MySQL InnoDB中undo日志的组织及实现
InnoDB中undo日志的组织及实现
left2right
已关注
Undo日志在InnoDB中起着重要的作用,保证着事务的原子性,解决崩溃恢复的问题,满足隔离性要求等。InnoDB中undo日志的结构是什么样的、这些undo日志是如何组织起来的、为满足事务原子性InnoDB中undo是如何实现的?针对这些问题,本文分两部分展开介绍:第一部分undo日志的结构和组织;第二部分Undo日志作用及实现。本文的侧重点是InnoDB中undo日志是如何组织及实现的,对主要点进行介绍,一些细节步过多展开。
Undo日志结构及组织
Undo日志存储在undo tablespace中为。了提升并发写undo日志能力,每个undo tablespace会划分128个rollback segment来进行管理,每个rollback segment包含1024个undo slot。写事务执行时要分配一个rollback segment,任何一类写操作(insert、update、temp insert、temp update)都要分配一个undo slot,该undo slot对应分配一个undo segment,维护着一个undo页面链表,该事务某类型的写操作的undo日志就写到这个undo页面链表中。有些事物写操作对应的undo日志很少,就会有针对undo页面链表的重用,即一个undo页面链表会包含多个事物的同类型undo日志。undo日志分为insert、update与delete这三类。下面围绕Undo日志格式、Undo页面结构以及undo tablespace组织展开进行说明:
Undo日志的格式
Undo日志格式分为insert操作、delete操作以及update操作对应的日志,读请求不更改记录,没有undo日志。
INSERT操作对应的undo日志
Insert操作对应的undo日志类型是TRX_UNDO_INSERT_REC的undo日志,记录这条记录对应的主键信息等,完整的结构如下图:

DELETE操作对应的undo日志
记录的删除操作分为两个阶段:
阶段1: 仅仅将记录的deleted_flag标示位设置为1,其他的不做修改(实际会修改记录的trx_id,roll_pointer等隐藏列的信息),这个阶段称为delete mark 。
阶段2:当该删除语句所在的事务提交之后,undo purge线程来真正的把记录删除掉。就是把记录从正常记录链表移除,加入到垃圾连表中。然后对页面的一些信息作修改,如页面中的用户记录数量PAGEN_RECS、上次插入记录的位置PAGE_LAST_INSERT、垃圾链表头节点的指针PAGE_FREE、页面中可重用的字节数量PAGE_GARBAGE,以及页目录的一些信息等,这个阶段称为purge。阶段2执行完后,这条记录就算是真正地被删除了。这条己删除记录占用的存储空间可以重新利用了。
在执行一条删除语句的过程中,在删除语句所在的事务提交前,只会经历阶段1,也就是delete mark阶段。而一旦事务提交,我们也就不需要再回滚越个事务了。所以在设计udo日志时,只需要考虑对删除操作在阶段1所做的影响进行回滚。
针对删除操作的阶段1,Innodb设计TRX_UNDO_DEL_MARK_REC类型的undo日志,在对一条记录进行delete mark操作前,需要把该记录的trx_id和roll——pointer的隐藏列旧值都记到对应的undo日志中的txid和olpointer属性中。可以通过undo日志的roll_pointer的属性找到上一次对该记录改动产生的undo日志,即结合roll_pointer属性将记录的undo日志历史修改串成一个链表。与类型为TRX_UNDO_INSERT_REC的undo日志不同,类型为TRX_UNDO_DEL_MARK_REC的udo日志还多了一个索引列各列信息的内容。也就是说,如果某个列被包含在某个索引中,那么它的相关信息就应该记录到这个索引列各列的信息部分。“相关信息”包括该列在记录中的位置(用pos表示)、该列占用的存储空间大小(用len表示)、该列实际值(用value表示)。所以,索引列各列信息存储的内容实质上就是的一个列表。这部分信息主要在事务提交后使用,用来对中间状态的记录进行真正的删除(即在阶段2,也就是puge阶段中使用)。具体日志结构如下:

UPDATE操作对应的undo日志
在执行UPDATE语句时,InnoDB对更新主键和不更新主键这两种情况有截然不同的处理:
1. 不更新主键
