编译原理复习 第一章 概述
文章目录
- Chapter1 概述
-
- 1.1 什么是编译程序
-
- 定义
- 语言
- 应用
- 语言处理过程
- 语言转变系统
- 编译程序和解释程序比较
- 1.2 编译过程和编译程序结构
-
- 词法分析
- 语法分析
- 语义分析
- 中间代码生成
- 代码优化
- 目标代码生成
- 符号表管理
- 出错处理
- 编译程序结构
- 1.3 编译阶段的组合
-
- 内容
- 分遍(趟, pass)问题
- 高级语言解释系统
-
- 解释系统
- 编译阶段和运行阶段存储结构
- 解释系统存储结构
- 编译程序设计要求
- 1.4 PL/0 编译程序
-
- 结构
- 程序实例
- 程序图
- PL/0 语言文法
- 目标代码类pcode
Chapter1 概述
1.1 什么是编译程序
定义
编译程序是现代计算机系统的基本组成部分
功能:

语言
- 低级语言
- 机器语言:计算机指令系统
- 汇编语言:符号化的指令系统
- 高级语言:算法语言,不依赖具体机器,面向问题
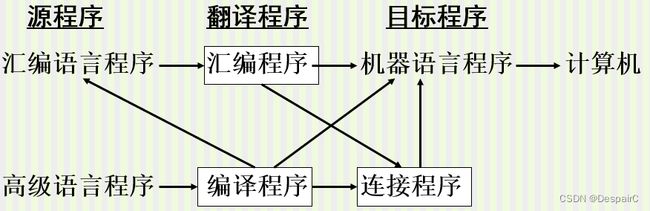
应用
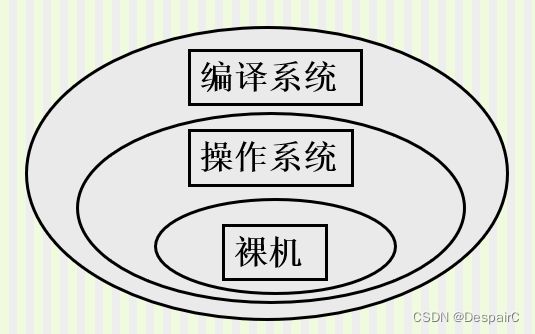
分类:
- 软件
- 计算机系统中的程序及其文档
- 系统软件
- 居于计算机系统中最靠近硬件的一层,其他软件一般都通过系统软件发挥作用。他和具体的应用领域无关,如编译系统和操作系统等。
- 语言处理系统
- 把软件语言书写的各种程序处理可在计算机上执行的程序
- 软件语言
- 用于书写软件的语言。它主要包括需求定义语言,功能性语言,设计性语言,程序设计语言以及文档语言
语言处理过程

语言转变系统
| 源语言 | 实现语言 | 目标语言 |
|---|---|---|
| C++ | C++编译器 | C |
| Java | Java编译器 | Bytecode |
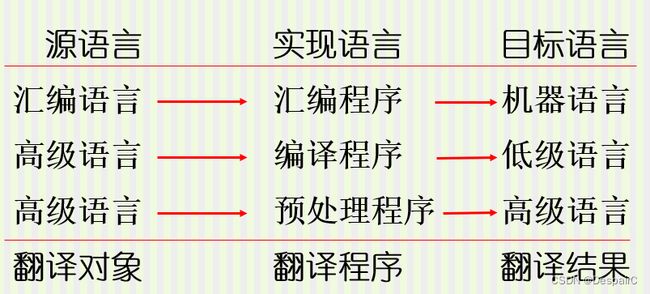
编译程序和解释程序比较

1.2 编译过程和编译程序结构
编译逻辑过程:
词法分析
字符序列 -> 单词序列
扫描、分解源程序,识别单词(记本子、标识符、常数、运算符、界限符),并给予种别(属性)和内部形式(值),构成单词的内部表示。
从左到右读字符流的源程序,识别单词
例子1:
position := initial + rate * 60;
词法分析:
| 单词类型 | 单词值 |
|---|---|
| 标识符1(id1) | position |
| 算符(赋值) | := |
| 标识符2(id2) | initial |
| 算符(加号) | + |
| 标识符3(id3) | rate |
| 算符(乘) | * |
| 整数 | 60 |
| 分号 | ; |
例子2:C 源程序片段
int a;
a = a + 2;
词法分析:
| 单词类型 | 单词值 |
|---|---|
| 保留字 | int |
| 标识符(变量名) | a |
| 界符 | ; |
| 标识符(变量名) | a |
| 算符(赋值) | a |
| 标识符(变量名) | a |
| 算符(加) | + |
| 整数 | 2 |
| 界符 | ; |
语法分析
分析器(Analyzer)
功能:层次分析。依据源程序的语法规则把源程序的单词序列组成语法短语(表示成语法树)
position := initial + rate * 60 ;(";"为语句分隔符)
规则
<赋值语句> ::= <标识符> ":=" <表达式>
<表达式> ::= <表达式> "+" <表达式>
<表达式> ::= <表达式> "*" <表达式>
<表达式> ::= "("<表达式>")"
<表达式> ::= <标识符>
<表达式> ::= <整数>
<表达式> ::= <实数>
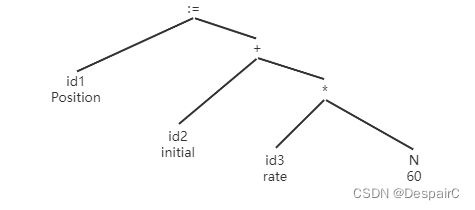
语法树模板:

