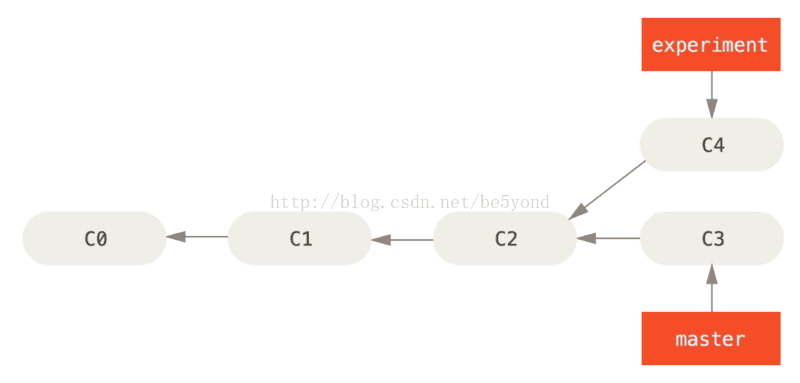
之前介绍过,整合分支最容易的方法是 merge 命令。 它会把两个分支的最新快照(C3 和 C4)以及二者最近的共同祖先(C2)进行三方合并,合并的结果是生成一个新的快照(并提交)。

其实,还有一种方法:你可以提取在 C4 中引入的补丁和修改,然后在 C3 的基础上应用一次。 在 Git 中,这种操作就叫做 变基。 你可以使用 rebase 命令将提交到某一分支上的所有修改都移至另一分支上,就好像“重新播放”一样。
在上面这个例子中,运行:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command
它的原理是首先找到这两个分支(即当前分支 experiment、变基操作的目标基底分支 master)的最近共同祖先 C2,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件,然后将当前分支指向目标基底 C3, 最后以此将之前另存为临时文件的修改依序应用。(译注:写明了 commit id,以便理解,下同)

C4 中的修改变基到 C3 上
现在回到 master 分支,进行一次快进合并。
$ git checkout master
$ git merge experiment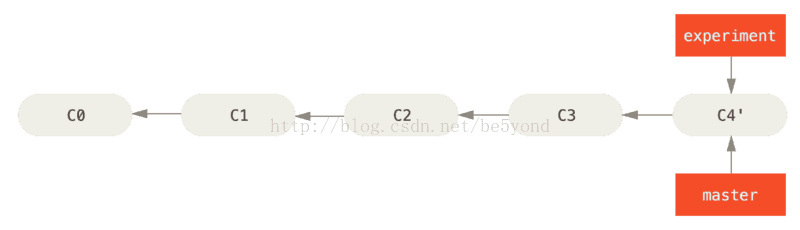
此时,C4' 指向的快照就和上面使用 merge 命令的例子中 C5 指向的快照一模一样了。 这两种整合方法的最终结果没有任何区别,但是变基使得提交历史更加整洁。 你在查看一个经过变基的分支的历史记录时会发现,尽管实际的开发工作是并行的,但它们看上去就像是串行的一样,提交历史是一条直线没有分叉。
一般我们这样做的目的是为了确保在向远程分支推送时能保持提交历史的整洁——例如向某个其他人维护的项目贡献代码时。 在这种情况下,你首先在自己的分支里进行开发,当开发完成时你需要先将你的代码变基到 origin/master 上,然后再向主项目提交修改。 这样的话,该项目的维护者就不再需要进行整合工作,只需要快进合并便可。
请注意,无论是通过变基,还是通过三方合并,整合的最终结果所指向的快照始终是一样的,只不过提交历史不同罢了。 变基是将一系列提交按照原有次序依次应用到另一分支上,而合并是把最终结果合在一起。
更有趣的变基例子
在对两个分支进行变基时,所生成的“重放”并不一定要在目标分支上应用,你也可以指定另外的一个分支进行应用。 就像 从一个特性分支里再分出一个特性分支的提交历史 中的例子那样。 你创建了一个特性分支 server,为服务端添加了一些功能,提交了 C3 和 C4。 然后从 C3 上创建了特性分支 client,为客户端添加了一些功能,提交了 C8 和 C9。 最后,你回到 server 分支,又提交了 C10。

假设你希望将 client 中的修改合并到主分支并发布,但暂时并不想合并 server 中的修改,因为它们还需要经过更全面的测试。 这时,你就可以使用 git rebase 命令的 --onto 选项,选中在 client 分支里但不在 server 分支里的修改(即 C8 和 C9),将它们在 master 分支上重放:
$ git rebase --onto master server client
以上命令的意思是:“取出 client 分支,找出处于 client 分支和 server 分支的共同祖先之后的修改,然后把它们在 master 分支上重放一遍”。 这理解起来有一点复杂,不过效果非常酷。

现在可以快进合并 master 分支了。(如图 快进合并 master 分支,使之包含来自 client 分支的修改):
$ git checkout master
$ git merge client
接下来你决定将 server 分支中的修改也整合进来。 使用 git rebase [basebranch] [topicbranch] 命令可以直接将特性分支(即本例中的 server)变基到目标分支(即 master)上。这样做能省去你先切换到 server 分支,再对其执行变基命令的多个步骤。
$ git rebase master server
如图 将 server 中的修改变基到 master 上 所示,server 中的代码被“续”到了 master 后面。

然后就可以快进合并主分支 master 了:
$ git checkout master
$ git merge server
至此,client 和 server 分支中的修改都已经整合到主分支里了,你可以删除这两个分支,最终提交历史会变成图 最终的提交历史 中的样子:
$ git branch -d client
$ git branch -d server
变基的风险
呃,奇妙的变基也并非完美无缺,要用它得遵守一条准则:
不要对在你的仓库外有副本的分支执行变基。
如果你遵循这条金科玉律,就不会出差错。 否则,人民群众会仇恨你,你的朋友和家人也会嘲笑你,唾弃你。
变基操作的实质是丢弃一些现有的提交,然后相应地新建一些内容一样但实际上不同的提交。 如果你已经将提交推送至某个仓库,而其他人也已经从该仓库拉取提交并进行了后续工作,此时,如果你用 git rebase 命令重新整理了提交并再次推送,你的同伴因此将不得不再次将他们手头的工作与你的提交进行整合,如果接下来你还要拉取并整合他们修改过的提交,事情就会变得一团糟。
让我们来看一个在公开的仓库上执行变基操作所带来的问题。 假设你从一个中央服务器克隆然后在它的基础上进行了一些开发。 你的提交历史如图所示:
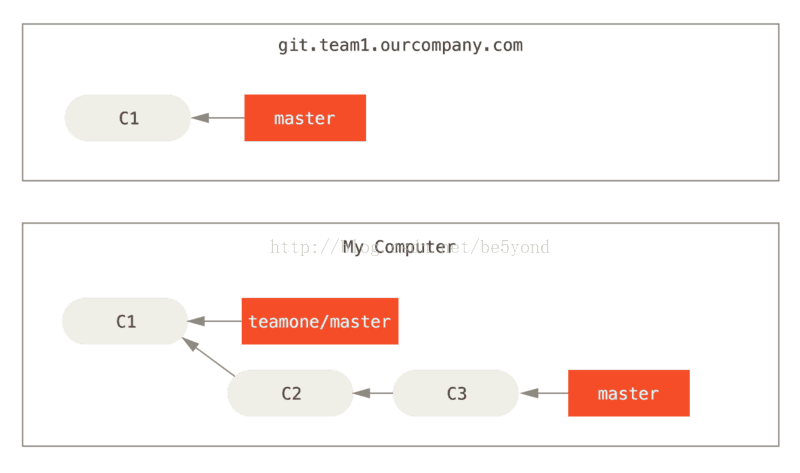
然后,某人又向中央服务器提交了一些修改,其中还包括一次合并。 你抓取了这些在远程分支上的修改,并将其合并到你本地的开发分支,然后你的提交历史就会变成这样:

