重生之——python与我不得不说的故事
本文基于B站 小甲鱼视频 进行总结!!!
目录
1.变量及运算
1.1变量使用规则
1.2转义字符和原始字符
1.3字符串的加法和乘法
1.4伪随机数
1.5数字类型及运算
2.分支和循环
2.1分支 if
2.2循环 while
2.3循环 for
3.列表
3.1列表定义
3.2列表下标索引输出
3.3列表切片
3.4列表方法
3.4.1内容增加
3.4.2内容删除
3.4.3内容替换
3.4.4内容查找
3.5列表运算
3.5.1加法
3.5.2嵌套列表
3.6列表拷贝
3.6.1浅拷贝
3.6.2深拷贝
3.7列表推导式
4.元组
4.1元组定义
4.2元组的通用
4.3元组打包和解包
5.字符串
5.1字符串变换
5.1.1capitalize
5.1.2casefold
5.1.3title
5.1.4swapcase
5.1.5upper
5.1.6lower
5.2字符串对齐
5.2.1center
5.2.2ljust
5.2.3rjust
5.2.4zfill
5.3字符串查找
5.3.1count
5.3.2find
5.3.3rfind
5.3.4index
5.3.5rinedx
5.4字符串替换
5.4.1expandtabs
5.4.2replace
5.4.3translate
5.5字符串判断
5.5.1startswith
5.5.2endswith
5.5.3isupper
5.5.4islower
5.5.5istitle
5.5.6isalpha
5.5.7isascii
5.5.8isspace
5.5.9isprintable
5.5.10isdecimal
5.5.11isdigit
5.5.12isnumeric
5.5.13isalnum
5.5.14isidentifier
5.5.15iskeyword
5.6字符串截取
5.6.1lstrip
5.6.2rstrip
5.6.3strip
5.6.4removeprefix
5.6.5removesuffix
5.7字符串拆分
5.7.1partition
5.7.2rpartition
5.7.3split
5.7.4rsplit
5.7.5splitlines
5.8字符串拼接
5.8.1join
5.9字符串格式化
5.9.1format基本语法
5.9.2format插入方法
5.9.3format对齐
5.9.4format +- 使用
5.9.5format精度
5.9.6format整型输出格式
5.9.7format浮点数输出
5.9.8 f-字符串
6.序列
6.1序列运算符
6.1.1 +
6.1.2 *
6.1.3 is
6.1.4 is not
6.1.5 in
6.1.6 not in
6.1.7 del
6.2序列函数
6.2.1 list
6.2.2 tuple
6.2.3 str
6.2.4 min
6.2.5 max
6.2.6 len
6.2.7 sum
6.2.8 sorted
6.2.9 reversed
6.2.10 all
6.2.11 any
6.2.12 enumerate
6.2.13 zip
6.2.14 map
6.2.15 filter
6.2.16 iter
6.2.17 next
7.字典
7.1字典创建
7.2字典内容操作
7.2.1 增加
7.2.2删除
7.2.3清空
7.2.4修改
7.2.5查找
7.3字典获取
7.3.1 items
7.3.2 keys
7.3.3 values
7.3.4 len
7.3.5 in & not in
7.3.6 list
7.3.7 iter
7.3.8 reversed
7.4字典拷贝
7.5字典嵌套
7.6字典推导式
8.集合
8.1集合创建
8.2集合唯一性
8.2.1
8.2.2 集合内容访问
8.2.3集合内容去重
8.3集合函数生成新集合
8.3.1 copy
8.3.2 isdisjoint
8.3.3 issubset
8.3.4 issuperset
8.3.5 union
8.3.6 intersection
8.3.7 difference
8.3.8 symmetric_differnece
8.4 集合函数修改原集合
8.4.1 update
8.4.2 intersection_update
8.4.3 difference_update
8.4.4 symmetric_difference_update
8.4.5 add
8.4.6 remove
8.4.7 discard
8.4.8 pop
8.4.9 clear
8.5可哈希
8.5.1基本概念
8.5.2语法
8.6散列表
9.函数
9.1函数基本概念
9.1.1函数定义
9.1.2函数的参数
9.1.3函数的返回值
9.2函数参数
9.2.1位置参数
9.2.2关键字参数
9.2.3默认参数
9.2.4收集参数
9.2.5解包参数
9.3函数作用域
9.3.1局部作用域
9.3.2全局作用域
9.3.3语句 global
9.4嵌套函数
9.4.1嵌套函数定义
9.4.2语句 nonlocal
9.5 LEGB规则
10.闭包
10.1闭包基本定义
11.装饰器
11.1单装饰器
11.2多装饰器
11.3装饰器+输入参数
12.lambda表达式
13.生成器
13.1生成器基本规则
13.2生成器表达式
14.算法
14.1递归
14.1.1递归基本规则
14.1.2递归-阶层
14.1.3递归-斐波那契数列
14.2汉诺塔
1.变量及运算
1.1变量使用规则
(1)变量可以以中文起头,可以单个 _
(2)变量交换 x,y=y,x
刘家森=123
李四=456
print(刘家森)
print(李四)
刘家森,李四=李四,刘家森
print(刘家森)
print(李四)
1.2转义字符和原始字符
(1)单引号中包含双引号,双引号中包含单引号,单引号中有单引号使用转义字符,使用转义字符让 \ 后面的字符被认为是普通字符
(2)字符串前 加 r 表明后面字符串都为原始字符串,也就是没有转义
(3)一个 \ 在末尾 表示下行接着上行写
(4)三个 ’ 三个 “ 也可以实现换行,但要注意开始和结束的 引号 相对应
(5)用 () 可以实现换行输入,代表一句代码
(6)print(i,end=" ") 表示输出一个 i 之后 空一个接着输出
print("let's go!")
print('"every place')
print("————————")
print("D:\there\two\one\now")
print("D:\\there\\two\\one\\now")
print(r"D:\there\two\one\now")
print("————————")
print("l\
j\
s")
potry="""
刘家森
牛逼
啊
"""
print(potry)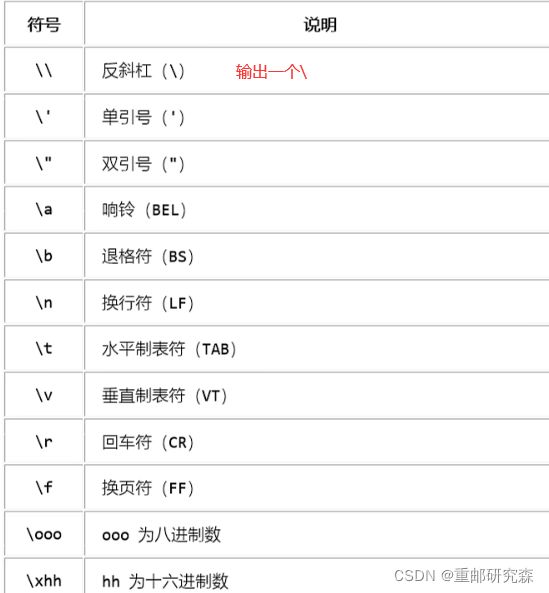
1.3字符串的加法和乘法
字符串的加法:字符串的拼接
字符串的乘法:字符串的多次输出
print('520'+'1314')
print("刘家森\n"*3)1.4伪随机数
利用 import 调用 random 库 即可实现下面函数
(1)random.randint(1,10) 随机产生1-10的一个整数
(2)random.getstate 获取随机数种子
(3)random.setstate 设置随机数生成器内部状态
1.5数字类型及运算
(1)python中的 0.1+0.2 不等于 0.3,这是由于精度导致。解决这个问题使用 decimal。deciaml中可以传递 整型 或者 字符型,不能传入浮点型
(2)对于 复数,python中可以实现 x.real 或者 x.imag分别实现调用输出
(3) // 地板除,对于结果取比目标结果小的整数
(4) Fraction(0,1) 代表 分子为0 分母为1
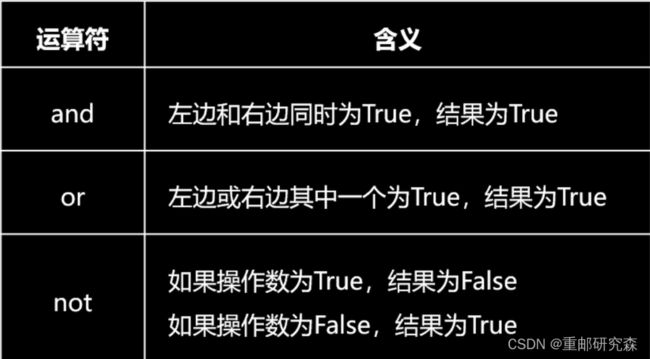
(4)逻辑运算符 and or not ,其中 not 代表取反的意思
(5)短路逻辑:从左往右,只有当第一个操作数的值无法确定逻辑运算结果时,才对第二个操作数进行求值 比如说 1and2 因为结果要判断到2才能确定,所以结果为2
import decimal
a=decimal.Decimal('0.1')
b=decimal.Decimal('0.2')
print(a+b)
c=0.1
d=0.2
print(c+d)
print("——————————")
x=1+2j
print(x.real)
print(x.imag)
print("——————————")
print(3/2)
print(3//2)
print("——————————")
if(3<4 and 4<5):
print("true")
else:
print("false")
print("——————————")
if(3<4 or 40<5):
print("true")
else:
print("false")
print("——————————")
if(not 3<4) :
print("true")
else:
print("false")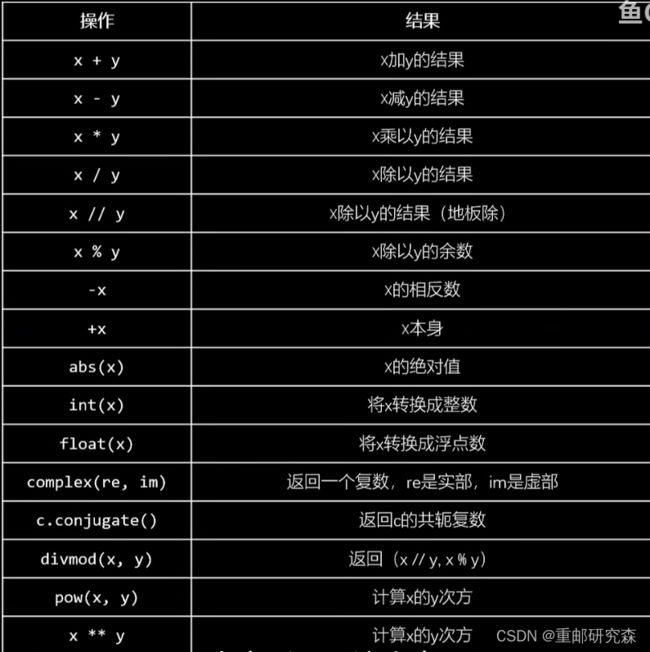
2.分支和循环
2.1分支 if
(1)if
(2)if else
(3)if elif elif else 其中elif==else if
(4)成立执行语句 if 判断条件 else 不成立执行语句
(5)可进行分支嵌套
(6)else 可用于 while 。当while条件为假时进入else,但中途用break跳出则不进入else
if 3<5:
print("对")
print("————————if else————————")
if (2==3):
print("相等")
else:
print("不等")
print("———————if elif—————————")