举例:
id1 := id2 + id3 * N
画图:
其他例子:

语义分析
语义审查(静态词义)
- 上下文相关性
- 类型匹配
- 类型转换
例1:
program p();
var rate:real;
procedure initial;
...
position := initial + rate * 60;
/* error */ /* error */ /* warning */
...
例2:
int arr[2], abc;
abc = arr * 10;
...
program p();
var rate:real;
var initial:real;
var position:real;
...
position := initial + rate * 60;

中间代码生成
便于代码优化,
便于从逻辑上分出与语言或机器无关的阶段
源程序的内部(中间)表示
三元式、四元式、P-Code、C-Code、U-Code、bytecode
(* id3 t1 t2)
t2 = id3 * t1
t2 := id3 * t1
举例:
id1 := id2 + id3 * 60
(1) (inttoreal, 60, -, t1) 实数,值为60,无,赋给t1
(2) (*, id3, t1, t2) 乘,运算值id3, 运算值t1,赋值给t2
(3) (+, id2, t2, t3) 加,运算值id2, 运算值t2,赋值给t3
(2) (:=, t3, -, id1) 赋值, 标识符t3, 无, 赋值给id1
代码优化
局部优化:
- 合并已知量 -> 编译时减少常量表达式
- 改变计算顺序 -> 减少指令、减少中间量
- 共享子表达式 -> 删除多余代码
- 降低运算强度 -> 乘方 --> 乘
循环优化:
- 循环不变部分外提
- 下标地址计算优化
- 降低运算强度-> 乘 --> 加
与机器有关的优化:
- 使用特殊指令 -> 如计数转移指令寄存器分配
举例1:
id1 := id2 + id3 * 60
未优化:
(1) (inttoreal, 60, -, t1) 实数,值为60,无,赋给t1
(2) (*, id3, t1, t2) 乘,运算值id3, 运算值t1,赋值给t2
(3) (+, id2, t2, t3) 加,运算值id2, 运算值t2,赋值给t3
(2) (:=, t3, -, id1) 赋值, 标识符t3, 无, 赋值给id1
优化后:
(1) (*, id3, 60.0, t1) 乘,运算值id3, 实数60,赋值给t1
(2) (+, id2, t1, id1) 加,运算值id2, 运算值t1,赋值给id1
举例2:
源代码:
t1 = b * c
t2 = t1 + 0
t3 = b * c
t4 = t2 + t3
a = t4
优化后:
t1 = b * c
t2 = t1 + t1
a = t2
目标代码生成
(* id3 60.0 t1 )
(+ id2 t1 id1)
生成代码:
movf id3, R2
mulf ##60.0, R2
movf id2, R1
addf R2, R1
movf R1, id1
符号表管理
-
记录源程序中使用的名字
-
收集每个名字的各种属性信息
-
类型、作用域、分配存储信息
Const1 常量 值:35
Var1 变量 类型:实 层次:2
-
出错处理
- 检查错误
- 报告出错信息
- 排错
- 恢复编译工作
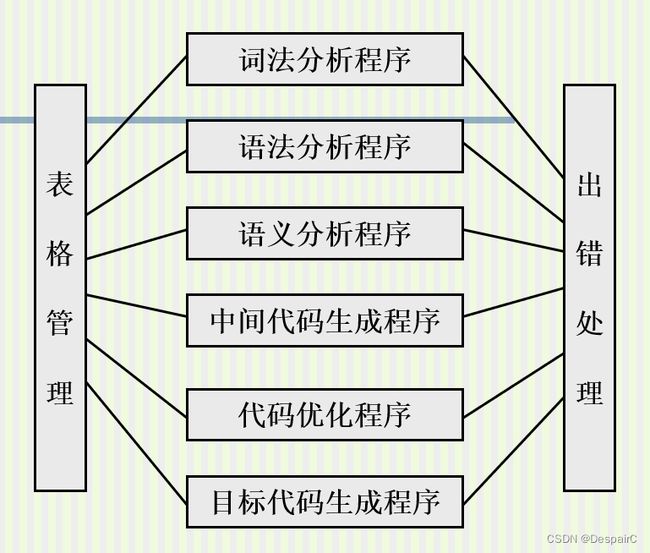
编译程序结构
Components
- 词法分析程序
- 语法分析程序
- 语义分析程序
- 中间代码生成程序
- 代码优化程序
- 目标代码生成程序
- 符号表管理程序
- 出错处理程序
1.3 编译阶段的组合
内容
- 分析、综合
- 源程序的分析
- 线性分析
- 层次分析
- 语义分析
- 目标程序的综合
- 源程序的分析
- 编译的前端
- -----------------------------------------------以中间代码为界
- 编译的后端
- 遍(趟)从头到尾扫描源程序(各种形式)一遍(pass)
分遍(趟, pass)问题
在编译过程中,扫描源(中间)程序的次数成为该编译程序的"遍"数。决定分遍次数的因素有:
-
源语言
FORTRAN、Pascal等,只需要单遍扫描
ALGOL60 要两遍扫描
ALGOL68 要三遍扫描
若允许先使用、后说明,则通常需要多遍扫描。
-
机器,尤其是内外存的大小,内存小,可能需要多遍
-
优化要求。充分优化需要多遍

