平衡二叉树、跳跃表
平衡二叉树、跳跃表
- 平衡二叉树介绍(AVL树、红黑树)
-
- 二叉搜索树Binary Search Tree
- 单旋转
- AVL树
- AVL树–平衡因子
- 插入
- 旋转场景一:LL
- 旋转场景二:RR
- 旋转场景三:LR
- 旋转场景四:RL
- 旋转
- 再举个栗子
- 插入
- RL-先右旋
- RL-再左旋
- 平衡
- 红黑树
- 实战:跳表———Redis内部的数据结构
-
- 跳表
- 添加第一级索引
- 添加第二级索引
- 添加多级索引
- 查询
- 空间复杂度
- 插入
- 随机建立索引
- 删除
- 现实中跳表的形态
- 实战:树堆——最容易实现的平衡树之一
-
- 随机的艺术
- Treap = Tree + Heap
- BST–检索
- BST–求前驱/后继
- 插入/删除
- 插入0,再删除0
- 插入
- 旋转
- 实战
-
- 1206.设计跳表
平衡二叉树介绍(AVL树、红黑树)
二叉搜索树Binary Search Tree
二叉搜索树(Binary Search Tree)是一棵满足如下性质(BST性质)的二叉树:
- 任意结点的关键码≥它左子树中所有结点的关键码
- 任意结点的关键码≤它右子树中所有结点的关键码
根据以上性质,二叉搜索树的中序遍历必然为一个有序序列

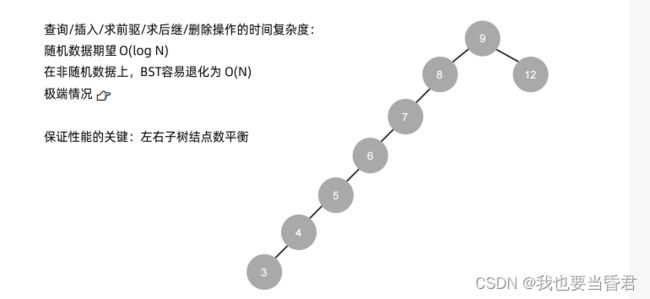
单旋转
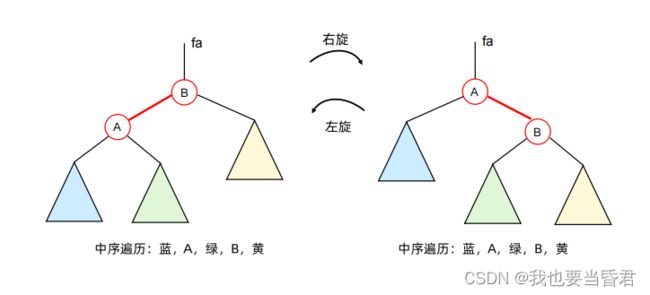
AVL树
平衡因子Balance Factor :
- 一个结点的左子树的高度减去它的右子树的高度。
AVL树
- 任意结点的平衡因子的绝对值都不超过1,即 balance factor E{-1,0,1}
- 每个结点需要保存:原始数据、左子结点、右子结点、子树高度
AVL树在插入、删除时,沿途更新结点的高度值
当平衡因子的绝对值大于1时,触发树结构的修正,通过旋转操作来进行平衡
AVL树–平衡因子

插入



旋转场景一:LL

旋转场景二:RR
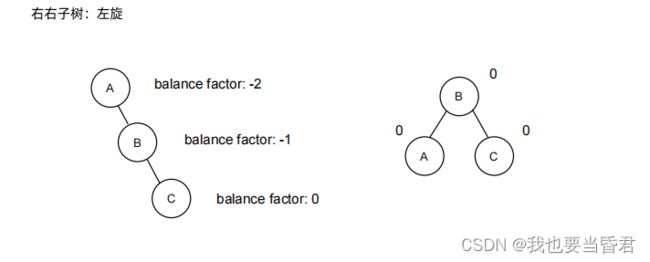
旋转场景三:LR

旋转场景四:RL

旋转


再举个栗子

插入

RL-先右旋
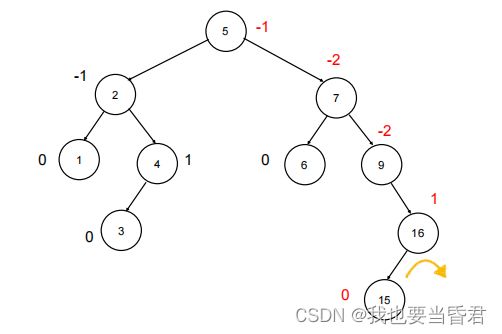
RL-再左旋
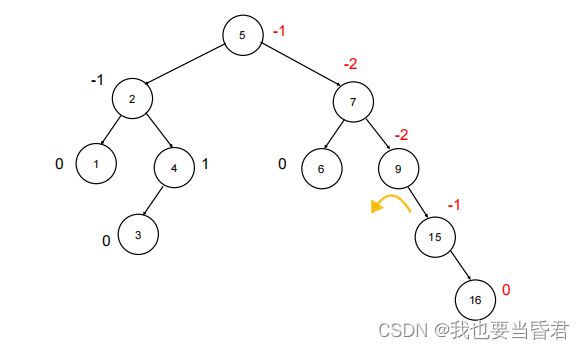
平衡