接下来,这个人又决定把合并操作回滚,改用变基;继而又用 git push --force 命令覆盖了服务器上的提交历史。 之后你从服务器抓取更新,会发现多出来一些新的提交。
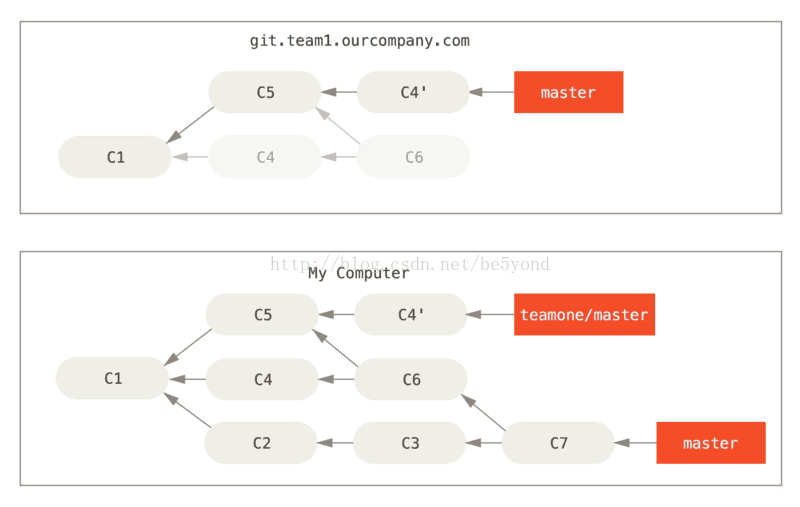
结果就是你们两人的处境都十分尴尬。 如果你执行 git pull 命令,你将合并来自两条提交历史的内容,生成一个新的合并提交,最终仓库会如图所示:
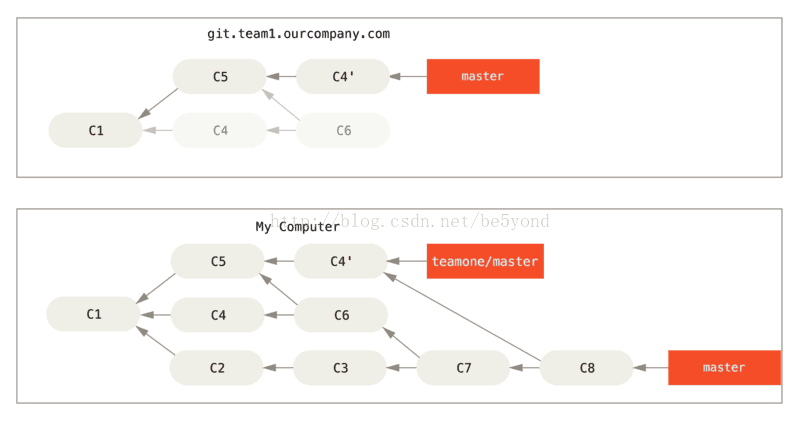
此时如果你执行 git log 命令,你会发现有两个提交的作者、日期、日志居然是一样的,这会令人感到混乱。 此外,如果你将这一堆又推送到服务器上,你实际上是将那些已经被变基抛弃的提交又找了回来,这会令人感到更加混乱。 很明显对方并不想在提交历史中看到 C4 和 C6,因为之前就是他把这两个提交通过变基丢弃的。
用变基解决变基
如果你 真的 遭遇了类似的处境,Git 还有一些高级魔法可以帮到你。 如果团队中的某人强制推送并覆盖了一些你所基于的提交,你需要做的就是检查你做了哪些修改,以及他们覆盖了哪些修改。
实际上,Git 除了对整个提交计算 SHA-1 校验和以外,也对本次提交所引入的修改计算了校验和—— 即 “patch-id”。
如果你拉取被覆盖过的更新并将你手头的工作基于此进行变基的话,一般情况下 Git 都能成功分辨出哪些是你的修改,并把它们应用到新分支上。
举个例子,如果遇到前面提到的 有人推送了经过变基的提交,并丢弃了你的本地开发所基于的一些提交 那种情境,如果我们不是执行合并,而是执行 git rebase teamone/master, Git 将会:
-
检查哪些提交是我们的分支上独有的(C2,C3,C4,C6,C7)
-
检查其中哪些提交不是合并操作的结果(C2,C3,C4)
-
检查哪些提交在对方覆盖更新时并没有被纳入目标分支(只有 C2 和 C3,因为 C4 其实就是 C4')
-
把查到的这些提交应用在
teamone/master上面
从而我们将得到与 你将相同的内容又合并了一次,生成了一个新的提交 中不同的结果,如图 在一个被变基然后强制推送的分支上再次执行变基 所示。

要想上述方案有效,还需要对方在变基时确保 C4' 和 C4 是几乎一样的。 否则变基操作将无法识别,并新建另一个类似 C4 的补丁(而这个补丁很可能无法整洁的整合入历史,因为补丁中的修改已经存在于某个地方了)。
在本例中另一种简单的方法是使用 git pull --rebase 命令而不是直接 git pull。 又或者你可以自己手动完成这个过程,先 git fetch,再 git rebase teamone/master。
如果你习惯使用 git pull ,同时又希望默认使用选项 --rebase,你可以执行这条语句 git config --global pull.rebase true 来更改 pull.rebase 的默认配置。
只要你把变基命令当作是在推送前清理提交使之整洁的工具,并且只在从未推送至共用仓库的提交上执行变基命令,就不会有事。 假如在那些已经被推送至共用仓库的提交上执行变基命令,并因此丢弃了一些别人的开发所基于的提交,那你就有大麻烦了,你的同事也会因此鄙视你。
如果你或你的同事在某些情形下决意要这么做,请一定要通知每个人执行 git pull --rebase 命令,这样尽管不能避免伤痛,但能有所缓解。
变基 vs. 合并
至此,你已在实战中学习了变基和合并的用法,你一定会想问,到底哪种方式更好。 在回答这个问题之前,让我们退后一步,想讨论一下提交历史到底意味着什么。
有一种观点认为,仓库的提交历史即是 记录实际发生过什么。 它是针对历史的文档,本身就有价值,不能乱改。 从这个角度看来,改变提交历史是一种亵渎,你使用_谎言_掩盖了实际发生过的事情。 如果由合并产生的提交历史是一团糟怎么办? 既然事实就是如此,那么这些痕迹就应该被保留下来,让后人能够查阅。
另一种观点则正好相反,他们认为提交历史是 项目过程中发生的事。 没人会出版一本书的第一版草稿,软件维护手册也是需要反复修订才能方便使用。 持这一观点的人会使用 rebase 及 filter-branch 等工具来编写故事,怎么方便后来的读者就怎么写。
现在,让我们回到之前的问题上来,到底合并还是变基好?希望你能明白,这并没有一个简单的答案。 Git 是一个非常强大的工具,它允许你对提交历史做许多事情,但每个团队、每个项目对此的需求并不相同。 既然你已经分别学习了两者的用法,相信你能够根据实际情况作出明智的选择。
3.7 Git 分支 - 总结
总结
4.1 服务器上的 Git - 协议
到目前为止,你应该已经有办法使用 Git 来完成日常工作。 然而,为了使用 Git 协作功能,你还需要有远程的 Git 仓库。 尽管在技术上你可以从个人仓库进行推送(push)和拉取(pull)来修改内容,但不鼓励使用这种方法,因为一不留心就很容易弄混其他人的进度。 此外,你希望你的合作者们即使在你的电脑未联机时亦能存取仓库 — 拥有一个更可靠的公用仓库十分有用。 因此,与他人合作的最佳方法即是建立一个你与合作者们都有权利访问,且可从那里推送和拉取资料的共用仓库。
架设一台 Git 服务器并不难。 首先,选择你希望服务器使用的通讯协议。 在本章第一节将介绍可用的协议以及各自优缺点。 下面一节将解释使用那些协议的典型设置及如何在你的服务器上运行。 最后,如果你不介意托管你的代码在其他人的服务器,且不想经历设置与维护自己服务器的麻烦,可以试试我们介绍的几个仓库托管服务。
如果你对架设自己的服务器没兴趣,可以跳到本章最后一节去看看如何申请一个代码托管服务的帐户然后继续下一章,我们会在那里讨论分散式源码控制环境的林林总总。
一个远程仓库通常只是一个裸仓库(bare repository)— 即一个没有当前工作目录的仓库。 因为该仓库仅仅作为合作媒介,不需要从磁碟检查快照;存放的只有 Git 的资料。 简单的说,裸仓库就是你工程目录内的 .git 子目录内容,不包含其他资料。