在不更新主键的情况下,又可以细分为被更新的列占用的存储空间不发生变化和发生变化两种情况:
就地更新(in-place update) :在更新记录时,对于被更新的每个列来说,如果更新后的列与更新前的列占用的存储空间一样大,那么可以进行就地更新,也就是直接在原记录的基础上修改对应列的值。每个列在更新前后占用的存储空间一样大,只要有任何一个被更新的列在更新前比更新后占用的存储空间大,或者在更新前比更新后占用的存储空间小,就不能进行就地更新。
先删除旧记录,再插入新记录: 在不更新主键的情况下,如果有任何一个被更新的列在更新前和更新后占用的存储空间大小不一致,那么就需要先把这条旧记录从聚簇索引页面中别除,然后再根据更新后列的值创建一条新的记录并插入到页面中。这里的删除并不是delete mark操作,而是真正地除掉,也就是把这条记录从正常记录链表中移除并加入到垃圾链表中,并且修改页面中相应的统计信息(比如PAGE FREE、PAGE GARBAGE等信息)。不过,这里执行真正删除操作的线程并不是在DELETE语句中进行purge操作时使用的专门的线程,而是由用户线程同步执行真正的删除操作。在真正删除之后,紧接着就要根据各个列更新后的值来创建一条新记录,然后把这条新记录插入到页面中。如果新创建的记录占用的存储空间不超过旧记录占用的空间,那么可以直接重用加入到垃圾链表中的旧记录所占用的存储空间,否则需要在页面中新申请一块空间供新记录使用。如果本页面内已经没有可用的空间,就需要进行页面分裂操作,然后再插入新记录。
针对UPDATE操作不更新主键的情况(包括上面说的就地更新和先删除旧记录再插入新记录),InnoDB设计类型为TRX_UNDO_UPD_EXIST_REC的undo日志,这个undo日志的大部分属性与前面介绍过的TRX_UNDO_DEL_MARK_REC类型的undo日志是类似的,不过要注意下面几点: n_updated属性表示在本条UPDATE语句执行后将有几个列被更新,后边跟着的列表中的pos、old_len和old_value分别表示被更新列在记录中的位置、更新前该列占用的存储空间大小、更新前该列的真实值。 如果在UPDATE语句中更新的列包含索引列,那么也会添加“索引列各列信息”这个部分,否则不会添加这个部分。 具体结构如下图所示:

2.更新主键
针对UPDATE语句更新记录主键的情况,Innodb分了两步进行处理。
步骤1. 将旧的记录进行delete mark操作,也就是只标记删除,在事务提交后有purge线程进行真正的删除。
步骤2. 根据更新后各列的值创建一条新记录,并将其插入到主键索引中。
针对UPDATE培句更新记录主键值的这种情况,在对该记录进行delete mark操作时,会记录一条类型为TRX_UNDO_DEL_MARK_REC的undo日志:之后插入新记录时,会记录类型为TRX_UNDO_NSERT_REC的undo日志。就是说,每对一条记录的主键值进行改,都会记录2条undo日志。这些日志的格式都在前面已经介绍过,就不再赘述。
增删改操作涉及二级索引
只有主键索引的记录才有trx_id、roll_pointer这些属性,也就是有对应的undo日志链,二级索引的更改没有对应的trx_id、roll_pointer,也就是没有对应的undo日志链。但每当我们增删改一条二级索引记录时,都会影响这条二级索引记录所在页面的Page Header部分中一个名为PAGE_MAX_TRX_ID的属性,通过这个属性及通过二级索引回查主键,判断索引版本的可见性等。 如果更新了二级索引记录的键值,就要进行下面这两个操作:
1. 对旧的二级索引记录执行delete mark操作(是delete mark操作,而不是彻底将这条二级索引记录删除,这主要是考虑到MVCC)。
2. 根据更新后的值创建一条新的二级索引记录,然后在二级索引对应的B+树中重新定位到它的位置并插进去。
Undo页面结构
FIL_PAGE_UNDO_LOG类型的页面(简称undo页面)是专门用来存放undo日志的,undo页面的结构主要由File Header、Undo Page Header、Undo Log Segment Header(只有undo页面链表的first page有)、Undo Log Header以及真正的undo日志(具体见上面不同的undo日志格式),下面结合undo页面结构图,展开分析undo页面的不同Header结构

Undo Page Header结构
Undo Page Header是Undo页面特有的,我们来看一下它的结构
