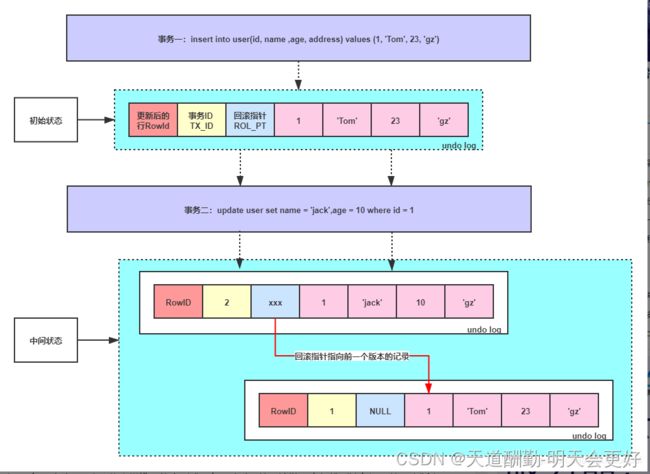
Mysql undo log
一、基本概念
undo log有两个作用:1.为事务提供回滚; 2.多版本并发控制(MVCC)
undo log和redo log记录物理日志不一样,它是逻辑日志,可以认为:当delete操作时,undo log记录的是insert记录,反之亦然,update操作时,记录的是相反的update记录。
二、undo log怎么产生的
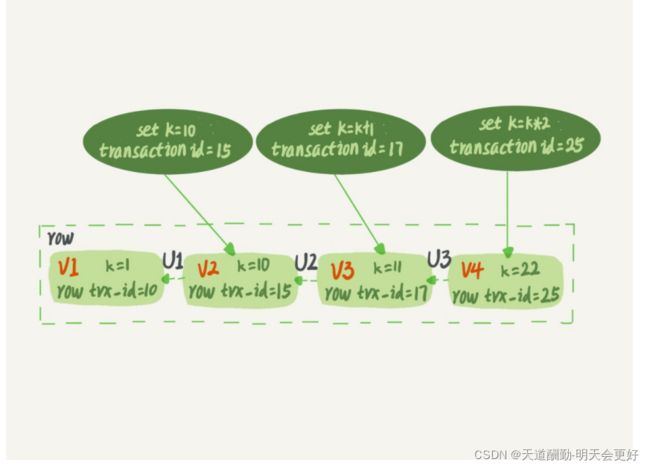
上面的行是最开始 k = 1;
1、 事务id = 15, 执行set k = 10; 则行记录里面的row_trx_id = 15
2、事务id = 17, 执行set k = k + 1; 则行记录里面的row_trx_id = 17
3、事务id = 25, 执行set k = k * 2; 则行记录里面的row_trx_id = 25
我们的undo log在哪里了?图中画的 U1 U2 U3 表示的就是undo log, 这里的V1 V2 V3里面的k并不是真实的值,都是可以用当前值和undo log计算来的。比如,需要V2的时候,就是通过V4依次执行U3、U2算出来。
row_trx_id是innodb存储引擎中,行记录中的系统列,每行数据都有的。
以前一直不明白undo log和mvcc、事务回滚什么关系,上面的图就很好的说明了。
三、undo的存储位置
当事务对记录进行增删改操作时,mysql就会生成1条或2条undo日志。
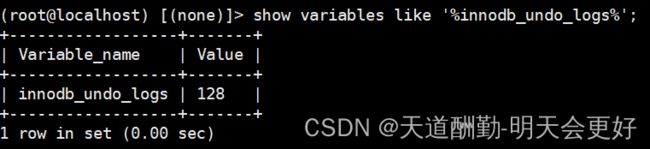
undo管理同表空间管理一样,都是通过segment来管理的,innodb有128个回滚段,可以通过innodb_undo_logs变量修改回滚段的个数。
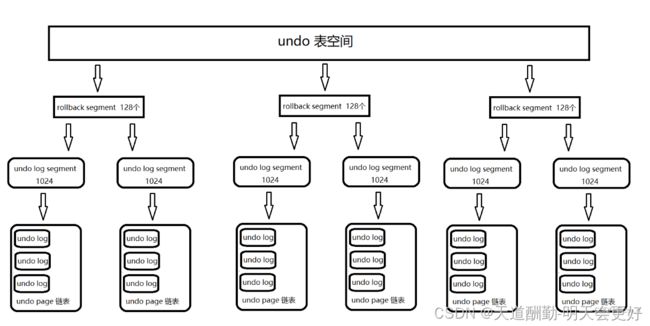
每个回滚段下面有1024个undo log segment, undo log segment存放的就是undo page链表
事务发起commit后不会立马删除undo log及undo log所在的页,这是因为还要支持MVCC技术,需要读取undo行记录的版本号。 是在commit发起后将undo log放入一个链表中(history list), 判断undo page使用空间是否小于3/4, 若是则undo page可以被重用,之后新的undo log在这个undo log后面,即一个undo page链表存放不同事务的undo log,以发挥undo page最大的使用率。
①将undo log放入列表中,不立马释放undo log,提供MVCC支持,待purge线程来进行回收
②purge线程从history list尾端开始判断undo log是否有事务持有可以释放重用,若可以,则进行purge回收,同时进入到undo purge队列里继续查找。
可以通过show engine innodb status\G查看 history list的长度, 每10s进行会删除history list中无用的undo page日志。
下面是备注,可以查看undo被purge线程清理的情况,idle是空闲的意思

undo log的物理存储
在5.6以前,Rollback Segment是在共享表空间里的,5.6以后存放自定义的目录中,需要在mysql最开始的设置。
四、undo log的相关参数
(root@localhost) [information_schema]> show variables like '%undo%';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 | undo空间最大大小 1G