协议
Git 可以使用四种主要的协议来传输资料:本地协议(Local),HTTP 协议,SSH(Secure Shell)协议及 Git 协议。 在此,我们将会讨论那些协议及哪些情形应该使用(或避免使用)他们。
本地协议
最基本的就是 本地协议(Local protocol) ,其中的远程版本库就是硬盘内的另一个目录。 这常见于团队每一个成员都对一个共享的文件系统(例如一个挂载的 NFS)拥有访问权,或者比较少见的多人共用同一台电脑的情况。 后者并不理想,因为你的所有代码版本库如果长存于同一台电脑,更可能发生灾难性的损失。
如果你使用共享文件系统,就可以从本地版本库克隆(clone)、推送(push)以及拉取(pull)。 像这样去克隆一个版本库或者增加一个远程到现有的项目中,使用版本库路径作为 URL。 例如,克隆一个本地版本库,可以执行如下的命令:
$ git clone /opt/git/project.git
或你可以执行这个命令:
$ git clone file:///opt/git/project.git
如果在 URL 开头明确的指定 file://,那么 Git 的行为会略有不同。 如果仅是指定路径,Git 会尝试使用硬链接(hard link)或直接复制所需要的文件。 如果指定 file://,Git 会触发平时用于网路传输资料的进程,那通常是传输效率较低的方法。 指定 file:// 的主要目的是取得一个没有外部参考(extraneous references)或对象(object)的干净版本库副本– 通常是在从其他版本控制系统导入后或一些类似情况(参见 Git 内部原理 for maintenance tasks)需要这么做。 在此我们将使用普通路径,因为这样通常更快。
要增加一个本地版本库到现有的 Git 项目,可以执行如下的命令:
$ git remote add local_proj /opt/git/project.git
然后,就可以像在网络上一样从远端版本库推送和拉取更新了。
优点
基于文件系统的版本库的优点是简单,并且直接使用了现有的文件权限和网络访问权限。 如果你的团队已经有共享文件系统,建立版本库会十分容易。 只需要像设置其他共享目录一样,把一个裸版本库的副本放到大家都可以访问的路径,并设置好读/写的权限,就可以了, 我们会在 在服务器上搭建 Git 讨论如何导出一个裸版本库。
这也是快速从别人的工作目录中拉取更新的方法。 如果你和别人一起合作一个项目,他想让你从版本库中拉取更新时,运行类似 git pull /home/john/project 的命令比推送到服务再取回简单多了。
缺点
这种方法的缺点是,通常共享文件系统比较难配置,并且比起基本的网络连接访问,这不方便从多个位置访问。 如果你想从家里推送内容,必须先挂载一个远程磁盘,相比网络连接的访问方式,配置不方便,速度也慢。
值得一提的是,如果你使用的是类似于共享挂载的文件系统时,这个方法不一定是最快的。 访问本地版本库的速度与你访问数据的速度是一样的。 在同一个服务器上,如果允许 Git 访问本地硬盘,一般的通过 NFS 访问版本库要比通过 SSH 访问慢。
最终,这个协议并不保护仓库避免意外的损坏。 每一个用户都有“远程”目录的完整 shell 权限,没有方法可以阻止他们修改或删除 Git 内部文件和损坏仓库。
HTTP 协议
Git 通过 HTTP 通信有两种模式。 在 Git 1.6.6 版本之前只有一个方式可用,十分简单并且通常是只读模式的。 Git 1.6.6 版本引入了一种新的、更智能的协议,让 Git 可以像通过 SSH 那样智能的协商和传输数据。 之后几年,这个新的 HTTP 协议因为其简单、智能变的十分流行。 新版本的 HTTP 协议一般被称为“智能” HTTP 协议,旧版本的一般被称为“哑” HTTP 协议。 我们先了解一下新的“智能” HTTP 协议。
智能(Smart) HTTP 协议
“智能” HTTP 协议的运行方式和 SSH 及 Git 协议类似,只是运行在标准的 HTTP/S 端口上并且可以使用各种 HTTP 验证机制,这意味着使用起来会比 SSH 协议简单的多,比如可以使用 HTTP 协议的用户名/密码的基础授权,免去设置 SSH 公钥。
智能 HTTP 协议或许已经是最流行的使用 Git 的方式了,它即支持像 git:// 协议一样设置匿名服务,也可以像 SSH 协议一样提供传输时的授权和加密。 而且只用一个 URL 就可以都做到,省去了为不同的需求设置不同的 URL。 如果你要推送到一个需要授权的服务器上(一般来讲都需要),服务器会提示你输入用户名和密码。 从服务器获取数据时也一样。
事实上,类似 GitHub 的服务,你在网页上看到的 URL (比如, https://github.com/schacon/simplegit[]),和你在克隆、推送(如果你有权限)时使用的是一样的。
哑(Dumb) HTTP 协议
如果服务器没有提供智能 HTTP 协议的服务,Git 客户端会尝试使用更简单的“哑” HTTP 协议。 哑 HTTP 协议里 web 服务器仅把裸版本库当作普通文件来对待,提供文件服务。 哑 HTTP 协议的优美之处在于设置起来简单。 基本上,只需要把一个裸版本库放在 HTTP 根目录,设置一个叫做 post-update 的挂钩就可以了(见 Git 钩子)。 此时,只要能访问 web 服务器上你的版本库,就可以克隆你的版本库。 下面是设置从 HTTP 访问版本库的方法:
$ cd /var/www/htdocs/
$ git clone --bare /path/to/git_project gitproject.git
$ cd gitproject.git
$ mv hooks/post-update.sample hooks/post-update
$ chmod a+x hooks/post-update