score=input("请输入分数:")
score=int(score)
if (score==2):
print("2")
elif (score==3):
print("3")
elif(score==4):
print("4")
else:
print(0)
print("——————if其他写法——————————")
a=10
b=20
smart=a if a5):
print("3>5")
else:
if(3>4):
print("3>4")
else:
print("3<4")2.2循环 while
(1)while 判断条件 执行语句
i=1
while i<=9:
j = 1
while j<=i:
print(j,"*",i,"=",j*i,end=" ")
j+=1
print()
i+=12.3循环 for
(1)for 变量 in 可迭代对象 :执行语句
(2)range(stop)生成0,stop-1的整数 range(start,stop)生成一个start,stop-1的整数 range(start,stop,step)step是改变的步进
注意事项:rangr(5,5)此时没有数字 range(4,5)此时只有4
for each in "hello":
print(each)
print("————————range(stop)————————————")
for i in range(10):
print(i,end=" ")
print("————————range(start,stop)————————————")
for i in range(5,5):
print(i,end=" ")
print("————————range(start,stop,step)————————————")
for i in range(10,5,-2):
print(i,end=" ")3.列表
3.1列表定义
定义:可以存放不同数据类型的序列
语法:【1,12,“迷惑”】
rhyme=[1,2,3.1,"刘家森"]
print(rhyme)
print("————————for输出所有列表—————————")
for each in rhyme:
print(each)3.2列表下标索引输出
(1)语法:列表名字【下标】
注意事项:(1)最后一个元素下标为 -1
(2)可以利用 len 函数找到最后元素下标,但要减1
print("————————列表下标输出—————————")
print(rhyme[0])
print(rhyme[3])
length = len(rhyme)
print(rhyme[length-1])
print(rhyme[-1])3.3列表切片
作用:可以对列表进行多值输出,也就是按区域一次性输出很多
注意事项:(1)【:】代表从头到尾输出整个列表
(2)【:3】代表从下标0号位置输出下标为 3-1的数
(3)【3:】代表从下标为3的位置输出到所有
(4)【a:b】代表从下标a开始,输出到下标 b-1
(5)【::2】代表从左至右间距为2依次输出列表
(6)【::-1】代表从右往左间距为1依次输出列表(逆序输出)
print("————————列表切片—————————")
print(rhyme[0:3])
print(rhyme[2:4])
print(rhyme[0:7:2])
print(rhyme[::2])
print(rhyme[::-1])3.4列表方法
3.4.1内容增加
语法:(1)末尾插入 append()添加单个 extend()添加多个
(2)容易位置插入 insert(a,b)在下标a出插入b值
作用:在列表末尾添加一个或多个指定元素
注意事项:(1)利用切片也可以实现增加,s【2:】=【7,8】 代表从当前2号下标开始后的数据等于 7,8,9
print("———————列表方法增加————————————")
heros=["钢铁侠","绿巨人"]
heros.append("黑寡妇")
print(heros)
heros.extend(["张三","李四","王五"])
print(heros)
print("———————切片方法增加————————————")
s=[1,2,3,4,5,6]
s[3:]=[7,8,9]
print(s)
print("———————列表方法容易位置增加————————————")
s.insert(3,4)
print(s)3.4.2内容删除
语法:(1)remove(a)删除列表中的 a 如果有多个 a 那就只删除第一个,并且如果列表没有a则会报错
(2)pop(b)删除下标为b 的元素
(3)clear 清空整个列表
print("———————列表方法删除————————————")
x=[1,2,3,4,5,6]
x.remove(1)
print(x)
x.pop(2)
print(x)
x.clear()
print(x)3.4.3内容替换
语法:(1)单值修改 利用下标值修改,s【下标】=“t替换值” 多值修改 利用切片修改
(2)排序 sort 升序 reverse 降序
print("——————插入————————")
s=[1,2,3,4,5,6]
s[3]=40
print(s)
s[2:]=[500,400,600]
print(s)
print("——————sort升排序————————")
s.sort()
print(s)
print("——————sort降排序————————")
s.reverse()
print(s)3.4.4内容查找
语法:count () 查找指定元素并返回个数
index()查找指定元素的下标 多元素的话返回第一个
index(x,start,end)查找指定范围内的 x
copy 拷贝列表
print("——————插入————————")
s=[1,2,3,4,5,6]
s[3]=40
print(s)
s[2:]=[500,400,600]
print(s)
print("——————sort升排序————————")
s.sort()
print(s)
print("——————sort降排序————————")
s.reverse()
print(s)
print("——————查找————————")
x=[1,2,2,3,6,5,2,4]
print(x.count((2)))
print(x.index(6))
print(x.index(2,2,4))
print("——————拷贝————————")
x_copy=x.copy()
print(x_copy)
x_copy2=x[:]
print(x_copy2)3.5列表运算
3.5.1加法
(1)列表之间相加 也就是列表元素拼接
(2)列表*x 也就是列表元素变为 x 倍
print("——————————列表加法————————")
s=[1,2,3]
x=[4,5,6]
y=s+x
print(y)
print(2*y)3.5.2嵌套列表
本质:二维列表
初始化:通过for循环实现
访问:(1)for循环 (2)元素下标(类似二维数组)
is 同一性运算符 用于检验两个变量是否指向同一个对象的运算符
print("——————————嵌套列表————————")
martix=[[1,2,3],[4,5,6],[7,8,9]]
print(martix)
martix=[[1,2,3],
[4,5,6],
[7,8,9]
]
print(martix)
print("——————————访问嵌套列表————————")
for i in martix:
for each in i:
print(each,end=' ')#元素间隔
print()#换行
print(martix[0])
print(martix[0][0])
print("——————————嵌套列表初始化————————")
A=[0]*3
for i in range(3):#让 i 依次变为 0 1 2 这样做是为了给下面 A【i】进行赋值为 A【0】
A[i]=[0]*3
print(A)3.6列表拷贝
3.6.1浅拷贝

对于一个列表 x ,将会产生一个不同内存地址,且数据一样的列表为 y。此时 x 和 y 之间互相不影响 适用于 一维列表,二维列表会出错。因为浅拷贝只是拷贝了外层,内存的数据是引用操作
print("————一维列表浅拷贝————————")
x=[1,2,3]
y=x.copy()
print(x)
print(y)
x[1]=10
print(x)
print(y)
print("————二维列表浅拷贝————————")
x=[[1,2,3],
[4,5,6],
[7,8,9]]
y=x.copy()
print(x)
print(y)
x[1][1]=50
print(x)
print(y)3.6.2深拷贝
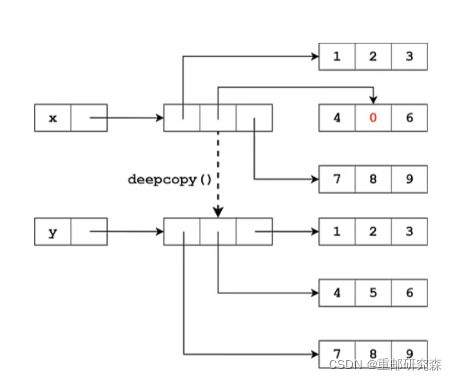
实现方法:利用copy模块调用copy函数,需要先 import copy库 使用 deepcopy 函数。它的原理是将原对象以及其子对象都进行了拷贝
import copy
print("————二维列表深拷贝————————")
x=[[1,2,3],
[4,5,6],
[7,8,9]]
y=copy.deepcopy(x)
print(x)
print(y)
x[1][1]=50
print(x)
print(y)3.7列表推导式
语法:(1)【改变方法 for 目标 in 当前列表】 oho=[i * 2 for i in oho]
(2)【改变方法 for 目标 in 当前列表 if 条件判断】
s=[i for i in range(10) if i%2==0] 先执行 for 再执行 if 最后输出 i
(3)【改变方法 for 目标 in 当前列表 for 目标 in 当前列表】 嵌套方法
z=[x+y for x in "fishc" for y in "FISHC"](4)【改变方法 for 目标 in 当前列表 if 条件判断 for 目标 in 当前列表 if 条件判断】