TRX_UNDO_PAGE_TYPE: 本页面准备存储什么类型的undo日志,不同类型的undo日志不能混着存储.比如一个Undo页面的TRX_UNDO_PAGE_TYPE属性值为TRX_UNDO INSERT,那么这个页面就只能存储类型为TRX_UNDO_INSERT_REC的undo日志,其他类型的undo日志就不能放到这个页面中了:之所以把ndo日志分成2个大类,是因为类型为TRX_UNDO_INSERT_REC的undo日志在事务提交后可以直接删除掉,而共他类型的undo日志还需要为MVCC服务
TRX_UNDO_INSERT(使用十进制1表示):类型为TRX_UNDO _INSERT_REC的undo日志属于这个大类,一般由INSERT语句产生:当UPDATE语句更新主健的情况时也会产生此类型的undo日志。我们把属于这个TRX_UNDO_INSERT大类的undo日志简称为insert undo日志.
TRX_UNDO_UPDATE (使用十进制2表示),除类型为TRX_UNDO_INSERT_REC外的undo日志都属于这个类型.比如前面说的TRX_UNDO_DEL_MARK_REC, TRX_UNDO_UPD_EXIST_REC等。一般由DELETE UPDATE语句产生的undo日志,我们把属于TRX_UNDO_UPDATE的undo日志简称为update undo日志。
TRX_UNDO_PAGE_START: 表示在当前页面中从什么位置开始存储undo日志,或者说表示第一条undo日志在本页面中的起始偏移量。
TRX_UNDO_PAGE_FREE: 与上面的TRX_UNDO_PAGE_START对应,表示当前页面中存储的最后一条undo日志结束时的偏移量;或者说从这个位置开始,可以继续写入新的undo日志。 TRX_UNDO_PAGE_NODE: 代表一个链表节点结构
Undo Log Segment Header的结构
Undo页面链表的第一个页面比普通页面多了一个Undo Log Segment Header,
TRX_UNDO_STATE: 本Undo页面链表处于什么状态。可能的状态有下面几种:
TRX_UNDO_ACTIVE: 活跃状态,也就是一个活跃的事务正在向这个Undo页面链表中写入undo日志。 TRX_UNDO_CACHED: 被缓存的状态。处于该状态的Undo页面链表等待之后被其他事务重用。 TRX_UNDO_TO_FREE: 等待被释放的状态,对于insert undo链表来说,如果在它对应的事务提交之后,该链表不能被重用,那么就会处于这种状态。
TRX_UNDO_TO_PURGE:等待被purge的状态。对于update undo链表来说,如果在它对应的事务提交之后,该链表不能被重用,那么就会处于这种状态。
TRX_UNDO_PREPARED:处于此状态的Undo页面链表用于存储处于PREPARE阶段的事务产生的日志。 TRX_UNDO_LAST_LOG: 本Undo页面链表中最后一个Undo Log Header的位置。
TRX_UNDO_FSEG_HEADER: 本Undo页面链表对应的段的Segment Header信息 TRX_UNDO_PAGE_LIST: Undo页面链表的基节点
Undo Log Header的结构
TRX_UNDO_TRX_ID: 生成本组undo日志的事务id
TRX_UNDO_TRX_NO: 事务提交后生成的一个序号,此序号用来标记事务的提交顺序(先提交的序号小,后提交的序号大)
TRX_UNDO_DEL_MARKS:标记本组undo日志中是否包含由delete mark操作产生的undo日志 TRX_UNDO_LOG_START: 表示本组undo日志中第一条undo日志在页面中的偏移量
TRX_UNDO_XID_EXISTS: 本组undo日志是否包含XID信息
TRX_UNDO_DICT_TRANS: 标记本组undo日志是不是由DDL产生的 TRX_UNDO_TABLE_ID: 如果TRX_UNDO_DICT_TRANS为真,本属性表示DDL语句操作的表的table id
TRX_UNDO_NEXT_LOG:下一组undo日志在页面中开始的偏移量
TRX_UNDO_PREV_LOG: 上一组undo日志在页面中开始的偏移量,一般来说,一个Undo页面链表只存储一个事务执行过程中产生的一组undo日志。但是在某些情况下,可能会在一个事务提交之后,后续开启的事务又重复利用这个Undo页面链表,这就会导致一个Undo页面中可能存放多组ndo日志.