红黑树
红黑树(Red-black Tree)是一种近似平衡的二叉搜索树
- 从根到叶子的最长路径≤2*最短路径(简记:高度差在2倍以内)
规则:
- 每个结点要么是红色,要么是黑色
- 根结点是黑色
- 最底层视作有一层空叶结点,是黑色的
- 不能有两个相邻的红色结点
- 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点


规则被打破时,通过变色或旋转操作来修正
有非常多的情况需要讨论,这里就不再讲了
相比AVL树,红黑树插入删除更快(旋转少)、更省空间(颜色vs平衡因子)
查询稍慢(不如AVL树更加平衡)
红黑树是许多语言中有序集合、有序映射(例如C++ set, map)的内部实现方式
实战:跳表———Redis内部的数据结构
跳表
跳表(Skip List)是对元素有序的链表的优化,对标的是平衡树和二分查找
- 二分查找:可以在数组上O(logN)查询,不可修改序列(不能用于链表)
- 平衡树:支持高效的查询、插入、删除,但比较复杂,不容易实现
跳表是一种查询、插入、删除都是O(logN)的数据结构,
其特点是原理简单、容易实现、方便扩展、效率优秀,在 Redis、LevelDB等热门项目中用于代替平衡树。
链表插入、删除都是O(1),但查询很慢——O(N)
跳表的核心思想:如何提高有序链表的查询效率?
添加第一级索引

添加第二级索引
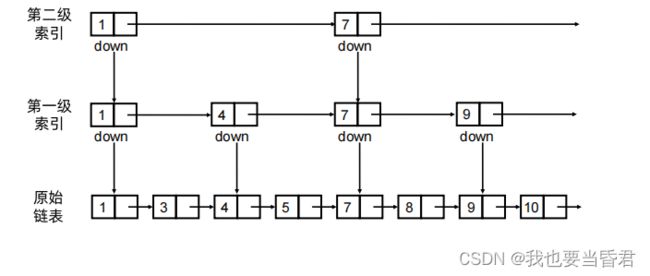
添加多级索引

查询
- 从最高级索引、头元素起步
- 沿着索引查找,直至找到一个大于或等于目标的元素,或者到达索引末尾
- 如果该元素等于目标,则表明目标已被找到,算法结束
- 如果该元素大于目标或已到达末尾,则回到当前索引的上一个元素,转入下一级索引,重复2

在一次查询中,每一层至多遍历3个结点
- 最高级索引只有2个结点
- 每一级索引遍历的第3个结点必然大于目标——不然的话在上一级索引中应该走得更远才对
- 时间复杂度≤3*层数=O(logN)

空间复杂度
索引的层数:o(logN)
每层索引的结点数:N/2+N/4 +N/8+ …
空间复杂度:O(N)
也可以每3个结点建一个索引
这样可以节省一点空间,但相应地造成查询效率略微下降(每层至多遍历3个结点→4个)
复杂度不变,常数有变化(时间和空间的平衡)
插入
先查询,再插入?
问题:插入很多次后,一个索引结点代表的结点数量会增多,如果不更新索引,时间复杂度会退化
解决方案:
重建?——效率太低!
在每个结点上记录它代表的下一级结点个数?——需要维护额外信息,实现复杂
跳表选择的方案是:利用随机+概率!
随机建立索引
现实中的跳表不限制“每2个结点建立一个索引”,而是:
- 在原始数据中随机n/2个元素建立一级索引
- 在一级索引中随机n/4个元素建立二级索引
- 在二级索引中随机n/8个元素建立三级索引
- …
当元素足够多时,可以期望随机出来的索引分布比较均匀
查询的时间复杂度依旧是O(logN)
删除
删除元素很简单,还是基于查询
在此过程中把原始链表和各级索引中对应的结点(如果有的话)都删掉就行了
时间复杂度O(logN)
现实中跳表的形态