x=[x+y for x in range(10) if x%2==0 for y in range(100,110) if y%2==0]注意事项:(1)ord 函数:把 字符 转为 Unicode 编码并保存为列表
(2)循环是通过迭代来改变列表各元素值,而列表推导式直接创建一个新的列表,然后再赋值为原先的这个变量名
print("——————for循环改变列表值——————————")
oho=[1,2,3,4,5]
for i in range(len(oho)):
oho[i]=oho[i] * 2
print(oho)
print("——————列表推导式一维列表——————————")
oho=[1,2,3,4,5]
oho=[i * 2 for i in oho]
print(oho)
x=[c*2 for c in "FinshC"]
print(x)
print("——————ord准换编码——————————")
code = [ord(x) for x in "FinshC"]
print(code)
print("——————列表推导式二维列表——————————")
martix=[[1,2,3],
[4,5,6],
[7,8,9]]
col2=[row[1] for row in martix]#获取每行下标为 1 的元素
print(col2)
diag=[martix[i][i] for i in range(len(martix))]
print(diag)
4.元组
4.1元组定义
语法:(元素1 ,元素2),这里和列表不一样,是()而不是【】,而且可以省去()
注意事项:元组内数据不可以再进行修改
ryhme=(1,2,3,4,5,6,"瘦死的骆驼比马大")
print(ryhme)
ryhme=1,2,3,4,5,6,"瘦死的骆驼比马大"
print(ryhme)4.2元组的通用
(1)元组和列表在 运算中区别是:只能查找,不能增加修改
(2)生成一个元素元组:s=(1,) 生成一个整数 s=(1)
(3)如果元组中成员是列表,则可以进行修改
print("———————元组定义—————————————")
ryhme=(1,2,3,4,5,6,"瘦死的骆驼比马大")
print(ryhme)
ryhme=1,2,3,4,5,6,"瘦死的骆驼比马大"
print(ryhme)
print("———————元组下标访问—————————————")
print(ryhme[0])
print(ryhme[-1])
print("———————元组切片访问—————————————")
print(ryhme[0:3])
print(ryhme[::])
print(ryhme[3:])
print(ryhme[3:5])
print(ryhme[::-1])
print("———————元组查找—————————————")
num=(1,1,4,3,2,5)
print(num.count(1))
print(num.index(2))
print("———————元组加法—————————————")
x=1,2,3
y=4,5,6
s=x+y
print(s)
print(s*2)
print("———————元组for访问—————————————")
for each in s:
print(each,end=' ')
print()
print("———————元组for嵌套—————————————")
w=(1,2,3),(4,5,6)
for i in w:
for each in i:
print(each,end=' ')
print()
print("———————元组列表推导式—————————————")
s=1,2,3,4,5
s=[each *2 for each in s]
print(s)
4.3元组打包和解包
打包:生成一个元组也叫打包
解包:把元组数据根据 , 分隔输出
注意事项:(1)列表和字符串也具有该性质
(2)字符串在使用过程中必须根据有多少字符分几个包
(3)字符串技巧:一个包输出多字符 a,*b=x。这时 a 占一个 其余全是 b的
print("————————元组打包————————————————")
t=(123,"刘家森","ljs")
print(t)
print("————————元组解包————————————————")
x,y,z=t
print(x)
print(y)
print(z)
print("————————列表解包————————————————")
x=[123,345,21]
q,w,e=x
print(q)
print(w)
print(e)
print("————————字符串解包————————————————")
x="ljs"
q,w,e=x
print(q)
print(w)
a,*b=x
print(a)
print(b)5.字符串
5.1字符串变换
5.1.1capitalize
capitalize()
把首字母变为大写,其他变为小写
print("————————capitalize————————————")
x="i lovE YOU"
print(x.capitalize())5.1.2casefold
casefold()
把大写字母全部变为小写(任何语言)
print("————————casefold————————————")
x="I lovE YOU"
print(x.casefold())5.1.3title
title()
将每个单词首字母变为大写,其他字母变为小写
print("————————title————————————")
x="i lovE yOU"
print(x.title())5.1.4swapcase
swapcase()
将所有字母的大小写进行翻转
print("————————swapcase————————————")
x="i lovE yOu"
print(x.swapcase())5.1.5upper
upper()
将所有字母变为大写
print("————————upper————————————")
x="i lovE yOu"
print(x.upper())
5.1.6lower
lower()
将所有字母变为小写(只能英语)
print("————————lower————————————")
x="i lovE yOu"
print(x.lower())5.2字符串对齐
下面这些函数的第一个参数(字符串宽度) 必须大于字符串长度,否则直接输出该字符串。此外下列函数第二个参数代表填充的 字符,不写第二个参数默认为 空格
5.2.1center
center(width,fillchar=‘’) fillchar为填充字符串
字符串居中对齐
print("————————center————————————")
x='刘家森'
x=x.center(15)
print(x)
5.2.2ljust
ljust(width,fillchar=‘’) fillchar为填充字符串
字符串左对齐
print("————————ljust————————————")
x='刘家森'
x=x.ljust(15)
print(x)
5.2.3rjust
rjust(width,fillchar=‘’) fillchar为填充字符串
字符串右对齐
print("————————rjust————————————")
x='刘家森'
x=x.rjust(15)
print(x)
5.2.4zfill
zfill(width)
用 0 填充左侧
print("————————zfill————————————")
x='刘家森'
x=x.zfill(15)
print(x)5.3字符串查找
5.3.1count
count(num,start,end)
查找某个字符串出现的次数(可选区间查找)
print("————————count————————————")
x='我来自我的家'
a=x.count("我")
print(a)
5.3.2find
find(num,start,end)
查找某个字符串的下标(从左往右)没找到返回 -1
print("————————find————————————")
x='我来自我的家'
a=x.find("我")
print(a)
5.3.3rfind
rfind(num,start,end)
查找某个字符串的下标(从右往左)没找到返回 -1
print("————————rfind————————————")
x='我来自我的家'
a=x.rfind("我")
print(a)
5.3.4index
index(num,start,end)
查找某个字符串的下标(从左往右) 没找到直接报错
print("————————index————————————")
x='我来自我的家'
a=x.index("我")
print(a)
5.3.5rinedx
rindex(num,start,end)
查找某个字符串的下标(从右往左) 没找到直接报错
print("————————rindex————————————")
x='我来自我的家'
a=x.rindex("我")
print(a)5.4字符串替换
5.4.1expandtabs
expandtabs([tabsize=8])
将字符串中的 tab 全部替换为空格,里面参数为1个tab换成x个空格
print("————————expandtabs————————————")
code = """
print("123")
print("456")
"""
new_code=code.expandtabs(2)
print(new_code)
5.4.2replace
replace(old,new,count=-1)
将 原字符串 替换为 新字符串,里面参数为替换次数
print("————————replace————————————")
x="在吗?"
