【MySQL】数据类型
目录
- 一、int相关类型
- 二、bit类型
- 三、浮点数类型
-
- 1.float
- 2.decimal
- 四、字符串类型
-
- 1.char
- 2.varchar
- 五、日期类型和时间类型
- 六、枚举和集合
-
- 1.枚举和集合
- 2.find_in_set
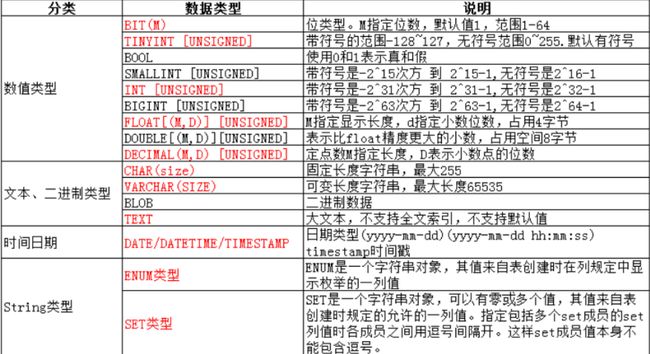
mysql中数据类型大致分为以下几类
一、int相关类型
| 类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| tinyint (无符号) | 1 | 0 | 255 |
| tinyint (有符号) | 1 | -128 | 127 |
| smallint (无符号) | 2 | 0 | 65535 |
| smallint (有符号) | 2 | -32768 | 32767 |
| mediumint (无符号) | 3 | 0 | 16777215 |
| mediumint (有符号) | 3 | 8388608 | 8388607 |
| int (无符号) | 4 | 0 | 4294967295 |
| bigint (有符号) | 4 | -0 | 2147483647 |
| int (无符号) | 4 | 0 | 18446744073709551615 |
| int (有符号) | 4 | -9223372036854775808 | 9223372036854775807 |
tinyint

MySQL中插入的数据不能越界。所以MySQL的数据类型本身也是一种约束。在选用数据类型的时候,按需选取。
如果要插入无符号类型的
create table if not exists t1( num tinyint unsigned );
二、bit类型
bit[(M)] :位字段类型。M表示有几位,范围从1到64位。如果M被忽略,默认为1。
因为设置的bit的大小为1,所以只有一个字节的大小,数值只能有0和1。
