undolog日志
文章目录
- `undolog` 日志
-
- 1. `undolog` 如何保障事务的原子性呢?
- 2. `MVCC`多版本并发控制
-
-
- 2.1 `MVCC`当前读和快照读
- 2.2 `MVCC` 的实现
-
- 2.2.1 三个隐式字段
- 2.2.2 `undolog` 日志
-
- 2.2.2.1 `undolog` 日志中的`updateUndolog`执行流程
- 2.2.3 `read-view`
-
- 2.2.3.1 `read-view` 中重要的属性
- 2.2.3.2 `read-view` 匹配条件规则
- 2.2.4 `MVCC`实现查询流程分析
-
- 3. 根据id查询为何会如此缓慢
undolog 日志
在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作(即回滚日志Undolog)。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。undolog日志保证事务的原子性,保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读;
记录的回滚操作,也称之为
回滚日志;所以在更新一条记录时,不仅会产生redolog,binlog日志,还会产生undolog日志;
从下面我们也可以看出,回滚日志是针对单条行记录而言的;
1. undolog 如何保障事务的原子性呢?
具体的方式为:在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为 undolog),然后进行数据的修改。如果出现了错误或者用户执行了 Rollback 语句,系统可以利用 undolog 中的备份将数据恢复到事务开始之前的状态。
2. MVCC多版本并发控制
MVCC(multi-version Concurrency control):多版本并发控制。同一条记录在系统中可以存在多个版本。主要是为了提高数据库的并发性能。做到有读写冲突时,也能不加锁,非阻塞并发读。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录。当前值是4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的
read-view。如图中看到的,在视图A、B、C里面,这一个记录的值分别是1、2、4。(值1,值2并不是物理上真实存在的,而是每次需要的时候通过当前版本和undolog日志计算出来的)

当事务提交之后,undolog并不能立马被删除,而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
undo log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert,执行一个update。undolog会记录一个相仿的update。
2.1 MVCC当前读和快照读
当前读: 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前的记录,会对读取的记录加锁(读取的是记录数据的最新版本,显式加锁的都是当前读)
select * from core_user where id > 2 for update;
select * from account where id>2 lock in share mode;
快照读: 不加锁的非阻塞读。快照读的前提是隔离级别不是串行界别。串行级别下的快照读会退化成当前读。快照读的实现是基于多版本并发控制,在很多的情况下,避免了加锁的操作。降低开销。但是读到的数据并不一定是当前的版本。而有可能是之前的版本。(普通的select语句都是快照读)
select * from core_user where id > 2;
2.2 MVCC 的实现
MVCC 通过三个隐式字段和undolog 日志,Read,View 共同实现的
2.2.1 三个隐式字段
DB_TRX_IDDB_ROLL_PTRDB_ROW_ID
DB_TRX_ID: 6byte,最近修改(修改/插入) 事务ID: 记录创建这条记录/修改这条记录的事务ID
DB_ROLL_PTR:7byte,回滚指针。指向这条记录的上一个版本
DB_ROW_ID:6byte,隐含的自增ID(隐藏主键),如果数据表没有主键,innodb会自动以DB_ROW_ID产生一个聚簇索引。
实际上还有一个删除flag隐藏字段,即记录被更新或删除并不代表真的删除,只是改变一下删除的flag
2.2.2 undolog 日志
undolog 日志可以区分为两种
insertundologupdateundolog
insertundolog: 代表事务在insert新数据时产生的undolog,只在事务回滚的时候需要。并且在事务提交后可以被立即丢弃
updateundolog: 事务在进行update或者delete时产生的undolog。不仅在事务回滚时需要,在快照读时也需要。所以不能随便删除,只有在事务回滚不涉及该日志时,才会被purge线程统一清理
为了实现
innodb的MVCC,更新和删除只是设置一下老记录的delete_bit,并不是真实的删除
2.2.2.1 undolog 日志中的updateUndolog执行流程
undolog实际上就是存在rollback segment中旧记录链,它的执行流程如下:
step1: 比如一个有个事务插入persion表插入了一条新记录,记录如下,name为Jerry, age为24岁,隐式主键是1,事务ID和回滚指针,我们假设为NULL

step2: 现在来了一个事务1对该记录的name做出了修改,改为Tom
在事务1修改该行(记录)数据时,数据库会先对该行加排他锁,然后把该行数据拷贝到undolog中,作为旧记录,既在undolog中有当前行的拷贝副本。拷贝完毕后,修改该行name为Tom,并且修改隐藏字段的事务ID为当前事务1的ID, 我们默认从1开始,之后递增,回滚指针指向拷贝到undo log的副本记录,既表示我的上一个版本就是它。

step3: 又来了个事务2修改person表的同一个记录,将age修改为30岁。在事务2修改该行数据时,数据库也先为该行加锁,然后把该行数据拷贝到undolog中,作为旧记录,发现该行记录已经有undolog了,那么最新的旧数据作为链表的表头,插在该行记录的undo log最前面。修改该行age为30岁,并且修改隐藏字段的事务ID为当前事务2的ID, 那就是2,回滚指针指向刚刚拷贝到undolog的副本记录。