y="想你!"
x=x.replace(x,y)
print(x)
5.4.3translate
translate(table)
根据转换表格进行转换。可以加上忽略参数,这样在输出就不会显示
print("————————table————————————")
table = str.maketrans("abcdefg","1234567","love")#忽略了 love
x="acchgd love abc"
x=x.translate(table)
print(x)5.5字符串判断
(1)下面判断函数都是返回一个 bool 类型数据
(2)从左往右的顺序执行函数,例如 x.upper.isupper。先执行全为大写再判断是否为大写
5.5.1startswith
startswith(prefix,start,end) prefix可以是一个元组 ((“我”,“你”,“它”))
判断查找的字符串是不是在第一个位置
print("——————startswith———————")
x="我爱你 ,我真的服了"
print(x.startswith("我爱你"))5.5.2endswith
endswith(prefix,start,end) prefix可以是一个元组 ((“我”,“你”,“它”))
判断查找的字符串是不是在最后一个位置
print("——————endswith———————")
x="我爱你 ,我真的服了"
print(x.endswith("服了"))5.5.3isupper
isupper()
判断字符串所有字母是否都为大写
print("——————isupper———————")
x="I LOVE YOU"
print(x.isupper())5.5.4islower
islower()
判断字符串所有字母是否都为小写
print("——————islower———————")
x="i love you"
print(x.islower())5.5.5istitle
istitle()
判断字符串所有字母是否以大写开始,其他全为小写
print("——————istitle———————")
x="I Love You"
print(x.istitle())5.5.6isalpha
isalpha()
判断是否只有字母构成,注意空格
print("——————isalpha———————")
x="iloveyou"
print(x.isalpha())5.5.7isascii
isascii()
判断字符串为空或字符串中的所有字符都是 ASCII
5.5.8isspace
isspace()
判断是否为空白字符串 \n 和 空格 为空白字符串
print("——————isspace———————")
x=" "
print(x.isspace())5.5.9isprintable
isprintable()
判断所有字符是否可以打印 \n 不能打印
print("——————isprintable———————")
x=" \n "
print(x.isprintable())5.5.10isdecimal
isdecimal()
检查是不是数字 一般只用于 1 2 3这种数字
5.5.11isdigit
isdigit()
检查是不是数字 支持
5.5.12isnumeric
isnumeric()
检查是不是数字 支持 一 Ⅰ等多种类型数字
5.5.13isalnum
isalnum()
当 isalpha isdecimal isnumerical isdigit返回 true 时,它也返回 true
5.5.14isidentifier
isidentifier()
判断字符串是否是一个合法的标识符
print("——————isidentifier———————")
x="a_1"#正确
y="1_a"#错误
print(x.isidentifier())5.5.15iskeyword
iskeyword(“sub”) sub为要查找的字符
来查看该字符是否为python中的关键字
print("——————iskeyword———————")
import keyword
print(keyword.iskeyword("if"))5.6字符串截取
5.6.1lstrip
lstrip(“sub“) sub默认情况为空,如果写上字符串abc 则代表去除左侧abc。但是有空格则都不去除
去除左侧的空格
print("——————lstrip———————")
x=" ljs"
print(x.lstrip())
5.6.2rstrip
lstrip(“sub“)sub默认情况为空,如果写上字符串abc 则代表去除右侧abc。但是有空格则都不去除
去除右侧的空格
print("——————rstrip———————")
x="ljs "
print(x.lstrip())
5.6.3strip
strip(“sub“)sub默认情况为空,如果写上字符串abc 则代表去除左右测abc。但是有空格则都不去除
去除左右侧的空格
print("——————strip———————")
x=" ljs "
print(x.strip())
x=" wx ljs wx"
print(x.strip("wx"))5.6.4removeprefix
removeprefix()
删除指定的前缀 注意空格字符串
print("——————removeprefix———————")
x="www.ljs.com "
print(x.removeprefix("www."))
5.6.5removesuffix
removesuffix()
删除指定的后缀 注意空格字符串
print("——————removeprefix———————")
x="www.ljs.com "
print(x.removesuffix("com "))
5.7字符串拆分
5.7.1partition
partition(”sub“) sub为分隔的字符串
根据输入要求从左往右,把字符串分为三部分,第一部分:为分隔符左侧,第二部分为:分隔符,第三部分:为分隔符右侧
print("——————partition———————")
x="www.ljs.com "
print(x.partition("."))
5.7.2rpartition
rpartition(”sub“) sub为分隔的字符串
根据输入要求从右往左,把字符串分为三部分,第一部分:为分隔符左侧,第二部分为:分隔符,第三部分:为分隔符右侧
print("——————rpartition———————")
x="www.ljs.com "
print(x.rpartition("."))5.7.3split
split(”sub“,num) 从左往右进行切割
(1)默认情况都不输入下是按空格划分无限次
(2)”sub“代表按sub进行分隔 , num代表切割次数
print("——————split———————")
x="www ljs com"
print(x.split())#默认输出
x="www.ljs.com"
print(x.split("."))
print(x.split(".",1))5.7.4rsplit
rsplit(”sub“,num) 从右往左进行切割
(1)默认情况都不输入下是按空格划分无限次
(2)”sub“代表按sub进行分隔 , num代表切割次数
print("——————rsplit———————")
x="www ljs com"
print(x.rsplit())#默认输出
x="www.ljs.com"
print(x.rsplit("."))
print(x.rsplit(".",1))5.7.5splitlines
splitlines(True)
按行进行分隔。如果写上true代表加上换行符输出
print("——————splitlines———————")
x="www\nljs\ncom"
y="www\nljs\rcom"
print(x.splitlines())
print(x.splitlines(True))5.8字符串拼接
5.8.1join
”sub“.join(["一部分",”二部分“,”三部分“])
把sub插入到各个部分之间,里面可以是列表【】,也可以是元组()
print("——————join———————")
x='.'