总结:多遍的结构清晰,优化好,但重复工作多,输入输出多,编译器本身代码长,且编译速度慢,出错处理较困难。
本书的PL/0编译器就是一个单遍编译器。
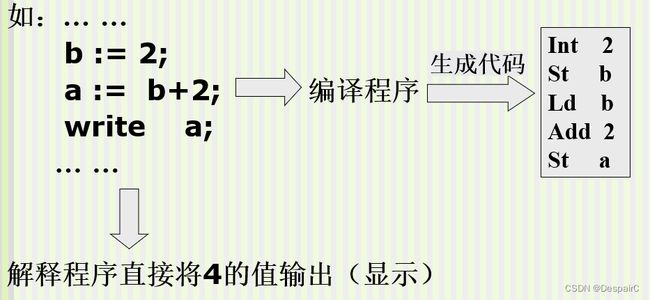
高级语言解释系统
- 功能:让计算机执行高级语言
- 与编译程序的不同
- 不生成目标代码
- 能支持交互环境(同增量式编译系统)
- 源程序和初始数据 通过 解释程序 得到 计算结果
解释系统
直接对源程序中的语句进行分析,执行器隐含的操作
编译阶段和运行阶段存储结构

解释系统存储结构

编译程序设计要求
- 目标程序运行速度快
- 目标程序短
- 编译程序快
- 编译空间 -> 小 / 充分利用内存
- 诊断、矫正错误的功能性强
1.4 PL/0 编译程序
结构
| 源语言 | 实现语言 | 目标语言 |
|---|---|---|
| PL/0 | C/pascal | 类 pcode |

程序实例
CONST A = 10; // 常量说明部分
VAR B,C; // 变量说明部分
PROCEDURE P; // 过程说明部分
VAR D;
PROCEDURE Q;
VAR X;
BEGIN |
READ(X); |
D:=X; | // Q的过程体
WHILE X#0 DO |
CALL P; |
END;
BEGIN |
WRITE(D); | // P的过程体
CALL Q; |
END;
BEGIN |
CALL P; | // 主程序体
END. |
同PASCAL
作用域规则:内层可引用包围它的外层定义的标识符,上下文约束
过程可嵌套定义,可递归调用
子集:
- 数据类型,只有整型
- 数据结构,只有简变和常数
- 数字最多为14位
- 标识符的有效长度为10
- 语句种类
- 过程最多可嵌套三层
程序图
程序图画图图形:

程序图画图实例:
PL/0 语言文法
EBNF引入的符号(元符号):
| 符号 | 定义 |
|---|---|
| < > | 用左右尖括号括起来的语法成分为非终结符 |
| ∷= (→) | ∷=(→)的左部由右部定义 |
| | | 或 |
| { } | 表示花括号内的语法成分可重复任意次或限 |
| [] | 表示方括号内的语法成分为任选项 |
| () | 表示圆括号内的成分优先 |
用 EBNF 描述<整数>的定义
<整数> ::= [+|-] <数字> {<数字>}
<数字> ::= 0|1|2|3|4|5|6|7|8|9
或者更好的写法
<整数> ::= [+|-]<非零数字>{<数字>}|0
<非零数字>::=1|2|3|4|5|6|7|8|9
<数字>::=0|<非零数字>
目标代码类pcode
目标代码类pcdoe是一种假想式计算机的汇编语言
指令格式
| f | l | a |
|---|
- f:功能吗
- l:层次码(标识符引用层去定义层)
- a:根据不同指令有所区别