| innodb_undo_directory | ./ | undo数据文件位置
| innodb_undo_log_truncate | OFF | undo是否加密
| innodb_undo_logs | 128 | 回滚段128个
+--------------------------+------------+
5 rows in set (0.00 sec)
五、 删除操作和history list
delete一条数据时首先将删除列的记录delete flag设置为1,该记录没有被实际删除在存在B+树中,索引上的信息也没有进行维护甚至没有产生undo log,这个真正的删除操作被“延时”,由purge线程来完成,以提供MVCC。
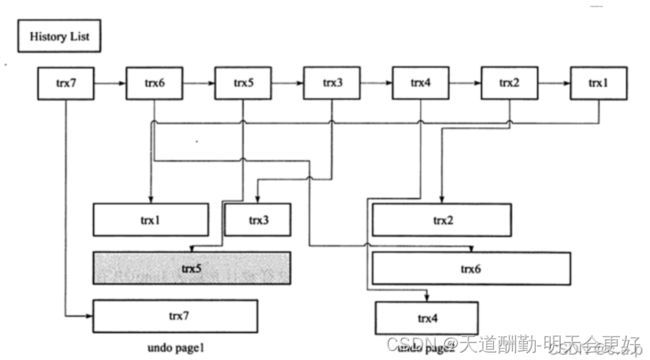
由于事务commit之后按照顺序将undo log放入history list中,如下图所示,trx*代表事务在undo中的记录即undo log,按照提交的先后顺序由history list管理,同时他们实际存放在undo page中,其中TRX5表示正在被事务引用,触发purge线程首先先从history list尾端进行遍历查找,即trx1那一段,首先回收的便是TRX1的undo log,接下来不是去查找TRX2,而是在trx1的undo page(undo page1)中继续向下查找,下一个要查找并回收的是trx3,接着找到trx5但是trx5被事务在占用,故再去history list中继续向前查找,刚才在history list中遍历到了trx1 ,接下来遍历trx2 ,找到并回收 ,同理查找undo page2中的trx6,接下来是trx4。
就以这样的逻辑顺序查找回收,每次回收300个page,通过上述方式可以发现purge实际上是一个离散读的过程,故实际过程中这个过程会很慢,同时也会消耗一定的IO,参数innodb_purge_batch_size可以设置每次purge的page数量。innodb_max_purge_lag控制history list的长度,默认为0(不做限制),purge速度和history list的长度是需要动态维持一定平衡的,purge的过多会造成IO压力,过少会造成history list过长,若长度达到innodb_max_purge_lag参数限制时,会“延缓”DML操作,其算法为delay=((length(history_list) - innodb_max_purge_lag * 10 )) - 5,delay单位是毫秒,但是delay代表的是一个dml操作的行,参数innodb_max_purge_lag_delay控制delay最大的毫秒数,避免purge缓慢造成SQL线程无限制等待。可见innodb_max_purge_lag=0不可随意更改。
六、undo log的存储机制
undo log的存储由InnoDB存储引擎实现,数据保存在InnoDB的数据文件中。在InnoDB存储引擎中,undo log是采用分段(segment)的方式进行存储的。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。在MySQL5.5之前,只支持1个rollback segment,也就是只能记录1024个undo操作。在MySQL5.5之后,可以支持128个rollback segment,分别从resg slot0 - resg slot127,每一个resg slot,也就是每一个回滚段,内部由1024个undo segment 组成,即总共可以记录128 * 1024个undo操作。
下面以一张图来说明undo log日志里面到底存了哪些信息?