y=x.join(["www","ljs","com"])
print(y)5.9字符串格式化
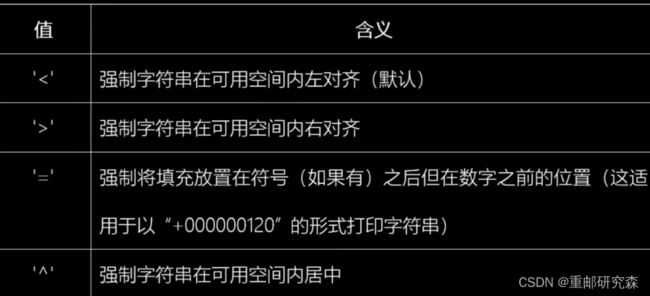
5.9.1format基本语法
语法:”刘家森{}“.format(”帅“)
作用:把字符串中的量当作一个可以输出的值,方法是{}代表这里要输出的位置,format里面是输出的值
print("———————format默认单插入———————————")
year=2010
x="刘家森来自于{}"
y=x.format(year)
print(y)5.9.2format插入方法
(1)默认多{}插入
print("———————format默认多插入———————————")
x="刘家森{},罗灿灿{}"
y=x.format("帅","美")
print(y)(2)按 format 里面数据序号插入
print("———————format{}插值方法1———————————")
x="刘家森{1},罗灿灿{0}"
y=x.format("帅","美")
print(y)
x="刘家森{1},罗灿灿{1}"
y=x.format("帅","美")
print(y)(3)format 里面数据名字插入
print("———————format{}插值方法2———————————")
x="{n1}美,{n2}美"
y=x.format(n1="刘家森",n2="罗灿灿")
print(y)5.9.3format对齐
(1)居中对齐
print("———————format居中———————————")
x="{:^10}"#10代表宽度为10 :代表位置或者关键字 :右边是格式化选项
y=x.format(250)
print(y)(2)右对齐
print("———————format右对齐1———————————")
x="{1:>10}{0:<10}"
y=x.format(520,250)
print(y)
print("———————format右对齐2———————————")
x="{left:>10}{right:<10}"
y=x.format(right=520,left=250)
print(y)(3)数据填充
print("———————format填充0———————————")
x="{:010}"#第一个0 代表填充 0
y=x.format(520)
print(y)
print("———————format填充0+对齐———————————")
x="{1:a>10}{0:b<10}"# 填充 a b
y=x.format(520,250)
print(y)5.9.4format +- 使用

print("———————format整数使用———————————")
x="{:+}{:-}"
y=x.format(250,-250)
print(y)
print("———————format , 当作千分符———————————")
x="{:,}"#位数不足则不显示
y=x.format(2515)
print(y)
print("———————format _ 当作千分符———————————")
x="{:_}"
y=x.format(2515)
print(y)5.9.5format精度

(1)对于整型,可以采用 上述1 2 两个方案
(2)对于字符串,则是进行字符截取
(3)精度使用在 : 后面加 .2 代表精度为2
print("———————format 数字精度———————————")
x="{:.2f}"#保留2位精度
y=x.format(3.2515)
print(y)
x="{:.2g}"#保留2位数
y=x.format(3.2515)
print(y)
print("———————format 字符串精度———————————")
x="{:.5}"#保留3位精度 不能用于整数
y=x.format("liu and lcc")
print(y)5.9.6format整型输出格式

print("———————format 整型输出格式二进制———————————")
x="{:b}"
y=x.format(16)
print(y)
print("———————format 整型输出格式Unicode———————————")
x="{:c}"
y=x.format(80)
print(y)
print("———————format 整型输出格式增加前缀———————————")
x="{:#b}"#实现输出前多一个 0b 表示二进制
y=x.format(16)
print(y)5.9.7format浮点数输出
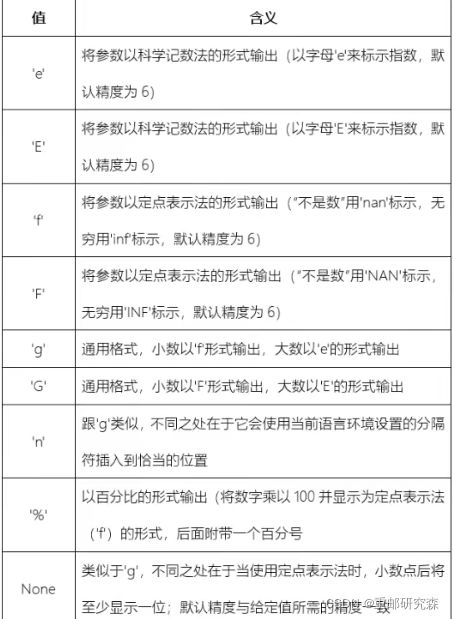
print("———————format 浮点数科学计数法输出———————————")
x="{:e}"#e是结果为e E是结果为E
y=x.format(16.3214)
print(y)
print("———————format 浮点数定点表示法输出———————————")
x="{:f}"#默认保留精度 6位
y=x.format(16.3214)
print(y)
print("———————format 浮点数 g 输出———————————")
x="{:g}"#如果format里面数大 则按e,如果小则按定点法
y=x.format(16003214)
z=x.format(125.321)
print(y)
print(z)
print("———————format 浮点数 % 输出———————————")
x="{:.2%}"#先乘100 再加%,默认精度 6
y=x.format(16.3214)
print(y)
5.9.8 f-字符串
作用:简化了 format 写法
语法:把之前 format 里面的数据写到 :前面,然后在 ” “ 前加入f或者F
注意事项:(1)支持3.6版本以上
print("———————f-字符串 基本使用———————————")
year=2010
x=F"刘家森来自:{year}"
y=F"刘家森来自:{1100}"
print(x)
print(y)
print("———————f-字符串 格式化———————————")
x=F"{-520:06}"
print(x)
x=F"{123456789:,}"
print(x)
print("———————f-字符串 精度———————————")
x=F"{3.1526:.2f}"
print(x)
print("———————f-字符串 复杂问题———————————")
a='+'
b='^'
c=10
d=3
e='g'
x=F"{3.1415:{a}{b}{c}.{d}{e}}"
print(x)
6.序列
(1)在 python中 所有对象 都有三个属性 ,唯一标识(不可修改无重复),类型,值
(2)id(s)查看 s 的唯一标识
6.1序列运算符
6.1.1 +
进行列表,元组,字符串的拼接
print("——————— + —————————————")
print([1,2,3]+[4,5,6])
print((1,2,3),(4,5,6))
print("123"+"456")6.1.2 *
进行列表,元组,字符串的多倍输出
print("——————— * —————————————")
print([1,2,3]*3)
print((1,2,3)*3)
print("123"*3)6.1.3 is
检测对象的 id 值 是否相等
print("——————— is —————————————")
a=1
b=1
if(a is b):
print("一样")
else:
print("不一样")
6.1.4 is not
检测对象的 id 值 是否不相等
print("——————— is not —————————————")
a=1
b=1
if(a is not b):
print("一样")
else:
print("不一样")6.1.5 in
判断某个函数是否在序列中
print("——————— in —————————————")
a="ljslcc"
if('j' in a):
print("在")
else:
print("不在")
6.1.6 not in
判断某个函数是否不在序列中
print("——————— not in —————————————")
a="ljslcc"
if('j' not in a):
print("在")
else:
print("不在")6.1.7 del
删除一个或多个指定的对象
rint("——————— del 基本用法—————————————")
x=[1,2,3,4,5,6]
print(x)
del x[0:2]#删除 0-2的元素
print(x)
print("——————— 切片实现 del —————————————")
x=[1,2,3,4,5,6]
x[0:3]=[]
print(x)
print("——————— del 缩进删除—————————————")
x=[1,2,3,4,5,6]
print(x)
del x[::2]#删除 0-2的元素
print(x)6.2序列函数
6.2.1 list
把元组,字符串变为列表
print("——————— list—————————————")
x=list((1,2,3,4,5))
print(x)
x=list("123456")
print(x)6.2.2 tuple
把列表,字符串变为元组
print("——————— tuple—————————————")
x=tuple([1,2,3,4,5])
print(x)
x=tuple("123456")
print(x)6.2.3 str
把元组,列表变为字符串
print("——————— str—————————————")
x=str((1,2,3,4,5))
print(x)
x=str([1,2,3,4,5])
print(x)
6.2.4 min
对比传入所有参数 返回最小的
注意啊事项:(1)传入参数不能为空
(2)对于参数为空,引入默认设置输出方式
print("————————— min 单参数 —————————————")
s=[1,1,2,3,4]
print(min(s))
print("————————— min 无参 —————————————")
s=[]
print(min(s,default="BBQ了"))
print("————————— min 多参数—————————————")
s=[1,1,2,3,4]
x=[7,8,8]
print(min(s,x))#输出具有最小值的列表6.2.5 max
对比传入所有参数 返回最大的
print("————————— max —————————————")
s="ljsandlcc"
print(max(s))6.2.6 len
len(sub) 获取 sub 长度
获取变量的长度 len函数的范围有限,2的32/64次方-1
print("————————— len ————————————")
x="abcd"
print(len(x))
6.2.7 sum
sum(sub) 对 sub 内求和
进行输入参数求和,输入可以为元组,列表
print("————————— sum ————————————")
x=(1,2,3,4,5)
print(sum(x))
y=5
print(sum(x,y))6.2.8 sorted
sorted()
元素升序排序。
注意事项:(1)与 sort 不一样在于 sorted不会改变之前的元素位置, sort会改变
(2)sorted 和 sort 一样 ,具有 关键参数控制排序方法(reverse:升降排序控制)(key:关键词控制排序)
(3)sort只能处理列表。 sorted可以处理元组,列表,字符串最后返回列表结果
print("————————— sorted ————————————")
x="aebcd"
print(sorted(x))#默认升序
print(x)
print("————————— sorted reverse参数————————————")
x="aebcd"
print(sorted(x,reverse=True))#降序
