大数据-hadoop入门与部署
大数据-hadoop入门与部署
- 大数据-hadoop入门与部署
-
- 启蒙
-
- 分治思想
- 单机处理大数据问题
- 集群分布式处理大数据的辩证
- Hadoop
-
- Hadoop项目/生态
- hadoop-hdfs
-
- 存储模型
- 架构设计
- 角色功能
- 元数据持久化
- 安全模式
-
- HDFS中的SNN
- 副本放置策略
- 读写流程
-
- HDFS写流程
- HDFS读流程
- 持久化机制
- 用法
-
- 部署
-
- 基础设施
- 部署配置
- 初始化运行
- 命令行使用
-
- 伪分布式: (单一节点)
- 完全分布式: (四节点)
大数据-hadoop入门与部署
启蒙
分治思想
需求:
- 我有一万个元素(比如数字或单词)需要存储?
- 如果查找某一个元素,最简单的遍历方式复杂的是多少?
- 如果我期望复杂度是O(4)呢?
分而治之的思想很重要,出现在了很多地方。 - Redis集群
- ElasticSearch
- Hbase
- HADOOP生态无处不在!
单机处理大数据问题
需求:
有一个非常大的文本文件,里面有很多很多的行,只有两行一样,它们出现在未知的位置,需要查找到它们。
单机,而且可用的内存很少,也就几十兆。
集群分布式处理大数据的辩证
- 2000台真的比一台速度快吗?
- 如果考虑分发上传文件的时间呢?
- 如果考虑每天都有1T数据的产生呢?
- 如果增量了一年,最后一天计算数据呢?
结论
分而治之
并行计算
计算向数据移动
数据本地化读取
Hadoop
Hadoop之父Doug Cutting
Hadoop的时间简史
- 《The Google File System 》 2003年
- 《MapReduce: Simplified Data Processing on Large Clusters》 2004年
- 《Bigtable: A Distributed Storage System for Structured Data》 2006年
- Hadoop由 Apache Software Foundation 于 2005年秋天作为Lucene的子项目Nutch的一部分正式引入。
- 2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为Hadoop 的项目中。
- Cloudera公司在2008年开始提供基于Hadoop的软件和服务。
- 2016年10月hadoop-2.6.5
- 2017年12月hadoop-3.0.0
- hadoop.apache.org
Hadoop项目/生态
The project includes these modules:
- Hadoop Common
- Hadoop Distributed File System (HDFS™)
- Hadoop YARN
- Hadoop MapReduce
Other Hadoop-related projects at Apache include:
- Ambari™
- Avro™
- Cassandra™
- Chukwa™
- HBase™
- Hive™
- Mahout™
- Pig™
- Spark™
- Tez™
- ZooKeeper™

www.cloudera.com
Cloudera’s Distribution Including Apache Hadoop
CDH is the most complete,tested, and popular distribution of Apache Hadoop and related projects.
- hadoop-2.6.0+cdh5.16.1
- hbase-1.2.0+cdh5.16.1
- hive-1.1.0+cdh5.16.1
- spark-1.6.0+cdh5.16.1
hadoop-hdfs
分布式文件系统那么多
为什么hadoop项目中还要开发一个hdfs文件系统?
存储模型
- 文件线性按字节切割成块(block),具有offset,id
- 文件与文件的block大小可以不一样
- 一个文件除最后一个block,其他block大小一致
- block的大小依据硬件的I/O特性调整
- block被分散存放在集群的节点中,具有location
- Block具有副本(replication),没有主从概念,副本不能出现在同一个节点
- 副本是满足可靠性和性能的关键
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入多次读取,不支持修改
- 支持追加数据
g)

架构设计
- HDFS是一个主从(Master/Slaves)架构
- 由一个NameNode和一些DataNode组成
- 面向文件包含:文件数据(data)和文件元数据(metadata)
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block的读写
- DataNode与NameNode维持心跳,并汇报自己持有的block信息
- Client和NameNode交互文件元数据和DataNode交互文件block数据