总结: 从上面我们可以看出,不同事务或者相同的事务对同一记录的修改,会导致该记录的undolog成为一条记录版本线性表,即链表, undolog 的链表头部就是最新的旧纪录,链表尾部就是最早的旧纪录;
之前有提到,undolog 的节点,可能会被 purge 线程清理掉,像图中的第一条 insert Undolog 记录,其实在事务提交之后可能就被删除丢失了,这里依然存在,只是为了方便演示;
2.2.3 read-view
什么是read-view?
在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以最新的事务,ID值越大),快照读操作的时候生产的读视图(read-view)。
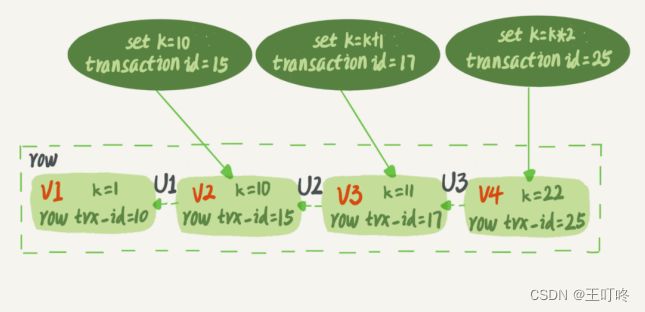
图中虚线框里是同一行数据的4个版本,当前最新版本是V4,k的值是22,它是被transaction为25的事务更新的,它的row_trx_id 为25。并且图中的三个虚线箭头,就是undolog。而V1,V2,V3并不是物理上真实存在的,而是每次需要的时候根据当前版本和undolog计算出来的。
快照的生成时机和事务的隔离级别是密切相关的。
读已提交的视图是在
sql语句执行的时刻产生的。可重复读的视图是在事务开始的时候产生的。
2.2.3.1 read-view 中重要的属性
m_ids:当前系统中那些活跃(未提交)的读写事务ID, 它数据结构为一个List。min_limit_id:表示在生成ReadView时,当前系统中活跃的读写事务中最小的事务id,即m_ids中的最小值。max_limit_id:表示生成ReadView时,系统中应该分配给下一个事务的id值。creator_trx_id: 创建当前read view的事务ID
2.2.3.2 read-view 匹配条件规则
- 数据事务ID
trx_id<min_limit_id,表明生成该版本的事务在生成Read View前,(因为事务ID是递增的),所以该版本可以被当前事务访问。 - 如果
trx_id>=max_limit_id,表明生成该版本的事务在生成Read View后才生成,所以该版本不可以被当前事务访问。 - 如果
min_limit_id=<trx_id<max_limit_id,则需3种情况讨论
(1)如果
m_ids包含trx_id,则代表Read View生成时刻,这个事务还未提交,但是如果数据的trx_id等于creator_trx_id的话,表明数据是自己生成的,因此是可见的。
(2)如果m_ids包含trx_id,并且trx_id不等于creator_trx_id,则Read-View生成时,事务未提交,并且不是自己生产的,所以当前事务也是看不见的;
(3)如果m_ids不包含trx_id,则说明你这个事务在Read View生成之前就已经提交了,修改的结果,当前事务是能看见的 (另类的trx_id<min_limit_id的情况?)。
2.2.4 MVCC实现查询流程分析
- 获取事务自身的版本号(
trx_id) - 获取
Read View - 将查询得到的数据和
Read View中的参数(事务版本号)做对比 - 符合
Read View的规则,直接返回 - 不符合
Read View的规则,通过undo log中的版本链,获取符合规则的数据 - 返回数据
3. 根据id查询为何会如此缓慢

通过上面的图片我们看到,第一个语句的查询结果里 c=1,带 lock in share mode 的语句返回的是 c=1000001。都是通过 id=1进行查询,为何查询所花费的时间相差如此的之大呢。按理说 lock in share mode 还要加锁,时间应该更长才对啊。接下来,我们通过一种场景解释这种情况造成的原因:
sessionA |
sessionB |
|---|---|
start transaction with consistent snapshot; |
|
update t set c =c+1 where id = 1; //执行100万次 |
|
select * from t where id =1 ; |
|
select * from t where id =1 lock in share mode; |
session A 先用 start transaction with consistent snapshot命令启动了一个事务,之后 session B 才开始执行 update 语句。
session B 执行完 100 万次 update 语句后,id=1 这一行处于什么状态呢?你可以从下图中找到答案

session B 更新完 100 万次,生成了 100 万个回滚日志 (undolog)。
带 lock in share mode 的 SQL 语句,是当前读,因此会直接读到 1000001 这个结果,所以速度很快;而 select * from t where id=1 这个语句,是一致性读,因此需要从 1000001 开始,依次执行 undolog,执行了 100 万次以后,才将 1 这个结果返回。
注意,
undolog里记录的其实是“把 2 改成 1”,“把 3 改成 2”这样的操作逻辑,画成减 1 的目的是方便看图。