知识蒸馏:如何用一个神经网络训练另一个神经网络
作者:Tivadar Danka
编译:ronghuaiyang
来源:AI公园
导读
知识蒸馏的简单介绍,让大家了解知识蒸馏背后的直觉。
如果你曾经用神经网络来解决一个复杂的问题,你就会知道它们的尺寸可能非常巨大,包含数百万个参数。例如著名的BERT模型约有1亿1千万参数。
为了说明这一点,参见下图中的NLP中最常见架构的参数数量。

各种模型结构的参数数量
在Kaggle竞赛中,胜出的模型通常是由几个模型组成的集合。尽管它们在精确度上可以大大超过简单模型,但其巨大的计算成本使它们在实际应用中完全无法使用。
有没有什么方法可以在不扩展硬件的情况下利用这些强大但庞大的模型来训练最先进的模型?
目前,有三种方法可以压缩神经网络,同时保持预测性能:
权值裁剪
量化
知识蒸馏
在这篇文章中,我的目标是向你介绍“知识蒸馏”的基本原理,这是一个令人难以置信的令人兴奋的想法,它的基础是训练一个较小的网络来逼近大的网络。
什么是知识蒸馏?
让我们想象一个非常复杂的任务,比如对数千个类进行图像分类。通常,你不能指望ResNet50能达到99%的准确度。所以,你建立一个模型集合,平衡每个模型的缺陷。现在你有了一个巨大的模型,尽管它的性能非常出色,但无法将其部署到生产环境中,并在合理的时间内获得预测。
然而,该模型可以很好地概括未见的数据,因此可以放心地相信它的预测。(我知道,情况可能不是这样的,但我们现在就开始进行思维实验吧。)
如果我们使用来自大而笨重的模型的预测来训练一个更小的,所谓的“学生”模型来逼近大模型会怎么样?
这本质上就是知识的蒸馏,这是由Geoffrey Hinton、Oriol Vinyals和Jeff Dean在论文Distilling the Knowledge in a Neural Network中介绍的。
大致说来,过程如下:
训练一个能够性能很好泛化也很好的大模型。这被称为教师模型。
利用你所拥有的所有数据,计算出教师模型的预测。带有这些预测的全部数据集被称为知识,预测本身通常被称为soft targets。这是知识蒸馏步骤。
利用先前获得的知识来训练较小的网络,称为学生模型。
为了使过程可视化,见下图。
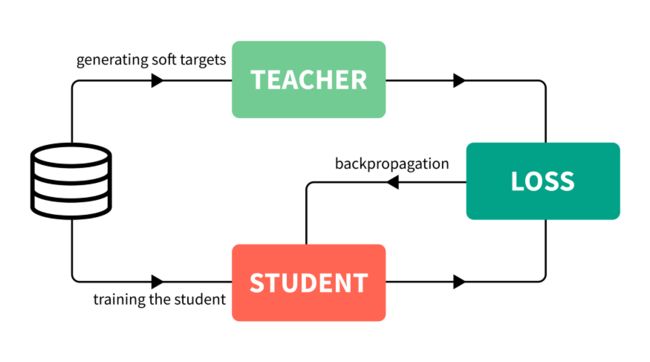
知识蒸馏
让我们关注一下细节。知识是如何获得的?
在分类器模型中,类的概率由softmax层给出,将logits转换为概率:

其中:

是最后一层生成的logits。替换一下,得到一个稍有修改的版本:

其中,T 是一个超参数,称为温度。这些值叫做soft targets。
如果 T 变大,类别概率会变软,也就是说会相互之间更加接近,极端情况下,T 趋向于无穷大。

如果 T = 1,就是原来的softmax函数。出于我们的目的,T 被设置为大于1,因此叫做蒸馏。
Hinton, Vinyals和Dean证明了一个经过蒸馏的模型可以像由10个大型模型的集成一样出色。

Geoffrey Hinton, Oriol Vinyals和Jeff Dean的论文Distilling the Knowledge in a Neural Network中对一个语音识别问题的知识蒸馏的结果
为什么不重头训练一个小网络?
你可能会问,为什么不从一开始就训练一个更小的网络呢?这不是更容易吗?当然,但这并不一定有效。
实验结果表明,参数越多,泛化效果越好,收敛速度越快。例如,Sanjeev Arora, Nadav Cohen和Elad Hazan在他们的论文“On the Optimization of Deep Networks: Implicit Acceleration by Overparameterization”中对此进行了研究。