print("————————— sorted key参数————————————")
x=["ab","ba","abc","aaaa"]
print(sorted(x,key=len))#根据 长度 排序6.2.9 reversed
reversed()
对元素进行反向排序
注意事项:(1)reversed返回的是参数反向迭代器,对原数据不改变
(2)reverse没返回值,改变了原数据,所以不能print(x.reverse())
print("————————— reversed ————————————")
x=[1,3,4,5]
print(list(reversed(x)))
print("————————— reverse ————————————")
x=[1,3,4,5]
x.reverse()
print(x)6.2.10 all
all()
判断所有元素是否为真(0为假)
print("————————— all ————————————")
x=[0,1,2]
y=[1,2,3]
print(all(x))
print(all(y))
6.2.11 any
判断是否存在元素是否为真(0为假)
print("————————— any ————————————")
x=[0,1,2]
y=[1,2,3]
print(any(x))
print(any(y))6.2.12 enumerate
把一个列表数据,通过自定义或者默认方式加上一个编号,构成二维元组

print("————————— enumerate ————————————")
x=["spring","summer","winter"]
print(list(enumerate(x)))
print(list(enumerate(x,5)))6.2.13 zip
把列表或者字符串进行对应拼接构成新的元组。例如x列表的一号位置和y字符串的1号位置拼接成一个2维元组的一号位置
注意事项:(1)从元素个数最少的为基础开始组成
(2)如果想要对所有元素都进行拼接,可以利用 itertools库,调用zip_longest函数,这样对于少了的数据就用 none 拼接
print("————————— zip ————————————")
x=[1,2,3]
y=[4,5,6]
z=[7,8,9]
zipped=zip(x,y,z)
print(list(zipped))
print("————————— zip_longest————————————")
import itertools
x=[1,2,3,4,5]
y=[4,5,6,7]
z=[7,8,9]
zipped=itertools.zip_longest(x,y,z)
print(list(zipped))6.2.14 map
根据自定义函数对可迭代对象的每个元素进行运算,并将运算之后的结果返回给迭代器
注意事项:(1)对于多参数情况,以最短为基础
print("————————— map 单参数————————————")
maped=map(ord,"ljsandlcc")
print(list(maped))
print("————————— map 多参数————————————")
maped=map(pow,(1,2,3),(2,2,2))
print(list(maped))
6.2.15 filter
根据自定义函数对可迭代对象的每个元素进行运算,并将运算之后的为真结果返回给迭代器
print("————————— filter 单参数————————————")
maped=filter(str.islower,"Jason")
print(list(maped))6.2.16 iter
(1)一个迭代器肯定是一个可迭代对象
(2)可迭代对象(列表,元组)可以重复使用,迭代器(通过像map,iter函数得到)则是一次性的

print("————————— 迭代器————————————")
maped=filter(str.islower,"Jason")
for each in maped:
print(each)
print(list(maped))
print("————————— 迭代器对象————————————")
x=[1,2,3,4]
for each in x:
print(each)
print(x)print("————————— iter————————————")
x=[1,2,3,4,5]
y=iter(x)
print(type(x))
print(type(y))6.2.17 next
逐个将迭代器的元素提取出来
注意事项:(1)因为迭代器元素有限,为了防止元素都访问完之后继续访问程序异常,可以加入参数使得异常时输出自定义参数
print("————————— next————————————")
x=[1,2,3,4,5]
y=iter(x)
print(next(y))
print(next(y))
print(next(y))
print(next(y))
print(next(y))
print("————————— next 控制范围————————————")
x=[1,2,3,4,5]
y=iter(x)
print(next(y,"没了"))
print(next(y,"没了"))
print(next(y,"没了"))
print(next(y,"没了"))
print(next(y,"没了"))
print(next(y,"没了"))7.字典
7.1字典创建
方法:(1){} 与 : 结合 a={"张三":"李四","1":"2"}
(2)dict 函数 b=dict(张三="1",李四="2",王五="3")
(3)dict+列表 c=dict([("z","1"),("x","2"),("q","3")])
(4)dict+(1) d=dict({"张三":"李四","1":"2"})
(5)dict+(1)+2 ) e=dict({"张三":"李四","1":"2"},王五="3")
(6)dict + zip f=dict(zip(["1","2","3"],["a","b","c"]))
注意事项:(1)字典内容不可以重复
print("———————— 字典 创建方法1————————————")
x={"张三":"李四","1":"2"}
print(type(x))
print(x["张三"])#输出李四
x["王五"]="赵6"#添加一对新的王五:赵六
print(x)
print("———————— 字典 创建方法2————————————")
x=dict(张三="1",李四="2",王五="3")
print(x)
print("———————— 字典 创建方法3————————————")
a=dict([("z","1"),("x","2"),("q","3")])
print(a)
print("———————— 字典 创建方法4————————————")
d=dict({"张三":"李四","1":"2"})
print(d)
print("———————— 字典 创建方法5————————————")
e=dict({"张三":"李四","1":"2"},王五="3")
print(e)
print("———————— 字典 创建方法6————————————")
f=dict(zip(["1","2","3"],["a","b","c"]))
print(f)7.2字典内容操作
7.2.1 增加
formkeys(iterable,values) 把迭代器对象赋值给 values
方法:x【”A“】=250 键A赋值250.如果字典有 A 了则是修改,如果没有则是添加
print("———————— 字典 增加内容————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x)
x["a"]=250#添加内容
print(x)7.2.2删除
(1)pop(键) 删除指定键
(2)popitem() 删除最后一个键
(3)del x【j键】 删除指定键或者字典
注意事项:(1)如果不存在删除的键,则出现异常,解决办法:pop(键,”没有该键“)
print("———————— 字典 删除内容————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x)
x.pop("j","没有")#删除键 j
print(x)
print("———————— 字典 删除最后内容————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x)
x.popitem()
print(x)
print("———————— 字典 删除del————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x)
del x['l']
print(x)7.2.3清空
clear()
print("———————— 字典 清空————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x)
x.clear()
print(x)7.2.4修改
方法:(1)update({other})other为字典或可迭代对象或多个键值对
(2)x【”A“】=250 键A重新赋值250.
print("———————— 字典 修改 多键值对————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x)
x.update({"l":1,"j":2})
print(x)
x.update(l='10',s='50')
print(x)7.2.5查找
get(key,default)default为找不到清空下的输出
setdefault(key,default) 如果没找到,则给没找到的键 赋值自定义值
print("———————— 字典 查找get————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
print(x.get('l',"找不到"))print("———————— 字典 查找setdefault————————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
m.setdefault('q',"找不到")
print(m)
7.3字典获取
视图对象:是字典的动态试图,当字典内容改变,视图对象内容也改变
7.3.1 items
获取字典的键值对视图对象
7.3.2 keys
获取字典的键视图对象
7.3.3 values
获取字典的值视图对象
print("———————— 字典 视图对象————————————")
x=dict.fromkeys("ljs",250)#初始化一个 字典
keys=x.keys()
values=x.values()
items=x.items()
print(keys)
print(values)
print(items)
x.pop('l')
print(keys)
print(values)
print(items)7.3.4 len
获取字典长度
print("———————— 字典 len———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
print(len(m))
7.3.5 in & not in
判断键是否存在于字典中
print("———————— 字典 in———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
print('l' in m)
print("———————— 字典 not in———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
print('l' not in m)
7.3.6 list
把字典中所有的键变为列表,输出键值用values()
print("———————— 字典 list———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
n=list(m)
print(n)
7.3.7 iter
将字典的键构成一个迭代器