https://redisbook.readthedocs.io/en/latest/internal-datastruct/skiplist.html
实战:树堆——最容易实现的平衡树之一
随机的艺术
在数据足够多的情况下,“随机”就是最自然、趋于平衡的
- 快速排序“随机”选取中轴(pivot),按大小分成两半,期望层数O(logN)
- 在一条数轴上随机撒点,点的期望分布是均匀的
- 跳表通过随机来选取索引元素,以及决定是否更新索引
- 把一组随机数据插入二叉搜索树(BST),期望是平衡的,即O(logN)层
对BST的结点进行旋转,不影响数据的有序性,可以让树变得更加平衡
问题:如何决定要不要旋转?
思路:产生一组额外的随机数据,让它们满足某种性质,从而形成一个趋于平衡的树结构
Treap = Tree + Heap
树堆(Treap)的每个结点保存两个值
- 原始数据,也叫关键码
- 额外的权值,是随机生成的
树堆首先是一棵二叉搜索树,结点的关键码(原始数据)满足BST性质:左≤根≤右
树堆也是一个堆,结点的额外权值满足大根堆形式:父≥子
Treap各项操作的时间复杂度均为O(logN)
Treap检索、求前驱、求后继的操作与普通BST一致——一次递归查找
BST–检索

BST–求前驱/后继

插入/删除
Treap先通过类似于BST的检索,找到需要插入新结点的位置
插入后,给新结点随机生成一个额外的权值
然后像二叉堆的插入过程一样,自底向上依次检查
当某个节点不满足大根堆性质时,就执行单旋转,使该点与其父节点的关系发生对换
删除时,首先通过检索找到需要删除的结点
由于Treap支持旋转,可以把需要删除的结点向下旋转成叶结点
最后直接删除
非常简便,避免了BST 删除操作对各种情况的讨论,也避免了维护堆性质
插入0,再删除0

插入

旋转

实战
1206.设计跳表
https://leetcode.cn/problems/design-skiplist/submissions/
constexpr int MAX_LEVEL = 32;
constexpr double SKIPLIST_P = 0.25;
struct Node {
int val;
vector<Node*> next;
Node(int val, int level) : val(val), next(vector<Node*>(level, nullptr)) {}
};
class Skiplist {
private:
int curLevel;
Node* head;
//生成1~maxLevel之间的数字. 且1/2概率返回2, 1/4概率返回3...
int randomLevel() {
int level = 1;
while (((double)rand() / (RAND_MAX)) < SKIPLIST_P && level < MAX_LEVEL) ++level;
return level;
}
public:
Skiplist() : curLevel(0), head(new Node(-1, MAX_LEVEL)) { //根据题目中num的取值范围, 我们让head值为-1即可保证head不会被更新
}
bool search(const int target) {
auto cur = head;
for (int i = curLevel - 1; i >= 0; --i) {
//找到第i层的最大的小于target的元素. 0层在下, max_level在上. 越下层的元素越多
while (cur->next[i] && cur->next[i]->val < target) cur = cur->next[i];
}
//已经到第0层了
cur = cur->next[0];
//检查当前元素的值是否等于target
return cur && cur->val == target;
}
void add(int num) {
//存放每层需要更新的位置. 我们先假设都更新的是head
vector<Node*> update(MAX_LEVEL, head);
auto cur = head;
for (int i = curLevel - 1; i >= 0; --i) {
//找到所有层的值小于num的最后一个结点
while (cur->next[i] && cur->next[i]->val < num) cur = cur->next[i];
update[i] = cur; //该节点即为num应当插入的位置的前驱节点
}
auto level = randomLevel(); //随机插入任意一层
curLevel = max(curLevel, level);
auto node = new Node(num, level); //创建要插入的节点, 其值为num, 其层级为randomLevel
//在所有预期的层级中插入随机出来的node. 从第0层开始插入到其可能的最上层!
for (int i = 0; i < level; ++i) {
node->next[i] = update[i]->next[i]; //与其后缀节点建立联系
update[i]->next[i] = node; //与其前驱结点建立联系
}
}
bool erase(int num) {
//记录每层要更新的位置. 依然假定要更新的为head
vector<Node*> update(MAX_LEVEL);
auto cur = head;
for (int i = curLevel - 1; i >= 0; --i) {
while (cur->next[i] && cur->next[i]->val < num) cur = cur->next[i];
update[i] = cur;
}
cur = cur->next[0]; //返回当前层的下一个节点
if (!cur || cur->val != num) return false; //若不存在num的节点, 则返回false
for (int i = 0; i < curLevel; ++i) {
if (update[i]->next[i] != cur) break; //从最下层开始向上遍历, 若有一层的后面的节点不为cur, 则说明cur没能进入这一层(以及更上层). 则我们可以直接退出循环
update[i]->next[i] = cur->next[i]; //更新当前层的节点. 在当前层中移除cur
}
delete cur; //我们可以将cur回收
while (curLevel > 1 && !head->next[curLevel-1]) --curLevel; //若当前的最上层已经只有一个head了, 则我们可以直接将当前层移除掉
return true;
}
};
https://ke.qq.com/course/417774?flowToken=1041943