这样就可以了。 Git 自带的 post-update 挂钩会默认执行合适的命令(git update-server-info),来确保通过 HTTP 的获取和克隆操作正常工作。 这条命令会在你通过 SSH 向版本库推送之后被执行;然后别人就可以通过类似下面的命令来克隆:
$ git clone https://example.com/gitproject.git
这里我们用了 Apache 里设置了常用的路径 /var/www/htdocs,不过你可以使用任何静态 web 服务器 —— 只需要把裸版本库放到正确的目录下就可以。 Git 的数据是以基本的静态文件形式提供的(详情见 Git 内部原理)。
通常的,会在可以提供读/写的智能 HTTP 服务和简单的只读的哑 HTTP 服务之间选一个。 极少会将二者混合提供服务。
优点
我们将只关注智能 HTTP 协议的优点。
不同的访问方式只需要一个 URL 以及服务器只在需要授权时提示输入授权信息,这两个简便性让终端用户使用 Git 变得非常简单。 相比 SSH 协议,可以使用用户名/密码授权是一个很大的优势,这样用户就不必须在使用 Git 之前先在本地生成 SSH 密钥对再把公钥上传到服务器。 对非资深的使用者,或者系统上缺少 SSH 相关程序的使用者,HTTP 协议的可用性是主要的优势。 与 SSH 协议类似,HTTP 协议也非常快和高效。
你也可以在 HTTPS 协议上提供只读版本库的服务,如此你在传输数据的时候就可以加密数据;或者,你甚至可以让客户端使用指定的 SSL 证书。
另一个好处是 HTTP/S 协议被广泛使用,一般的企业防火墙都会允许这些端口的数据通过。
缺点
在一些服务器上,架设 HTTP/S 协议的服务端会比 SSH 协议的棘手一些。 除了这一点,用其他协议提供 Git 服务与 “智能” HTTP 协议相比就几乎没有优势了。
如果你在 HTTP 上使用需授权的推送,管理凭证会比使用 SSH 密钥认证麻烦一些。 然而,你可以选择使用凭证存储工具,比如 OSX 的 Keychain 或者 Windows 的凭证管理器。 参考 凭证存储 如何安全地保存 HTTP 密码。
SSH 协议
架设 Git 服务器时常用 SSH 协议作为传输协议。 因为大多数环境下已经支持通过 SSH 访问 —— 即时没有也比较很容易架设。 SSH 协议也是一个验证授权的网络协议;并且,因为其普遍性,架设和使用都很容易。
通过 SSH 协议克隆版本库,你可以指定一个 ssh:// 的 URL:
$ git clone ssh://user@server/project.git
或者使用一个简短的 scp 式的写法:
$ git clone user@server:project.git
你也可以不指定用户,Git 会使用当前登录的用户名。
优势
用 SSH 协议的优势有很多。 首先,SSH 架设相对简单 —— SSH 守护进程很常见,多数管理员都有使用经验,并且多数操作系统都包含了它及相关的管理工具。 其次,通过 SSH 访问是安全的 —— 所有传输数据都要经过授权和加密。 最后,与 HTTP/S 协议、Git 协议及本地协议一样,SSH 协议很高效,在传输前也会尽量压缩数据。
缺点
SSH 协议的缺点在于你不能通过他实现匿名访问。 即便只要读取数据,使用者也要有通过 SSH 访问你的主机的权限,这使得 SSH 协议不利于开源的项目。 如果你只在公司网络使用,SSH 协议可能是你唯一要用到的协议。 如果你要同时提供匿名只读访问和 SSH 协议,那么你除了为自己推送架设 SSH 服务以外,还得架设一个可以让其他人访问的服务。
Git 协议
接下来是 Git 协议。 这是包含在 Git 里的一个特殊的守护进程;它监听在一个特定的端口(9418),类似于 SSH 服务,但是访问无需任何授权。 要让版本库支持 Git 协议,需要先创建一个 git-daemon-export-ok 文件 —— 它是 Git 协议守护进程为这个版本库提供服务的必要条件 —— 但是除此之外没有任何安全措施。 要么谁都可以克隆这个版本库,要么谁也不能。 这意味着,通常不能通过 Git 协议推送。 由于没有授权机制,一旦你开放推送操作,意味着网络上知道这个项目 URL 的人都可以向项目推送数据。 不用说,极少会有人这么做。
优点
目前,Git 协议是 Git 使用的网络传输协议里最快的。 如果你的项目有很大的访问量,或者你的项目很庞大并且不需要为写进行用户授权,架设 Git 守护进程来提供服务是不错的选择。 它使用与 SSH 相同的数据传输机制,但是省去了加密和授权的开销。
缺点
git:// 访问只有读权限。 Git 协议也许也是最难架设的。 它要求有自己的守护进程,这就要配置 xinetd 或者其他的程序,这些工作并不简单。 它还要求防火墙开放 9418 端口,但是企业防火墙一般不会开放这个非标准端口。 而大型的企业防火墙通常会封锁这个端口。
4.2 服务器上的 Git - 在服务器上搭建 Git
在服务器上搭建 Git
现在我们将讨论如何在你自己的服务器上搭建 Git 服务来运行这些协议。
|
Note
|
这里我们将要演示在 Linux 服务器上进行一次基本且简化的安装所需的命令与步骤,当然在 Mac 或 Windows 服务器上同样可以运行这些服务。 事实上,在你的计算机基础架构中建立一个生产环境服务器,将不可避免的使用到不同的安全措施与操作系统工具。但是,希望你能从本节中获得一些必要的知识。 |
在开始架设 Git 服务器前,需要把现有仓库导出为裸仓库——即一个不包含当前工作目录的仓库。 这通常是很简单的。 为了通过克隆你的仓库来创建一个新的裸仓库,你需要在克隆命令后加上 `--bare`选项 按照惯例,裸仓库目录名以 .git 结尾,就像这样:
$ git clone --bare my_project my_project.git
Cloning into bare repository 'my_project.git'...
done.