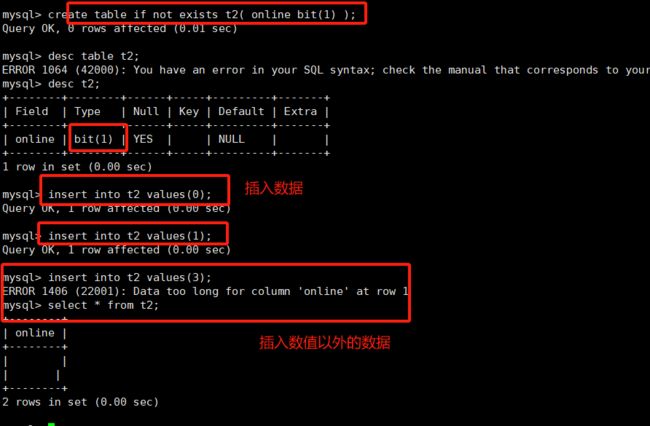
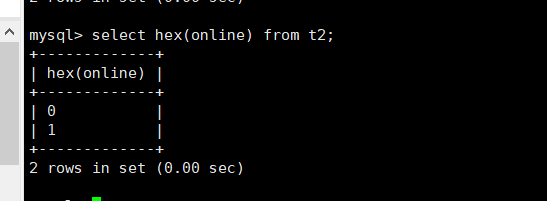
打印t2发现位类型并没有被显示,这是因为bit字段在显示时,是按照ASCII码对应的值显示。如果真想看到,可以使用十六进制打印。
三、浮点数类型
1.float
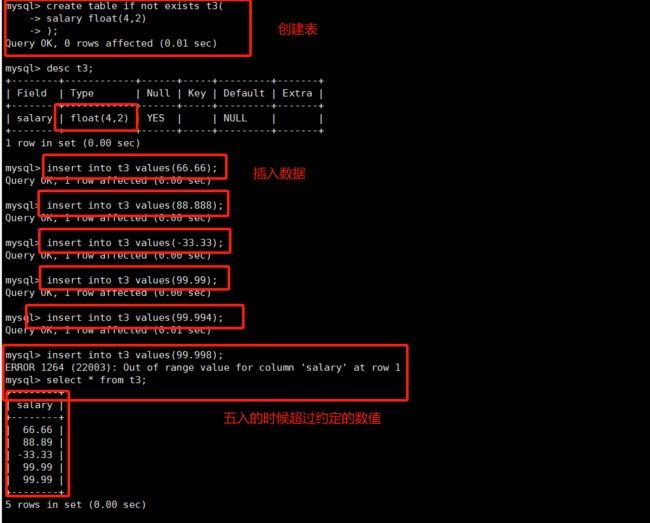
float[(m, d)] [unsigned] //M指定显示长度,d指定小数位数,占用空间4个字节
double同float使用
浮点数会存在精度的丢失。
float(4,2) 表示的范围是 -99.99 ~ 99.99float(4,2) unsigned 表示的范围 0 ~ 99.99
当用户小数个数给多了,将会四舍五入进行存储,但是如果五入超过可存储数值的最大范围,依然存储不了。float占用空间4个字节。
2.decimal
decimal(m, d) [unsigned] //定点数m指定长度,d表示小数点的位数
decimal(4,2) 表示的范围是 -99.99 ~ 99.99
decimal(4,2) unsigned 表示的范围 0 ~ 99.99
decimal和float很像,表示的数据范围一样,但是精度不一样:
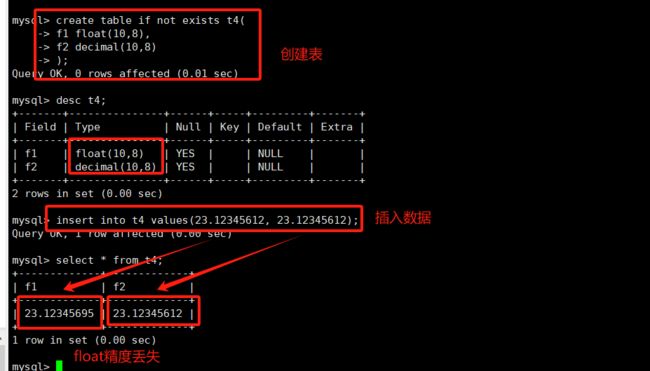
float表示的精度大约是7位。
decimal整数最大位数m为65。支持小数最大位数d是30。DECIMAL 类型占用的存储空间为 M+2 字节,其中 M
表示数字的精度。如果d被省略,默认为0.如果m被省略,默认是10。建议:如果希望小数的精度高,推荐使用decimal或double而不是float。
四、字符串类型
1.char
char(L) //固定长度字符串,L是可以存储的长度,单位为字符(注意是字符,不是字节),
//最大长度值可以为255
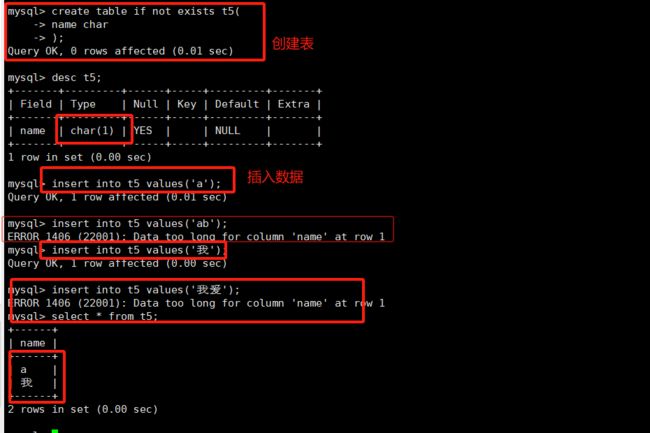