undo页面链表
因为一个事务可能包含多个语句,而且一个语句可能会对若干条记录进行改动,而对每条记录进行改动前(再强调一下,这里指的是聚簇素引记录),都需要记录1条或2条undo日志。所以在一个事务执行过程中可能产生很多uo日志。这些日志可能在一个页面中放不下,需要放到多个页面中。这些页面就通过前文介绍的TRX_UNDO_PAGE_NODE属性连成了链表,一个事务中最多有4个以Undo页面为节点组成的链表,并不是在事务一开始就为它分配这4个链表,具体分配策略如下:
刚开启事务时,一个Undo页面链表也不分配:
当事务执行过程中向普通表插入记录或者执行更新记录主键的操作之后,就会为其分配一个普通表的insert undo链表
当事务执行过程中刷除或者更新了普通表中的记录之后,就会为其分配一个普通表的update undo链表
当事务执行过程中向临时表插入记录或者执行更新记录主键的操作之后,就会为其分配一个临时表的insert undo链表
当事务执行过程中删除或者更新了临时表中的记录之后,就会为其分配一个临时表的update undo链表。
总之就是:按需分配,啥时候需要啥时候分配,不需要就不分配。
Undo页面重用
为提高并非执行多个事务写undo日志的性能,InnoDB为每个事务单独分配相应的Undo页面链表(最多可能分配4个链表)。但大部分事务执行的过程中至少修改一条或者几条记录,产生的undo日志非常少,占用很少的空间,一个页面链表(虽然链表只有一个页面)只存这几条undo日志,也造成空间浪费。 为提高空间利用,在事务提交后某些情况下Undo页面链表可以被重用,需要满足两个条件:
1.该链表只有一个Undo页面;
2. 该Undo页面以及使用空间小雨整个页面空间的3/4.
如果没有undo页面链表重用,每个undo页面链表(一个Undo log segment)对应一组undo日志,一个Undo Log Header。Undo页面重用后,一个undo页面链表(一个Undo log segment)对应多组undo日志,多条Undo Log Header。
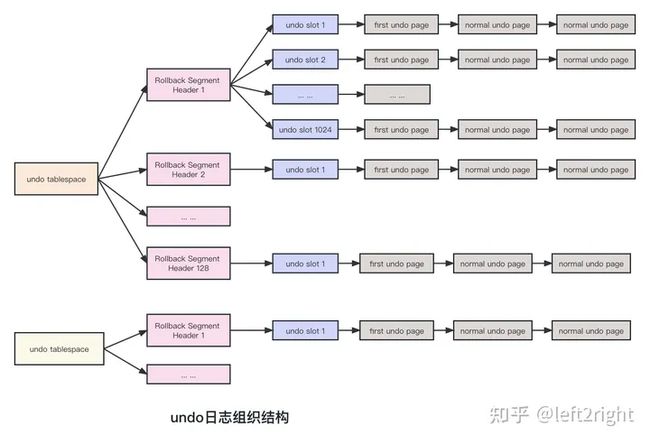
Undo tablespace组织
Innodb中至少存在两个undo tablespace,每个Undo tablespace特定的页存储着128个(可修改)Rollback Segment Header页面地址,每个Rollback Segment Header就相当于一个回滚段。在Rollback Segment Header页面中,又包含1024个undo slot。写事务在执行时,会为每一类写操作分配一个undo slot,每个undo slot都对应一个Undo页面链表,具体结构如下图所示:
在事务提交后,update类型undo日志会按照trx no从小到大插入到rseg的history list上,方便后面使用rollback segment小顶堆,有序的purge这些undo日志,undo history list结构如下图所示:

Undo作用及实现实现
Undo日志保证了事务的原子性、解决了崩溃恢复的问题,满足隔离性要求。Innodb针对undo log的实现涉及的地方比较多,我们这里围绕着启动时undo相关操作、undo tablespace如果修改、事务写操作、MVCC读请求、事务回滚、Undo Purge & Truncate展开,包含了undo的整个生命周期,主要介绍关键流程,不对细节过多展开(个别地方可能分析有偏差)。下文中代码实现介绍基于mysql 8.0(commit为ea7087d885006918ad54458e7aad215b1650312c),代码介绍中的缩进表示调用下一级函数。
启动时undo相关操作
启动时undo相关操作包括undo tablespace初始化,相关内存对象初始化,crash前的事务恢复以及回滚,实现见如下:
// 实例启动创建undo tablespace及事务恢复加入到rw_trx_list
srv_start
srv_undo_tablespaces_init
srv_undo_tablespaces_create // undo tablespaces创建及open
srv_undo_tablespace_create
srv_undo_tablespace_open
srv_undo_tablespaces_construct // undo tablespace创建后的一些完成动作:加密及添加RSEG_ARRAY page等
trx_purge_sys_mem_create // purge sys 内存对象创建及初始化
trx_sys_init_at_db_start // trx sys init
trx_rsegs_init // undo tablespace rseg 串行初始化,每个undo tablespace 128个
trx_rseg_mem_create // rseg对象创建
trx_undo_lists_init // 为每个rseg初始化1024个undo slot(undo log memory object)
trx_undo_mem_init // Creates and initializes an undo log memory object
trx_rsegs_parallel_init // ndo tablespace rseg 并行初始化