现在,你的 my_project.git 目录中应该有 Git 目录的副本了。
整体上效果大致相当于
$ cp -Rf my_project/.git my_project.git
虽然在配置文件中有若干不同,但是对于你的目的来说,这两种方式都是一样的。 它只取出 Git 仓库自身,不要工作目录,然后特别为它单独创建一个目录。
把裸仓库放到服务器上
既然你有了裸仓库的副本,剩下要做的就是把裸仓库放到服务器上并设置你的协议。 假设一个域名为 git.example.com 的服务器已经架设好,并可以通过 SSH 连接,你想把所有的 Git 仓库放在 /opt/git 目录下。 假设服务器上存在 /opt/git/ 目录,你可以通过以下命令复制你的裸仓库来创建一个新仓库:
$ scp -r my_project.git [email protected]:/opt/git
此时,其他通过 SSH 连接这台服务器并对 /opt/git 目录拥有可读权限的使用者,通过运行以下命令就可以克隆你的仓库。
$ git clone [email protected]:/opt/git/my_project.git
如果一个用户,通过使用 SSH 连接到一个服务器,并且其对 /opt/git/my_project.git 目录拥有可写权限,那么他将自动拥有推送权限。
如果到该项目目录中运行 git init 命令,并加上 --shared 选项,那么 Git 会自动修改该仓库目录的组权限为可写。
$ ssh [email protected]
$ cd /opt/git/my_project.git
$ git init --bare --shared
由此可见,根据现有的 Git 仓库创建一个裸仓库,然后把它放上你和协作者都有 SSH 访问权的服务器是多么容易。 现在你们已经准备好在同一项目上展开合作了。
值得注意的是,这的确是架设一个几个人拥有连接权的 Git 服务的全部——只要在服务器上加入可以用 SSH 登录的帐号,然后把裸仓库放在大家都有读写权限的地方。 你已经准备好了一切,无需更多。
下面的几节中,你会了解如何扩展到更复杂的设定。 这些内容包含如何避免为每一个用户建立一个账户,给仓库添加公共读取权限,架设网页界面等等。 然而,请记住这一点,如果只是和几个人在一个私有项目上合作的话,仅仅 是一个 SSH 服务器和裸仓库就足够了。
小型安装
如果设备较少或者你只想在小型开发团队里尝试 Git ,那么一切都很简单。 架设 Git 服务最复杂的地方在于用户管理。 如果需要仓库对特定的用户可读,而给另一部分用户读写权限,那么访问和许可安排就会比较困难。
SSH 连接
如果你有一台所有开发者都可以用 SSH 连接的服务器,架设你的第一个仓库就十分简单了,因为你几乎什么都不用做(正如我们上一节所说的)。 如果你想在你的仓库上设置更复杂的访问控制权限,只要使用服务器操作系统的普通的文件系统权限就行了。
如果需要团队里的每个人都对仓库有写权限,又不能给每个人在服务器上建立账户,那么提供 SSH 连接就是唯一的选择了。 我们假设用来共享仓库的服务器已经安装了 SSH 服务,而且你通过它访问服务器。
有几个方法可以使你给团队每个成员提供访问权。 第一个就是给团队里的每个人创建账号,这种方法很直接但也很麻烦。 或许你不会想要为每个人运行一次 adduser 并且设置临时密码。
第二个办法是在主机上建立一个 git 账户,让每个需要写权限的人发送一个 SSH 公钥,然后将其加入 git 账户的 ~/.ssh/authorized_keys 文件。 这样一来,所有人都将通过 git 账户访问主机。 这一点也不会影响提交的数据——访问主机用的身份不会影响提交对象的提交者信息。
4.3 服务器上的 Git - 生成 SSH 公钥
生成 SSH 公钥
如前所述,许多 Git 服务器都使用 SSH 公钥进行认证。 为了向 Git 服务器提供 SSH 公钥,如果某系统用户尚未拥有密钥,必须事先为其生成一份。 这个过程在所有操作系统上都是相似的。 首先,你需要确认自己是否已经拥有密钥。 默认情况下,用户的 SSH 密钥存储在其 ~/.ssh 目录下。 进入该目录并列出其中内容,你便可以快速确认自己是否已拥有密钥:
$ cd ~/.ssh
$ ls
authorized_keys2 id_dsa known_hosts
config id_dsa.pub
我们需要寻找一对以 id_dsa 或 id_rsa 命名的文件,其中一个带有 .pub 扩展名。 .pub 文件是你的公钥,另一个则是私钥。 如果找不到这样的文件(或者根本没有 .ssh 目录),你可以通过运行 ssh-keygen 程序来创建它们。在 Linux/Mac 系统中,ssh-keygen 随 SSH 软件包提供;在 Windows 上,该程序包含于 MSysGit 软件包中。
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/schacon/.ssh/id_rsa):
Created directory '/home/schacon/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/schacon/.ssh/id_rsa.
Your public key has been saved in /home/schacon/.ssh/id_rsa.pub.