角色功能
NameNode
- 完全基于内存存储文件元数据、目录结构、文件block的映射
- 需要持久化方案保证数据可靠性
- 提供副本放置策略
DataNode
- 基于本地磁盘存储block(文件的形式)
- 并保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
元数据持久化
- 任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来
- 使用FsImage存储内存所有的元数据状态
- 使用本地磁盘保存EditLog和FsImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并有体积膨胀风险
- FsImage具有恢复速度快,体积与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FsImage+EditLog整合的方案:
滚动将增量的EditLog更新到FsImage,以保证更近时点的FsImage和更小的EditLog体积
安全模式
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当Namenode启动时,它从硬盘中读取Editlog和FsImage
- 将所有Editlog中的事务作用在内存中的FsImage上
- 并将这个新版本的FsImage从内存中保存到本地磁盘上
- 然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了
- Namenode启动后会进入一个称为安全模式的特殊状态。
- 处于安全模式的Namenode是不会进行数据块的复制的。
- Namenode从所有的 Datanode接收心跳信号和块状态报告。
- 每当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全(safely replicated)的。
- 在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的30秒等待时间),Namenode将退出安全模式状态。
- 接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他Datanode上。
HDFS中的SNN
SecondaryNameNode(SNN)
- 在非Ha模式下,SNN一般是独立的节点,周期完成对NN的EditLog向FsImage合并,减少EditLog大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
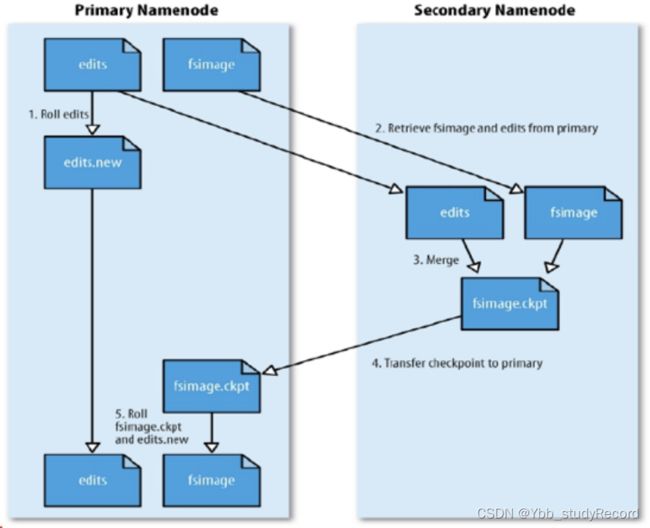
副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在于第一个副本不同的 机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。
- 更多副本:随机节点。
读写流程
HDFS写流程

- Client和NN连接创建文件元数据
- NN判定元数据是否有效
- NN处发副本放置策略,返回一个有序的DN列表
- Client和DN建立Pipeline连接
- Client将块切分成packet(64KB),并使用chunk(512B)+chucksum(4B)填充
- Client将packet放入发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存并发送给第二个DN
- 第二个DN收到packet后本地保存并发送给第三个DN
- 这一个过程中,上游节点同时发送下一个packet
- 生活中类比工厂的流水线:结论:流式其实也是变种的并行计算
- Hdfs使用这种传输方式,副本数对于client是透明的
当block传输完成,DN们各自向NN汇报,同时client继续传输下一个block
所以,client的传输和block的汇报也是并行的
HDFS读流程
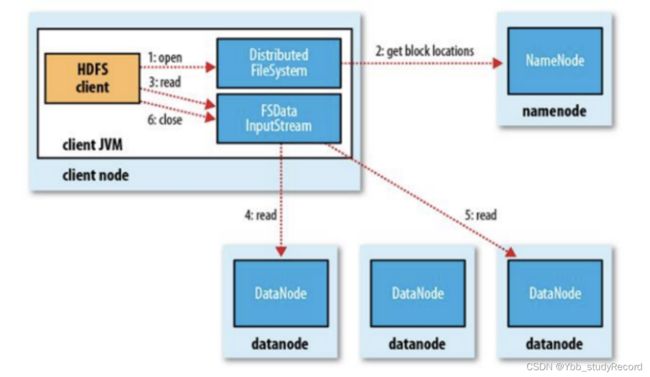
- 为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。
- 如果在读取程序的同一个机架上有一个副本,那么就读取该副本。
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。
语义:下载一个文件:
- Client和NN交互文件元数据获取fileBlockLocation
- NN会按距离策略排序返回
- Client尝试下载block并校验数据完整性
语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
- Hdfs支持client给出文件的offset自定义连接哪些block的DN,自定义获取数据
- 这个是支持计算层的分治、并行计算的核心
持久化机制
EditsLog: 日志
体积小,记录少:必然有优势
FsImage: 镜像、快照
如果能更快的滚动更新时点
最近时点的FsImage + 增量的EditsLog
现在10点
FI:9点+ 9点到10点的增量的EL
1.加载FI
2.加载EL
3.内存就得到了关机前的全量数据!!!!
问题:
那么: FI 时点是怎么滚动更新的!!!!!?
由 NN 8点溢写,9点溢写。。。
NN :第一次开机的时候,只写一次FI ,假设8点,到9点的时候,EL 记录的是8~9的日志
只需要将8-9点的日志,更新到8点的FI中,FI的数据就会变成9点
寻求另外一台机器来做
用法
官网导读
http://hadoop.apache.org/docs/r2.6.5/
- 支持最好的平台:GNU/Linux
- 依赖的软件:java,ssh
部署模式:
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
部署
基础设施
- 操作系统、环境、网络、必须通畅
- 设置IP及主机名
- 关闭防火墙&selinux
- 设置hosts映射
- 时间同步
- 安装jdk
- 设置SSH免秘钥
设置网络:
设置IP
* 大家自己看看自己的vm的编辑->虚拟网络编辑器->观察 NAT模式的地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
#HWADDR=00:0C:29:42:15:C2
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.150.11
NETMASK=255.255.255.0
GATEWAY=192.168.150.2
DNS1=223.5.5.5
DNS2=114.114.114.114
设置主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node01
设置本机的ip到主机名的映射关系
vi /etc/hosts
192.168.150.11 node01
192.168.150.12 node02
关闭防火墙
service iptables stop
chkconfig iptables off
关闭 selinux
vi /etc/selinux/config
SELINUX=disabled
做时间同步
yum install ntp -y
vi /etc/ntp.conf
server ntp1.aliyun.com
service ntpd start
chkconfig ntpd on
安装JDK:
rpm -i jdk-8u181-linux-x64.rpm
*有一些软件只认:/usr/java/default
vi /etc/profile
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile | . /etc/profile
ssh免密: ssh localhost 1,验证自己还没免密 2,被动生成了 /root/.ssh
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
如果A 想 免密的登陆到B:
A:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
B:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
结论:B包含了A的公钥,A就可以免密的登陆
你去陌生人家里得撬锁
去女朋友家里:拿钥匙开门
部署配置
- centos 6.5
- jdk 1.8
- hadoop 2.6.5
规划路径:
mkdir /opt/bigdata
tar xf hadoop-2.6.5.tar.gz
mv hadoop-2.6.5 /opt/bigdata/
pwd
/opt/bigdata/hadoop-2.6.5
vi /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
配置hadoop的角色:
cd $HADOOP_HOME/etc/hadoop
必须给hadoop配置javahome要不ssh过去找不到
vi hadoop-env.sh
export JAVA_HOME=/usr/java/default
给出NN角色在哪里启动
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
配置hdfs 副本数为1.。。。
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
配置DN这个角色再那里启动
vi slaves
node01
初始化运行
hdfs namenode -format
创建目录
并初始化一个空的fsimage
VERSION
CID
start-dfs.sh
第一次:datanode和secondary角色会初始化创建自己的数据目录
http://node01:50070
修改windows: C:\Windows\System32\drivers\etc\hosts
192.168.150.11 node01
192.168.150.12 node02
192.168.150.13 node03
192.168.150.14 node04
命令行使用
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
验证知识点
cd /var/bigdata/hadoop/local/dfs/name/current
观察 editlog的id是不是再fsimage的后边
cd /var/bigdata/hadoop/local/dfs/secondary/current
SNN 只需要从NN拷贝最后时点的FSimage和增量的Editlog
hdfs dfs -put hadoop*.tar.gz /user/root
cd /var/bigdata/hadoop/local/dfs/data/current/BP-281147636-192.168.150.11-1560691854170/current/finalized/subdir0/subdir0
for i in `seq 100000`;do echo "hello hadoop $i" >> data.txt ;done
hdfs dfs -D dfs.blocksize=1048576 -put data.txt
cd /var/bigdata/hadoop/local/dfs/data/current/BP-281147636-192.168.150.11-1560691854170/current/finalized/subdir0/subdir0
检查data.txt被切割的块,他们数据什么样子
伪分布式: (单一节点)
- 部署路径
- 配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
slaves