trx_rseg_init_thread
trx_rseg_physical_initialize
trx_undo_lists_init
trx_undo_mem_init
trx_lists_init_at_db_start // create & initializes the trx list of trx_sys
trx_resurrect // 恢复 crash时没有提交的写事务
trx_resurrect_insert // 恢复insert事务
trx_resurrect_update // 恢复 update(包括delete)事务
trx_add_to_rw_trx_list // 添加恢复出来的事务到trx list: rw_trx_list
// 对undo tablespace的状态进行fix
innobase_dict_recover
boot_tablespaces
validator.validate(tablespaces)
srv_undo_tablespace_fixup // 对server crashed时正在进行truncate的undo tablepsace进行状态修复
// 对恢复出来rw_trx_list中的事务进行rollback或者cleanup
innobase_post_recover
trx_recovery_rollback_thread // trx recover & rollback线程,专门处理crash前在运行的事务的后续处理
trx_recovery_rollback
trx_rollback_or_clean_recovered // 对 rw_trx_list 中的事务基于状态进行rollback或者cleanup
trx_rollback_or_clean_resurrected
trx_cleanup_at_db_startup // TRX_STATE_COMMITTED_IN_MEMORY 状态的事务cleanup
trx_rollback_active // TRX_STATE_ACTIVE状态的事务rollback,具体的rollback见后面事务回滚
trx_rollback_activeUndo tablespace创建与修改
undo tablespace的创建修改分两种场景:
1.实例创建启动时创建对应的undotablespace(上面已经介绍);
2. 实例运行中进行创建及修改,代码实现如下:
// 实例运行中通过DDL创建修改undo tablespace
innobase_alter_tablespace
innodb_create_undo_tablespace // 新增创建
srv_undo_tablespace_create
innodb_alter_undo_tablespace // 修改undo tablespace状态active or inactive
innodb_alter_undo_tablespace_active
innodb_alter_undo_tablespace_inactive
innodb_drop_undo_tablespace // 删除undo tablespace事务写操作
事务写操作对应的undo主要分为三个点:
1. 事务启动时为写事务分配undo rseg,基于round-robin的方式从undo tablespace中分配
2. 事务执行中为写操作分配undo log并将对应类型的undo内容写入日志
3. 事务commit时为undo log分配trx no,将rseg加入到purge queue,并将update undo加入rseg history list
// trx start 分配rseg
trx_start_if_not_started_low
trx_start_low // 事务启动
trx_assign_rseg_durable
get_next_redo_rseg
get_next_redo_rseg_from_undo_spaces // Get next redo rollback segment in round-robin
trx_set_rw_mode // 读事务切换为写事务
trx_assign_rseg_durable
get_next_redo_rseg
get_next_redo_rseg_from_undo_spaces
// insert记录
btr_cur_optimistic_insert // 乐观插入
btr_cur_pessimistic_insert // 悲观插入
btr_cur_ins_lock_and_undo
trx_undo_report_row_operation // 写undo
trx_undo_assign_undo // Assigns an undo log for a transaction
trx_undo_reuse_cached // 从cache分配
trx_undo_create // 新创建
trx_undo_page_report_insert // 记录要插入的内容到undo,内容见上面insert操作对应日志介绍
// update记录
btr_cur_update_in_place // 原地更新记录
btr_cur_optimistic_update // 乐观更新
btr_cur_pessimistic_update // 悲观更新