在UTF8编码格式中,虽然汉字占3个字节,但是在MySQL中,char是不看字节数的,只看字符的个数。所以这里无论是插入字符还是汉字,都是限制一个字符以内。
2.varchar
varchar(L)//可变长度字符串,L表示字符长度,最大长度65535个字节
//(注意这里是字节,而char那边是字符!例如utf8中,单字符是3字节,那么L的最大长度为21844字符!计算方式见下方:)
关于varchar(L),L到底是多大,这个len值,和表的编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3
个字节用于记录数据大小,所以说有效字节数是65532。(如果表中仅有一个varchar字段,有效字节数是65532,如果还有其他的字段,那么varchar的实际有效字节将会比65532低一点)当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符占用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符占用2字节)。
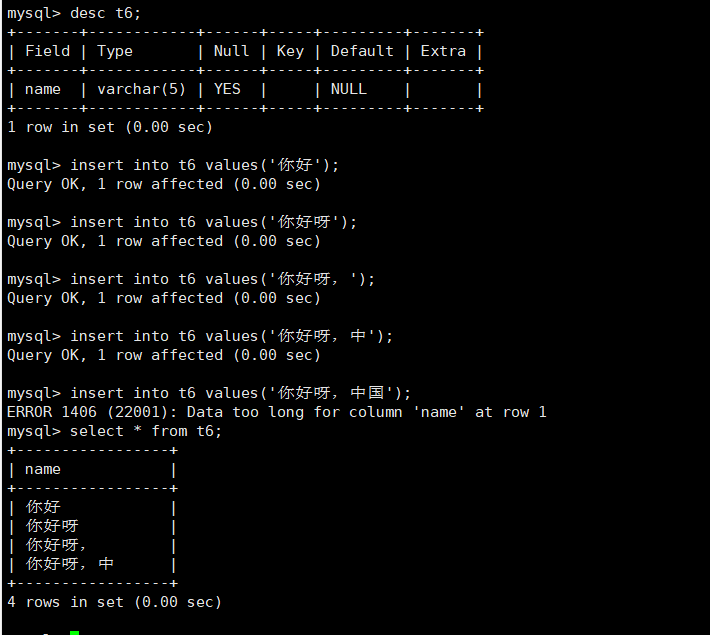
char 和 varchar的区别
- char是固定长度字符串,类似C/C++中的数组的概念,例如char(6)表示开辟6个字符的大小的空间,没用完就是浪费。
- varchar是可变长度的字符串,例如varchar(6)表示最大长度为6个字符,如果用户仅使用了一个字符,那么varchar只会分配出一个字符的空间+额外1个字节(记录数据大小)用于存储。
char 和 varchar类型的选择
- 如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5
- 如果数据长度有变化,就使用变长(varchar), 比如:名字,地址,但是你要保证最长的能存的进去。
- 定长的磁盘空间有时比较浪费,但是效率高。
- 变长的磁盘空间有时比较节省,但是效率低。
- 定长的意义是,直接开辟好对应的空间
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