伪分布式: 在一个节点启动所有的角色: NN,DN,SNN
完全分布式: (四节点)
- 部署路径
- 配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
slaves
- 分发配置

基础环境
部署配置
1)角色在哪里启动
NN: core-site.xml: fs.defaultFS hdfs://node01:9000
DN: slaves: node01
SNN: hdfs-siet.xml: dfs.namenode.secondary.http.address node01:50090
2) 角色启动时的细节配置:
dfs.namenode.name.dir
dfs.datanode.data.dir
初始化&启动
格式化
Fsimage
VERSION
start-dfs.sh
加载我们的配置文件
通过ssh 免密的方式去启动相应的角色
伪分布式到完全分布式:角色重新规划
node01:
stop-dfs.sh
ssh 免密是为了什么 : 启动start-dfs.sh: 在哪里启动,那台就要对别人公开自己的公钥
这一台有什么特殊要求吗: 没有
node02~node04:
rpm -i jdk....
node01:
scp /root/.ssh/id_dsa.pub node02:/root/.ssh/node01.pub
scp /root/.ssh/id_dsa.pub node03:/root/.ssh/node01.pub
scp /root/.ssh/id_dsa.pub node04:/root/.ssh/node01.pub
node02:
cd ~/.ssh
cat node01.pub >> authorized_keys
node03:
cd ~/.ssh
cat node01.pub >> authorized_keys
node04:
cd ~/.ssh
cat node01.pub >> authorized_keys
配置部署:
node01:
cd $HADOOP/etc/hadoop
vi core-site.xml 不需要改
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/full/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/full/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/full/dfs/secondary</value>
</property>
vi slaves
node02
node03
node04
分发:
cd /opt
scp -r ./bigdata/ node02:`pwd`
scp -r ./bigdata/ node03:`pwd`
scp -r ./bigdata/ node04:`pwd`
格式化启动
hdfs namenode -format
start-dfs.sh