btr_cur_upd_lock_and_undo
trx_undo_report_row_operation // 写undo
trx_undo_assign_undo // Assigns an undo log for a transaction
trx_undo_reuse_cached // 从cache分配
trx_undo_create // 新创建
trx_undo_page_report_modify // 记录要修改的内容到undo,内容见上面update & delete操作对应日志介绍
// trx commit
trx_commit_low
trx_write_serialisation_history
trx_serialisation_number_get // 分配trx no及将rseg加入到purge queue
trx_add_to_serialisation_list
purge_sys->purge_queue->push(std::move(elem));
trx_undo_update_cleanup
trx_purge_add_update_undo_to_history // 将undo log 加入到rseg history list的开头
flst_add_firstMVCC读请求
读请求根据隔离性级别不同实现也不同,本篇主要讲undo,所以这里只围绕非锁定一致性读稍作展开,即使用mvcc的读请求。主要是基于read view和undo不同版本的trx id判断可见性,来构建相应版本的数据返回,见下面代码:
row_search_mvcc
trx_assign_read_view // 分配read view
Row_sel_get_clust_rec_for_mysql
row_sel_build_prev_vers_for_mysql
row_vers_build_for_consistent_read
trx_undo_prev_version_build // 沿着roll ptr构建更早版本
row_get_rec_roll_ptr // 获取roll ptr
trx_undo_get_undo_rec // 获取undo rec
purge_sys->view.changes_visible // 使用read view和该版本对应的rx id判断可见性事务回滚
undo的回滚操作分为两种场景:一种是在事务中主动执行rollback回滚;另外一种是在实例crash recovery时对事务的回滚.回滚主要分为三个步骤:
1. 触发及构建需要回滚的trx的信息保存到roll_node_t;
2. trx rollback query graph基于roll_node_t构建undo_node_t;
3. row undo query graph使用undo_node_t对btree上的记录进行回撤操作。代码如下:
// 1. 事务中主动触发Rollback
innobase_rollback_trx
trx_rollback_for_mysql
trx_rollback_for_mysql_low
trx_rollback_to_savepoint_low // 构建roll_node_t并交给trx rollback处理
pars_complete_graph_for_exec
que_fork_start_command
que_run_threads
// 2. 实例启动后recover线程触发对rw_trx_list中活跃事务回滚
trx_rollback_or_clean_recovered // 对 rw_trx_list 中的事务基于状态进行rollback或者cleanup
trx_rollback_or_clean_resurrected
trx_rollback_active // 构建roll_node_t并交给trx rollback处理
roll_node_create
que_fork_start_command
que_run_threads
// trx rollback 线程处理roll_node_t相关的trx rollback
trx_rollback_step
trx_rollback_start
trx_roll_graph_build
row_undo_node_create // 构建 undo_node_t 进行 undo
// row undo 对btree上的记录进行回撤
row_undo_step
row_undoUndo Purge & Truncate
Undo Purge
Undo purge的流程是围绕purge queue(基于tx no的小顶堆)展开的: 首先:在transaction commit阶段给update操作对应的undo分配tx no,将update操作对应的rseg加入到purge queue(见函数trx_serialisation_number_get),接着将对应的update undo log加入到rseg history list开头(见函数trx_purge_add_update_undo_to_history) 然后:后台trx purge 线程使用purge queue将undo log按照trx no从小到大扫出来一批,分配到不同的row purge线程 最后:row purge 线程基于undo log的不同类型删除(TRX_UNDO_DEL_MARK_REC),更新(TRX_UNDO_UPD_EXIST_REC)分别调用不同的函数将undo log对应记录的二级索引、主键从btree上真正的删除掉,并加入到garbage list
