阿里云服务器搭建hadoop(单机)
-
前期准备(centOS7的安装环境)
一、下载jdk1.8和hadoop(在windows下载)
1、下载jdk1.8
下载地址:
Java Archive Downloads - Java SE 8
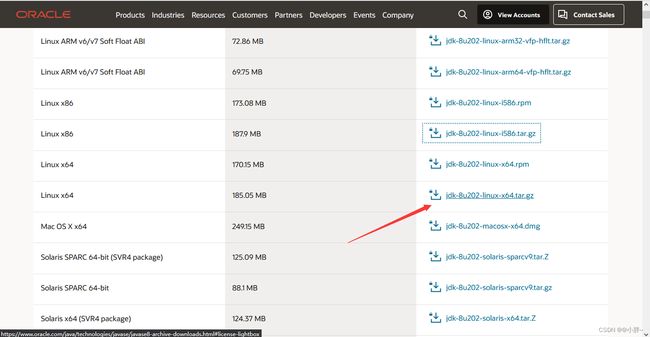
2、下载hadoop2.10.2
下载地址:(在浏览器直接打开这个地址就会进行下载、如果没有下载说明没有当前版本,返回上两级目录后,进入合适的版本进行下载)
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz
在服务器的根目录下创建一个存放jdk和hadoop的文件夹,方便后续配置
mkdir /apps
二、上传jdk和hadoop安装包到Linux虚拟机
1.下载FlashFXP(可以去下载其他的传输工具,目的就是为了把jdk和hadoop安装包上传到虚拟机)
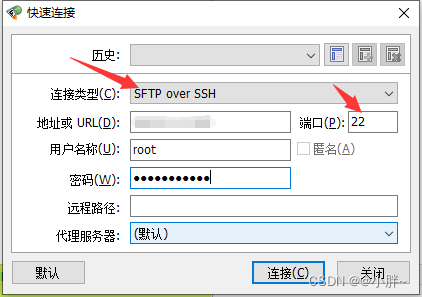
2.使用FlashFXP连接虚拟机(会话—快速连接—输入服务器公网IP、用户名、密码)
3.连接上以后,找到刚刚创建的文件夹,将jdk和hadoop安装包拖拽上传就好了
注:也可以直接在虚拟机上使用wget下载jdk和hadoop(wget 下载地址)
例:wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz
-
安装jdk和hadoop
安装jdk
1.解压jdk安装包至/apps目录下
cd /apps
tar -zxvf jdk-8u202-linux-x64.tar.gz2.重命名一下
mv jdk1.8.0_202/ /apps/java83、配置环境变量
echo 'export JAVA_HOME=/apps/java8' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile4、查看jdk是否安装成功:
java -version安装hadoop
1.解压hadoop安装包至/apps目录下
tar -zxvf hadoop-2.10.2.tar.gz配置hadoop
1. 修改Hadoop配置文件core-site.xml。
进入编辑页面。
vi /apps/hadoop-2.10.2/etc/hadoop/core-site.xml在
hadoop.tmp.dir
file:/apps/hadoop-2.10.2/tmp
location to store temporary files
fs.defaultFS
hdfs://localhost:9000
2. 修改Hadoop配置文件 hdfs-site.xml。
进入编辑页面。
vi /apps/hadoop-2.10.2/etc/hadoop/hdfs-site.xml 在
dfs.replication
1
dfs.namenode.name.dir
file:/apps/hadoop-2.10.2/tmp/dfs/name
dfs.datanode.data.dir
file:/apps/hadoop-2.10.2/tmp/dfs/data
3、修改配置文件yarn-env.sh 和 hadoop-env.sh
echo "export JAVA_HOME=/usr/java8" >>/apps/hadoop-2.10.2/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /apps/hadoop-2.10.2/etc/hadoop/hadoop-env.sh4.配置环境变量
echo 'export HADOOP_HOME=/apps/hadoop-2.10.2/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile 5、测试hadoop安装成功
hadoop version-
配置SSH免密登录(可以不配置)
1.创建公钥和私钥
ssh-keygen -t rsa
2.将公钥添加到authorized_keys文件中
cd ~
cd .ssh
cat id_rsa.pub >> authorized_keys-
启动hadoop
1. 初始化namenode 。
hadoop namenode -format2. 启动Hadoop(此操作会依次启动namenode和datanode,如果没有配置SSH免密登录,这里需要输入几次用户名和密码)。
start-dfs.sh3、启动yarn
start-yarn.sh启动成功后,jps查看启动的进程
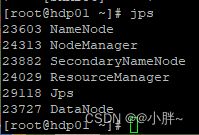
hadoop的基本操作
查看hadoop文件:hadoop fs -ls
上传文件到hadoop:hadoop fs -put ./(liunx的目录) (hadoop的目录)
删除hadoop上的文件:hadoop fs -rm -r /(文件路径)
从hadoop上下载文件:hadoop fs -get (hadoop路径) (下载到liunx机的路径)
在hadoop上创建一个文件夹:hadoop fs -mkdir (文件名) //无限递归创建在fs后加-t
移动hadoop上的文件:hadoop fs -mv 原路径 到达的目录
在hadoop上复制文件:hadoop fs -cp 原文件目录 复制到达的目录
在hadoop上查看文件:hadoop fs -cat 文件路径 或者 (查看部分)hadoop fs -tail -f 文件路径 | tail -5(5是查看的行数)
合并文件:cat 被切割成的文件名 >> 创建一个新文件名 // 合并时候被切割的文件名从大到小合并
列:cat blk_1073741825 >> jdk.tgz
cat blk_1073741826 >> jdk.tgz
-
停止全部进程
stop-all.sh