ClickHouse 表引擎
一、引擎分类
| MergeTree系列 | LogTree系列 | 集成引擎 | 特定功能引擎 |
|---|---|---|---|
| 适用于高负载任务的最通用和功能最强大的表引擎。可以快速插入数据并进行后续的后台数据处理 1. MergeTree 2. ReplacingMergeTree 3. SummingMergeTree 4. AggregatingMergeTree 5. CollapsingMergeTree 6.VersionedCollapsingMergeTree 7. GraphiteMergeTree |
用于将数据快速写入大量小表(低于100万行)并整体 读取的场景 1. TinyLog 2. StripeLog 3. Log
|
集成引擎集成第三方的存储和系统来读写数据,ClickHouse本身不存储数据。 1. Kafka 2. MySQL 3. ODBC 4. JDBC 5. HDFS
|
1. Distributed
2. MaterializedView
3. Dictionary
4. Merge
5. File
6. Null
7. Set
8. Join
9. URL
10. View
11. Memory
12. Buffer
|
二、MergeTree引擎
MergeTree系列引擎是ClickHouse中最强大的表引擎。 数据按照片段被一批批写入表。 数据片段在后台按照一定的规则进行合并。
建表模板
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]建表语句
ENGINE : 引擎的名称和参数
PARTITION BY : 分区键
ORDER BY : 表的排序键
PRIMARY KEY : 表的主键
SAMPLE BY : 采样表达式
TTL : 定义行数据的存储时间,磁盘和卷之间数据片段的自动移动的逻辑。 SETTINGS: 控制MergeTree行为的额外参数。
1. index_granularity: 索引粒度,以行数为单位,表示索引标记(mark)之间的最大数据行数。默
认值:8192。
2. index_granularity_bytes: 索引粒度, 以字节为单位, 表示索引粒度的最大字节大小, 默认值:
10Mb。设置该参数为0, 将仅按行数限制索引粒度大小。
3. use_minimalistic_part_header_in_zookeeper : 数据片段(part)头在ZooKeeper中的存储方
法。设置为1,紧凑存储数据片段头信息,极大减少ZooKeeper的存储数据量。
4. storage_policy : 存储策略。 存储策略定义了使用多块设备进行数据存储的逻辑。
更多设置参数:参数列表及其功能参见表system.merge_tree_settings。
MergeTree参数的设置:
1. 表级别:在建表时设置。
2. 全局:config.xml的merge_tree标签内进行设置。
建表示例
1. 非分区表
CREATE TABLE merge_demo
(
srcip String,
destip String,
date_time DateTime
)
ENGINE = MergeTree()
ORDER BY srcip
SETTINGS index_granularity = 8192;
2. 分区表
CREATE TABLE merge_partition_demo
(
`srcip` String,
`destip` String,
`date_time` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(date_time)
ORDER BY srcip数据存储
checksums.txt:校验文件的正确性和完整性。
columns.txt:存储列的信息,包括数据类型。
count.txt : 存储分区目录下数据的总行数。
primary.idx : 存储索引数据的文件。稀疏索引,能够加速查询。
bin文件:存储数据的文件, 以压缩格式存储,默认LZ4。
mrk文件:存储列的数据标记的文件。
partiton.dat:存储存储分区表达式生成的值。使用二进制格式存储。该文件只在分区表中存储。
minmax_*文件: 存储能当前目录下, 分区字段对应的原始字段的最小和最大值。
skp_idx_*.idx、skp_idx_*.mrk: skip索引标记文件。
数据片段(data part)
一个表是由按主键排序的数据片段(part)组成
当向表中插入数据时, 将创建单独的数据片段
ClickHouse在后台合并数据片段以便更高效的存储
不会合并来自不同分区的数据片段。
表和列的TTL规则与实践表和列的TTL
定义值的生命周期
可以为整个表设置,也可以为每个单独的列设置
表级的TTL也可以指定在磁盘和卷之间自动移动数据的逻辑
设置TTL的表, 必须包含Date或DateTime类型的字段
定义数据的生命周期, 需要在这个日期字段使用操作符:
TTL time_column
TTL time_column + interval
示例:
TTL date_time + INTERVAL 1 MONTH
TTL date_time + INTERVAL 15 HOUR
列级TTL
当列中的值过期时, ClickHouse将它们替换为该列对应数据类型的默认值。
如果数据片段中的所有列值都过期, 则删除该数据片段下的该列的文件。
TTL子句不能用于key列。
示例:
1. 创建TTL的表
2. TTL过期验证
3. 给列增加TTL
4. 修改列的TTL
表级TTL
1. 表级的TTL定义了过期行的删除、磁盘和卷之间自动移动数据的逻辑。
2. 一张表可以定义一个过期行移除的表达式和多个磁盘和卷之间自动移动数据的逻
辑的表达式。
TTL expr [DELETE|TO DISK 'aaa'|TO VOLUME 'bbb'], ...