print("———————— 字典 iter———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
e=iter(m)
print(next(e))
print(next(e))
print(next(e,"没了"))
print(next(e,"没了"))
7.3.8 reversed
对字典内部键值对进行逆向操作
print("———————— 字典 reversed———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
e=reversed(m)
print(list(e))7.4字典拷贝
copy() 浅拷贝
print("———————— 字典 浅拷贝copy———————————")
m=dict.fromkeys("ljs",250)#初始化一个 字典
n=m.copy()
print(m)
print(n)7.5字典嵌套
字典里面的键值也为字典
print("———————— 字典 嵌套1———————————")
d={"张三":{"语文":60,"数学":60,"英语":60},"李四":{"语文":70,"数学":70,"英语":70}}
print(d)
print(d["张三"]["数学"])
print("———————— 字典 嵌套2———————————")
d={"张三":[60,70,80],"李四":[600,700,800]}
print(d)
print(d["张三"][1])#输出张三的 下标 17.6字典推导式
通过 for 循环加上字典,能够更快的得到新的 字典
print("———————— 字典 推导式———————————")
d={"a":1,"b":2,"c":3}
b={v:k for k,v in d.items()}
print(d)
print(b)
print("———————— 字典 推导式+判断条件———————————")
d={"a":1,"b":2,"c":3}
b={v:k for k,v in d.items() if v<=2}#第一个v:k代表v为键,k为键值,实习交换是因为里面的k,v顺序和v:k不一样
print(d)
print(b)
print("———————— 字典 推导式嵌套+判断条件————————————")
d={x:y for x in [1,2,3] for y in [2,4,6] if y<5}
print(d)8.集合
8.1集合创建
方法:(1){字符串}
(2)推导式 s for s in “ljs"
(3)set 函数 a = set(”ljs“)
注意事项:(1)集合不能使用下标访问,因为集合是无序的
print("——————————集合创建方式1————————")
a={"ljs","lcc"}
print(type(a))
print("——————————集合创建方式2————————")
{s for s in "ljs"}
print("——————————集合创建方式3———————")
s=set("ljs")
print(s)8.2集合唯一性
8.2.1
判断某个元素是否存在集合中
print("——————————集合in ———————")
s=set("ljs")
print('s' in s)
print("——————————集合not in ———————")
s=set("ljs")
print('s' not in s)8.2.2 集合内容访问
通过推导式进行访问
print("——————————集合元素访问 ———————")
s=set("ljs")
for each in s:
print(each)8.2.3集合内容去重
由于集合具有元素不重复的特点,所以可以对一个列表进行集合设置,从而实现去掉重复值
print("——————————集合元素去重 ———————")
s=list("ljsljs")
print(s)
s=set(s)
print(s)8.3集合函数生成新集合

8.3.1 copy
实现集合的浅拷贝
print("——————————集合函数 copy ———————")
d=set("abc")
print(d)
t=d.copy()
print(t)
8.3.2 isdisjoint
判断两个集合是否相干(是否存在交集)
print("——————————集合函数 isdisjoint ———————")
s=set("ljs")
print((s.isdisjoint(set("lcc"))))#这里lcc和ljs具有交集 l 所以相干,所以是false
8.3.3 issubset
判断一个集合是否是另外一个集合的子集之后返回一个新集合
注意事项:(1)可以用 s <= set(“LJS”)来判断 s 是不是 LJS 的子集
(2)可以用 s < set(“LJS”)来判断 s 是不是 LJS 的真子集
(3)可以用 s >= set(“LJS”)来判断 s 是不是 LJS 的超集
(4)可以用 s > set(“LJS”)来判断 s 是不是 LJS 的真超集
(5)可以用 s | set(“LJS”)来判断 s 是不是 LJS 的并集
(6)可以用 s & set(“LJS”)来判断 s 是不是 LJS 的交集
(7)可以用 s - set(“LJS”)来判断 s 是不是 LJS 的差集
(8)可以用 s ^ set(“LJS”)来判断 s 是不是 LJS 的对称差集
print("——————————集合函数 issubset ———————")
d=set("abc")
print((d.issubset("abcd")))
8.3.4 issuperset
判断一个集合是否是另外一个集合的超集之后返回一个新集合(if B中容易元素都是 A的元素,则A为B超级)
print("——————————集合函数 issuperset ———————")
d=set("abcdef")
print((d.issuperset("abcd")))
8.3.5 union
把两个集合求并集之后返回一个新集合
print("——————————集合函数 union ———————")
q1=set("abcdef")
print((q1.union("gh","pl")))
8.3.6 intersection
求两个集合交集之后返回一个新集合
print("——————————集合函数 intersection ———————")
q1=set("abcdef")
print((q1.intersection("ach")))
8.3.7 difference
求两个集合的差集之后返回一个新集合
print("——————————集合函数 difference ———————")
q1=set("abcdef")
print((q1.difference("abgh")))
8.3.8 symmetric_differnece
求两个集合对称差集之后返回一个新集合(排除两个集合共有元素,由剩余元素组成的结合叫对称差集)
print("——————————集合函数 symmetric_difference ———————")
q1=set("abcdef")
print((q1.symmetric_difference("abgh")))8.4 集合函数修改原集合
8.4.1 update
对集合进行数据(列表,字符串)插入
注意事项:(1)只能 set 不能 frozenset
(2)修改当前集合
(3)之前没有 update 的是返回一个修改之后的新集合,有 update 的是直接修改原集合
print("—————————set函数 updtae—————————————————")
x = set("ljs")
x.update(set("and"))
print(x)
8.4.2 intersection_update
与 intersection功能一样,区别在于没有返回值,是对原集合进行修改
print("—————————set函数 intersection_updtae—————————————————")
x = set("ljs")
x.intersection_update(set("andl"))
print(x)
8.4.3 difference_update
与 difference功能一样,区别在于没有返回值,是对原集合进行修改
print("—————————set函数 differnce_updtae—————————————————")
x = set("ljs")
x.difference_update(set("and"))
print(x)
8.4.4 symmetric_difference_update
与 symmetric 功能一样,区别在于没有返回值,是对原集合进行修改
print("—————————set函数 symmetric_difference_updtae—————————————————")
x = set("ljs")
x.symmetric_difference_update(set("andl"))
print(x)8.4.5 add
将传入的字符串整体传入,而不是 update一样分开一个一个传入
print("—————————set函数 add—————————————————")
x = set("ljs")
x.add("andl")
print(x)8.4.6 remove
删除集合中某个元素,如果元素不存在则抛出异常
print("—————————set函数 remove—————————————————")
x = set("ljs")
x.remove("l")
print(x)
8.4.7 discard
删除集合中某个元素,如果元素不存在则静默处理
print("—————————set函数 discard—————————————————")
x = set("ljs")
x.discard("al")
print(x)
8.4.8 pop
随机弹出集合中的一个元素
print("—————————set函数 pop—————————————————")
x = set("aljs")
x.pop()
print(x)
8.4.9 clear
清空集合内容
print("—————————set函数 clear—————————————————")
x = set("aljs")
x.clear()
print(x)8.5可哈希
8.5.1基本概念
哈希值就像一个人的身份证,不同人的身份证不一样。并且人发生了变化,哈希值也会变化,所以可以通过哈希值对内容较大的数据进行控制
8.5.2语法
hash(object)获取 object 的哈希值
注意事项:(1)对于整数求哈希值,永远是其本身
(2)对于 1 和 1.0 的哈希值一样,但 1.01就不一样
(3)可变对象(列表,集合)没有哈希值
(4)不可变对象(字符串)有哈希值
(5)只有可哈希的对象才能作为字典的键以及集合元素
(6)要实现集合嵌套,不能用 set 而要用 frozenset 因为这是不可变集合
8.6散列表
可以快速的在列表进行查找里面的元素,比如说 列表是新华字典里面一页一页的找相同的字。而集合上则是按拼音进行查找。但集合也需要大量内存空间!
9.函数
9.1函数基本概念
9.1.1函数定义
def 函数名():
pass
print("————————函数定义————————————")
def myfunc():
# pass#空执行
for i in range(3):
print("ljs",end=' ')
myfunc()
print("\n")9.1.2函数的参数
print("————————函数参数————————————")
def myfunc(name,times):
# pass#空执行
for i in range(times):
print(F"ljs{name}",end=' ')
myfunc(" and lcc",2)
print("\n")9.1.3函数的返回值
函数如果没写 return 也会默认返回一个 none
print("————————函数返回值————————————")
def div(x,y):
if(y==0):
return "除数不能为0!!!"