五、日期类型和时间类型
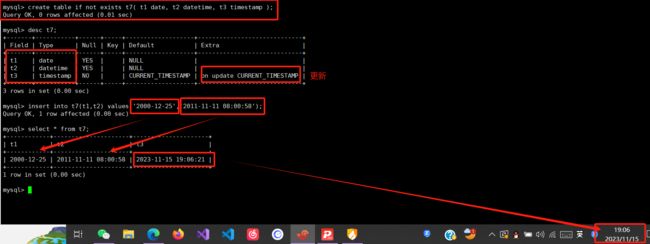
date :日期 ‘yyyy-mm-dd’ ,占用三字节
datetime : 时间日期格式 ‘yyyy-mm-dd HH:ii:ss’ 表示范围从 1000 到 9999 ,占用八字节
timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,占用四字节 ,插入数据后,会自动更新
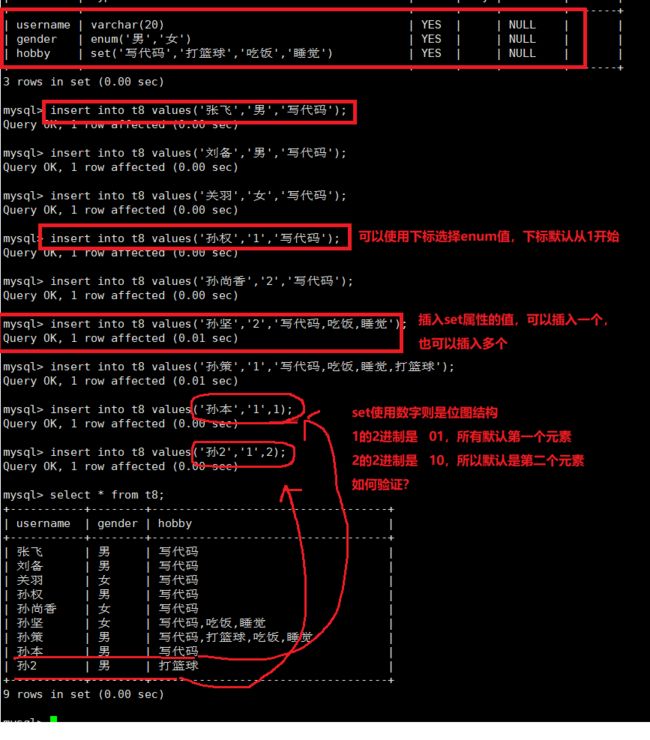
六、枚举和集合
1.枚举和集合
enum:枚举,“单选”类型;
语法:enum(‘选项1’,‘选项2’,‘选项3’,…);
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,…最多65535个;当我们添加枚举值时,也可以添加对应的数字编号。
set:集合,“多选”类型;
语法:set(‘选项值1’,‘选项值2’,‘选项值3’, …);
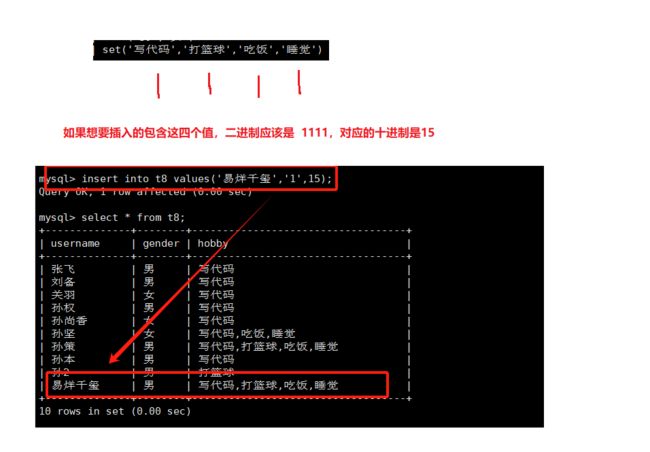
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,… 最多64个。
说明:不建议在添加枚举值,集合值的时候采用数字的方式,因为不利于阅读。
2.find_in_set
find_in_set用于集合查询。
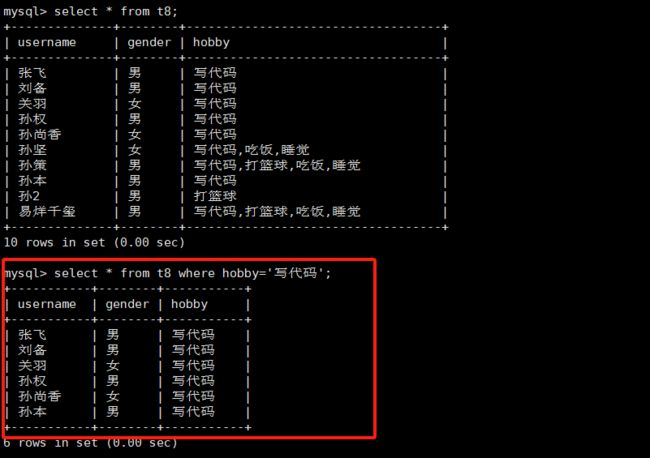
当我们使用select查询数据时,指定某个值查询的时候,只能查出指定的数据,例如,如果查hobby是写代码,查询结果只有hobby中只有写代码的,像别的数据写代码只是hobby中其中的一个字段,还有其他字段,使用普通查询查不到。
使用select_in_set,只要包含指定字段的数据都会被查询出来。
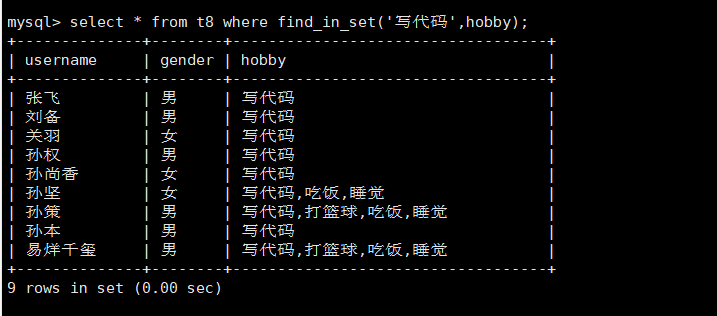
但是find_in_set不支持多个指定字段同时查询。

此时我们可以使用and