左:单层网络与4层和8层的线性网络
右:使用TensorFlow教程中的MNIST分类的参数化和基线模型。
对于复杂的问题,简单的模型很难在给定的训练数据上很好地泛化。然而,我们拥有的远不止训练数据:教师模型对所有可用数据的预测。
这对我们有两方面的好处。
首先,教师模型的知识可以教学生模型如何通过训练数据集之外的可用预测进行泛化。回想一下,我们使用教师模型对所有可用数据的预测来训练学生模型,而不是原始的训练数据集。
其次,soft targets提供了比类标签更有用的信息:它表明两个类是否彼此相似。例如,如果任务是分类狗的品种,像“柴犬和秋田犬非常相似”这样的信息对于模型泛化是非常有价值的。

左:秋田犬,右:柴犬
与迁移学习的区别
Hinton等人也提到,最早的尝试是复用训练好的集成模型中的一些层来迁移知识,从而压缩模型。
用Hinton等人的话来说,
“……我们倾向于用学习的参数值在训练过的模型中识别知识,这使得我们很难看到如何改变模型的形式而保持相同的知识。知识的一个更抽象的观点是,它是一个从输入向量到输出向量的学习好的映射,它将知识从任何特定的实例化中解放出来。—— Distilling the Knowledge in a Neural Network
因此,与转移学习相反,知识蒸馏不会直接使用学到的权重。
使用决策树
如果你想进一步压缩模型,你可以尝试使用更简单的模型,如决策树。尽管它们的表达能力不如神经网络,但它们的预测可以通过单独观察节点来解释。
这是由Nicholas Frosst和Geoffrey Hinton完成的,他们在他们的论文Distilling a Neural Network Into a Soft Decision Tree中对此进行了研究。

他们的研究表明,尽管更简单的神经网络的表现比他们的研究要好,但蒸馏确实起到了一点作用。在MNIST数据集上,经过蒸馏的决策树模型的测试准确率达到96.76%,较基线模型的94.34%有所提高。然而,一个简单的两层深卷积网络仍然达到了99.21%的准确率。因此,在性能和可解释性之间存在权衡。
Distilling BERT
到目前为止,我们只看到了理论结果,没有实际的例子。为了改变这种情况,让我们考虑近年来最流行和最有用的模型之一:BERT。
来自于谷歌的Jacob Devlin等人的论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,很快被广泛应用于各种NLP任务,如文档检索或情绪分析。这是一个真正的突破,推动了几个领域的技术发展。
然而,有一个问题。BERT包含约1.1亿个参数,需要大量的时间来训练。作者报告说,训练需要4天,使用4个pods中的16个TPU芯片。训练成本将约为10000美元,不包括碳排放等环境成本。
Hugging Face成功地尝试减小BERT的尺寸和计算成本。他们使用知识蒸馏来训练DistilBERT,这是原始模型大小的60%,同时速度提高了60%,语言理解能力保持在97%。

DistilBERT的性能
较小的架构需要更少的时间和计算资源:在8个16GB V100 gpu上花费90小时。如果你对更多的细节感兴趣,你可以阅读原始论文"DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"或者文章的综述,写的很精彩,强烈推荐。
总结
知识蒸馏是压缩神经网络的三种主要方法之一,使其适合于性能较弱的硬件。
与其他两种强大的压缩方法权值剪枝和量化不同,知识蒸馏不直接对网络进行缩减。相反,它使用最初的模型来训练一个更小的模型,称为“学生模型”。由于教师模型甚至可以对未标记的数据提供预测,因此学生模型可以学习如何像教师那样进行泛化。在这里,我们看到了两个关键的结果:最初的论文,它介绍了这个想法,和一个后续的论文,展示了简单的模型,如决策树,也可以用作学生模型。
英文原文:https://towardsdatascience.com/can-a-neural-network-train-other-networks-cf371be516c6
欢迎加入Imagination GPU与人工智能交流群

群已满200人,入群请加小编拉进群,
小编微信号:eetrend89(添加请备注公司名和职称)
推荐阅读
Imagination 光线追踪专刊 | 业界首个移动端光线追踪GPU架构

END
Imagination Technologies是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech !
长按识别二维码
关注我们