else:
return x/y
result=div(4,2)
print(result)
print("\n")9.2函数参数
9.2.1位置参数
根据参数位置是确定的,如果不按照这个顺序输入,结果就会不一样
def myfunc(s,vt,o):
return "".join((o,vt,s))#返回一个字符串,并且这个字符串调用了 join函数进行字符串拼接
print(myfunc("我","打","你"))
9.2.2关键字参数
根据参数名字确定,跟位置没关系
print("—————————关键字参数———————————————")
def myfunc(s,vt,o):
return "".join((o,vt,s))#返回一个字符串,并且这个字符串调用了 join函数进行字符串拼接
print(myfunc(o="我",vt="打",s="你"))
print()9.2.3默认参数
默认参数必须放在后面,不能放在前面
注意事项:(1)对于一些函数,例如 sum abs 是不允许进行关键字参数,只能位置传递。
abs(x=-1)❌ abs(-1)✔
(2)关键字参数看 * 位置参数看 /


print("—————————默认参数———————————————")
def myfunc(s,vt,o="我"):
return "".join((o,vt,s))#返回一个字符串,并且这个字符串调用了 join函数进行字符串拼接
print(myfunc("你","打","刘家森"))
print()9.2.4收集参数
定义:传入参数的数量随意,这样的参数叫收集参数
语法:* 形参名字
注意事项:(1)函数返回的多参数其实本质是元组,这个元组可以进行解包
(2)函数传入的收集参数本质是元组,利用了 * 进行打包
(3)如果收集参数后面还需要参数,那就必须用关键字参数
(4)利用 ** 两个 * 可以实现对收集参数进行 打包为字典
print("—————————收集参数———————————————")
def myfunc(*args):
print("有{}个参数".format(len(args)))
print("第2个参数是:{}".format(args[1]))
print("所有参数:{}".format(args))
myfunc("刘家森","罗灿灿","爱吃东西","哈哈哈","喵喵喵")
print()
print("—————————收集参数+关键字参数———————————————")
def myfunc(*args,a=1,b=2):
print("所有参数:{}".format(args),a,b)
myfunc("刘家森","罗灿灿")
print()
print("—————————收集参数 ** ———————————————")
def myfunc(**args):
print(args)
myfunc(a=1,b=2)
print()9.2.5解包参数
为了实现传入的元组进行解包成单独模块
注意事项:(1) * 代表对元组进行解包
(2)** 代表对字典进行解包
print("—————————解包参数 * ———————————————")
args=(1,2,3,4)
def myfunc(a,b,c,d):
print(a,b,c,d)
myfunc(*args)#对 args 进行解包
print()
print("—————————解包参数 ** ———————————————")
args={'a':1,'b':2,'c':3,'d':4}
def myfunc(a,b,c,d):
print(a,b,c,d)
myfunc(**args)#对 args 进行解包为 键值
print()9.3函数作用域
9.3.1局部作用域
指一个变量可以被访问的范围。当一个变量被定义在函数内部中,这个变量称为局部变量
print("—————————作用域 局部 ———————————————")
def myfunc():
x=520
print(x)
myfunc()
#print(x)这是一个局部变量,无法在全局中访问
9.3.2全局作用域
定义在函数外部的变量,作用域为全局,这个变量称为全局变量
print("—————————作用域 全局 ———————————————")
x = 520
def myfunc():
x=250
print(x)
myfunc()
print(x)#这是一个全局变量,无法在全局中访问9.3.3语句 global
在局部变量前加一个 global 可以实现 局部变量修改全局变量的值
print("—————————作用域 global ———————————————")
x = 520
def myfunc():
global x
x=250
print(x)
myfunc()
print(x)9.4嵌套函数
9.4.1嵌套函数定义
在一个函数内部在定义一个函数。在使用内部函数时,需要在内部提取调用
print("—————————嵌套函数 ———————————————")
def myfunc():
x=520
def myfund():
x=250
print("d:x=",x)
myfund()#嵌套函数需要在函数内部中 调用,外部不能调用
print("c:x=",x)
myfunc()
print()9.4.2语句 nonlocal
在内部函数中去修改外部函数的变量
print("—————————嵌套函数 nonlocal———————————————")
def myfunc():
x=520
def myfund():
nonlocal x
x=250
print("d:x=",x)
myfund()#嵌套函数需要在函数内部中 调用,外部不能调用
print("c:x=",x)
myfunc()
print()9.5 LEGB规则
L:local 局部作用域,局部作用域会消失
E:enclosed 嵌套函数外层函数作用域 外层作用域的值会保留下来
G:global 全局作用域
B:build-in 内置作用域 相当于内置函数变为了变量名
当作用域发生冲突时,例如 L 和 G,则 python 会使用 L 局部作用域
10.闭包
10.1闭包基本定义
简单解释就是说,内层函数调用了外层函数的变量,并且外层函数返回的是内存函数的引用。这样子就可以实现对一个变量重复改变使用。举个例子,一个点在坐标移动,它往右移动之后得到新坐标,这时再往上移动不是从原点出发,而是从第一次移动后的点
print("—————————闭包———————————————")
def power(exp):
def exp_of(base):
return base ** exp
return exp_of
square=power(2)
cube=power(3)
print(square(2))
print(square(5))
print(cube(2))
print(cube(5))
print("—————————闭包 nonlocal———————————————")
def outer():
x=0
y=0
def inner(x1,y1):
nonlocal x,y
x+=x1
y+=y1
print(F"x={x},y={y}")
return inner
move=outer()
print(move(1,2))
print(move(-1,2))
11.装饰器
11.1单装饰器
作用:在闭包基础之上,把函数的传入参数也设置为函数,这样就相当于先执行闭包的内层函数,再碰到外层的传入函数时,就执行调用的函数。
本质:再调用函数的时候,相当于把调用函数放进了装饰器里面!
语法(1):def 外层()+内层() return 内层
@外层
def 调用函数()
调用函数()
语法(2):def 外层()+内层() return 内层
def 调用函数()
调用函数 = 外层(调用函数)
调用函数()
rint("—————————函数作为参数传递 装饰器 ———————————————")
def time_master(func):
def call_func():
print("开始运行")
start=time.time()
func()
stop=time.time()
print("程序结束")
print(F"消耗{(stop-start):.2f} 秒")
return call_func
@time_master
def myfunc():
time.sleep(2)
print("正在运行")
myfunc()11.2多装饰器
在被调用函数上存在多个装饰器,调用顺序从下往上
print("—————————函数作为参数传递 多装饰器 ———————————————")
def add(func):
def inner():
x=func()
return x+1
return inner
def cube(func):
def inner():
x=func()
return x*x*x
return inner
def square(func):
def inner():
x=func()
return x*x
return inner
@add
@cube
@square
def test():
return 2
print(test())11.3装饰器+输入参数
语法(1):@外层函数(参数) 调用函数()
语法(2):调用函数=外层(参数)(调用函数)
print("—————————函数作为参数传递 装饰器+输入参数 ———————————————")
def logger(msg):
def time_master(func):
def call_func():
print("开始运行")
start = time.time()
func()
stop = time.time()
print("程序结束")
print(F"消耗{(stop - start):.2f} 秒")
return call_func
return time_master
@logger("A")
def funA():
time.sleep(1)
print("A")
@logger("B")
def funB():
time.sleep(2)
print("B")
funA()
funB()12.lambda表达式
作用:解决一些简单的函数
语法:lambda arg1 arg2 : expression
print("—————————lambda基本规则———————————————")
square = lambda x : x*x
print(square(2))
print("—————————lambda—+列表———————————————")
y=[lambda x:x*x,2,3]
square=y[0](y[1])
print(square)
print("—————————lambda—+map———————————————")
mapped=map(lambda x:ord(x)+10,"Fljs")
print(list(mapped))
print("—————————lambda—+filter———————————————")
mapped=filter(lambda x:x%2,range(10))
print(list(mapped))13.生成器
13.1生成器基本规则
作用:让函数退出之后还能保留状态,是一种特殊的迭代器
语法:yield 替换 return
print("——————————yield基本规则————————————")
def counter():
i=0
while(i < 5):
yield i
i+=1
for i in counter():
print(i)
print("——————————yield+next————————————")
c=counter()
print(next(c))
print(next(c))
print(next(c))
13.2生成器表达式
区别:列表推导式:一次性生成所有数据放到列表中
生成器推导式:一次只产生一个数据
方法:(1)使用 yield
(2)直接写
print("——————————生成器直接表达式————————————")
t=(i*i for i in range(5))
for i in t:
print(i)14.算法
14.1递归
14.1.1递归基本规则
作用:函数调用自身的过程
print("———————递归基本规则-无限循环———————————")
# def func():
# print("ljs")
# func()
# print(func())
print("———————递归基本规则-条件循环———————————")
def func(i):
if i>0:
print(F"ljs{i}")
i-=1
func(i)
print(func(10))14.1.2递归-阶层
print("———————递归基本规则-阶层1———————————")
def factIter(n):
result=n
for i in range(1,n):
result *=i
return result
print(factIter(5))
print("———————递归基本规则-阶层2———————————")
def factIter(n):
if n==1:
return 1
else:
return n*factIter(n-1)
print(factIter(5))
14.1.3递归-斐波那契数列
print("———————递归基本规则-斐波那契数列迭代———————————")
def fib(n):
a=1
b=1
c=1
while(n>2):
c=a+b
a=b
b=c
n -=1
return c
print(fib(12))
print("———————递归基本规则-斐波那契数列递归———————————")
def fibc(n):
if n==1 or n==2:
return 1
else:
return fibc(n-1)+fibc(n-2)
print(fibc(12))14.2汉诺塔
def hanoi(n,x,y,z):
if n==1:
print(x,'-->',z)
else:
hanoi(n-1,x,z,y)
print(x,'-->',z)
hanoi(n-1,y,x,z)
n=int(input("次数"))
hanoi(n,'A','B','C')