The key fingerprint is:
d0:82:24:8e:d7:f1:bb:9b:33:53:96:93:49:da:9b:e3 [email protected]
首先 ssh-keygen 会确认密钥的存储位置(默认是 .ssh/id_rsa),然后它会要求你输入两次密钥口令。如果你不想在使用密钥时输入口令,将其留空即可。
现在,进行了上述操作的用户需要将各自的公钥发送给任意一个 Git 服务器管理员(假设服务器正在使用基于公钥的 SSH 验证设置)。 他们所要做的就是复制各自的 .pub 文件内容,并将其通过邮件发送。 公钥看起来是这样的:
$ cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAklOUpkDHrfHY17SbrmTIpNLTGK9Tjom/BWDSU
GPl+nafzlHDTYW7hdI4yZ5ew18JH4JW9jbhUFrviQzM7xlELEVf4h9lFX5QVkbPppSwg0cda3
Pbv7kOdJ/MTyBlWXFCR+HAo3FXRitBqxiX1nKhXpHAZsMciLq8V6RjsNAQwdsdMFvSlVK/7XA
t3FaoJoAsncM1Q9x5+3V0Ww68/eIFmb1zuUFljQJKprrX88XypNDvjYNby6vw/Pb0rwert/En
mZ+AW4OZPnTPI89ZPmVMLuayrD2cE86Z/il8b+gw3r3+1nKatmIkjn2so1d01QraTlMqVSsbx
NrRFi9wrf+M7Q== [email protected]
4.4 服务器上的 Git - 配置服务器
配置服务器
我们来看看如何配置服务器端的 SSH 访问。 本例中,我们将使用 authorized_keys 方法来对用户进行认证。 同时我们假设你使用的操作系统是标准的 Linux 发行版,比如 Ubuntu。 首先,创建一个操作系统用户 git,并为其建立一个 .ssh 目录。
$ sudo adduser git
$ su git
$ cd
$ mkdir .ssh && chmod 700 .ssh
$ touch .ssh/authorized_keys && chmod 600 .ssh/authorized_keys
接着,我们需要为系统用户 git 的 authorized_keys 文件添加一些开发者 SSH 公钥。 假设我们已经获得了若干受信任的公钥,并将它们保存在临时文件中。 与前文类似,这些公钥看起来是这样的:
$ cat /tmp/id_rsa.john.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCB007n/ww+ouN4gSLKssMxXnBOvf9LGt4L
ojG6rs6hPB09j9R/T17/x4lhJA0F3FR1rP6kYBRsWj2aThGw6HXLm9/5zytK6Ztg3RPKK+4k
Yjh6541NYsnEAZuXz0jTTyAUfrtU3Z5E003C4oxOj6H0rfIF1kKI9MAQLMdpGW1GYEIgS9Ez
Sdfd8AcCIicTDWbqLAcU4UpkaX8KyGlLwsNuuGztobF8m72ALC/nLF6JLtPofwFBlgc+myiv
O7TCUSBdLQlgMVOFq1I2uPWQOkOWQAHukEOmfjy2jctxSDBQ220ymjaNsHT4kgtZg2AYYgPq
dAv8JggJICUvax2T9va5 gsg-keypair
将这些公钥加入系统用户 git 的 .ssh 目录下 authorized_keys 文件的末尾:
$ cat /tmp/id_rsa.john.pub >> ~/.ssh/authorized_keys
$ cat /tmp/id_rsa.josie.pub >> ~/.ssh/authorized_keys
$ cat /tmp/id_rsa.jessica.pub >> ~/.ssh/authorized_keys
现在我们来为开发者新建一个空仓库。可以借助带 --bare 选项的 git init 命令来做到这一点,该命令在初始化仓库时不会创建工作目录:
$ cd /opt/git
$ mkdir project.git
$ cd project.git
$ git init --bare
Initialized empty Git repository in /opt/git/project.git/
接着,John、Josie 或者 Jessica 中的任意一人可以将他们项目的最初版本推送到这个仓库中,他只需将此仓库设置为项目的远程仓库并向其推送分支。 请注意,每添加一个新项目,都需要有人登录服务器取得 shell,并创建一个裸仓库。 我们假定这个设置了 git 用户和 Git 仓库的服务器使用 gitserver 作为主机名。 同时,假设该服务器运行在内网,并且你已在 DNS 配置中将 gitserver 指向此服务器。那么我们可以运行如下命令(假定 myproject 是已有项目且其中已包含文件):
# on John's computer
$ cd myproject
$ git init
$ git add .
$ git commit -m 'initial commit'
$ git remote add origin git@gitserver:/opt/git/project.git
$ git push origin master
此时,其他开发者可以克隆此仓库,并推回各自的改动,步骤很简单:
$ git clone git@gitserver:/opt/git/project.git
$ cd project
$ vim README
$ git commit -am 'fix for the README file'
$ git push origin master
通过这种方法,你可以快速搭建一个具有读写权限、面向多个开发者的 Git 服务器。
需要注意的是,目前所有(获得授权的)开发者用户都能以系统用户 git 的身份登录服务器从而获得一个普通 shell。 如果你想对此加以限制,则需要修改 passwd 文件中(git 用户所对应)的 shell 值。
借助一个名为 git-shell 的受限 shell 工具,你可以方便地将用户 git 的活动限制在与 Git 相关的范围内。该工具随 Git 软件包一同提供。 如果将 git-shell 设置为用户 git 的登录 shell(login shell),那么用户 git 便不能获得此服务器的普通 shell 访问权限。 若要使用 git-shell,需要用它替换掉 bash 或 csh,使其成为系统用户的登录 shell。 为进行上述操作,首先你必须确保 git-shell 已存在于 /etc/shells 文件中:
$ cat /etc/shells # see if `git-shell` is already in there. If not...
$ which git-shell # make sure git-shell is installed on your system.
$ sudo vim /etc/shells # and add the path to git-shell from last command
现在你可以使用 chsh 命令修改任一系统用户的 shell:
$ sudo chsh git # and enter the path to git-shell, usually: /usr/bin/git-shell
这样,用户 git 就只能利用 SSH 连接对 Git 仓库进行推送和拉取操作,而不能登录机器并取得普通 shell。 如果试图登录,你会发现尝试被拒绝,像这样:
$ ssh git@gitserver
fatal: Interactive git shell is not enabled.
hint: ~/git-shell-commands should exist and have read and execute access.
Connection to gitserver closed.
git 用户的家目录下建立一个目录,来对 git-shell 命令进行一定程度的自定义。 比如,你可以限制掉某些本应被服务器接受的 Git 命令,或者对刚才的 SSH 拒绝登录信息进行自定义,这样,当有开发者用户以类似方式尝试登录时,便会看到你的信息。 要了解更多有关自定义 shell 的信息,请运行 git help shell。