3. 当表中的数据过期时, ClickHouse删除所有对应的行。
4. TTL规则的类型跟在每个TTL表达式后面, 它表示表达式满足后(达到当前时间)
要执行的操作。
DELETE - 删除过期的行(默认操作);
TO DISK 'aaa' - 将片段移至磁盘aaa;
TO VOLUME 'bbb' - 将片段移动至磁盘bbb.
表级TTL
创建表示例:
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb';
SETTINGS storage_policy = 'moving_from_ssd_to_hdd';注意:当TTL表达式指定了磁盘和卷之间移动数据的逻辑, 那么ClickHouse的表必须指定存储策略, 且该
存储策略中要包含相应的磁盘和卷。
表级TTL
使用案例:TTL过期后执行数据删除案例。
数据删除说明:
1. 当ClickHouse合并数据片段时, 将删除TTL过期的数据。
2. 当ClickHouse发现数据过期时, 它将执行一个计划外的合并。 要控制这类合并的频率, 可设置参数
merge_with_ttl_timeout。如果该值设置的过低, 它将导致执行许多的计划外合并,这可能会消耗大量
资源。
3. 如果在合并的时候执行SELECT查询, 则可能会得到过期的数据。 为了避免这种情况, 可以在SELECT
之前使用OPTIMIZE查询。
自定义分区及底层存储合并机制自定义分区键
1. 分区是在建表时使用PARTITION BY expr子句指定。
2. 分区键可以是表列中的任何表达式。
例如,按月指定分区:PARTITION BY toYYYYMM(date_column)。
使用元组指定分区:PARTITION BY (toMonday(StartDate), EventType)
3. 在将新数据插入表中时,每个分区的数据存储为单独的数据片段(每个数据片段的数
据是按主键排序的),在插入后的10-15分钟内,同一个分区的数据片段将合并为一个整
体的数据片段。
分区目录的命名规则
根据分区表达式的数据类型, 分区的命名规则是存在差异的。
1. 不指定分区:分区名称为all。
2. 数值数据类型:分区名称为数值。
3. 日期数据类型:将日期转换为数字作为分区名称。
4. 字符串数据类型:将日期转换为hash作为分区名称。
系统表:
SELECT partition, name, table, active FROM system.parts WHERE table like 'xxx';
分区目录的合并过程
在将新数据插入表中时,每个分区的数据按照目录存储为单独的数据片段, 目录名为
数据片段名称,这个和system.parts表的name字段一致。
在插入后的10-15分钟内,同一个分区的数据片段将合并为一个整体的数据片段。
数据片段名称包含了4部分的信息,下面以数据片段20200421_1_2_1为例进行拆解:
- 20200421是分区名称。
- 1是数据块的最小编号。
- 2是数据块的最大编号。
- 1是块级别,即该块在MergeTree中的深度。
分区目录的合并过程
1. active列为数据片段的状态。1表示激活状态,0表示非激活状态。当源数据片段合并为较大的片段之
后,这些源的数据片段就变为了非激活状态。损坏的数据片段也是非激活状态。
2. 同一分区有多个独立的数据片段,这表明这些片段尚未合并。
ClickHouse会在插入后大约15分钟合并数据片段,也可以使用OPTIMIZE语句执行计划外的合并:
OPTIMIZE TABLE mergeTableDemo PARTITION 202004;
3. 非激活的片段(active=0片段)将在合并后约10分钟被删除。
4. detached目录包含使用DETACHED语句从表分离的数据片段。 损坏的数据片段也将移至该目录,而