trx_commit_low
trx_write_serialisation_history
trx_serialisation_number_get // 分配trx no及将rseg加入到purge queue
trx_add_to_serialisation_list
purge_sys->purge_queue->push(std::move(elem));
trx_undo_update_cleanup
trx_purge_add_update_undo_to_history // 将undo log 加入到rseg history list的开头
flst_add_first
srv_do_purge
trx_purge
trx_purge_attach_undo_recs // 扫一批undo日志,并封装相应的内存数据结构,供后面row purge线程进行purge
trx_purge_fetch_next_rec
trx_purge_choose_next_log // 选择下一个trx对应的undo日志
purge_sys->rseg_iter->set_next(); // 基于trx no选择最小的rseg进行处理
purge_sys->purge_queue->pop();
trx_purge_read_undo_rec
trx_purge_get_next_rec // 读取下一条undo rec
trx_purge_rseg_get_next_history_log
trx_purge_get_log_from_hist
rseg->last_page_no = FIL_NULL;
que_run_threads(thr); // 将undo对应的数据结构传递给row purge线程进行purge
trx_purge_truncate // undo purge结束后尝试对undo tablespace进行truncate,后面展开说明
row_purge // row purge线程基于trx purge线程传递过来的数据结构对undo日志对应的记录进行purge
row_purge_del_mark // purge TRX_UNDO_DEL_MARK_REC类型的undo记录的二级索引及主键
row_purge_remove_sec_if_poss // purge 二级索引
row_purge_remove_sec_if_poss_leaf
row_purge_poss_sec
row_vers_old_has_index_entry
btr_cur_optimistic_delete
row_purge_remove_sec_if_poss_tree
row_purge_poss_sec
row_vers_old_has_index_entry
btr_cur_pessimistic_delete
row_purge_remove_clust_if_poss // purge主键
btr_cur_optimistic_delete
btr_cur_pessimistic_delete
row_purge_upd_exist_or_extern_func // purge TRX_UNDO_UPD_EXIST_REC类型的undo对应记录的二级索引、及blob数据
row_purge_remove_sec_if_poss
lob::purgeUndo Truncate
Undo truncate分为两个步骤,第一步是将undo log从各个undo tablespace的rseg undo history摘除掉;第二步是对undo tablespace文件truncate(先删除,再创建),具体代码实现如下:
trx_purge_truncate
trx_purge_truncate_history // 将 undo log从rseg的undo history摘除
trx_purge_truncate_rseg_history
trx_purge_get_log_from_hist
trx_purge_free_segment
trx_purge_remove_log_hdr
trx_purge_truncate_undo_spaces // truncate undo tablespace
trx_purge_mark_undo_for_truncate
trx_purge_truncate_marked_undo
fil_delete_tablespace // Step-1: Delete the old tablespace.
fil_ibd_create // Step-2: Re-create tablespace with new file
fsp_header_init // Step-3: Re-initialize tablespace header.
trx_rseg_array_create // Step-4: Add the RSEG_ARRAY page总结
InnoDB中undo日志设计及实现相对清晰,但涉及的地方比较多,有些地方设计的比较巧妙,需要仔细的研究,整体对undo日志这块做下梳理。