4.5 服务器上的 Git - Git 守护进程
Git 守护进程
接下来我们将通过 “Git” 协议建立一个基于守护进程的仓库。 对于快速且无需授权的 Git 数据访问,这是一个理想之选。 请注意,因为其不包含授权服务,任何通过该协议管理的内容将在其网络上公开。
如果运行在防火墙之外的服务器上,它应该只对那些公开的只读项目服务。 如果运行在防火墙之内的服务器上,它可用于支撑大量参与人员或自动系统(用于持续集成或编译的主机)只读访问的项目,这样可以省去逐一配置 SSH 公钥的麻烦。
无论何时,该 Git 协议都是相对容易设定的。 通常,你只需要以守护进程的形式运行该命令:
git daemon --reuseaddr --base-path=/opt/git/ /opt/git/
--reuseaddr 允许服务器在无需等待旧连接超时的情况下重启,--base-path 选项允许用户在未完全指定路径的条件下克隆项目,结尾的路径将告诉 Git 守护进程从何处寻找仓库来导出。 如果有防火墙正在运行,你需要开放端口 9418 的通信权限。
你可以通过许多方式将该进程以守护进程的方式运行,这主要取决于你所使用的操作系统。 在一台 Ubuntu 机器上,你可以使用一份 Upstart 脚本。 因此,找到如下文件:
/etc/event.d/local-git-daemon
并添加下列脚本内容:
start on startup
stop on shutdown
exec /usr/bin/git daemon \
--user=git --group=git \
--reuseaddr \
--base-path=/opt/git/ \
/opt/git/
respawn
出于安全考虑,强烈建议使用一个对仓库拥有只读权限的用户身份来运行该守护进程 - 你可以创建一个新用户 git-ro 并且以该用户身份来运行守护进程。 为简便起见,我们将像 git-shell 一样,同样使用 git 用户来运行它。
当你重启机器时,你的 Git 守护进程将会自动启动,并且如果进程被意外结束它会自动重新运行。 为了在不重启的情况下直接运行,你可以运行以下命令:
initctl start local-git-daemon
在其他系统中,你可以使用 sysvinit 系统中的 xinetd 脚本,或者另外的方式来实现 - 只要你能够将其命令守护进程化并实现监控。
接下来,你需要告诉 Git 哪些仓库允许基于服务器的无授权访问。 你可以在每个仓库下创建一个名为 git-daemon-export-ok 的文件来实现。
$ cd /path/to/project.git
$ touch git-daemon-export-ok
4.6 服务器上的 Git - Smart HTTP
Smart HTTP
我们一般通过 SSH 进行授权访问,通过 git:// 进行无授权访问,但是还有一种协议可以同时实现以上两种方式的访问。 设置 Smart HTTP 一般只需要在服务器上启用一个 Git 自带的名为 git-http-backend 的 CGI 脚本。 该 CGI 脚本将会读取由 git fetch 或 git push 命令向 HTTP URL 发送的请求路径和头部信息,来判断该客户端是否支持 HTTP 通信(不低于 1.6.6 版本的客户端支持此特性)。 如果 CGI 发现该客户端支持智能(Smart)模式,它将会以智能模式与它进行通信,否则它将会回落到哑(Dumb)模式下(因此它可以对某些老的客户端实现向下兼容)。
在完成以上简单的安装步骤后, 我们将用 Apache 来作为 CGI 服务器。 如果你没有安装 Apache,你可以在 Linux 环境下执行如下或类似的命令来安装:
$ sudo apt-get install apache2 apache2-utils
$ a2enmod cgi alias env
该操作将会启用 mod_cgi, mod_alias, 和 mod_env 等 Apache 模块, 这些模块都是使该功能正常工作所必须的。
接下来我们要向 Apache 配置文件添加一些内容,来让 git-http-backend 作为 Web 服务器对 /git 路径请求的处理器。
SetEnv GIT_PROJECT_ROOT /opt/git
SetEnv GIT_HTTP_EXPORT_ALL
ScriptAlias /git/ /usr/lib/git-core/git-http-backend/
如果留空 GIT_HTTP_EXPORT_ALL 这个环境变量,Git 将只对无授权客户端提供带 git-daemon-export-ok 文件的版本库,就像 Git 守护进程一样。
接着你需要让 Apache 接受通过该路径的请求,添加如下的内容至 Apache 配置文件:
Options ExecCGI Indexes
Order allow,deny
Allow from all
Require all granted
最后,如果想实现写操作授权验证,使用如下的未授权屏蔽配置即可:
AuthType Basic
AuthName "Git Access"
AuthUserFile /opt/git/.htpasswd
Require valid-user
这需要你创建一个包含所有合法用户密码的 .htaccess 文件。 以下是一个添加 “schacon” 用户到此文件的例子:
$ htdigest -c /opt/git/.htpasswd "Git Access" schacon
git-http-backend 的 CGI。它被引用来处理协商通过 HTTP 发送和接收的数据。 它本身并不包含任何授权功能,但是授权功能可以在 Web 服务器层引用它时被轻松实
|
Note
|
欲了解更多的有关配置 Apache 授权访问的信息,请通过以下链接浏览 Apache 文档: http://httpd.apache.org/docs/current/howto/auth.html
|
4.7 服务器上的 Git - GitWeb
GitWeb
如果你对项目有读写权限或只读权限,你可能需要建立起一个基于网页的简易查看器。 Git 提供了一个叫做 GitWeb 的 CGI 脚本来做这项工作。
如果你想要查看 GitWeb 如何展示你的项目,并且在服务器上安装了轻量级网络服务器比如 lighttpd 或 webrick, Git 提供了一个命令来让你启动一个临时的服务器。 在 Linux 系统的电脑上,lighttpd 通常已经安装了,所以你只需要在项目目录里执行 git instaweb 命令即可。 如果你使用 Mac 系统, Mac OS X Leopard 系统已经预安装了 Ruby,所以 webrick 或许是你最好的选择。 如果不想使用 lighttpd 启动 instaweb 命令,你需要在执行时加入 --httpd 参数。
$ git instaweb --httpd=webrick
[2009-02-21 10:02:21] INFO WEBrick 1.3.1
[2009-02-21 10:02:21] INFO ruby 1.8.6 (2008-03-03) [universal-darwin9.0]
这个命令启动了一个监听 1234 端口的 HTTP 服务器,并且自动打开了浏览器。 这对你来说十分方便。 当你已经完成了工作并想关闭这个服务器,你可以执行同一个命令,并加上 --stop 选项:
$ git instaweb --httpd=webrick --stop
如果你现在想为你的团队或你托管的开源项目持续的运行这个页面,你需要通过普通的 Web 服务器来设置 CGI 脚本。 一些 Linux 发行版的软件库有 gitweb 包,可以通过 apt 或 yum 来安装,你可以先试试。 接下来我们来快速的了解一下如何手动安装 GitWeb。 首先,你需要获得 Git 的源代码,它包含了 GitWeb ,并可以生成自定义的 CGI 脚本:
$ git clone git://git.kernel.org/pub/scm/git/git.git
$ cd git/
$ make GITWEB_PROJECTROOT="/opt/git" prefix=/usr gitweb
SUBDIR gitweb
SUBDIR ../
make[2]: `GIT-VERSION-FILE' is up to date.