不是被删除。ClickHouse不会使用detached目录中的数据片段。 此目录中的数据可以随时添加、删除
或修改,ClickHouse只有在运行ATTACH语句时才会感知该目录。
分区表达式指定
alter语句、optimize语句通常需要指定分区的表达式,分区表达式的值为system.parts的partition字
段, 而不是分区的名称,这里需要注意。
因为字符串和日期类型的分区,分区名称和分区表达式的值是不一样的。
例如, 日期类型的分区:

分区表达式的值是2020-04-21,分区名称为20200421。
执行optimize操作:optimize table test_partition partition '2020-04-21'。
不能写成:optimize table test_partition partition '20200421。
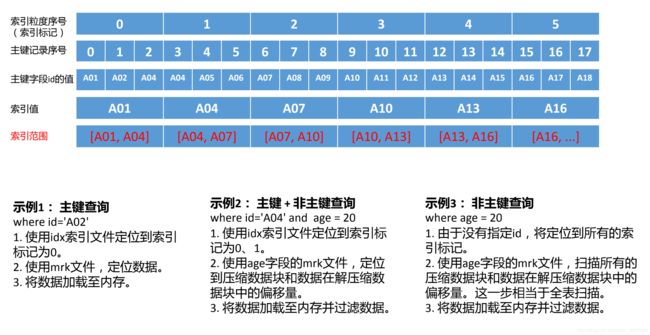
主键/索引的工作机制-MergeTree的稀疏索引
数据按照主键排序后存储的
每个索引记录对应8192条(由index_grandularity指定)记录
索引是常驻内存的
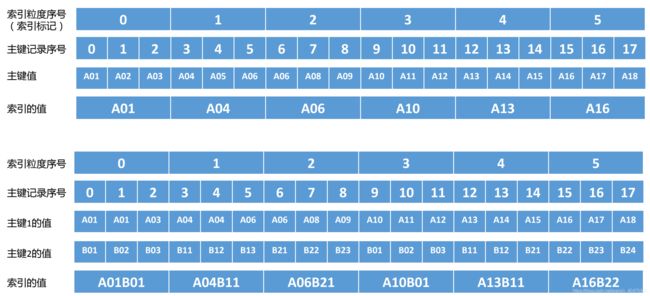
索引的生成过程
索引由Primary Key 指定。索引数据保存在primary.idx文件中。 这里假设索引粒度(index_grandularity)为3,即每3条数据生成一条索引记录。
A01B01 A04B11 A06B21 A10B01 A13B11 A16B22
索引的查询 1 A04 A07 A10 A13 A16
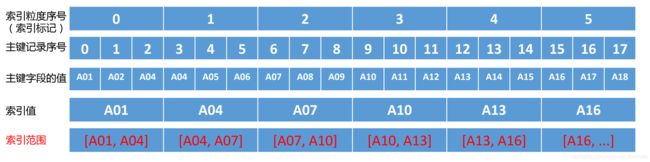
前后相邻的两个索引的值,构成索引的范围。
根据主键的查询条件,确定索引范围。
(1)、id in ('A02', 'A08'), 转化为索引范围区间[A01, A04] 和 [A07, A10], 对应索引标记0和2中查询数据。
(2)、id = 'A04', 在索引范围[A01, A04]和[A04, A07]区间查询数据,对应索引标记0和1。
(3)、id > 'A11', 在索引范围[A10, +inf]区间查询数据,对应所有值大于3的索引标记。
(4)、id like 'A0%', 在索引范围[A01, A04]、[A04,A07]和[A07, A10]区间查询数据,对应索
引标记为0、1和2。
数据标记的工作机制--数据存储
bin文件是真正存储数据的文件。
bin文件的数据是按照排序健排序后存储的。
一个bin文件由N个压缩数据块组成。
一个压缩数据块存储压缩前大小为64K~1M 字节的数据。

数据标记
mkt文件是存储数据标记的文件。
存储索引标记、压缩数据块在BIN文件的偏移量、解压缩数据块的
偏移量。
假设age字段,每个值占用1字节空间,在该列则一个索引粒度范围
内占用8192*1字节 = 8192字节 = 8KB。
每8(64KB/8KB=8)个索引粒度,占用一个压缩数据块。
压缩数据块的切分规则:
(1)、一个压缩数据块存储压缩前大小为64K~1M 字节的数据。
(2)、按一个索引粒度为最小单位, 添加其对应的数据,用于生
成压缩数据块。
(3)、如果一个索引粒度对应的数据小于64K,则继续添加下一个
索引粒度对应的数据,
直至数据的大小在64K~1M之间,然后生成压缩数据块。
(4)、如果一个索引粒度对应的数据超过1M, 则该批次数据将拆
分为多个压缩数据块存储。
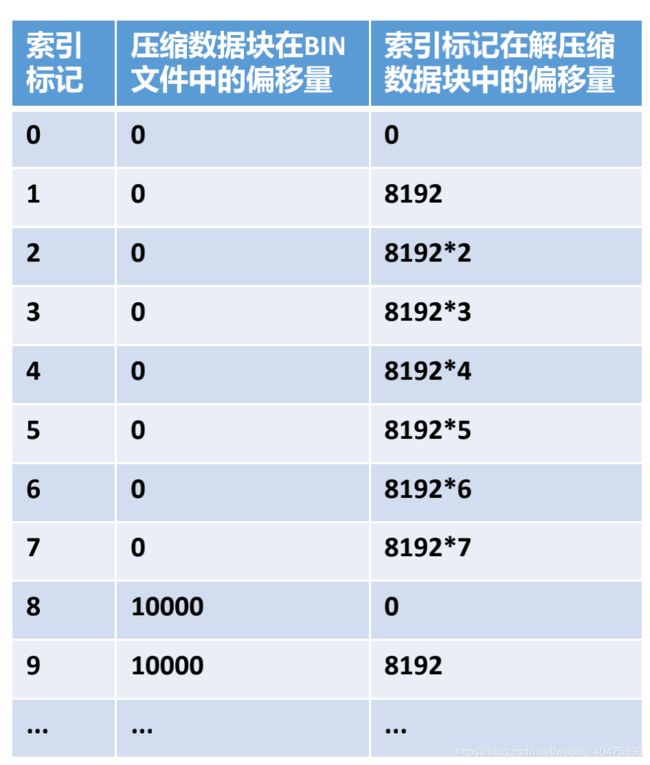
数据查询
1. 确定分区(如果有)
2. 根据primary.idx确定数据数据在哪些索引标记内。
3. 根据索引标记和数据标记文件(*.mrk或*.mrk2)确定数据在哪个压缩数据块,以及在解
压缩数据块中的偏移量
4. 加载数据至内存,向量化操作、查询过滤

数据查询示例