GEN gitweb.cgi
GEN static/gitweb.js
$ sudo cp -Rf gitweb /var/www/
需要注意的是,你需要在命令中指定 GITWEB_PROJECTROOT 变量来让程序知道你的 Git 版本库的位置。 现在,你需要在 Apache 中使用这个 CGI 脚本,你需要为此添加一个虚拟主机:
ServerName gitserver
DocumentRoot /var/www/gitweb
Options ExecCGI +FollowSymLinks +SymLinksIfOwnerMatch
AllowOverride All
order allow,deny
Allow from all
AddHandler cgi-script cgi
DirectoryIndex gitweb.cgi
http://gitserver/ 在线查看你的版本库。
4.8 服务器上的 Git - GitLab
GitLab
虽然 GitWeb 相当简单。 但如果你正在寻找一个更现代,功能更全的 Git 服务器,这里有几个开源的解决方案可供你选择安装。 因为 GitLab 是其中最出名的一个,我们将它作为示例并讨论它的安装和使用。 这比 GitWeb 要复杂的多并且需要更多的维护,但它的确是一个功能更全的选择。
安装
GitLab 是一个数据库支持的 web 应用,所以相比于其他 git 服务器,它的安装过程涉及到更多的东西。 幸运的是,这个过程有非常详细的文档说明和支持。
这里有一些可参考的方法帮你安装 GitLab 。 为了更快速的启动和运行,你可以下载虚拟机镜像或者在 https://bitnami.com/stack/gitlab 上获取一键安装包,同时调整配置使之符合你特定的环境。 Bitnami 的一个优点在于它的登录界面(通过 alt-&rarr 键进入;);它会告诉你安装好的 GitLab 的 IP 地址以及默认的用户名和密码。

无论如何,跟着 GitLab 社区版的 readme 文件一步步来,你可以在这里找到它 https://gitlab.com/gitlab-org/gitlab-ce/tree/master 。 在这里你将会在主菜单中找到安装 GitLab 的帮助,一个可以在 Digital Ocean 上运行的虚拟机,以及 RPM 和 DEB 包(都是测试版)。 这里还有 “非官方” 的引导让 GitLab 运行在非标准的操作系统和数据库上,一个全手动的安装脚本,以及许多其他的话题。
管理
GitLab 的管理界面是通过网络进入的。 将你的浏览器转到已经安装 GitLab 的 主机名或 IP 地址,然后以管理员身份登录即可。 默认的用户名是 [email protected],默认的密码是 5iveL!fe(你会得到类似 请登录后尽快更换密码 的提示)。 登录后,点击主栏上方靠右位置的 “Admin area” 图标进行管理。

使用者
GitLab 上的用户指的是对应协作者的帐号。 用户帐号没有很多复杂的地方,主要是包含登录数据的用户信息集合。 每一个用户账号都有一个 命名空间 ,即该用户项目的逻辑集合。 如果一个叫 jane 的用户拥有一个名称是 project 的项目,那么这个项目的 url 会是 http://server/jane/project 。

移除一个用户有两种方法。 “屏蔽(Blocking)” 一个用户阻止他登录 GitLab 实例,但是该用户命名空间下的所有数据仍然会被保存,并且仍可以通过该用户提交对应的登录邮箱链接回他的个人信息页。
而另一方面,“销毁(Destroying)” 一个用户,会彻底的将他从数据库和文件系统中移除。 他命名空间下的所有项目和数据都会被删除,拥有的任何组也会被移除。 这显然是一个更永久且更具破坏力的行为,所以很少用到这种方法。
组
一个 GitLab 的组是一些项目的集合,连同关于多少用户可以访问这些项目的数据。 每一个组都有一个项目命名空间(与用户一样),所以如果一个叫 training 的组拥有一个名称是 materials 的项目,那么这个项目的 url 会是 http://server/training/materials 。
每一个组都有许多用户与之关联,每一个用户对组中的项目以及组本身的权限都有级别区分。 权限的范围从 “访客”(仅能提问题和讨论) 到 “拥有者”(完全控制组、成员和项目)。 权限的种类太多以至于难以在这里一一列举,不过在 GitLab 的管理界面上有帮助链接。
项目
一个 GitLab 的项目相当于 git 的版本库。 每一个项目都属于一个用户或者一个组的单个命名空间。 如果这个项目属于一个用户,那么这个拥有者对所有可以获取这个项目的人拥有直接管理权;如果这个项目属于一个组,那么该组中用户级别的权限也会起作用。
每一个项目都有一个可视级别,控制着谁可以看到这个项目页面和仓库。 如果一个项目是 私有 的,这个项目的拥有者必须明确授权从而使特定的用户可以访问。 一个 内部 的项目可以被所有登录的人看到,而一个 公开 的项目则是对所有人可见的。 注意,这种控制既包括 git “fetch” 的使用也包括对项目 web 用户界面的访问。
钩子
GitLab 在项目和系统级别上都支持钩子程序。 对任意级别,当有相关事件发生时,GitLab 的服务器会执行一个包含描述性 JSON 数据的 HTTP 请求。 这是自动化连接你的 git 版本库和 GitLab 实例到其他的开发工具,比如 CI 服务器,聊天室,或者部署工具的一个极好方法。
基本用途
你想要在 GitLab 做的第一件事就是建立一个新项目。 这通过点击工具栏上的 “+” 图标完成。 你会被要求填写项目名称,也就是这个项目所属的命名空间,以及它的可视层级。 绝大多数的设定并不是永久的,可以通过设置界面重新调整。 点击 “Create Project”,你就完成了。
项目存在后,你可能会想将它与本地的 Git 版本库连接。 每一个项目都可以通过 HTTPS 或者 SSH 连接,任意两者都可以被用来配置远程 Git。 在项目主页的顶栏可以看到这个项目的 URLs。 对于一个存在的本地版本库,这个命令将会向主机位置添加一个叫 gitlab 的远程仓库:
$ git remote add gitlab https://server/namespace/project.git
如果你的本地没有版本库的副本,你可以这样做:
$ git clone https://server/namespace/project.git
web 用户界面提供了几个有用的获取版本库信息的网页。 每一个项目的主页都显示了最近的活动,并且通过顶部的链接可以使你浏览项目文件以及提交日志。
一起工作
在一个 GitLab 项目上一起工作的最简单方法就是赋予协作者对 git 版本库的直接 push 权限。 你可以通过项目设定的 “Members(成员)” 部分向一个项目添加写作者,并且将这个新的协作者与一个访问级别关联(不同的访问级别在 组 中已简单讨论)。 通过赋予一个协作者 “Developer(开发者)” 或者更高的访问级别,这个用户就可以毫无约束地直接向版本库或者向分支进行提交。
另外一个让合作更解耦的方法就是使用合并请求。 它的优点在于让任何能够看到这个项目的协作者在被管控的情况下对这个项目作出贡献。 可以直接访问的协作者能够简单的创建一个分支,向这个分支进行提交,也可以开启一个向 master 或者其他任何一个分支的合并请求。 对版本库没有推送权限的协作者则可以 “fork” 这个版本库(即创建属于自己的这个库的副本),向 那个 副本进行提交,然后从那个副本开启一个到主项目的合并请求。 这个模型使得项目拥有者完全控制着向版本库的提交,以及什么时候允许加入陌生协作者的贡献。
在 GitLab 中合并请求和问题是一个长久讨论的主要部分。 每一个合并请求都允许在提出改变的行进行讨论(它支持一个轻量级的代码审查),也允许对一个总体性话题进行讨论。 两者都可以被分配给用户,或者组织到 milestones(里程碑) 界面。
4.9 服务器上的 Git - 第三方托管的选择
第三方托管的选择
如果不想设立自己的 Git 服务器,你可以选择将你的 Git 项目托管到一个外部专业的托管网站。 这带来了一些好处:一个托管网站可以用来快速建立并开始项目,且无需进行服务器维护和监控工作。 即使你在内部设立并且运行了自己的服务器,你仍然可以把你的开源代码托管在公共托管网站 - 这通常更有助于开源社区来发现和帮助你。
现在,有非常多的托管供你选择,每个选择都有不同的优缺点。 欲查看最新列表,请浏览 Git 维基的 GitHosting 页面 https://git.wiki.kernel.org/index.php/GitHosting
4.10 服务器上的 Git - 总结
总结
你有多种远程存取 Git 仓库的选择便于与其他人合作或是分享你的工作。